
基于深度学习的主题资源监测采集功能实现研究
2019-07-08 02:27刘艳民张旺强祝忠明陈宏东
图书与情报 2019年2期
关键词:深度学习
刘艳民 张旺强 祝忠明 陈宏东


摘 要:文章构建了基于深度学习的主题资源监测采集模型,并利用深度学习词向量工具word2vec对收集的语料进行深度训练,对采集资源与主题模型进行相似度匹配,通过设定合适阈值来实现自动化监测主题资源。实践证明:基于深度学习的定主题监测方法在海洋战略研究所信息监测系统的应用过程中,在主题资源自动监测的准确性上效果优于传统基于向量空间模型的监测算法,能为专题知识库和领域情报信息监测系统的构建打下坚实的基础。
关键词:深度学习;主题资源监测;word2vec;相似度计算
中图分类号:G202 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2019035
Research on the Realization of Theme Resource Monitoring and Collection Function Based on Deep Learning
Abstract Theme open knowledge resource acquisition is usually realized by intelligence personnel through fixed-source and fixed-point data acquisition. But in the age of big data, the number of open access information resources has increased dramatically. In order to improve the accuracy and recall rate of automatic monitoring and collection of theme-related resources,to reduce intelligence personnel workload, the latest achievements of deep learning technology is introduced in the field of artificial intelligence. A theme resource monitoring and collection model based on deep learning is proposed. The word vector tool word2vec was used to train the collected corpus in depth. Similarity matching is conducted between theme crawler collection resources and theme model. The practice proves that the thematic monitoring method based on deep learning proposed in this paper is applied to the information monitoring system of the institute of ocean strategy. The accuracy of subject resource automatic monitoring is better than that of traditional detection algorithms.
Key words deep learning; thematic resource monitoring; word2vec; similarity calculation
1 引言
大数据时代背景下,各个领域内的可开放获取信息资源量以指数形式增长,科研人员在构建专题知识库、领域情报信息监测、舆情监测系统时,需要从海量可开放获取的网络资源中得到专题所涉的最新发展动态,如有关智库的权威机构、政府部门,国内外大学院系颁发的最新政策、科研数据、研究报告、决策资讯等多种类型的资源。这些数据时效性强,可信度高,已成为学者和研究人员重视和关注的资源。因此,情报人员及时发现和跟踪、分析利用这些开放信息资源,让科研人员掌握最新的科技情报信息,对于科学研究的开展具有重要意义。
本文在现有网络开放信息监测方法研究的基础上,设计开发了基于深度学习的网络主题开放资源自动监测和采集功能,随后将本文方法应用在海洋战略研究所信息监测平台中,实现了对监测主题相关情报信息的智能识别、监测和采集发布。结果证明,相比传统自动监测方法,本文提出的方法优势是无需手动配置领域监测本体和特征实体指标权重值,主题模型构建和相似度匹配由机器深度学习来实现,提高了主题资源监测采集的准确率和召回率。
2 研究进展
2.1 主题资源的监测采集研究进展
国外最早由美国国家情报总局和美国国防部首先提出开源情报(Open-source intelligence,OSINT)[1]的理念,主要通过利用公开可以获取的信息资源来实现情报分析,而不是隐蔽和秘密的信息资源。2005年,美国中央情报局(Central Intelligence Agency,CIA)成立了美國国家情报公开资源中心(Open Source Center,OSC)[2],该中心主要收集、开发和利用网络开源情报信息资源。在监测技术和方法方面,Krishna BV等[3]提出基于主题模型的舆情监测和情感分析方法,该方法能够自动从文本中挖掘态度、观点和隐藏的情感;Liu MR等[4]从在线新闻中基于实体和新闻文档的加权无向图提取关键实体和重要事件,从而对新闻文本进行聚类,产生每日重大事件。计算机科学领域的文本挖掘、主题追踪等技术的发展为网络信息自动监测提供了重要的参考价值。
国内目前关于互联网主题资源跟踪和采集主要通过主题爬虫和文本挖掘、自然语言处理技术来实现,中国医学科学院钱庆[5]开发了医药卫生体制改革舆情监测系统,该系统的主题追踪主要借助主题词表来描述网络动态信息中的各种知识单元,通过对相关知识单元进行自动抽取和发布,采用向量空间模型的TF-IDF算法强调不同位置特征词的权重,主题模型构建过程从共现的角度改进了KNN方法,形成了医疗卫生体制改革的主题模型,实现了主题信息自动获取、自动分类的效果;中科院兰州文献情报中心的刘巍[6]通过将自然语言处理技术应用到自动监测功能过程中,可实现对监测资源的重要概念和实体的自动抽取,且与用户配置的语料库进行相似度匹配,实现自动化检测的目标。张智雄[7-8]组织的团队一直致力于研究科技战略情报监测技术和系统工具开发,目前已搭建了自动监测平台,且提出了基于对象计算的战略情报监测分析方法,从五个维度来进行情报价值的计算,这个过程需要对监测本体和指标权重体系进行配置[9]。上述方法在一定程度上实现了定题监测和采集功能,但在关键概念和实体抽取过程中,只支持部分机器学习功能,在相似度匹配部分,需要对领域本体语料和指标权值进行人工配置,降低了自动监测效率,没用到目前人工智能领域最新成果深度学习技术来提高监测采集的智能化,从而提高检测效率和降低人工成本。
2.2 深度学习理论及应用研究进展
深度学习是机器学习研究中的新领域,是一种无监督特征学习和特征层次结构的学习方法,实际上是一种多隐层的神经网络算法,其核心思想是模拟人脑进行分析学习、决策机制来解决问题。2006年,加拿大多伦多大学教授Geoffery Hinton[10]在《Science》上发表论文,首次提出深度学习的观点,其本质思想是通过构建多隐层的模型和海量的训练数据,来学习更有用的特征,从而提升最终预测的准确性。深度学习从大类上可以归入神经网络,核心是通过分层网络获取分层次的特征信息,解决需人工设计特征的重要难题,它包含有多个重要算法,如卷积神经网络(Convolutional Neural Networks,CNN)、深信度网络(Deep Belief Networks,DBN),多层反馈循环神经网络Recurrent neural Network,RNN)等。与传统的机器学习算法不同,深度学习可以自动进行特征提取,而无需人工干预,且可以提取为标记、非结构化数据中的潜在特征,如音视频、图像、文本等多媒体数据[11]。在具体的特征学习和训练上,深度学习与神经网络模型存在差异,深度学习采用自上而下的无监督学习,逐层构建单层神经元,采用wake-sleep算法进行逐层调整优化,收敛至局部误差最小,自顶层往下误差矫正信号越来越小[12]。
随着深度学习技术的迅速发展,基于神经网络的自特征抽取的词向量表示方法受到广大研究者的关注。Mikolov等[15]通过借鉴Bengio等[13]提出的NNLM(Neural Network Language Model)模型以及Hinton[14]的Log Linear模型,提出了word2vec语言模型,Google公司在2013年开放了word2vec这一款用于训练词向量的开源软件工具,标志着深度学习从理论走向了实践。word2vec模型可以根据给定的语料库,通过优化后的训练模型快速有效的将一个词语表达成实数值的向量形式[16]。word2vec包含了两种训练模型,分别是CBOW(Continuous Bag-Of-Words)模型和Skip-Gram模型(见图1)。
从模型图可以看出,CBOW和Skip-gram模型均包含输入层、投影层和输出层。其中,CBOW模型通过上下文来预测当前词的词向量,即将当前词上下文对应的连续词语表示成词袋的形式,将训练的目标向量选为上下文词向量的求和。而Skip-gram模型生成词向量的方式恰好与CBOW模型相反,它仅通过当前词来预测其上下文。word2vec模型在给定的语料库上训练CBOW和Skip-gram两种模型,然后输出得到所有出现在语料库上的单词的词向量表示。基于得到的单词的词向量,可以计算词与词之间的关系,如词语相似性,语义关联性等。目前word2vec模型已应用于情报学领域,如舆情演化分析[17]、恐怖组织挖掘[11]、期刊选题相似性计算[12]等。针对word2vec在文本挖掘领域的良好应用效果,本文提出基于深度学习的主题资源监测采集模型。
3 基于深度學习的主题资源监测采集模型构建
本文构建的基于深度学习的主题资源监测采集模型主要包括数据采集、数据预处理(分词、去停用词、词性标注)、特征提取、深度学习(相似度匹配)、采集发布等步骤(见图2)。传统监测采集模型相似度匹配使用抽取出的关键概念和实体对象与用户参数配置设定的关键词进行匹配,需要非常专业的词表及实体规范库来对主题进行统一表述,降低监测采集的智能化,人工成本较高。向量空间模型要求关键词必须精确匹配,对语义相近的关键词,效果较差。本研究基于word2vec的文本相关度比较模型对语料进行训练,关键词之间进行相关度比较,即使两个关键词集合完全没有交集,也可以给出合理的比较结果。主题资源监测采集模型遵循数据生命周期管理理论,通过构建合理的数据管理组织架构体系,确保采集数据准确性及质量,提高数据有效性、一致性和规范性,实现数据从产生到销毁的全过程规范化管理,充分发挥采集数据价值,提升采集过程的自动化程度,促进各应用系统信息高度共享,为科研决策提供科学依据。
3.1 数据采集
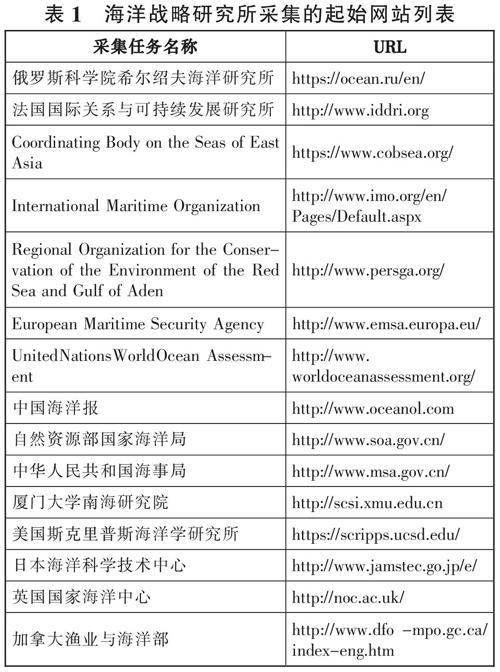
数据采集的基础信息来源是专业人员根据经验制定的情报机构,包括智库、权威机构组织、国外大学院系、政府部门等网站内容。本研究截取了海洋战略研究所指定采集的起始网站列表(见表1)。由表可知,主题爬虫采用的网页搜索策略为基于内容评价的搜索策略,利用文本相关度比较算法进行比较,分析网页内容和主题的相关度来进行爬取。爬取到与主题相关网页提取情报来源的名称、网址、正文等基础信息,作为主题监测的语料集。
3.2 数据预处理
采集信息后对语料进行预处理过程主要包括网页净化、去停用词、中文分词、词性标注等操作。本研究选择自然语言处理工具对采集文本进行预处理。由于中英文文本差异,预处理步骤有所不同,英文文本挖掘预处理不需做分词,中文文本需进行中文分词。通过定义的中文和英文停用词表进行匹配来对正文信息进行过滤停用词的预处理。从正文中抽取反映文本主题的实词,需对文本进行词性标注。英文文本预处理需做拼写检查更正及大写转换小写操作,其预处理独有的步骤是词干提取和词形还原。
3.3 特征提取
经过预处理后的实体概念集合,需要将信息中的重要特征提取出来,文档的内容特征利用基本语言单位如字、词或短语来表示,这些基本语言单位被称为文档的特征项,特征项的权值反映的是一个特征项在文档集合中的贡献程度。本文利用经典的TF-IDF方法来提取特征项,并在计算特征项的权重时将特征项的位置信息考虑进来,不同位置的特征项对主题的贡献有差异,对出现在文本标题、首句、段首、段尾和正文五个不同位置的特征项赋予不同的权重。综合利用词频以及位置权重计算出每个概念在文本中的重要度。根据阈值去除满足条件的概念既为文本的特征项,也既关键概念集合,同时根据关键特征项集合中的重要度进行排序,可实现抽取指定数量的关键概念。抽取出的特征项集合将会用于与主题模型进行相似度匹配,从而判断是否是用户关注的主题,如果相似,则将抽取的信息加入语料库,且将采集的数据进行发布显示。
3.4 主题建模
主题模型(Topic model)是针对文本隐含主题的建模方法,其中主题是指一个概念或一个方面,在文档集中表现为一系列相关的词语。如果用数学语言来描述的话,主题就是词汇表上词语的条件概率分布,与主题关系越密切的词语,它的条件概率越大,反之则越小,文档集中的每篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。LDA主题模型是由Blei等[18]提出的一个“文本-主题-词”的三层贝叶斯概率模型,该模型也是一种非监督的机器学习算法,可以用来识别大规模文档集或语料库中潜在的主题,它采用了词袋模型方法[19]。主题资源监测的核心内容是采集情报信息与主题进行相似度计算(计算流程见图3)。根据海洋战略研究内容,主题设置为五个方面,分别为海洋战略与规划、海洋经济与科技、海洋环境与资源、海洋政策与管理、海洋法律与权益。每个主题分别选择一定数量的语料进行训练,形成主题模型。在采集新闻过程中,将每篇新闻文本与生成的主题模型进行相似度判断,从而确定每篇新闻文档的主题类别。通过主题建模和深度学习,计算采集文本与主题语义相似度,在一定阈值范围内进行主题资源采集及分类。
采集文本与主题相似度计算[20]流程包括:
Step1:每个主题收集一定数量语料首先进行预处理,包括去停用词、分词、词性标注等操作。利用TF-IDF方法提取文本特征项。
Step2:经过Step1预处理后的主题文档集合建立文档-词项矩阵,基于LDA主题模型,训练主题语料,确定每个主题中前N个主题词及概率分布。
Step3:采集新闻进行预处理、文本特征项提取。
Step4:主题语料与采集新闻利用word2vec进行训练和深度学习。
Step5:将主题映射到word2vec空间中,选取主题ti的前h个词作为主题词,对主题词做归一化处理,即计算每个词w占主题的权重ωi ,在公式(1)中: θi为词w在主题ti中的表示。在主题ti映射到word2vec空间上的向量v(ti)计算公式(2)中,即词w在word2vec空间的坐标*w占主题ti的权重。
ωi= (1)
v(ti)=[∑][h][n=1]ωinv(win) (2)
Step6:將Step3得到的新闻文本映射到word2vec空间。计算方式为每个词在word2vec空间下的坐标相加,再除以总词数。文档向量v(di)计算公式(3)中,c代表的是文档的总词数。
v(di)= (3)
Step7:采集新闻文档与主题的相似度计算采用欧式距离来度量:
dis tan ce(v(di),v(ti))=|v(di)-v(ti)| (4)
Step8:通过计算测试文本与主题文本向量的欧式距离,设置合适阈值来确定文本是否为主题相关资源。
3.5 采集发布
采集文本与主题进行相似度计算后,跟主题相关资源的网址信息进行本地数据库存储,正文提取算法有最大文本块和文本密度算法,可以抽取网页中的文本标题、作者、发布时间、封面图片、及文章正文等内容,发布内容按照图片、论文、资讯内容分栏目展示,发布后的网络资源用户可进行评价。
4 实验测试结果
本文在基于深度学习的基础上,搭建了基于深度学习的海洋发展战略研究所信息监测系统(见图4)。并对其监测系统的框架进行设计(见图5),在这一框架中采集专题管理功能为每个第三方系统创建对应的专题,支持设置第三方系统网站名称、可访问IP、专题管理员等。采集任务管理功能支持从外部系统监测源以API的方式读取采集源列表,且支持同第三方系统自动同步资源列表。分布式采集子系统功能已实现集成Crawler4J爬虫系统,可实现分布式多任务自动调度。主題建模与相关度计算模块主要使用LDA构建主题模型,主题模型构建过程中对主题语料库扩展期刊论文、会议论文关键词、摘要等内容,来提高主题模型精确度。通过word2vec对样本网页数据建模生成词向量模型,结合LDA构建的主题模型进行相似度计算。Web管理系统功能主要实现对采集到的资讯、图片、论文进行管理、发布。
本试验LDA主题模型使用的Gibbs抽样,设置迭代次数为1000次,超参数取固定的经验值。用word2vec训练文档集时,各参数设置情况为size=100, window=5,min-count=1,cbow=1。其中size代表词向量的维数,window代表上下文窗口大小,min-count代表词语出现的最小阈值,cbow代表是否使用模型CBOW,0为使用,1为不使用。本实验使用Skip-gram模型。LDA和word2vec都是用Gensim实现的,Gensim是用于构建主题模型的免费Python包。对五个主题收集英文语料进行LDA主题建模,得到五个主题的top10特征词及占主题权重(见表2)。
可以看出,对主题爬虫收集的英文主题语料经过LDA主题模型训练后,得到的top10主题特征词能够较好描述主题特征,海洋战略与规划得到的特征词组合后可形成“marine planning(海洋规划)”“marine spatial planning”“sea power(海权)”或者“marine power”等关键词。海洋法律与权益得到的特征词可组合为“marine biodiversity(海洋生物多样性)”“marine diversity(海洋多样性)”“marine security(海洋安全)”,而其他特征词“dispute(冲突)”“right(权利)”等与海洋立法及涉海案件息息相关。海洋经济与科技主题得到的特征词主要有“marine industry(海洋工业)”“marine economy(海洋经济)”,代表了主题的主要研究方向,尤其是印度、日本、菲律宾及印度尼西亚的海洋科学技术。海洋政策与管理主题在英文语料提取的特征词主要为“ocean policy”“marine policy(海洋政策)”及跟海洋管理有关的“ocean management”“marine management”以及 “coastal zone(沿海地带)”的管理政策。海洋环境与资源提取的特征词跟“marine protected area(海洋保护区)”匹配、其他关键词“ecosystem(生态系统)”“conservation(保护)”“environmental(环境)”“climate(气候)”都跟环境相关。这充分表明LDA主题模型在主题建模方面的优势,主题爬虫语料经LDA训练可很好描述主题信息,为后面相似度匹配及文本分类做铺垫。
为验证基于深度学习的主题相关资源采集策略在信息监测系统中的应用效果。本文选择2017年12月至2018年10月监测系统通过主题爬虫从各开放知识资源获取网站采集的约3万条数据,筛选出4865条与海洋研究相关的新闻,对4865条数据进行人工标识之后,将训练集和测试集比例按照8:2进行划分,80%用于训练集,20%用于测试集。为准确评价主题相似度匹配的效果,本文选取的评价指标为准确率P、召回率R及F1-measure,F1-measure值为准确率和召回率的调和平均值。将机器检测结果与人工标记结果进行比对。传统计算文本相似度方法为基于向量空间模型的TF-IDF算法,该方法以词在文档中出现频率以及在文档集中出现该词的概率来表征词的权重。本文通过基于向量空间模型的TF-IDF算法与LDA和word2vec结合的算法进行了对比试验,对比实验用同样的文档集作为语料库,首先对语料库进行预处理,再利用TF-IDF算法把主题文档和测试文档表示成关于词项的向量,然后计算测试文档与主题文档的余弦相似度,根据相似度结果值设定合适阈值来作为监测结果,TF-IDF算法测试结果给出F1- measure值(监测结果见表3)。
由检测结果可看出,当测试总样本数为973,引入深度学习技术后运用LDA进行主题建模,利用word2vec进行文本主题相似度计算,实验结果表明,五个主题监测文本的准确率都达到85%以上,文本平均识别率达到91.07%。而基于向量空间模型的TF-IDF算法监测结果的F1值明显低于本文提出的算法,这说明TF-IDF算法的缺点是仅通过TF(词频)和IDF(逆文档频率)来计算,不能有效判断文档中词项本身的语义信息,具有一定局限性。
5 结语
本文提出的基于深度学习的主题资源监测采集策略,通过应用在海洋战略研究所信息监测系统中,可以实现对大量多源异构情报信息进行自动化监测和采集,且通过LDA主题模型对主题进行建模,能够很好描述主题信息,结合深度学习的相似度匹配算法能够进行智能主题分类,有效降低情报人员的工作量,提高了主题资源监测的准确率与召回率,其监测效果优于传统基于向量空间模型的监测算法。
本研究也存在问题和不足,如训练样本需要花费大量时间,通过样本数据建立的主题模型词向量有限。为了让主题模型的准确度不断提高,需要从来源数据中不断提取新的词向量对主题模型进行优化、完善,实现主题模型语义关系的自动扩充,从而进一步提高主题信息监测系统自动获取、自动分类效率,以便为科研人员提供更优服务。
参考文献:
[1] Open-source intelligence[EB/OL].[2019-03-12].https://en.wikipedia.org/wiki/Open-source_intelligence.
[2] Open Source Center[EB/OL].[2019-03-12].https://en.wikipedia.org/wiki/Open_Source_Center.
[3] Krishna BV,Pandey AK,Kumar APS.Topic Model Based Opinion Mining and Sentiment Analysis[C].8th International Conference on Computer Communication and Informatics,Coimbatore,2018.
[4] Liu M,Liu Y,Xiang L,et al.Extracting key entities and significant events from online daily news[C].Intelligent Data Engineering and Automated Learning-IDEAL 2008,2008(5326):201-209.
[5] 钱庆,安新颖,代涛.主题追踪在医药卫生体制改革舆情监测系统中的应用[J].图书情报工作,2011,55(16):46-49.
[6] 刘巍,王思丽,祝忠明,等.基于自然语言处理技术的定题监测功能实现研究[J].图书与情报,2018(3):135-140.
[7] 张智雄,张晓林,刘建华,等.网络科技信息结构化监测的思路和技术方法实现[J].中国图书馆学报,2014,40(4):4-15.
[8] 张智雄,刘建华,谢靖,等.科技战略情报监测服务云平台的设计与实现[J].现代图书情报技术,2014(6):51-61.
[9] 邹益民,张智雄,刘建华.基于对象行为的情报关注模型研究[J].中国图书馆学报,2013,39(5):50-59.
[10] Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks[J].Science,2006,313(5786):504-507.
[11] 郭璇,吴文辉,肖治庭,等.基于深度学习和公开来源信息的反恐情報挖掘[J].情报理论与实践,2017,40(9):135-139.
[12] 逯万辉.基于深度学习的学术期刊选题同质化测度方法研究[J].情报资料工作,2017(5):105-112.
[13] BENGIO Y,SCHWENK H,SEHECAO J S,et al.A neural probabilistic language model[J].Journal of Machine Learning Research,2003,3(6):1137-1155.
[14] Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets[J].Neural Computation,2006,18(7):1527-1554.
[15] Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[J].Advances in Neural Information Processing Systems,2013(26):3111-3119.
[16] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].Computer Science,2013(2):1-12.
[17] 安璐,吴林.融合主题与情感特征的突发事件微博舆情演化分析[J].图书情报工作,2017,61(15):120-129.
[18] Blei DM,Ng AY,Jordan MI.Latent dirichlet allocation[J].Machine Learning Research Archive,2003(3):993-1022.
[19] Ling W,Luís T,Marujo L,et al.Finding function in form:Compositional character models for open vocabulary word representation[C].Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.Lisbon,Portugal,2015,1520-1530.
[20] Wang ZB,Ma L,Zhang YQ.A Hybrid Document Feature Extraction Method Using Latent Dirichlet Allocation and Word2vec[C].First International Conference on Data Science in Cyberspace(DSC),Changsha,China,2016:98-103.
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
