
基于特征融合及子空间学习的行人再识别
2019-07-12 06:23:46李大湘费国园
西安邮电大学学报 2019年2期
李大湘, 费国园, 刘 颖
(1. 西安邮电大学 通信与信息工程学院, 陕西 西安 710121;2. 电子信息现场勘验应用技术公安部重点实验室, 陕西 西安 710121)
在多摄像机监控网络中,利用行人再识别技术[1]可实现目标行人跟踪或异常场景检测,从而服务于智能安防和刑事侦查[2-3]。受光照、遮挡、姿势和杂乱背景等因素干扰,行人外观通常会发生变化,所以,行人再识别的重点主要在于特征提取和度量学习[4]。
在特征提取方面,有局部特征集成(ensemble of localized features,ELF)[5]、对称驱动的局部特征累积(symmetry-driven accumulation of local features, SDALF)[6]、局部最大概率(local maximal occurrence,LOMO)特征[7]、分层高斯方法利用高斯块的高斯区域(Gaussian region of Gaussian patch,GOG)描述符[8]等方法。其中,LOMO特征是HSV颜色直方图和尺度不变局部三元模式(scale invariant local ternary pattern,SILTP)纹理特征的高维表示,而GOG描述符则将图像分为由多个高斯分布描述的不同区域,以刻画行人图像的颜色和纹理等信息。每种高斯分布代表一个图像块,每个图像块的特征融合后得到行人图像的特征向量。
除了欧氏距离和马氏距离外,用于行人再识别的距离度量学习方法还有许多[9],如交叉视图二次判别分析(cross-view quadratic dis-criminant analysis, XQDA)[7]、成对特定CRC编码(pairewise-specific collaborative representation based classification coding,PSCRC)[10]、多核全监督子空间学习(multi-kernel fully-supervised subspace learning,MKFSL)[11]等方法。其中,MKFSL方法能有效利用行人图像,通过学习产生一个有辨别力的子空间,先利用有标签样本的GOG特征学习初始投影,再利用该投影将无标签样本映射到低维空间中,但是,因未能充分利用标签样本,往往会引发行人图像表征单一化或模型浮动。
为了进一步充分利用带标签样本,本文拟从特征融合和子空间学习两方面,对MKFSL行人再识别算法加以优化。以串联融合后的LOMO特征和GOG特征,描述行人图像,弥补单一描述符表征行人图像的局限性。挑选典型带标签样本,来学习优化的判别式投影,避免模型浮动问题。
1 特征提取与融合
1.1 局部最大概率特征
LOMO是特征包含颜色特征和纹理特征。考虑到光照对颜色信息的影响,先对图像利用带颜色恢复的Retinex算法(multi-scale retinex with color restoration,MSRCR)[12]进行预处理,再对其进行HSV颜色直方图特征提取。针对摄像机中的行人目标视图变化问题,采用纹理特征SILTP对行人图像进行描述。

1.2 高斯描述符
采用GOG特征对行人图像作进一步描述。
将行人图像调整为128×48像素,对每张图像进行有重叠的分块处理,分为7个大小为32×48像素的水平区域。对各水平区域进行稠密块采样,采样间隔为2像素,各稠密块的大小为5×5像素。对稠密块中各像素提取8维像素特征,包括像素点的垂直位置、梯度值以及颜色信息等。
用高斯分布拟合稠密块内的像素特征,再用另一高斯分布拟合水平区域内所有稠密块的特征。拼接所有水平区域内的特征向量,所得27 622维特征向量即为GOG特征。
拼接所提取到的LOMO特征向量GOG特征向量,即为行人图像的特征向量。
2 子空间学习
引入子空间学习,将原始特征空间中线性不可分的数据,映射到区分能力更强的低维子空间,对这种映射关系的设计是子空间学习的关键。
选择全监督的子空间学习方法[11],学习一个判别式子空间。选定n张带标签的行人图像,以其特征向量分别描述为xi∈d(n=1,2,…,n),记其相应的标签为yi。学习平方距离函数
(1)
其中,U∈d×r,是一个低维投影矩阵,可将不同摄像机视图中的行人图像映射到一个公共子空间,从而进行有效的行人再识别[11]。r(≪d)是投影子空间的维数。
如果xi和xj属于同一人,也即yi=yj,则其距离函数值较小,反之较大。最优低维投影矩阵可以表示为

(2)
其中,X=(x1,x2,…,xn),而权重矩阵W∈n×n的元素
(3)
利用迹操作,可以将损失函数L(X,U,W)重新改写为tr (UTXLXTu)。其中,L是一个对角矩阵D与权重矩阵W之差,即
L=D-W,
而D对角线上的元素是W对应行之和。增加约束
tr (UTXLXTu)=1,
通过广义特征值分解,即可求得最优低维投影矩阵U*,它由r个最小特征值对应的相关特征向量组成。通常取r=n-1。
得到优化的投影矩阵U*之后,将测试样本的探测图像和候选集图像特征投影到该空间中,通过计算两者的马氏距离,得出一个有序列表,据此即可计算出得人再识别的匹配率。
3 实验分析
3.1 行人再识别数据集
实验选取VIPeR数据集和PRID450s数据集。
VIPeR数据集[13]包含632个行人的1 264张户外图像,其大小被统一标准化为128×48像素,整个数据集被均等一分为二,一半用于训练,一半用于测试。
PRID450s数据集[14]更接近现实,包含由两个摄像机捕从不同视角所捕获的450对图像,其大小不一,但光照强度一致。
3.2 实验设置及评估准则
采用配置64位操作系统、Intel i7处理器的联想电脑,利用软件Matlab2015a进行实验。选用累积特征匹配曲线(cumulative match characteristic curve,CMC)作为评估准则。CMC曲线是模式识别系统的重要评价指标,用以计算前k次匹配到目标样本的概率。比较待查找样本对象与候选集样本间的距离,从小到大排序。查询到的同一行人样本越靠前,则相应算法性能越好。为了统一处理数据,将各数据集图像的大小均预调整为128×48像素,再进行特征提取。
3.3 结果分析
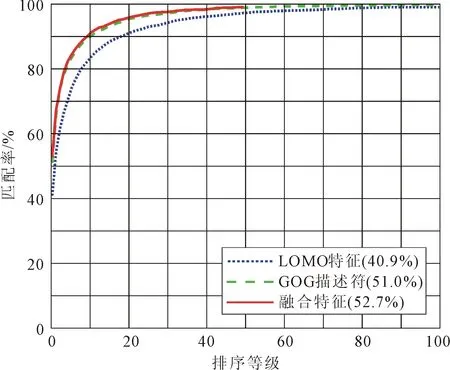
串联融合LOMO特征和GOG特征,并结合改进的子空间学习方法,在数据集VIPeR和PRID450s上进行10次实验,对其结果取平均,所得CMC曲线图如图1所示。其中排序等级代表具有较大相似度目标的个数。
基于像素点提取的GOG描述符,相较基于滑动窗提取的LOMO特征,前者对应的匹配曲线明显要高,而其融合特征对应的匹配曲线最高。融合特征可避免单一特征在描述行人图像方面的局限性,在行人再识别时的1级匹配率更高。
(a) VIPeR

(b) PRID450s
在两个数据集上,所给改进算法与其他行人再识别算法的实验结果分别如表1和表2所示。
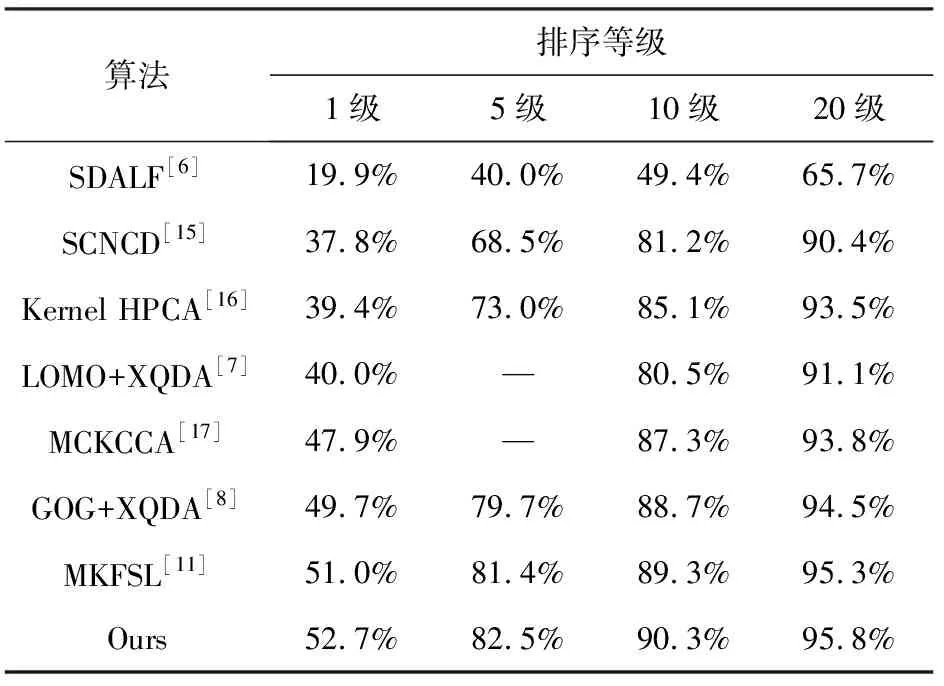
表1 VIPeR数据集上不同算法的匹配率
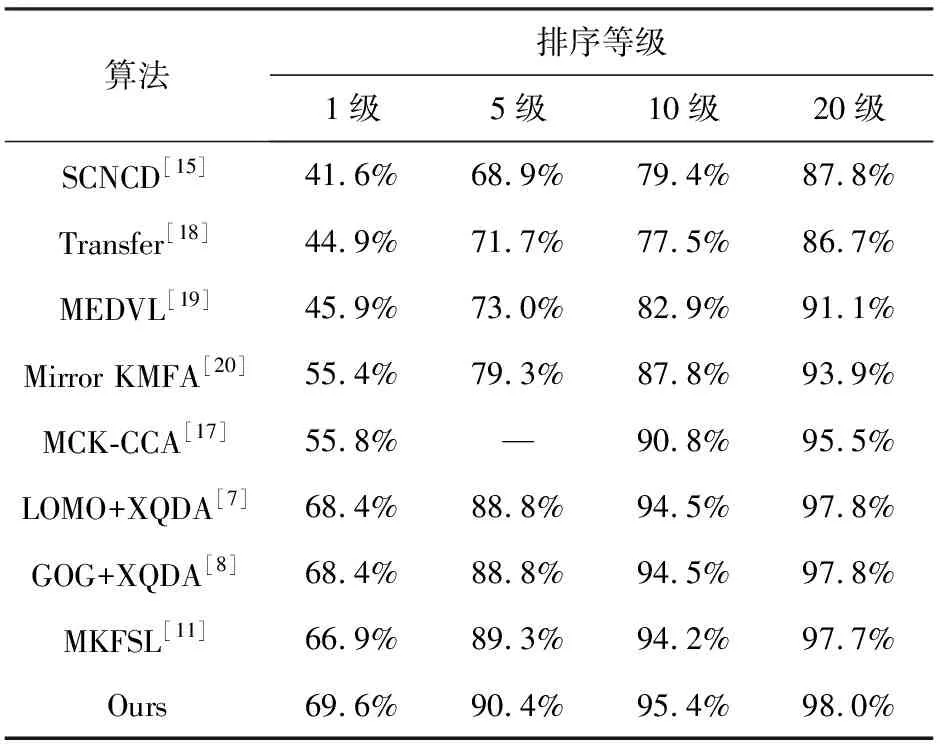
表2 PRID450s数据集上不同算法的匹配率
改进算法融合了两种鲁棒性的描述符以描述行人图像,并引入了子空间学习方法求得的判别性投影矩阵,具有良好的匹配性能。与原MKFSL算法相比,在数据集VIPeR和PRID450s上,改进算法的1级匹配率分别提高了1.7%和2.7%。
4 结语
为了充分发挥带标签样本的可用性,给出一种改进的MKFSL行人再识别算法。融合LOMO特征和GOG描述符以表征行人图像,有效降低了光照、视角及摄像机参数等外界因素所带来的影响。利用低维投影矩阵,将所提取的特征映射到低维子空间中,使之表现出可区分能力更强的特点,更有利于准确地实现行人再识别。实验结果显示,所给改进算法可行有效。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
意林(2021年5期)2021-04-18 12:21:17
数学物理学报(2021年1期)2021-03-29 03:14:42
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
学生天地(2019年15期)2019-05-05 06:28:28
扬子江(2019年1期)2019-03-08 02:52:34
许昌学院学报(2018年4期)2018-05-02 12:27:37
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
