
SpaceMocap:在轨人体运动捕捉系统
2019-07-05 10:02:34王春慧张小虎
宇航学报 2019年6期
李 由,王春慧,严 曲,张小虎,谢 良
(1. 中国航天员科研训练中心人因工程重点实验室,北京 100194;2. 国防科技大学空天科学学院,长沙 410073)
0 引 言
实现人-机-环境系统的和谐共融是航天人因工程的目标,在空间飞行微重力环境下,人体姿态、运动学特性参数与地面重力环境相比有着显著变化[1]。因此需要建立在轨人体姿态测量方法,通过在轨实验获取航天员姿态和运动的基础数据,并分析其工作空间,为长期在轨飞行人因研究提供方法和平台支撑。
运动捕捉(Motion capture, Mocap)是指捕捉人体姿态和动作的技术,它广泛应用于动画制作、生物力学、人机工程、自然交互、混合现实、互动游戏、体育训练、机器人控制等诸多领域。从技术的角度来说,运动捕捉的实质就是要测量、跟踪、记录人体在三维(3D)空间中的运动轨迹。常用的运动捕捉技术从原理上可分为机械式、声学式、电磁式、惯性导航式和光学式。目前以光学式和惯性式最为常见,前者的优势在于精度高、无电缆或机械装置的限制,缺点是标志点易遮挡、混淆、丢失,系统庞大、价格昂贵。后者的优势在于不受光照条件影响、无遮挡问题,缺点是测量结果存在漂移现象,佩戴传感器影响人体自由运动。
失重对人体姿态和运动的影响一直是航天员在轨实验研究的一个重要内容。中性体位(Neutral body posture, NBP)是人体在微重力中自然呈现的姿势,NASA对在轨NBP测量进行了长期的深入研究。在1973、1974年利用天空实验室3次飞行任务,分别在飞行28天、56天、84天时,由航天员拍摄中性体位下的全身照片。如图1(a)、(b)所示,通过确定测点,绘制出头、颈、躯干、上肢、前臂、手、大腿、小腿、脚身体各体段的棍图,然后利用角度尺测量关节角度。这种方法需要人体平面与相机视线垂直,关节点定位受主观因素影响,而且手动计算角度的效率很低。
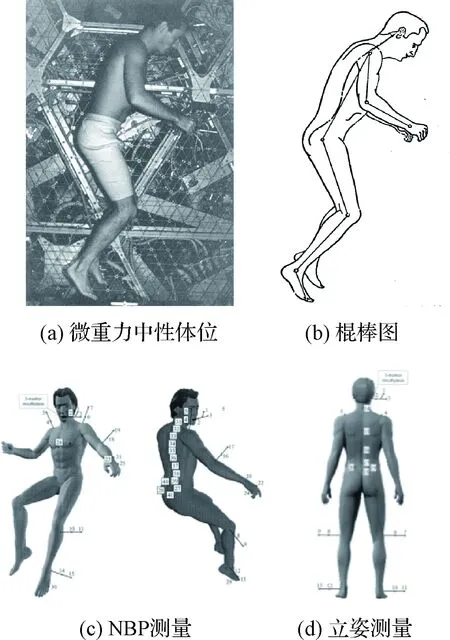
图1 国外在轨人体姿态测量示意图Fig.1 Existing on-orbit posture measurement systems
随着人体测量技术的不断发展,目前NASA利用先进的光电测试技术在国际空间站开展“微重力环境下的人体姿态”项目研究,如图1(c)、(d)所示。定量研究长期微重力环境下中性体位,积累中性体位下人体形态以及立姿下的脊柱形态的基础数据。
在轨运动测量方面,由意大利空间局和法国空间局联合研制ELITE和ELITE-S2[2-3]用于国际空间站多方面分析航天员在失重情况下的运动情况。其原理是通过安装在受试者周围的4个摄相机记录受试者的运动,进一步通过软件处理计算安装在受试者身上的传感器的空间位置。这种方法属于光学式运动捕捉。
随着计算机视觉技术的发展,无标志点运动捕捉(Markerless Mocap)方法逐渐成熟起来。这类位置姿态(以下简称“位姿”)估计或运动捕捉方法又称为“基于模型的位姿估计和跟踪方法”[4],其核心思想是“模型-数据”配准,即求解人体位置和姿态,使得该位姿下的人体表面模型与二维(2D)图像或3D点云最大程度上匹配。早期的多视角轮廓方法[5]从每个相机图像中提取人体外轮廓,获取包含人体的视锥,再通过各视锥的交集获取视觉凸包(Visual Hull),最后利用迭代最近点(Iterative closest point, ICP)方法求解位姿。这种方法需要人体位于简单背景下,并且无法很好地处理凹陷[6-7]。随着深度学习技术的发展,出现了基于彩色图像的方法[8-10]以及基于深度图像的方法[11]。然而这些方法主要以关节点检测为主,精度和跟踪的连续性无法满足运动捕捉的要求。
RGB-D相机(又称深度相机或3D相机)能够同步输出彩色图像和深度图像,按照原理不同可分为结构光(Structured Light)、TOF(Time of flight)、双目视觉(Stereo Vision)三类。随着Kinect、Xtion、Astra等RGB-D相机的普及,直接获取深度图像(或点云)变得非常方便。基于该相机与上述位姿估计方法的核心思想,本文提出了基于多台RGB-D相机的在轨航天员运动捕捉系统——SpaceMocap。
1 系统处理流程
SpaceMocap系统由一台PC与多台RGB-D相机构成,每台相机与PC通过USB线缆连接,工作流程如图2所示。
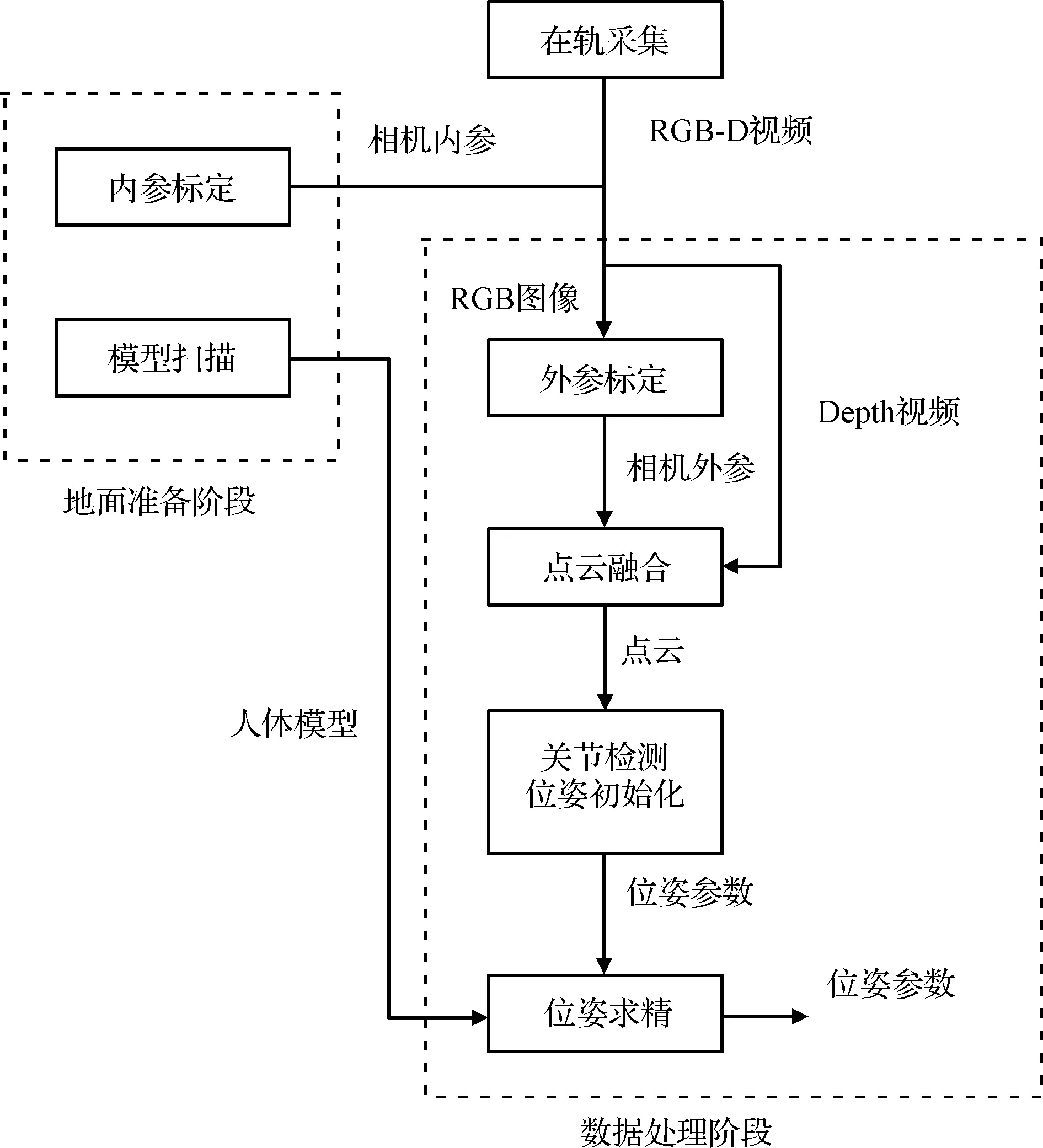
图2 SpaceMocap系统处理流程Fig.2 Processing flow of spaceMocap
①地面准备阶段:扫描人体模型,并分别标定彩色相机的内参数。②在轨采集阶段:系统控制多台相机同步采集航天员任务视频。③地面处理阶段:首先通过标志点标定各彩色相机的外参数,再通过ICP方法实现多个点云的融合。利用预先训练好的深度神经网络对人体关节点位置进行检测,并初始化位姿,再通过改进的ICP方法以“模型-点云”配准的方式进行位姿求精,并实现序列图像中关节点角度跟踪,以c3d和bvh数据文件的格式输出关节点位置和关节角度。
2 技术细节
2.1 地面系统准备
地面准备阶段主要完成人体模型扫描和相机内参数标定两个工作。
2.1.1人体模型扫描与关节角度驱动
由于整个方法是基于“模型-点云”配准实现位姿求解,所以首先需要获取人体模型。尽管可以直接采用通用人体模型(如用圆柱体、椭球体代替人体体段),但是获取特定航天员的人体模型,做到数据同源,显然可以使位姿求解获得更高的精度。
目前针对人体稠密实时重建,主要可以分为单目和多目的重建策略。基于多目的人体稠密重建,目前最具有代表性的工作为Fusion4D[12],该工作采用8个视角的深度图对人体进行稠密重建,鲁棒性较高,但是8台深度相机需要精确标定,难以推广普及。相对而言,基于单目的人体稠密重建实用性更好。为此,基于单台RGB-D相机(如Kinect、Xtion、Astra)对被测试者进行近距离扫描获取深度视频,利用DynamicFusion算法[13]重建高精度的人体表面三角网格模型。通过扫描获取的是固态静止模型,而位姿跟踪需要的是可以被关节角度驱动的模型。为此,采用自动骨骼蒙皮绑定[14]方法将该三角网格模型和参数化骨骼模型转化为多自由度人体模型。基本原理及本系统所用的18-关节人体模型如图3所示。
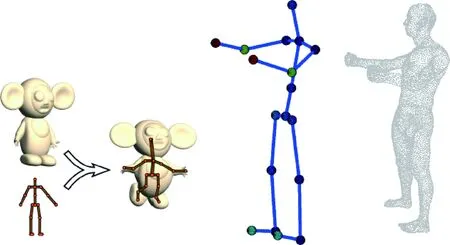
图3 本系统的人体模型Fig.3 Human body model in our system
2.1.2相机内参数标定
RGB-D相机包含彩色相机和深度相机,本文仅标定彩色相机,深度相机沿用厂家提供的内参数。在此,采用张正友标定方法[15]对每台RGB-D相机的彩色相机进行标定,记录其内参数,该参数将用于后续外参数标定(即相机位姿求解)。
2.2 在轨视频采集
在轨视频采集阶段,航天员将各相机安装在舱内既定位置,通过USB数据线将相机与PC连接,调节云台使得被试航天员位于各相机视场当中,并利用采集软件对被试航天员的任务视频进行多目同步采集。在轨采集示意图如图4所示。由于深度图像的边缘普遍存在较大失真,因此尽量使被试者位于各图像的中央位置。另外,由于深度相机的测量精度随物距增大而迅速降低,因此在深度相机有效物距范围(0.5~6 m)内,被试者应尽量靠近相机。

图4 在轨采集示意图Fig.4 On-orbit Acquisition
为了后续地面处理中获取各相机的外参数,在实验现场各相机公共视场内布置多个合作标志点,这些标志点在既定的参考坐标系中的坐标是精确已知的,后续测量结果将转换到该坐标系下。
SpaceMocap利用深度视频进行运动捕捉,彩色视频仅仅作为显示用。为此,采集软件对彩色视频进行有损压缩,对深度视频进行无损压缩,每5 min一次将它们保存在硬盘中。试验结束后,航天员将这些视频数据拷贝至移动存储介质带回地面。
2.3 视频地面处理
首先,通过简单的计算将深度图像转换为点云数据。由于每个视角点云都是以其深度相机拍摄时的位姿为原点的,因此需要通过相机外参数标定获取拍摄时各相机相对于参考系的位姿,再利用该位姿对点云进行坐标变换,使其融合到参考系下。
2.3.1基于相机外参数标定与ICP的点云融合
外参数是相机相对于参考系的位姿。采用PnP算法[16]对包含合作标志点的彩色图像进行求解,获取在轨实验时刻各彩色相机的外参数。
利用外参数将每朵点云变换到参考系下,但由于每台RGB-D相机的深度相机与彩色相机之间还存在一个位姿差异,因此还需对各点云进行微调。为此,采用ICP算法对点云的位姿进行迭代优化。
每次实验相机云台都是固定不变的,因此上述点云融合所需的参数只计算一次,对于后续每一帧点云都要利用该参数进行融合。融合后的点云除了包含目标人体外,还包含大量的背景或无关物体的点云,会对后续的检测和跟踪造成影响。为此,对于第一帧点云,用户可以指定一个感兴趣长方体(Cube of Interest),检测或跟踪算法仅处理该COI内部点云。COI仅在第一帧点云需要设置,在跟踪过程中,COI自动跟随人体位姿。值得一提的是,该COI内部仍然存在噪声点云,然而我们的算法可以根据距离阈值有效地排除这些噪点。

图5 地面数据处理软件界面Fig.5 Interface of ground data processing software
2.3.2关节点检测与位姿初始化
不结合前后帧数据,在单帧数据中,直接检测获取人体关节点位置信息,为跟踪器提供鲁棒的单帧检测结果,是关节位置检测器的主要功能。目前存在大量的人体关节点检测算法,主要是针对单目人体姿态检测:基于单目深度图的3D人体关节点检测[11]和基于单目彩色图的2D人体关节点检测[8-10]。单目人体姿态检测难以应对部位遮挡的情况,只能应对人体正面朝向相机的情况。
传统的神经网络框架都是以2D、3D图像作为输入的,多目深度图可以通过变换,将多目融合点云转换成3D图像,继而作为神经网络的输入,这种做法是目前3D神经网络的研究热点。但是将点云转为3D图像具有一定的局限性,首先3D图像中存在大量的空白处,存在空间浪费;其次,由于点云的疏密程度不同,转换的3D图像会发生变化,造成输入错误。因此,本文研究了以点云为直接输入的神经网络框架,能够有效减少3D深度学习的使用空间,并且能够应对疏密程度不一致的点云输入。
以点云为输入的神经网络初步框架如图6所示,点云首先通过学习获得的变换矩阵进行归一化处理,再利用卷积特征处理获取特征,循环处理,可

图6 以点云为输入的神经网络框架Fig.6 Neural network framework using point clouds as inputs
获得高层特征信息,不需要对点云进行特殊处理。对COI内部点云进行关节点位置检测,演示结果如图7所示。

图7 关节点3D位置检测示意图Fig.7 Joint point 3D position detection
利用本深度神经网络检测初始时刻人体各关节位置,根据对应关系即可求解人体初始位姿,完成跟踪的自动初始化。后续跟踪如果失败,系统将自动调用本方法进行重新初始化。
2.3.3位姿求精与姿态跟踪
基于神经网络的关节位置检测算法能鲁棒地定位关节点的3D位置,但是精度较低,检测算法也没有用到连续帧之间的关系,连续帧之间存在检测抖动,因此仅通过3D检测算法难以获得精确、平滑的关节角度结果。
传统的关节角度跟踪算法采用ICP策略,鲁棒性较差,难以应对大幅度运动,本研究利用神经网络作为关节位置的鲁棒检测器,能够鲁棒应对大幅运动。传统的基于ICP策略的关节角度跟踪策略,在寻找点云和模型之间的对应性时,仅仅考虑点云的位置信息,即以点云同模型之间的点距离最小化为目标,由此找到的点云对应性容易受到复杂运动影响,例如大臂和胸部在特定姿态下紧挨在一起,此时仅靠距离最小化原则容易出现错误点对应。因此,提出了融合点云位置和法向的点对应求取策略,可以有效地应对复杂运动情况。
综上所述,根据改进的ICP方法优化求解了人体精确位姿并实现了序列图像中人体位姿(关节角度)的跟踪。对关节点位置、角度进行差分和平滑,即可获取速度、角速度等运动参数。
3 试验结果
3.1 人体姿态测量结果
为验证SpaceMocap系统的性能,我们在地面进行了反复的测试,并将结果与精密光学动捕设备进行了比对。试验结果表明,运动捕捉的模型与点云具有良好的重合度,关节点定位误差在5 mm以内,关节角度误差在2.5°以内,误差主要取决于深度相机的精度和分辨率。2016年9月,SpaceMocap(整包质量约4 kg,体积400 mm×300 mm×200 mm)搭载TG-2升空,对SZ-11两名航天员的任务视频进行了采集和处理。
Space Mocap系统3个RGB-D相机(Orbbec Astra)在轨获取的航天员NBP图像点云,以及SpaceMocap系统地面测量软件获取的姿态跟踪结果如图8(b)所示。由图中可见,航天员人体模型与点云有良好的匹配度,表明姿态跟踪结果准确。本次试验获取的中性体位姿态角与NASA的数据(见图8(a))如表1所示。人体本体坐标系定义为x轴向左、y轴向上、z轴向前,定义水平面为xz、矢状面为yz、冠状面为xy。表1中各角度为各关节在各平面上的投影角,与NASA的数据基本相符,但有些角度也存在较大差异。此外,任意时刻航天员的占位空间可以根据该时刻捕获的姿态模型求得。这是我国首次获取的航天员在轨NBP角度、占位空间等数据,将为我国载人航天人机交互设计提供重要的参考依据。
3.2 舱内活动的运动学测量结果
本次试验对航天员舱内多组运动视频进行了分析。以脚蹬离测试为例,航天员从后球底附近的硬扶手处蹬离,沿着地板向前锥段方向飘移,在前锥段附近的硬扶手处停靠。定义X轴与Z轴位于地板所在平面,Z轴由后球底指向前锥段,X轴指向左侧。系统获取了全身及各关节点的位移和速度,各关节角度和角速度数据。

表1 SZ-11任务与NASA中性体位姿态角度的对比Table 1 NBP angels of SZ-11 and NASA astronauts (°)

图8 在轨中性体位测量结果Fig.8 NBP measurement results
经系统分析,身体质心变化曲线如图9所示。由图可知,质心基本平行于舱体地板(Y值变化很小),从舱体后球底运动到前锥段(Z值逐渐增大)并稍向左侧飘移(X值逐渐增大)。经计算,质心在Z方向初始速度约为0.11 m/s。运动过程中,质心X方向和Z方向上的最大速度均为0.3 m/s,在运动结束位置附近时的质心Z方向速度约为0.03 m/s。运动测量结果与图像表观吻合较好。
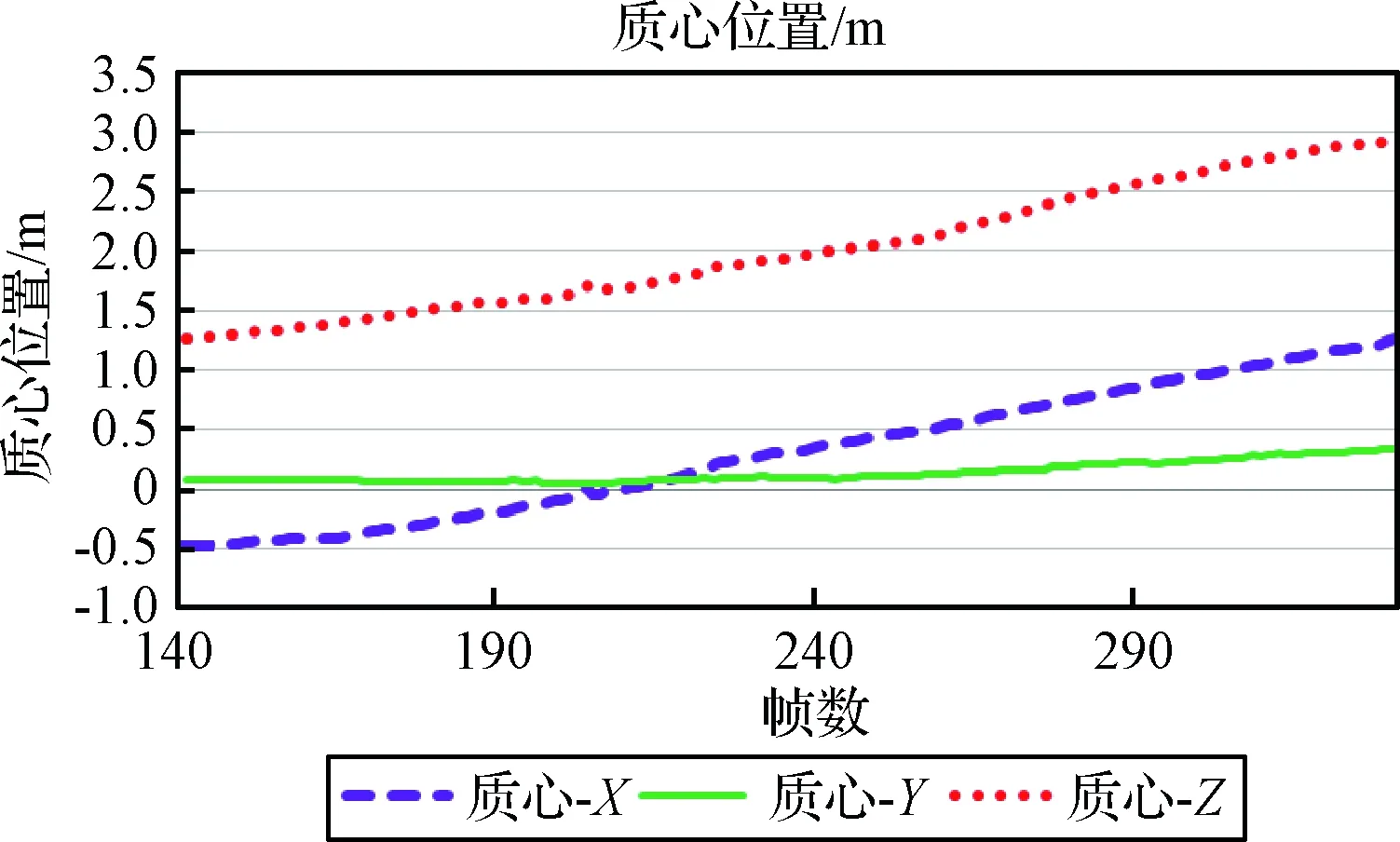
图9 舱内活动的运动学测量结果Fig.9 Kinematic measurements of in-cabin activities
此外,系统提供人机交互辅助测量功能。当自动初始化或跟踪失效时,可通过界面手动调节人体质心位置、主轴方向和各关节角度,实现位姿的高效调整。用户通过观察模型-点云、模型-图像的重合度,可以定性分析当前位姿测量结果的准确性。通过观察系统实时显示的匹配度数值,定量分析当前位姿测量结果的置信度。
4 结论与展望
1) 提出了一种有效的基于多台RGB-D相机的运动捕捉方法,不仅具有直观、非接触式等视觉测量的共性优势,无需在人体上粘贴任何标志,而且具有较高的测量精度以及良好的鲁棒性和抗遮挡能力。
2) 基于上述方法构建的SpaceMocap系统是我国首个在轨人体运动捕捉系统。它具有体积小、质量轻、功耗低等优势。试验结果表明,其适用于微重力、狭小空间下的在轨应用。
3) SpaceMocap在最近一次飞行任务中为我国首次获取了在轨航天员的中性体位姿态,以及其它姿态、占位空间、运动参数等重要数据,今后还将用于在轨人因行为分析等领域。目前,我们正在选型更高性能的RGB-D相机,改进算法(如融合彩色图像与深度图像信息)并提高实时性,使其更好地应用于后续载人航天任务。
猜你喜欢
科学技术创新(2021年19期)2021-07-16 10:07:04
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
军营文化天地(2017年6期)2017-06-28 11:30:19
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
汽车文摘(2015年11期)2015-12-14 19:10:11
第二课堂(课外活动版)(2015年6期)2015-10-21 19:26:21
销售与市场·管理版(2015年5期)2015-05-05 12:39:51
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:51
