
基于公共空间视频的人脸情绪识别
2019-07-11 03:44:28卿粼波周文俊熊文诗滕奇志
安徽工业大学学报(自然科学版) 2019年1期
王 露,唐 韬,卿粼波,周文俊,熊文诗,滕奇志
(1.四川大学电子信息学院,四川成都610065;2.上海交通大学电子信息与电气工程学院上海200030)
情绪识别作为计算机视觉领域的研究重点之一,具有广泛的应用前景。目前对情绪的研究主要利用人脸序列开展,因为人脸情绪是人们表达情感状态最具表现力的非语言渠道之一。随着我国城市化进程的推进,城市大数据由传统的手机信令、互联网定位数据逐渐过渡到由图片和视频构成的城市公共空间新型大数据,新型大数据包含的关于人的信息也更丰富。因此,利用从公共空间视频截取的人脸表情序列分析基于公共空间的人群情绪可为城市公共安全评估、居民幸福感预测提供可靠信息,为城市规划研究者提供有效参考。如何制作基于城市公共空间的人脸表情数据集并进行人脸情绪识别是亟待解决的问题。目前,人脸情绪识别主要采用传统方法和基于深度学习的方法。传统的人脸情绪识别主要采用隐马尔可夫模型(hidden markov model,HMM)、支持向量机(support vector machine,SVM)、Adaboost算法。钟岩[1]利用局部二值模式(local binary patterns,LBP)提取人脸图像的特征,输入至嵌入式隐马尔可夫模型(EHMM)对人脸表情进行分类;Liu等[2]利用Gabor算子对面部表情进行局部特征融合,再利用SVM分类器进行人脸情绪分类;Gudipati等[3]利用Adaboost和Haar建立级联分类器对表情数据集进行情绪识别。上述方法在人脸情绪识别上均取得了一定效果,但由于公共空间场景的复杂性,且不同环境下人工选择面部表情特征存在差异,传统方式获得的模型参数对使用环境要求较高,对本文研究的适用性不强。
2006年,Hinton等[4]提出了深度学习理论,将多个抽象的数据处理层组合构成计算模型代替传统的人工选择特征方法,可避免人工选择特征的缺陷。卷积神经网络(convolution neural network,CNN)[5]是一种前馈神经网络,也是深度学习中最典型的模型之一,其已成功应用到大型图像处理与识别任务中且取得了非凡成就。针对视频中人脸情绪的识别,李勇等[6]采用改进的LeNet-5网络进行面部情绪识别;Zhang等[7]利用多信号卷积神经网络提取人脸图像的静态特征,使用另一网络提取表情序列的动态特征,最终融合得到情绪分类。长短期记忆网络(long short term memory network,LSTM)[8]是一种时间递归神经网络,适用于处理时间隔和延迟较大的视频序列,目前已有多项研究将LSTM应用到人脸情绪识别中。Kankanamge等[9]利用多个LSTM网络结合局部二值模式提取人脸特征进行情绪识别;Yu等[10]采用3DCNN提取图像序列面部表情的时空特征,再利用嵌套的LSTM网络进行动态特征建模,实现人脸情绪的识别。上述情绪识别研究取得了较好的识别效果,但研究对象均为公开人脸数据集如JAFFE[12]、CK+[13]等,此类数据一般是实验者在特定环境中根据要求做出指定表情然后借助设备拍摄得到。而公共空间视频场景复杂多变,包含的人群信息更为丰富,且视频是在人们无意识的情况下获取,人们的面部表情更能反应其真实的情绪状态。因此,文中提出一种双流卷积网络模型对公共空间视频中的人脸情绪进行识别,以期有效识别每类情绪。
1 基于公共空间表情数据集的制作
人脸表情识别常用的数据集有JAFFE、CK+、AFEW[14]等。JAFFE和CK+数据集均包含7种情绪,JAFFE数据集有213张图片,CK+数据集为表情序列,有593个图像序列。JAFFE和CK+中的数据都是在实验环境下采集得到的,数据样本单一,不适用于研究公共空间视频中的人脸表情,且这两个数据集的规模较小,利用深度学习方法进行训练时易出现过拟合。AFEW是视频情感识别大赛(emotion recognition in the wild challenge,EmotiW)采用的数据集,数据量大,视频背景多样,但该数据集截取自电影片段,面部情绪是根据情节需要而表现,不代表真实情感状态,且AFEW的情绪分类不能完全适用于本文研究。公开数据集的情绪一般有7~8类,划分较为细致。由于人们在公共场所具有一定的自我形态意识,公共空间视频中人们的表情变化不如公开数据集丰富夸张。因此参照Zhang等[11]提出的面向公共空间视频的4种情绪,即Bored、Excited、Frantic和Relaxed为文中的数据集制作标签。
采用现场拍摄和网上收集的方式建立基于城市公共空间的人脸表情数据集,制作过程包括3个步骤。
1)人脸表情序列的提取 利用MeanShift算法[15]跟踪单人人脸,提取视频中分辨率较高的人脸表情序列。
2)人脸表情图像预处理 采用Li等[16]提出的SURF级联法进行人脸检测,提取有用的人脸区域,然后对序列进行灰度化处理,降低原始图像中背景杂质的干扰。
3)建立情绪标签邀请8名志愿者(4男4女)观看视频序列,根据Arousal-Valence情感平面中的Arousal和Valence分量值[11]描述他们看到的情绪状态;取8名志愿者对每个视频序列标记的两个分量值求平均,对序列进行打分;根据视频序列的Arousal和Valence分量值在Arousal-Valence情感平面中的位置得到序列的情绪标签。人脸数据集的具体制作流程如图1,为保证隐私图中人脸已经打码。

图1 数据集的制作流程Fig.1 Production process of dataset
建立的人脸数据集分为3个部分:训练集、验证集和测试集,视频序列个数分别为855,163,180。验证集用于完成训练阶段的测试,当训练数据完成一次迭代后,利用验证集对该阶段的训练效果进行评估;测试集用于对训练好的模型进行测试,验证模型的准确率。为保证最终实验的可靠性,每个数据集中4种情绪的视频数量基本相同。与公开数据集相比,本文数据集的限制更少,更具有通用性。
2 基于双流网络的人脸情绪识别方法
2.1 感受野分析
公共空间中视频分辨率相对有限,制作的人脸数据集质量不高。若只采用单一尺寸的视频帧作为网络输入,则会因图像分辨率较低而导致对人脸表情特征的提取力度不够。一个强大的动态表情识别网络应能够描述多层次的视觉特征,既需捕捉局部视觉内容,也需对全局视觉信息进行把握,以提高特征提取的丰富度,最终提高情绪识别的效果。文中利用不同分辨率的表情图像作为网络输入,利用不同感受野(receptive field)包含不同尺度的特征信息这一优势进行表情的图像特征提取,提升整个网络的识别精度。
神经网络中,感受野是指CNN的每一层输出特征图(feature map)上的像素点在原图像上映射区域的大小。利用CNN提取特征时,大的感受野表示其能接触到的原始图像范围大,意味着包含更为全局、语义层次更高的特征,训练时的模型参数也更多;小的感受野表示其包含的特征越趋向局部和细节,能更有效地提取局部细微的特征,训练时的模型参数也较少。为更直观地说明不同感受野下提取特征的区别,图2给出了不同感受野示例,虚线框中为采用同样卷积核操作时的感受野。图2(a)中的感受野能覆盖唇部1/2的面积且包含部分唇部周边信息,图2(b)中的感受野只能覆盖唇部1/3的区域且几乎不包括唇部周边信息。

图2 不同尺度下的感受野示例Fig.2 Receptive field examples at different scales
为说明感受野在CNN中的计算过程,图3给出了关于CNN感受野的实例。假设输入图像大小为5×5,卷积核大小为3×3,步长s为1×1,填充大小为1×1,进行卷积操作后得到右边大小为3×3的特征图。感受野中心为特征图中每个特征对应输入图像的中心位置,感受野的大小对应输入图像的区域大小。
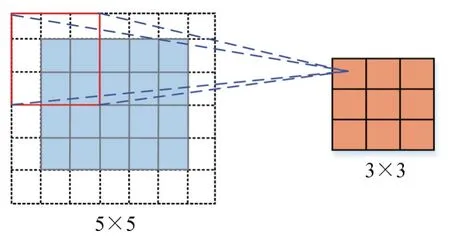
图3 CNN感受野示例Fig.3 CNN example of receptive field
2.2 双流网络模型的建立
为提升本文制作数据集的识别准确率,结合2.1节感受野的相关特性,提出基于双流网络的人脸识别框架,如图4。图中人脸情绪识别框架由两通道卷积网络构成,第一通道Channel 1(C1)中,视频帧尺寸固定为224×224,利用CNN网络对单帧人脸表情序列进行训练,学习面部表情在粗分辨率下的静态特征;第二通道Channel 2(C2)中,图像序列以固定尺寸336×336输入CNN网络,学习面部表情在精细分辨率下的静态特征,再将获取的特征送入LSTM网络用于学习序列的动态特征;最后将两通道训练得到的模型进行加权融合,用于最终的分类测试。C1通道的输入为单帧图片,C2通道的输入为图像序列。

图4 基于双流网络的人脸情绪识别框架Fig.4 Facial emotion recognition framework based on two-stream network
经对比分析,采用VGG16[17]作为基础CNN网络,用于提取静态特征。VGG16 net有13个卷积层,卷积核的大小均为3×3,步长为1,整个网络包含5个最大池化层、2个全连接层。该网络的深度与结构满足本文人脸情绪识别的需求。本文C2通道网络使用了一个LSTM网络层,VGG16与LSTM的连接方式如图5:在VGG16的最后一个池化层后接入一个全连接层fc6,fc6的输出响应为4 096维;在fc6后面连接LSTM网络提取图像序列的动态特征,LSTM网络的输出为128维;紧接着全连接层fc7,其输出响应为4维,表示本文进行的是四分类;最后在fc7后接入一个softmax层,对fc7的输出特征进行分类。

图5 VGG16与LSTM的连接方式Fig.5 Connection mode between VGG16 and LSTM
3 实验与测试
3.1 网络训练及情绪识别的评价标准
根据建立数据集的实际情况,若利用所提双流网络直接对表情图像进行学习,训练模型的效果会不理想,因此借助在公开数据集上预训练得到的模型对本文网络微调。通过对比表情识别领域中的众多预训练模型,选定基于AEFW 6.0[18]数据集训练得到的VGG-Face作为两通道网络的预训练模型。AEFW 6.0数据集的表情序列均从电影片段中截取,部分视频背景为户外场景,与本文数据采集环境相似,适用于模型的预训练。微调阶段,为避免过拟合,在每一个全连接层后加入Dropout层,Dropout_ratio设置为0.5。参考文献[19]的方法,采用准确度(accuracy,ACC)和宏平均精度(macro average precision,MAP)作为情绪识别效果的评价标准。
3.2 实验设置
基于Python的深度学习框架Caffe环境下进行实验,计算机配置为Intel Core i7-7700@4.2 GHz,NVIDIA GeForce GTX 1070,操作系统为Ubuntu 14.04。实验中两通道网络的参数设置如表1,除初始学习率(base_lr)和每个序列视频的输入帧数(frame)不同之外,学习率变化指数(gamma)、网络动量(momentum)、学习率衰减策略(lr_policy)、权重衰减量(weight_decay)、最大迭代次数(max_iter)的设定一致。

表1 实验参数设定Tab.1_ Setting of experimental parameters
为评估双流网络人脸情绪识别的性能,进行3组实验:利用C1通道网络进行训练,测试分类效果;利用C2通道网络进行训练,测试分类效果;对C1和C2两通道得到的训练模型加权融合,测试分类效果。权重主要根据训练过程中模型在验证集上的准确率而定,模型的融合公式为

其中:W224和W336分别为C1、C2通道的权重;分别表示第i类情绪的识别精度;Si为模型融合后第i类情绪的识别精度。
3.3 实验结果分析
3.3.1 融合实验
为验证本文模型的有效性,给出单独使用C1,C2训练模型后在测试集上的ACC和MAP;然后给出两通道网络以不同权重比进行融合获得的分类效果,两通道网络的识别效果如表2。从表2可看出,C2通道的训练效果比C1通道更好,说明高分辨率图像使模型学习到表情序列局部细节信息,获得更为丰富的视觉特征,也证明结合CNN与LSTM网络能获取更好的训练效果。C2比C1学习的内容更丰富且C2的分类效果比C1的好,在进行模型融合时着重考虑增加C2比重后的模型效果。因此将C1,C2权重比分别设置为5∶5,3∶7,1∶9,以选择最优权值。表2表明,权重比为1∶9时的测试效果最好,ACC为88.89%,MAP为88.75%,高出其他测试结果5%~9%。

表2 人脸情绪识别的ACC与MAPTab.2_ ACC and MAPof face emotion recognition
为证明两通道网络性能互补,利用图6所示的混淆矩阵展示双流网络对4种情绪的分类效果。图6(a)是C1通道模型对4种情绪的分类结果,可以看出C1通道网络对excited和frantic的分类效果最好,主要是因为这两类情绪的面部表情变化较大且训练样本包含序列的所有图片,CNN网络能有效学习输入数据的特征。由于人类个体差异,人们在表达bored和relaxed两类情绪时面部表情的变化幅度不一,采用CNN网络进行单帧训练的效果会不太理想。图6(b)中4种情绪的分类结果较好且各类别的准确度差距不大,表明将CNN与LSTM相结合学习序列在不同感受野下的视觉特征是可行的。图6(c)为C1与C2权重比为1∶9时的分类效果,除bored以外的其他情绪均取得了较高的分类精度,bored被误判为relaxed的概率较大,因为bored与relaxed两类情绪的区别没有excited和frantic明显,易出现误判。

图6 人脸情绪识别结果的混淆矩阵Fig.6 Confusion matrix of face emotion recognition results
3.3.2 识别性能
本文人脸情绪识别数据集标签与应用场景及现有数据集的均不同,无法与公开数据集进行实验对比。为验证本文方法的优势,参照文献[20-21],将C2通道的序列输入分别改为常规尺寸224×224、低分辨率尺寸128×128进行网络训练;参照文献[22]采用Alexnet网络训练C1通道网络。不同方法的人脸情绪识别效果如表3。从表3可看出,本文提出的双流卷积网络模型对基于公共空间的人脸情绪数据集识别效果最好,ACC和MAP比已有方式分别提升7%~28%,7%~29%,结合本文数据集的特点证明了本文方法的优越性与通用性。

表3 不同方法的识别结果Tab.3 Recognition results of different methods
4 结语与展望
针对基于公共空间中的人脸情绪识别,建立本文适用的人脸表情数据集,提出双流网络进行人脸情绪识别,两通道分别以不同分辨率的图像输入网络进行训练,以多尺度学习不同感受野下的表情特征;最后将两通道得到的训练模型进行加权融合,用于测试分类。多组实验证明,提出的双流模型具有较高的人脸情绪识别率,ACC和MAP最高可达88.89%和88.75%。整个网络能在较大程度上识别公共空间中的人脸情绪,可为城市规划研究者提供有力的参考依据。本文的人脸表情数据集已取得初步成效,但仍存在数据量不足、清晰度不够等问题,后续将进一步完善和丰富数据集内容并在合适的时机公开,同时改善网络性能,将更好的研究成果应用于智慧城市规划中。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
动漫星空(2018年9期)2018-10-26 01:17:14
风流一代·青春(2018年2期)2018-02-26 15:27:06
风流一代·青春(2017年6期)2018-02-14 19:28:55
风流一代·青春(2017年5期)2018-02-14 09:32:37
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
商业评论(2014年6期)2015-02-28 04:44:25
发明与创新(2015年33期)2015-02-27 10:40:09
