
基于国产GPU的GLSL编译器设计∗
2019-07-10 08:18彭获然熊庭刚胡艳明
计算机与数字工程 2019年6期
彭获然 熊庭刚 胡艳明 黄 亮
(武汉数字工程研究所 武汉 430205)
1 引言
在图形处理器不断发展的过程中,图形应用对可编程能力的需求日益增长,高级着色语言应运而生。开发者通过使用高级着色语言编写着色器来自定义发生在图形处理流程中关键处的处理过程,利用底层的图形硬件实现更多样复杂的渲染效果[1]。图形驱动中的着色语言编译器便承担起编译着色器的任务,并在图形渲染管线中扮演重要角色,其生成的机器代码的质量会直接影响图形渲染的效果和效率。
2 GLSL和OpenGL中的着色器
GLSL 是OpenGL 规范中用来编写着色器的高级着色语言,其语法源于C 语言,二者的源码非常相似,这使得着色器的编写和阅读对于有C 语言基础的开发者来说更加容易。在OpenGL 2.0中,开发者可使用GLSL version1.10 编写顶点着色器和片段着色器程序。图1 展示了应用程序中OpenGL 着色器的执行模型,应用程序通过OpenGL API 中的函数调用编译器对着色器源码字符串进行处理,得到可执行机器码。
3 GLSL编译器设计
本文的GLSL 编译器的流程如图2 所示。其前端包含预处理、词法分析、语法及语义分析和中间代码生成;其后端包含代码优化和链接,最终生成目标机器代码。编译器前后端之间使用一种标准的中间表示形式进行过渡,便于使用相对成熟的机器无关的优化技术[2]。

图1 OpenGL着色器执行模型
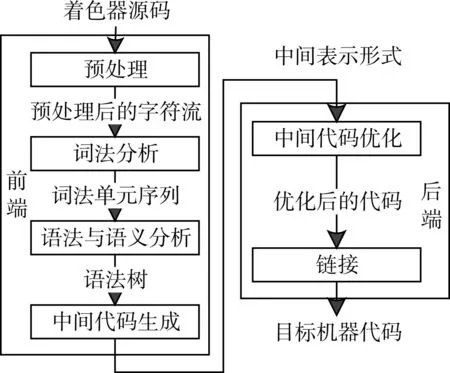
图2 GLSL编译器流程
3.1 GLSL编译器前端设计
GLSL编译器前端负责读入着色器源码并生成基于中间表示形式的中间代码。首先前端根据GLSL 的预处理指令对着色器源码进行预处理,包括宏定义的替换和条件编译部分源码的删减等。GLSL 的预处理指令的功能和使用方法与C 语言类似,存在少量区别(如没有#include 指令等),在GLSL的官方文档中有详细说明[3]。
3.1.1 词法分析
GLSL编译器前端的核心部分包含词法分析和语法语义分析。词法分析器读入预处理后生成的字符流,剔除其中的注释部分并组织成有意义的词素序列;对于每个词素,词法分析器产生词法单元作为输出,包含行号信息、词素类型及词素的值,词素类型有标识符、操作符、关键字、常量以及空白符。其中标识符、操作符和关键字的值为其字符串,常量的值即为其本身的值,空白符没有值。本文使用开源的Flex工具根据GLSL的词法规则生成词法分析器,其工作流程如图3所示。
使用Flex来生成词法分析器时,需要用正则表达式(Regular Expression,RE)这一强大的符号表示法来描述目标语言的字符模式[4]。描述GLSL 的标识符的代码如下所示,标识符由字母、下划线和数字组成且开头不能是数字:
identifier{nodigit}({nodigit}{|digit})*
nodigit [_A-Za-z]
digit [0-9]

图3 Flex和词法分析器
常量(包括八进制、十进制、十六进制的整数和浮点数)也用类似的方法描述其模式,空白字符和操作符采用逐个列举的方式,关键字则使用关键字列表从标识符中区分出来。
以图4 中这段顶点着色器源码example.vert 为例,经词法分析会生成如下词法单元序列(行号信息在此省略):(关键字 ,“attribute”),(关键字,“vec4”),(标 识 符 ,“my_Vertex”),(操 作 符 ,“;”)……(标识符,“gl_Position”),(操作符,“=”),(标识符,“my_TransformMatrix”),(操作符,“*”),(标识符,“my_Vertex”),(操作符,“;”),(操作符,“}”)。

图4 顶点着色器源码示例example.vert
3.1.2 语法分析与语义分析
在词法分析完成后,语法分析器获得一个词法单元序列,根据GLSL的语法识别其中的语法成分,并验证其结构可以由GLSL 的语法生成,否则进行错误处理。此外,语法分析器还需要检查前述序列是否符合GLSL的语义,例如类型是否匹配,被使用的变量是否已定义等;若着色器语法语义正确,语法分析器将根据着色器中的语句构造语法树,语法树中的每个内部节点表示一个运算,而该节点的子节点表示该运算的分量[5]。本文所述编译器的语法分析器采用开源的Bison 工具生成,其工作流程如图5所示。
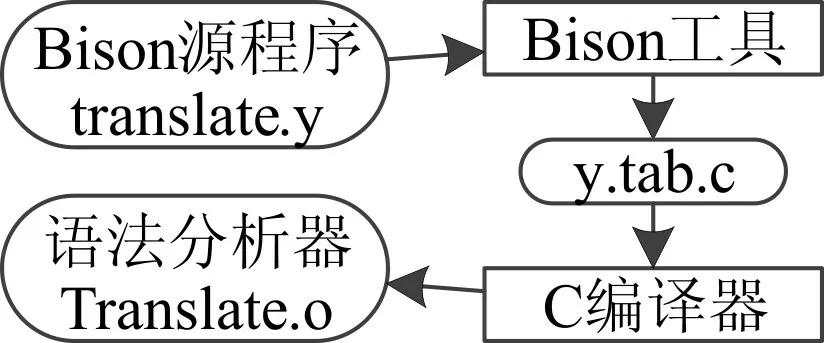
图5 Bison和语法分析器
使用Bison 生成语法分析器时,在Bison 源程序中使用LALR(1)语法来描述目标语言的语法规则[6]。图6 是Bison 源程序中描述语法规则的部分片段,包括动作函数的参数类型定义,终结符定义,变量标识符的模式和相应动作。着色器的词法单元序列会在语法分析器中匹配到具体的语法范式,并执行该范式对应的动作函数,完成着色语言程序语法树的创建。

图6 Bison程序片段
以example.vert为例,经过语法分析后得到图7所示的语法树,同时生成名字信息表(部分名字信息表见表1)。

表1 部分名字信息

图7 example.vert的语法树
由于三地址代码拆分了多运算符算术表达式以及控制流语句的嵌套结构,比较适用于目标代码的生成和优化,故本文所述编译器采用三地址码作为中间表示形式。对于GLSL,三地址代码中的地址可以是属性(Attribute)、一致变量(Uniform)、着色器中明确定义的变量、输出变量(Output)、临时变量和常数。
首先将语法分析器输出的语法树转换为三地址代码语法树,转换的过程中需要根据目标GPU平台的指令集作一些变换。以图7 语法树为例,由于目标GPU 平台的乘法指令只支持标量或四分量向量作操作数,故将矩阵乘法拆分为多条向量乘法和加法指令,得到如图8所示三地址代码语法树。
接下来通过深度优先遍历三地址代码语法树可得到如表2 所示的三地址代码中间表示形式,中间表示可输出到文本文件中方便调试(注:表2 中OP 代表操作符,DST 代表目的操作数,SRC 代表源操作数)。

图8 三地址代码语法树

表2 三地址代码中间表示形式
3.2 GLSL编译器后端设计
GLSL 编译器后端读入中间代码,由代码优化模块负责对其优化,通过改进中间代码,以达到生成更好的目标代码的目的。链接模块则要完成链接树的创建,并根据链接树来分配物理寄存器资源并设置相应寄存器模式,最终生成符合GPU 指令集的目标机器代码。
3.2.1 优化
优化部分分为机器无关的优化和机器相关的优化。本文所述编译器采取的机器无关代码优化方式包含:死代码消除,函数展开,常量传播,冗余判断消除,公共子表达式消除,循环展开和代码移动等较为成熟的中间代码优化技术[7~10]。
而针对所用国产GPU 的SIMD 指令集架构,本文采取的机器相关代码优化包含乘加指令优化和向量指令合并。具体如下。
1)乘加指令优化:由于目标机器的指令集包含乘加指令,且着色器一般包含大量乘法和加法运算,乘加指令优化将大大提高程序的性能;如果一条加法指令只依赖之前的一条乘法指令,且乘法指令的目标使能与加法指令一致,相应的乘法指令和加法指令可以被合并成一条乘加指令。
例如MUL R0 R1 R2
//R0 ←R1*R2
ADD R3 R4 R0
//R3 ←R4+R0
两条指令若满足条件可优化为
MAD R3 R1 R2 R4
//R3 ←R4+(R1*R2)
2)合并向量指令:目标机器的指令集基于向量指令,提高向量指令的利用效率是代码优化的重要目标;对于多条具备相同指令码的指令,如果其相应操作数可分配到同一向量寄存器上而不影响运算结果,便可合并为一条向量指令,向量指令合并可降低代码长度同时减少寄存器使用量[11]。
例如:[x,y,0,0]←[a,b,0,0]+[c,d,0,0]
[0,0,z,w]←[0,0,e,f]+[0,0,g,h]
两条语句可以合并为:
[x,y,z,w]←[a,b,e,f]+[c,d,g,h]
example.vert 的三地址代码经过优化之后,用伪代码表示如表3 所示,指令数量得到明显的精简。
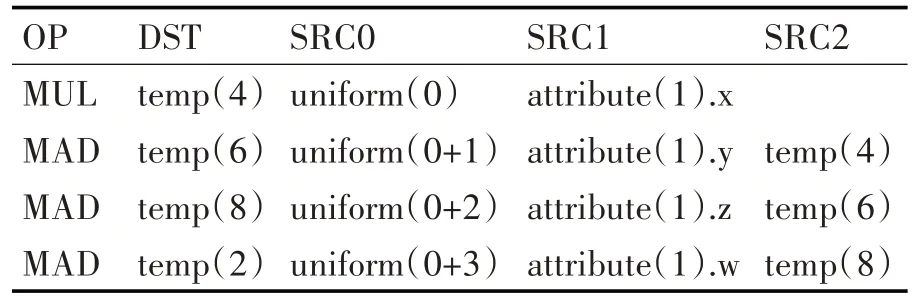
表3 优化之后得到的代码
3.2.2 链接
目标机器码的链接由链接器完成,链接器负责链接树的创建,并根据链接树来分配国产GPU 中的物理寄存器资源并设置相应寄存器模式,最终生成符合国产GPU 指令集的目标机器代码。链接器的工作主要有两方面要求:生成高效率的目标机器代码和有效地利用目标机器上的可用资源。
由于只涉及寄存器运算分量的指令要比那些涉及内存运算分量的指令运行快得多,而GPU 的寄存器资源又非常有限,因此如何提升寄存器资源的利用效率成为链接阶段的一个重要工作内容。如果一个变量的值存放在寄存器中,而之后一直不会被使用,那么这个寄存器就应该被分配给另外一个变量[12]。表4 简单地展示了寄存器分配的这一基本思路(其中uniform(0)为矩阵,由连续四个寄存器按顺序分别存储一列元素,各列使用相对寻址访问),相对于表3 减少了三个临时寄存器占用而不影响程序结果。
为了有效利用寄存器资源,需要综合考虑函数调用及循环嵌套,记录属性、变量和输出的使用信息以及各条指令代码的启示性信息,包括当前代码属于哪个函数体,当前代码调用者,当前代码最深的函数嵌套层次,当前代码对应的临时寄存器的后续使用信息[13~14]。

表4 example.vert程序寄存器分配示意
链接器最后需要输出目标机器代码。国产GPU 的指令集包括常用算术运算,超越函数计算,流程控制和纹理操作等。指令集支持一个目的操作数和三个源操作数。源操作数可以任意取反或取绝对值;指令支持源操作数和目的操作数的任意分量选择;目的操作数可设置饱和操作;指令支持相对寻址模式。为了更好地契合国产GPU 的指令集架构,且保证代码转化的灵活性,本文采取模式匹配的方法生成机器代码[15],具体步骤如下:
第一步,将指令指针IP 设置到中间代码起始位置;
第二步,模式指针PP 设置到目标模式起始位置;
第三步,判断模式对应指令数是否大于剩余未转换的中间代码,若是,进入第四步;否则进入第五步;
第四步,模式指针PP 设为下一模式起始位置并重复第三步;
第五步,从模式指针PP和指令指针IP开始,逐条判断各指令是否匹配,若模式得到完整匹配便生成该模式对应的机器指令代码并进入下一步,否则执行第四步;
第六步,指令指针增加已匹配模式对应指令数,若所有中间代码已完成匹配,结束流程,否则执行第二步。
4 实验与结果
本文使用如图9 所示的顶点和片段着色器对编译器进行基本功能测试。
顶点着色器经编译器处理得到如表5 所示伪代码。
片段着色器经编译器处理得到伪代码如表6所示。
应用程序输出渲染效果如图10 所示,说明着色器经编译器编译可正常工作,验证了编译器的基本功能。

图9 测试用着色器

表5 实验顶点着色器优化后伪代码

表6 实验片段着色器伪代码

图10 渲染效果
5 结语
本文根据GLSLv1.10的特点,借助Flex与Bison工具设计了GLSL 编译器的前端;以三地址码作为中间表示使后端可以应用多种成熟的机器无关代码优化技术,并针对国产GPU 平台的SIMD 指令集架构应用乘加指令优化和向量指令合并进一步优化代码;最终链接生成目标机器代码。该编译器可将GLSLv1.10 编写的着色器编译成该国产GPU 平台上可执行的代码,为国产GPU 对OpenGL 规范的支持做出了一定的贡献,由于对应的版本相对落后,与今天商用平台的仍有很大差距,今后仍需进一步拓展编译器功能,以支持更高版本的GLSL,同时继续深入研究编译过程中的优化技术,以提高输出机器码质量。
猜你喜欢
计算机研究与发展(2021年3期)2021-04-01
计算机应用(2020年5期)2020-06-07
计算机与网络(2019年9期)2019-10-21
计算机研究与发展(2019年4期)2019-04-18
电子技术与软件工程(2018年1期)2018-03-22
科技经济市场(2017年5期)2017-09-16
科技视界(2014年24期)2014-04-22
中学生英语高效课堂探究(2011年4期)2011-07-07
群文天地(2011年14期)2011-04-20
现代电子技术(2009年8期)2009-06-25
