
基于数据驱动的标签分布方法的面部表情分析*
2019-07-11 07:29王士同
计算机与生活 2019年7期
谢 磊,王士同
江南大学 数字媒体学院,江苏 无锡 214122
1 引言
人脸表情识别是指从特定的表情状态判别被识别对象的心理状况,实现计算机对人脸表情的理解与分析。进而,从根本上改变人与计算机之间的关系,改善人机交互体验。因此,人脸表情识别也逐渐引起关注。一般而言,人脸表情识别方法主要按照图像预处理、特征提取(或降维)、分类的流程实现表情识别。主要侧重于如何利用先验知识更好地提取特征和进行特征表达,再结合分类器作进一步的优化。有许多方法已在表情分类方面得到使用,例如:基于人工神经网络(artificial neural network,ANN)的方法[1],基于支持向量机(support vector machine,SVM)[2]的方法,基于概率论的贝叶斯分类的方法[3]以及基于隐马尔可夫模型(hiddenMarkovmodel,HMM)[4]的方法。作为单一表情识别问题,在以往的研究中已经达到了不错的准确度。
然而,由Plutchik的情绪理论[5]可知,面部表情的情况可类似于颜色,所有颜色均由三原色混合而成,表情同样是由几种基础表情情绪合成。有少量基本情绪,所有其他情绪均由这些基本情绪以组合、混合或复合形式出现。当然,这些基本情绪的强度不尽相同。可设定一个表情中所有情绪的强度之和为1,则每个情绪强度在0~1之间,那么情绪强度指标可通过各个基础情绪的数值进行描述表达。反观那些只识别表情单一情绪的标签学习方法,则有很大的局限性,在现实场景中不能很好适用。事实情况也是如此,大多数时候人脸的面部表情通常包含了较为丰富的内容,表达着多种情感。另一方面,同一表情的情绪状况也存在差异。例如开心这一表情类别,微笑属于其范畴,开怀大笑也同样属于。图1给出了一组开心表情的示例。很明显,即使是同一表情,在视觉效果上也存在较大差异。随着情绪表达的增强,从微笑到大笑呈现出序列状。
对于以上情况,可以考虑将每个基本情绪认为是一个标签,则多标签学习(multi-label learning,MLL)[6]可以用来描述每个表情图像与其相关的情绪。MLL可首先选择一个阈值,然后将分数高于阈值的情绪标记为相关情绪,而其他标记为无关情绪。那么相关情绪可设为1,不相关情绪设为0。但是,这种方式使得所有相关的情绪都被视为同等重要。因此,关于基础情绪强度的重要信息丢失了,不能很好地表示出每种情绪的强度。
针对以上问题,本文提出了一种数据驱动的情绪标签分布方法(data-driven emotion label distribution method,D2ELDM)。不同于传统方法,该方法认定表情由多种基础情绪混合而成,且允许每种情绪有不同强度。具体来讲,首先通过稀疏子空间学习发掘表情样本的相关结构,然后将上下文结构合并到标签分布[7]模型中。接下来算法将自适应地从样本结构所保留的数据中学习不同表情的相关性,进而获得自身所包含的基础情绪的强弱状态。图2构建出了一个样本的标签分布状况。从图中可以明显看出,每个样本的标签分布模型都是具体的。也就是说,不同面部样本的标签分布由面部样本本身以及同它相关的表情结构来确定。总的来讲,本文算法通过情绪强度信息对表情进行描述分析,比单一表情分类更切实合理。同时,通过数据驱动构造的标签分布更加灵活真实。

Fig.2 Obtaining emotion label distribution adaptively图2 算法自适应获得表情标签分布
2 相关工作
2.1 表情情绪分析
表情识别分析一般作为标签预测问题解决,可以总结以往的一些工作。在结构构建方面,Ni等人[8]通过结合所有相关的样本来获得映射函数,从而在这个映射空间中传递它们的标签。在面部特征表示方面,由于面部区域具有规则的纹理信息,之前的一些方法通过构建纹理特征(例如LBP(local binary patterns)[9]、Gabor[10]和 AAM(active appearance models)[11])来表示面部外观。与直接使用面部区域图像提取特征的这些方式相比,最近的研究考虑了面部器官之间的相关性。例如,Guo等人[12]提出了生物启发的特征。他们首先将脸部图像分割成许多局部区域,然后通过“空间金字塔模型”的方法提取面部特征。同时,表情区域特征[13]的重要性也逐渐得到关注。另一方面,一些人脸识别通过设计各种深层神经网络来提取面部特征。这些方式[14-15]的优点主要是可以捕捉到较多区别性的视觉信息。同样,本文在对样本特征进行提取时也会使用到已有的深度学习框架。
2.2 子空间聚类
要达到自适应学习样本相关结构的目的,子空间学习目前是基于图形数据聚类算法中一个重要且有效的方式。
稀疏子空间聚类(sparsesubspaceclustering,SSC)[16]是聚类高维数据(如图像和视频)的典型方法。其基本思想是每个样本可以通过几个其他样本的线性组合进行重建。因此,SSC方法根据样本之间所在的环境结构关系,将所有原始样本都嵌入到相应的局部流形子空间中。许多研究人员通过在子空间学习中添加各种约束来提高聚类性能,如低阶约束[17]、轨迹拉索约束[18]和混合高斯噪声约束[19]。最近,李等人[20]通过将发掘出的上下文结构跟数据聚类组合成一个统一的框架来解决SSC问题。
在实际应用方面,SSC技术被广泛用于解决各种图像或视频处理问题。例如,Tierney等人[21]假定视频中每帧均可由在时间上相邻的其他视频帧进行重建。为此,他们首先为时间上相邻的视频帧添加平滑约束,再通过将SSC运用于视频中的每一帧实现了对视频的分段。最近,Cao等人[22]将SSC扩展到多视图图像聚类中,先使用Hilbert-Schmidt范数来限制不同视图之间的相关性,之后迭代地对每个视图求解SSC。虽然比较流行的学习方法[23-24]和子空间学习方法都能够捕获样本的环境结构,但它们在表情识别中的作用是不同的。现有的这些方法使用多元学习提取图像特征,而本文的方法使用子空间学习来构建标签分布。
3 D2ELDM算法框架
本章中,将对数据驱动的情绪标签分布方法进行详尽描述,例如问题分析、公式定义及推导、具体计算过程,并在最后汇总出算法的整体框架。为了方便理解和阅读,在表1中总结了本文使用的符号集合。
下面是对文中向量及矩阵方面的一些说明,定义x(i)表示为x的第i个元素,同样,将X(i,j)表示为X的第i行,第j列的元素。此外,分别定义XT、X†、为X的转置矩阵、逆矩阵、F范数、1范数。
3.1 通过公式对问题进行定义
首先需要对现有数据进行处理,取得一组人脸表情样本S{(xn,yn),n=1,2,…,N},其 中xn∈RD×1和yn分别表示第n个样本的图像特征向量和情绪标签。可以对yn分别取1~7,其对应的情绪分别为“开心”“难过”“惊讶”“恐惧”“愤怒”“厌恶”“中性”等。为了方便表示,将标签设置为1到T,来表示不同的情绪。接下来,使用标签分布的方式来代替传统单一表情的表达方式。符号表示方面,用pn∈RT×1定义为第n个人脸样本的标签分布,其中pn(t)表示第n个人脸样本中第t种情绪的强度状况。

Table 1 Detailed description of variables表1 符号描述表
下面,通过求解回归优化问题的方式来学习图像特征xn和标签分布pn,n=1,2,…,N之间的映射关系,可得出如下公式:

其中,f(·)表示映射函数。对于式(1)的求解,需要通过增加正则项来提高其泛化性。由于样本特征维度较高且数值大于样本量的数值,通过加入范数的方式来控制其稀疏性及复杂性。最后,人脸表情分析的预测模型可构建成一个线性回归的形式:
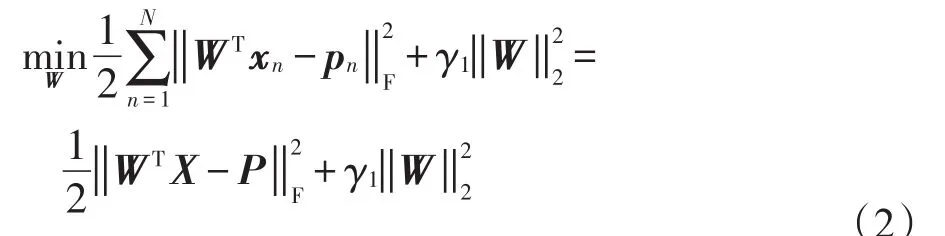
式中,用W∈RD×T作为回归矩阵来表示映射函数f(·)。其中γ1是平衡参数,来调控正则项。通过W的第t列(wt)来预测人脸样本的第t个情绪标签的情况。
下面将逐步描述出对标签分布P的构造过程。与传统的one-hot编码[25]对人脸表情标记不同(在one-hot编码模式中,每个人脸样本的表情仅由单个标签进行标记,用1或0进行唯一表示)。但通过分析观察得知,一些具有相似图像特征的面部样本的标签集合却不相同。因此,人脸表情的识别不仅由其自身的标签确定,而且还受其相关面部环境(由视觉上相似的面部样本构成)的影响。一般而言,探索人脸样本之间的环境结构问题通常被转化为子空间结构学习的问题[16,19-20,26]。
在这里,首先构造图形矩阵C∈RN×N来捕捉面部的环境结构。为了得到图矩阵,使用“样本自我表达”[16]这一方式来构建优化函数,可定义为如下公式:

公式中通过最小化第一项来进行样本的“自我表达”,第二项的β是控制C的稀疏度的参数。通过把对角线设为0,对样本的自我描述进行限制,不能描述自身。由此可见,式(3)表明每个人脸样本都可由其面部结构环境中的其他样本进行线性重建。


显然,以上方式确保了所得的亲和度矩阵非负且对称。
亲和图所表达出的样本之间的相关性,也即说明了面部样本不仅与其自身表情标签相关,同样会受到一些在视觉上相似的面部样本的标签的影响。因此,常常会导致预测标签同自身标签有出入。根本原因是人脸面部表情自身包含多种不同强弱的基础情绪,这也是提出的面向数据的标签分布的依据。
由此可见,如若每个面部样本相对应的标签同时来源于自身的one-hot编码以及与其视觉上相似的面部样本的标签情况,那就可以用标签分布更加灵活真实地描述人脸表情样本的情绪状况。因此,这种标签分布方式可以对具有多种情绪的表情样本进行编码标记。
首先,构造出样本的多标签矩阵Y∈RT×N,则Y(:,n)表示Y的第n列,再结合前面给出的yn表示第n个样本的情绪标签,那么Y可通过如下方式得到:
步骤1构造0向量Y(:,n);
步骤2如果yn=t,则Y(t,n)=1。
在Y的基础上,构造样本的标签分布矩阵P∈RT×N,其中第n列也即第n个样本的标签分布用pn表示。则数据驱动的标签分布pn可通过如下形式 得到:
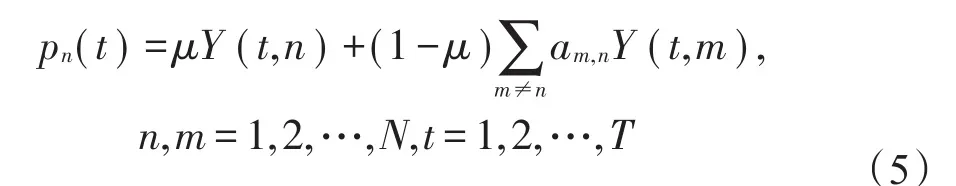
其中,μ∈[0,1]是一个权衡参数。第二项描述了第n个样本的合成标签分布,它是通过其他表情样本与第n个样本之间的关联度进行构建。其中,am,n表示第m个样本和第n个样本之间联系紧密度的因子。显然,式(5)表明,每个人脸样本的情绪标签分布都是通过自身情绪标签与其面部环境样本的加权线性组合构成的一个离散分布。给出其对应的矩阵表示公式,如下:

其中,am,n与亲和图A(m,n)相对应。
最后,可以将联合优化问题的完整形式写成如下公式:

式中,λ、γ1、γ2均为平衡参数。
3.2 算法过程
首先,分别通过SSC算法和线性回归的方式对C和W进行初始化。然后,可以通过交替迭代的方法实现对D2ELDM的优化。
3.2.1 已知W对C进行迭代计算
在求解计算方面,由于存在对矩阵取绝对值的情况,则考虑先去掉绝对值,再使用迭代更新来对C进行优化。首先定义C1为C1=(|C|+C)/2,C2为C2=(|C|-C)/2。那么可以通过C=C1-C2的方式来简化目标函数,很明显C1、C2为两个非负矩阵。接下来可定义Cτ=|C|+|CT|,那么Cτ可用(C1+C2+C1T+C2T)进行表示。
替换后,式(7)可以被写为如下形式:

下面,分别为约束项C1≥0和C2≥0引入拉格朗日乘子Ψ1和Ψ2。然后得到拉格朗日函数:

下面则按照标准的求解过程分别对C1和C2求导数,得到如下公式:
使用KKT条件Ψ1(n,m)C1(n,m)=0及Ψ2(n,m)C2(n,m)=0,可得到关于C1、C2的等式,具体内容如下:

下面,可以通过以下方式对C1和C2进行更新:

获得C1和C2的收敛值后,通过以下步骤获得C的解:

3.2.2 已知C对W进行计算
在求得C之后,可通过式(6)构建标签分布P,继而转换式(8)为以下公式:

接下来,按照常规方式,可对式(15)取其对wt的导数,并置零得到:

最终,可以得到如下结果:

因此,通过计算式(17)便可得到回归矩阵。最后,对于整个算法来讲,可以通过设置迭代次数来控制计算状况。
3.3 对测试集中人脸表情进行分析
在通过学习算法获得回归矩阵W之后,便可以预测出面部表情样本的情绪标签分布,进而判定其主要表情,以及其内在的各种情绪强弱情况。标签分布可用以下公式获得:

其中,xq为测试样本向量,为样本的情绪标签分布状况。通过对分布状况可视化等方式,可以直观得到表情的具体结果。最后,整理出人脸情绪分析框架的具体过程。具体过程如下:
算法1数据驱动的情绪标签分布方法
输入:人脸图像特征X∈RD×N及表情标签Y∈RT×N。
输出:人脸表情情绪分布。
1.初始化
通过稀疏子空间聚类算法初始化C
通过线性回归方式初始化回归矩阵W
2.迭代计算
While迭代终止条件未满足
2.1 通过式(13)和式(14)更新C
2.2 通过式(4)计算邻接图矩阵
2.3 根据式(6)更新标签分布
2.4 更新回归矩阵W:
对于W的第t列wt,执行以下操作:wt=(XXT+γ1I)†XP(t,:)T
End迭代终止
3.测试数据集中表情的情绪标签分析
根据式(18)获取标签分布,即得到样本情绪的具体状况。
4 实验
4.1 实验环境
本文所有实验均在同一环境下完成,采用在Windows 7环境下搭建系统,计算机处理器配置为Intel®CoreTMi3-4150 CPU@3.5 GHz,内存4 GB,主算法在Matlab2017b下完成。
4.2 数据库及处理
CK+数据库[27]:该数据库在美国卡内基梅隆大学机器人研究所和心理学系共同建立的人脸表情库(Cohn-Kanade AU-coded database,CK)基础上,于2010年进行扩展而来。是人脸表情数据库中比较流行的一个。如文献中描述,数据库共包含123人的593个图像序列,其特点在于人脸样本的表情强度逐渐递增,表情呈现连续性变化。例如,从微笑逐渐连续转为大笑,更适合算法对其表情强度进行分析。文中选取时注重保留各个表情的强度序列状况,最后一共筛选出640张图片,其中“开心”“难过”“惊讶”“恐惧”“中性”的情绪样本都为30,“愤怒”“厌恶”的样本量为21。
JAFFE数据库[28]:该数据集是日本ATR人类信息处理研究实验室和日本九州大学心理学系建立的日本女性人脸表情数据库(Japan female facial expression,JAFFE)。数据库共包含10位年轻日本女性的213幅表情图像,表情类别为6种基本表情和中性表情。数据库样本相对精简,但表情区分度较高,不同表情之间差异明显,也即单个情绪比较强,可以更全面测试算法性能。
自制数据库(Mydata):为刚好验证算法实用性,本文结合身边人员做了一个小型数据库。选取三男三女同学对表情取样,表情选取同以上数据库相同,每人7类表情,每个表情3张样本,共计126张样本图片。
实验数据库样例在图3中给出。

Fig.3 Sample images of databases图3 表情库样本
实验中,首先需要对图片中的人脸进行识别选取,之后,面部样本的特征提取通过Caffe工具箱[29]中的AlexNet网络[30]实现,需要注意的是,在对样本使用框架时,需要对图片大小进行调整来适应网络输入层,同样需要对样本微调后再进行特征提取。使用AlexNet的“relu7”层输出作为面部图像特征,该层为网络输出层前一层,较好保留了样本特征。另一方面,通过随机初始化的方式来预设网络参数,然后应用标准反向传播方法来优化这些参数。
4.3 参数设置
一般可设置μ=0.5,对于目标函数中的参数来讲,设置λ=0.5,γ1=0.1,参数γ2的数值可采用SSC[16]中方法获得。同时,本文对目标函数中参数也尝试了多种不同的组合进行实验,发现本文方法在相对较宽的参数值范围内实现了较为稳定的性能。选取CK+数据库做展示,使用不同参数对样本进行实验,发现准确率在小范围内波动,结果在图4中给出。

Fig.4 Accuracy by different parameters图4 不同参数实验结果
4.4 算法实验结果
实验时取数据集的70%作为训练数据,剩余图片样本则作为测试集。需要注意的是,选取数据时需要在各表情里进行随机选取,保证各表情在训练集中都有取到。本文所有实验结果为多次实验后取众值所得。下面各表中第一列表示验证数据的对应标签,后面每行表示预测得到的结果情况。在各表的最后给出其综合识别率,也即整体正确率。表2是JAFFE数据集实验结果,其中测试数据集有64个样本,恐惧表情有10张,其余皆为9张。很明显,其在“惊讶”“恐惧”“愤怒”等表情有很好的识别效果,但在中性表情类别的实验结果表现欠佳,有3张被识别为了恐惧。平均识别率为78.13%。表3为自制数据集实验结果,在平均识别率方面优于表2,为82.86%。
同前两个数据集实验结果不同,表4中实验结果具有较大提升,综合识别率为96.88%。因为CK+数据集在数据量上更大,且表情情绪具有更强的连续性,范围更为广泛。可以发现在这种情况下,结果有了很好的改善。随着数据量增大,以及表情连续性的增强,样本在构建邻接图时有更为广泛的选择空间,根据所选图片构造出的标签分布更为合理真实。结果显示,大多表情识别率均达到100%,但在测试结果中可以看出,有部分“愤怒”表情被识别为“厌恶”。参见图5给出的样例,不难发现他们的脸部特征具有很高相似性,例如眼睛微闭、嘴角侧拉、眉心紧皱等方面。这些相似状况会给表情的识别带来干扰,看似相似的表情,些许微妙的变化便会导致其表达情绪形成较大差异。同时,根据图5所给的标签分布状况图可看出,本文算法对于此类状况在“愤怒”和“厌恶”情绪都给出了较高的估值。

Table 2 Experimental results of JAFFE表2 JAFFE数据库识别结果

Table 3 Experimental results of Mydata表3 Mydata数据库识别结果
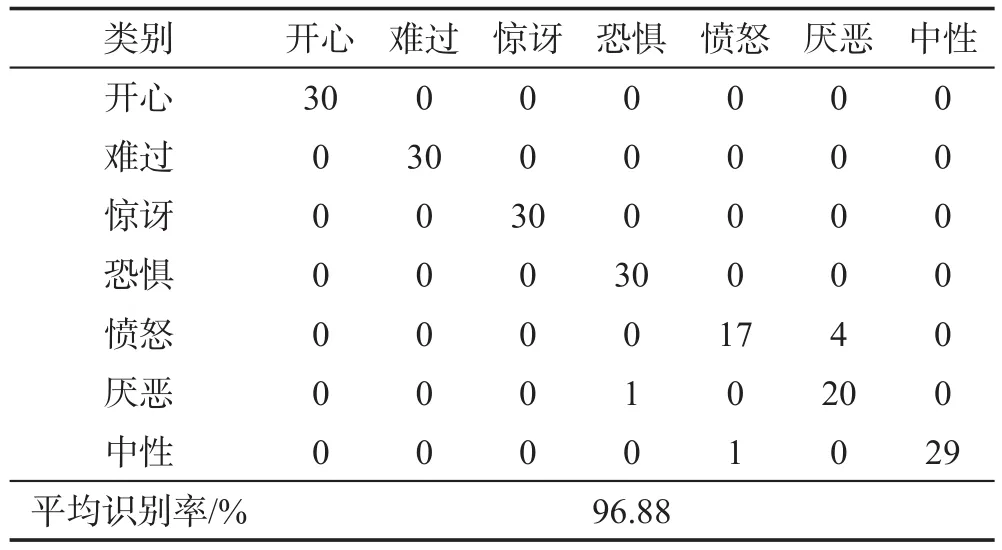
Table 4 Experimental results of CK+表4 CK+数据库识别结果
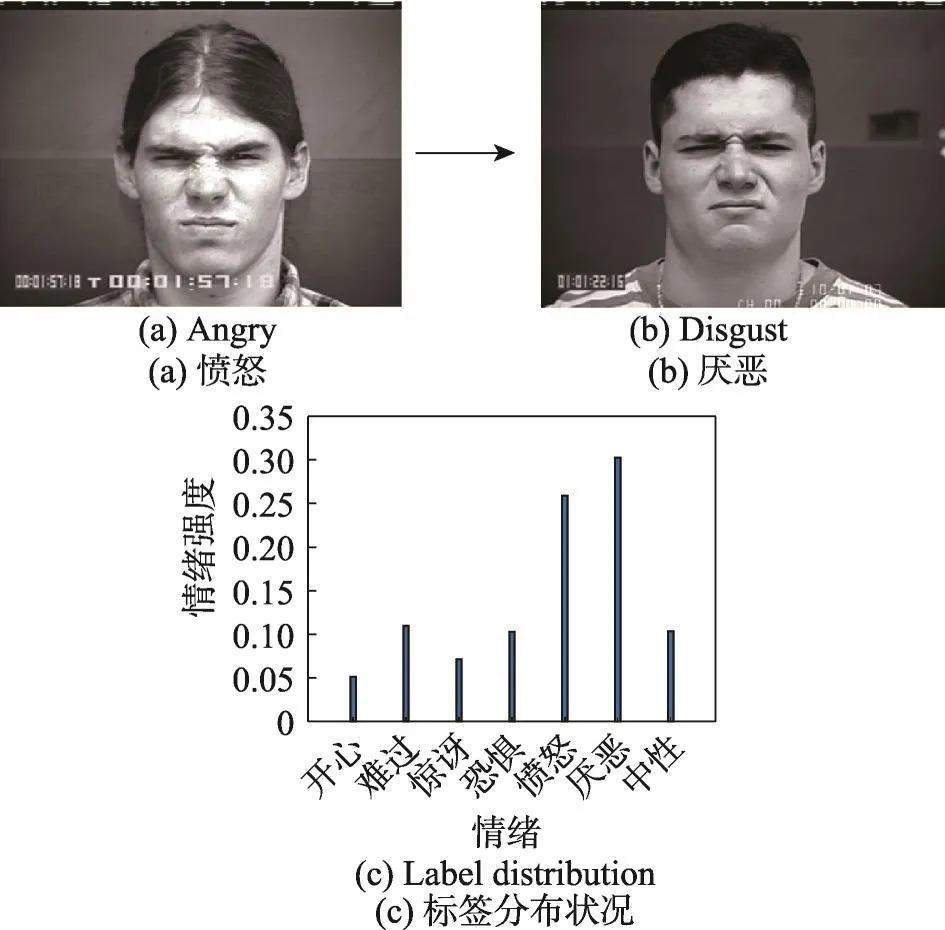
Fig.5 Angry expressions are misidentified as disgust and emotion description degree图5 愤怒表情被错误识别为厌恶样例及其情绪描述度
本文算法可以很好地对表情进行分析,在识别准确率上也有很好的表现。为此,本文选取不同算法与本文方法进行比较,例如一些经典算法SVM[31]、KNN(K-nearest neighbor)[32]、AdaBoost(adaptive boosting)[33]、RF(random forest)[34]、改进算法(least squares twinK-class support vector classification,LST-KSVC)[35],以及较为火热的深度学习中的AlexNet[30]。表5给出了其与以上算法在识别率上的对比情况,可以看出本文算法在识别率上有着不错的表现。图6给出了部分样例的识别图示,竖轴的数值(如同引言所讲,总值为1,各个情绪强度为0到1之间)可表示基础情绪的强度情况,可看出本文算法在实际场景的表情分析方面具有良好的应用价值。

Table 5 Accuracy of different algorithms表5 不同算法准确率比较 %

Fig.6 Emotion analysis图6 表情分析实例
5 结束语
针对人脸表情的复杂丰富性,本文提出了一种基于数据驱动的表情标签分布方法。通过数据集中人脸的相似特征构造邻接图,从而得到每个样本自身的表情标签状况。与其他的表情识别算法不同,本文算法可以在保证较好识别率的情况下,分析出样本表情所包含的基础情绪的强度,在视觉上更加直观地显示出样本表情的内在信息。实验结果表明,本文算法在对表情的预测及分析方面都有不错的表现。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
读与写·教育教学版(2017年10期)2017-11-10
Coco薇(2015年11期)2015-11-09
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
