
面向大数据应用的自适应带宽分配策略
2019-08-07 00:46姜晶
兵器装备工程学报 2019年7期
姜 晶
(徐州开放大学 信电学院, 江苏 徐州 221116)
随着移动设备的高速发展,海量数据(大数据)的应用日益剧增[1-3]。通常大数据具有3Vs特性:容量(Volume)、速度(Velocity)和多变(Variety)[4]。随着大数据的不断涌现,随之而来的问题也难以避免,如大数据分析、大数据传输以及容量问题。其中,大数据传输问题尤为突出。为此,在满足数据有效期的条件下,如何高效地传输大数据成为研究热点。
节点产生的数据可能需要通过网络传输至其他节点。在传输数据前,节点通常先传输数据请求。因此,如何可靠地传输请求并处理传输请求,对数据传输的成功起到关键作用。而有效地给传输请求(Request,Req)分配带宽有利于快速地传输请求。然而由于海量数据和网络的复杂性,有效地分配带宽存在一些挑战。
给请求分配宽的带宽,可降低传输时延,但也消耗了宽带资源。反之,若分配窄的带宽,网络可接收更多的请求,但增加传输时延,最终也可能加大了链路瓶颈的概率。因此,自适应地分配带宽显得尤为重要。即在有限资源下,满足时限要求,尽可能给传输请求分配带宽,进而高效地传输数据[5]。
为了克服现存带宽分配的不足,提出自适应带宽分配策略(Flexible Bandwidth Allocation for Big Data Transfer,FBA-BDT)。首先,建立优化规划目标函数,其目的是在满足所有传输请求的时限条件下,最大化地完成请求的传输。目标函数给每个已接收的请求分配了最优带宽,使得能在截止日期前完成数据传输,进而提高带宽利用率。
1 问题描述
本节针对大数据传输请求(Big Data Transfer Requests,BDTRs)建立最优规划目标函数。
令G(V,E)表示网络,其中V为顶点集、E为边集。Cl表示链路l∈E的剩余带宽[6]。最初,当网络没有准许任何请求时,所有链路均具有最大容量的带宽。在时隙t,令R表示已准许的BDTRs集。对于每个请求r∈R,其可用一个元组〈sr,dr,Vr,tr〉表述,其中sr为源节点、dr为目的节点、Vr为需要传输的数据容量、tr为完成数据传输的截止时间。
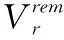
引用二值变量xr表示请求r是否被网络准许,若xr=1,表示准许;若xr=0,表示拒绝。而引用二值变量yr表示选用了哪条路径:Pr,1或Pr,2。而用zr表示给请求r分配的带宽数。因此,自适应带宽分配的优化规划目标函数如下:
(1)
(2)
(3)
xrVr/tr≤zr, ∀r∈R
(4)
(5)
xr,yr∈{0,1}, ∀r∈R
(6)
由式(1)可知,目标函数的目的就是最大化已准许的BDTRs数,准许的BDTRs数越多,通过的数据量越大。而限制条件式(2)和式(3)确保了给已选的每个BDTR的路径分配足够的带宽。如果一条链路用于多个请求,必须有剩余带宽分配给这些请求。
限制条件式(2)应用于使用第一条路径(Pr,1,∀r∈R∪Rac)的BDTRs,而限制条件式(3)应用于使用第二路径(Pr,2)的其他请求。注意当yr=1,表示请求r利用路径Pr,1传输数据;而yr=0,表示请求r利用路径Pr,2传输数据。而限制条件式(4)和式(5)给已准许的请求和正在进行的请求提供了最小的带宽,并满足它们的时限要求。
然而,由于目标函数的非线性特性[7],计算目标函数的运算量较大。即使对于少量的BDTRs和小型网络,涉及的变量数仍过大,并且变量数随请求数和网络尺寸呈指数增长。因此,很难在短时间内,获取最优解。为此,接下来,利用启动算法求解目标函数,进而获取可接收的次优解。
2 求解算法
利用FBA-BDT算法求解目标函数。求解过程由两步构成,伪代码分别如算法1和算法2所示。它们需解决的问题如图1所示。从图1可知,算法1的目的在于满足请求的最基本要求(分配所需的最小带宽),而算法2是将剩余带宽重新分配给已准许的请求。
注意到,算法1和算法2均是周期地执行,即在每个时隙开始执行,且每个时隙的时长为ts。具体而言,在时隙t-1到达的所有BDTRs需在时隙t的开始时完成。
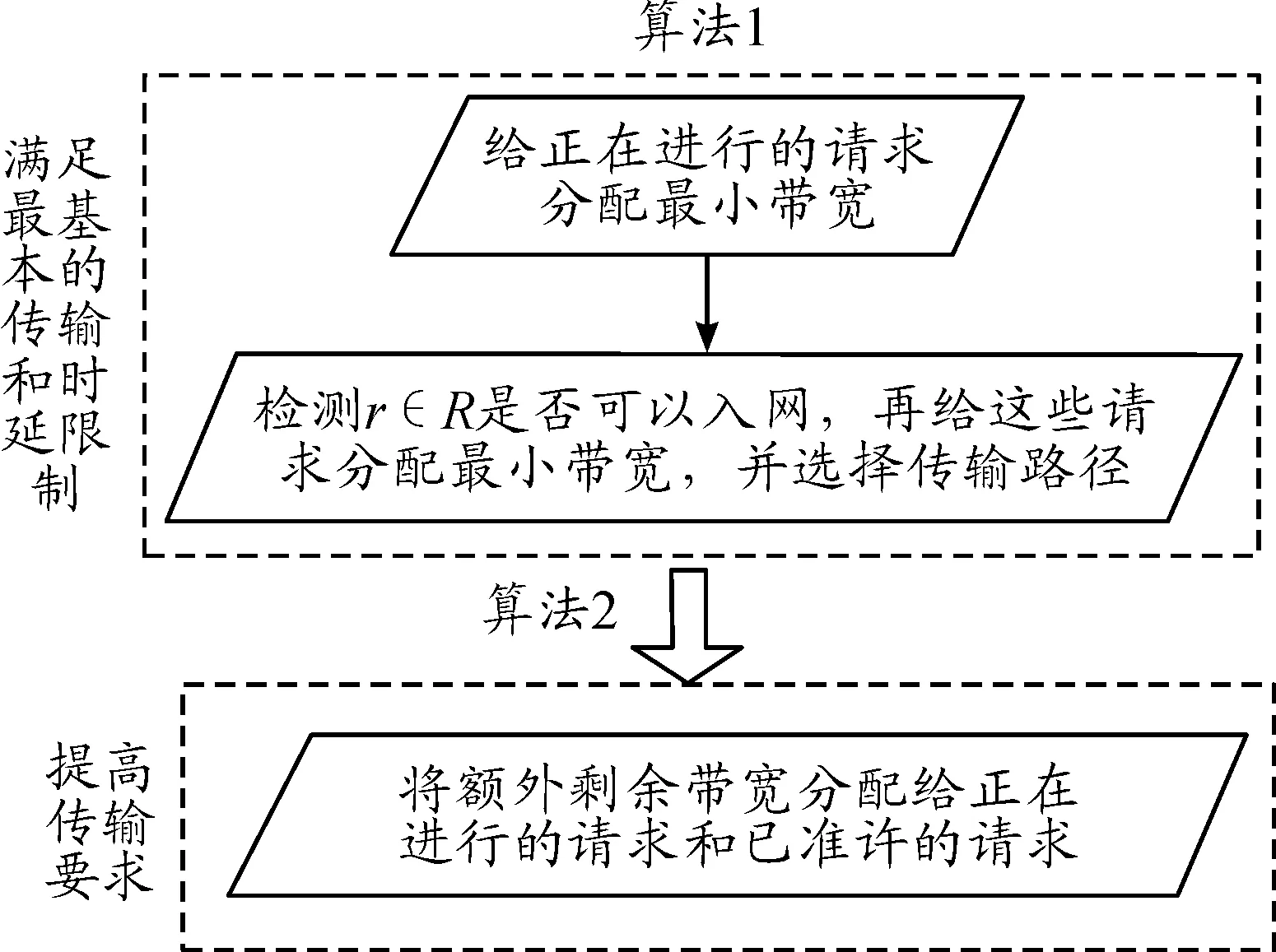
图1 FBA-BDT算法的两个子算法框图
2.1 算法1
具体而言,在给定正在进行的传输请求数和网络状态时,算法1目的就是给每条准许的请求选择一条合适的路径,并分配最小的带宽,进而完成数据的传输。
(7)
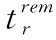
(8)
式(8)中,er表示请求r拥有的剩余时隙数;ts是时隙的时长。
然后给已准许的请求R中的每条请求决策传输数据的路径,进而满足截止时期tr,如算法1的Step5至Step14,为每个请求r的可选路径计算最小剩余带宽。假定可选路径Pr,1、Pr,2的最小剩余带宽分别表示为CPr,1、CPr,2。

图2 算法1的伪代码
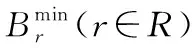
(9)
如果请求r能够获取更高带宽的路径,即满足式(10),则准许请求r入网,并选择更高带宽的路径Pr传输数据。否则拒绝r入网。
(10)
完成算法1后,就构成已准许的请求集Rad。综上所述,算法1的执行流程如图3所示。
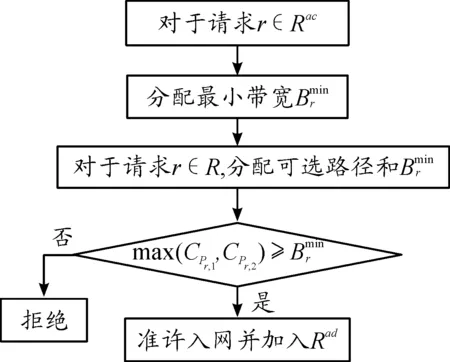
图3 算法1的执行流程框图
2.2 算法2
完成了第一阶段后,基于可用的剩余带宽[8-9],第二阶段试着将额外的带宽分配给已准许的Req和正在进行的Req,进而完成数据的传输,提高资源效率。
算法2的伪代码如图4所示。在给定Rad和Rac条件下,算法2就将额外带宽分配给这些请求,使它们能够在截止日期前完成数据传输。对于请求r,首先迭代计算路径Pr上所有链路,进而完成在每条链路上能够获取的额外带宽。对于链路l∈Pr,所分配的额外带宽zr,其正比于每条请求所需要传输的数据量,表示为:
(11)
迭代完毕后就可计算分配请求r的带宽,即:
(12)
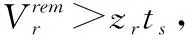
(13)

图4 算法2的伪代码
3 性能分析
3.1 仿真环境
仿真过程中引用ESnet拓扑[5]。网络由58个节点组成,其中23个节点是流量Hubs,而余下的35个节点为流量产生节点。每个流量产生节点能够以10 Gbit/s数据率产生数据。假定连接58个节点的所有链路具有10 Gbit/s的容量。每条请求所传输的数据量在[1,20]GB内随机选取。每条请求的传输截止时限在[40,300]s。每个时隙的时长为40 s。此外,由于数据传输时延是秒量级,忽略传播时延[10-11]。
为了更好地分析FBA-BDT算法的性能,选择拒绝请求率、每个时隙传输的平均数据量和每个时隙每条请求所分配的平均带宽[12-13]。其中拒绝请求率等于拒绝的BDTRs数与已准许的BDTRs数之比[14];每个时隙传输的平均数据量等于在总仿真时间内的总时隙内传输的平均数据量;每个时隙每条Req所分配的平均带宽等于在总的时隙数、总的已准许的BDTRs内,给已准许的BDTRs所分配的带宽。
此外,比较最小带宽分配(Minimum Bandwidth Allocation,MinBA)、最大带宽分配(Maximum Bandwidth Allocation,MaxBA)策略。MinBA策略在满足时限要求下,给每条准许BDTRReq分配所需的最小带宽,并维持此带宽,直到数据传输完毕。而MaxBA策略是分配可用的最大带宽。
3.2 数据分析
3.2.1 拒绝请求率
图5显示了拒绝请求率随请求到达率的变化曲线。相比于MaxBA和MinBA算法,FBA-BDT算法的拒绝率得到了有效控制。即使在糟糕的情况,FBA-BDT算法的拒绝率比MaxBA和MinBA算法也分别提高82%、40%。换而言之,MinBA算法拒绝40%的Req被FBA-BDT算法接收。
FBA-BDT算法的最佳拒绝率比MaxBA和MinBA算法分别降低了88%和98%。这些数据表明给请求自适应分配带宽比采用固定策略分配带宽,能够有效地降低拒绝请求率。
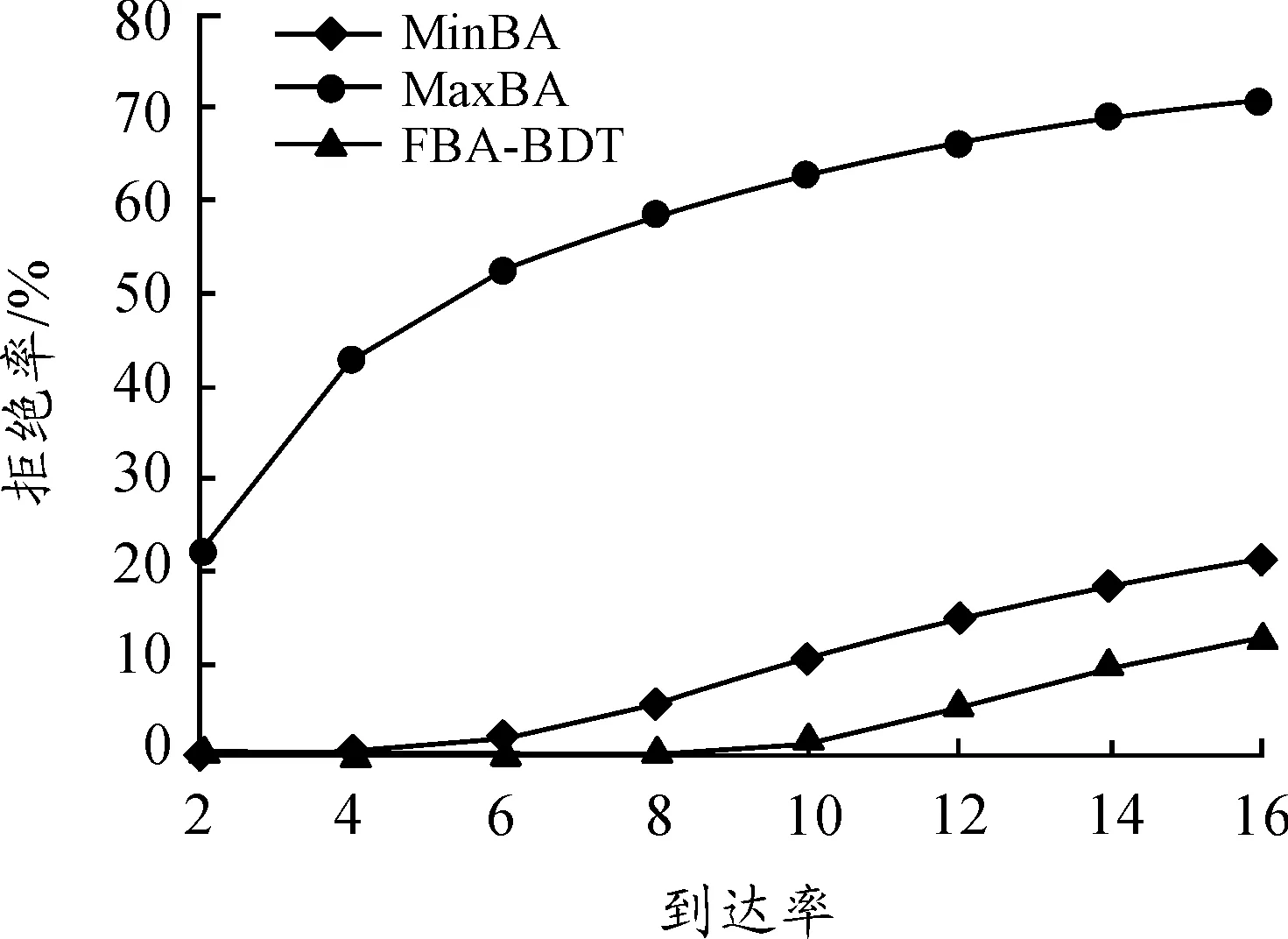
图5 拒绝请求率
3.2.2 每个时隙传输的平均数据量
图6显示每个时隙传输的平均数据量随请求到达率的变化曲线。从图6可知,在每个时隙的请求到达率为16个BDTRs时,FBA-BDT算法能够每时隙传输高达142 GB,而MaxBA和MinBA算法只能够传输50 GB和125 GB。换而言之,利用FBA-BDT算法,网络每天能够传输和处理约300 TB的大数据,这几乎是Large Hadron Collider的4倍。

图6 每个时隙传输的平均数据量
3.2.3 每个时隙每条请求所分配的平均带宽
图7显示了每个时隙每条请求所分配的平均带宽随Req到达率的变化曲线。从图7可知,MaxBA和MinBA算法在到达率变化期间给所有请求分配相同的带宽。而FBA-BDT算法给请求分配的带宽随到达率的增加而逐渐减少。原因在于:当到达率低时,有额外可用带宽分配给这些请求。而当到达率增加时,额外可用带宽随之下降。
此外,FBA-BDT算法可提高资源效率。在低到达率时分配更多带宽给请求,可提高带宽利用率,也使得请求在截止日期前完成数据的传输。
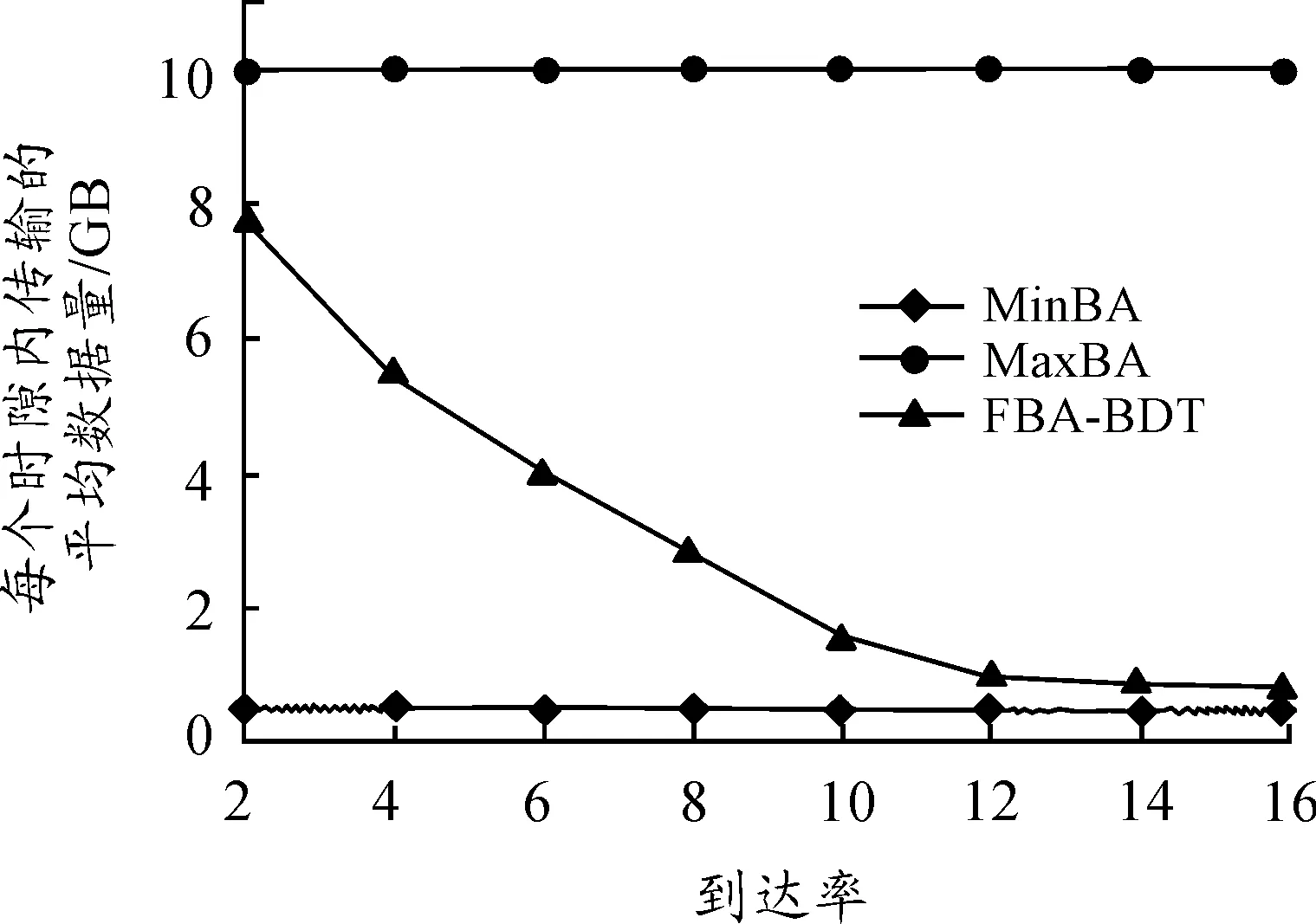
图7 每个时隙每条请求所分配的平均带宽曲线
4 结论
本文基于传输请求时限条件下,分析了利用自适应分配带宽的大数据传输问题,进而最大化请求接收率。提出的FBA-BDT算法先建立目标函数,再利用启发式算法求解目标函数。实验数据表明,提出的FBA-BDT算法有效地降低了请求拒绝率,并提高了数据量。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
数字技术与应用(2022年7期)2022-08-03
移动通信(2021年5期)2021-10-25
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
舰船电子对抗(2020年2期)2020-06-23
科学与技术(2018年23期)2018-06-17
科技创新导报(2016年27期)2017-03-14
山东工业技术(2016年5期)2016-03-04
科技与创新(2014年11期)2014-08-21
