
采用区分性幅相联合字典学习的低截获概率信号分离方法
2019-06-19 01:35周一鹏田元荣周东青
国防科技大学学报 2019年3期
陈 游,周一鹏,王 星,田元荣,周东青
(1. 空军工程大学 航空工程学院, 陕西 西安 710038; 2. 国防科技大学 电子对抗学院, 安徽 合肥 230037;3. 北方电子设备研究所, 北京 100089)
在日益激烈的信息化作战中,作战飞机处于多种类型、多种体制辐射源信号混叠的复杂电磁环境[1]。在这种环境下,机载传感器需要将混叠在一起的各个辐射源信号分离开,从而实现对敌方辐射源威胁的正确识别并引导电子对抗装备实施有效对抗。这种单平台下的辐射源信号分离是典型的单通道盲源分离问题,具有重要的研究价值。
目前,单通道盲源分离问题已经成为信号处理领域的研究热点。传统的独立分量分析(Independent Component Analysis, ICA)[2]及其相关改进算法[3-4]具有严格的使用条件,只适用于正定和超定情况下的信号分离。而对于单通道盲源分离问题,一种解决思路是通过一定的先验信息将“全盲”问题转化为“半盲”问题,然后根据信号的稀疏性,采用稀疏分析理论实现信号分离。1999年,Lee等[5]提出对先验数据进行字典学习得到能够表示信号的过完备字典,实现盲信号分离。2001年,Bofill等[6]提出基于频域稀疏表示的欠定盲信号分离方法。此后,朱航等[7]提出基于改进的自适应Chirplet分解法实现单通道雷达引信的混合信号分离,但这种分离方法取决于产生字典的解析函数与信号结构特征的匹配程度,在应用时有一定的局限性。自从Mairal等[8]提出区分性字典学习(Discriminative Dictionary Learning, DDL)思想以后,区分性K奇异值分解(K-Singular Value Decomposition, K-SVD)字典学习[9]、Fisher区分性字典学习[10-11]等算法相继提出,但这些算法主要应用于图像分类问题。2014年,Bao等[12]将DDL用于语音信号分离,各个信号分量的独立字典组成联合字典,将混合信号在联合字典上进行分离。此后田元荣等[13]提出一种具有共同子字典的盲源分离算法,实现对混合语音信号的有效分离,但共同子字典对分离性能的提高取决于信号源之间的相关性,同时也增加了计算量。本文提出一种采用区分性幅相联合字典学习(Discriminative Amplitude-Phase Dictionary Learning, DAPDL)的雷达信号分离算法。
1 字典学习在信号分离中的应用
1.1 基本思路
信号y∈Rn可表示为字典D中有限个原子的线性组合,即y=Dx。其中过完备字典D=[d1,d2,…,dm]∈Rn×m包含m个原子,x∈Rm为信号y在字典D表示下的稀疏系数向量。
基于字典学习的单通道信号分离方法通过事先对信号样本进行学习,得到不同源信号的字典。然后将不同源信号的字典组成联合字典,当需要对未知混合信号进行分离时,将混合信号在字典上进行稀疏表示,这时不同信号分量投影到对应的子字典上。根据子字典和对应的稀疏表示系数向量恢复出各个源信号,实现信号分离。该方法主要分为以下3个步骤:
步骤1:字典学习,根据先验的信号样本学习不同源信号的子字典。
步骤2:稀疏表示,将未知混合信号在联合字典上稀疏表示,得到稀疏表示系数向量。
步骤3:信号分离,通过对应子字典和系数向量,分离出各个源信号。
1.2 幅相联合字典的构建
已有的信号分离算法通常对信号的幅度信息进行学习[14]。这种方法在学习过程中丢失了信号的相位信息,因为在信号恢复过程中,除非混合信号的相位与信号分量的相位在各个时刻均相同,否则重构信号的相位信息将产生较大误差。式(1)~(3)解释了仅基于幅度信息进行信号分离的误差形成原因[14]。
Y(t,f)=Y1(t,f)+Y2(t,f)
(1)
|Y(t,f)|ejφ=|Y1(t,f)|ejφ1+|Y2(t,f)|ejφ2
(2)
|Y(t,f)|=|Y1(t,f)|ej(φ1-φ)+|Y2(t,f)|ej(φ2-φ)
=|Y1(t,f)|+|Y2(t,f)|,φ=φ1=φ2
(3)
其中,Y(t,f)为源信号Y1(t,f)和Y2(t,f)组成的混合信号,φ、φ1和φ2分别为混合信号和两个源信号的相位。考虑到在实际应用中,许多雷达信号进行幅度和相位的复合调制,信号的相位中也包含着重要的情报信息。因此,本文考虑构建包含相位子字典和幅度子字典的幅相联合字典,最大化地包含信号的全部信息,提高分离信号的保真性。幅相联合字典的结构为D=[DA,DP]。信号在幅相联合字典上进行稀疏表示,其系数分为幅度系数xA和相位系数xP,如图1所示。
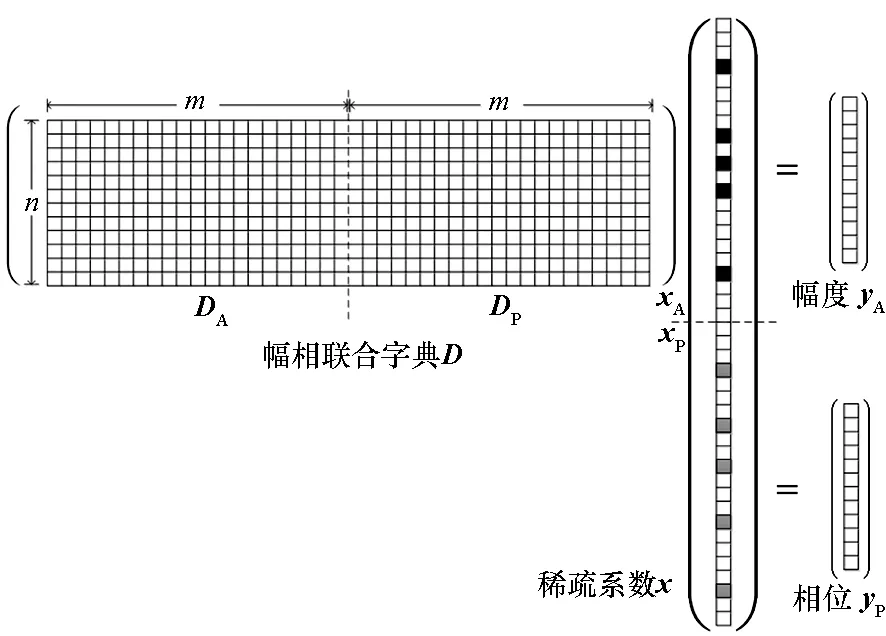
图1 采用幅相联合字典的稀疏表示示意图Fig.1 Sparse representation based on amplitude-phase dictionary
2 区分性幅相联合字典学习算法
2.1 交叉表示问题分析
混合信号中各个信号分量能否有效分离,一方面取决于子字典的保真性,即信号能否在对应的子字典上充分表达,另一方面也取决于字典的区分性,即不同信号子字典之间的相关程度。实际情况中,不同雷达信号有一定的相似性,传统算法中各个信号分量的子字典训练过程独立进行,不能保证训练得到的字典之间具有较低的相关性。当子字典之间存在相关性时,信号在联合字典上的投影将很难完全集中在对应子字典上,相当一部分的能量将在其他信号的字典上表示,这就造成了交叉表示的问题。交叉表示越严重,分离得到的信号失真就越严重。图2(a)和图2(b)分别为某一调频连续波(Frequency-Modulated Continuous Wave, FMCW)信号和Costas信号的幅度向量[xA1,xA2]在各自子字典DA1,DA2上进行稀疏表示的分布,图2(c)为二者的混合信号的幅度向量xA在字典DA=[DA1,DA2]上的分布。
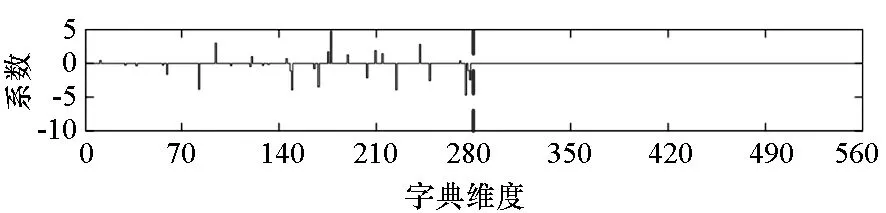
(a) FMCW信号在字典DA1上的稀疏表示系数(a) Sparse representation coefficients of the FMCW signal in dictionary DA1

(b) Costas信号在字典DA2上的稀疏表示系数(b) Sparse representation coefficients of the Costas signal in dictionary DA2
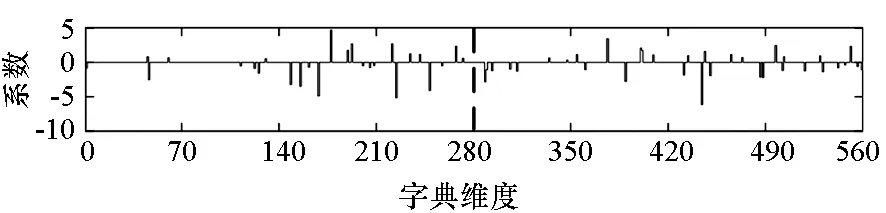
(c) 混合信号在字典[DA1 DA2]上的稀疏表示系数(c) Sparse representation coefficients of the mixed signal in dictionary [DA1 DA2]图2 交叉表示示例Fig.2 Example of cross representation
理想情况下,应该有[xA1,xA2] =xA。然而比较图2(a)~(c)可知[xA1,xA2]≠xA,这说明混合信号投影时两个信号均有一部分能量在对方的字典上交叉表示。图3为混合信号的稀疏表示系数的构成说明。

图3 稀疏表示系数在联合字典上的构成说明Fig.3 Illustration of the sparse representation coefficient in joint dictionary
2.2 目标函数构建
针对由于信号之间存在一定的相似性,导致字典学习得到的子字典之间存在相关性的问题,采用联合学习法,将两个源信号的信号样本进行联合训练,在训练过程中加入交叉表示抑制项,从而在字典训练过程中尽可能地减小子字典之间的相关性,增加字典的区分性。图4为采用的联合字典学习方法示意图。
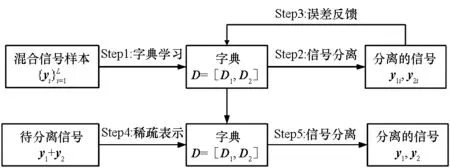
图4 联合字典学习与信号分离示意图Fig.4 Schematic diagram of joint dictionary learning and signal separation

为了获得相关性较小的子字典,基于区分性字典学习思想,在目标函数中加入交叉表示抑制项,抑制信号分量在不同字典上的交叉表示。改进的目标函数包括幅度和相位部分:


(4)


(5)
式(4)中,FA为幅度部分的目标函数,yAi为第i个信号的幅度部分,DA为幅度联合字典,DAi为第i个信号分量对应的子字典,xAi和xAii为信号在幅度联合字典和相应子字典上的系数,DAj为第j个幅度子字典,xAij为第i个信号分量在第j个幅度子字典上表示时的系数。同理可得式(5)相位部分目标函数中FP、yPi、DP、DPi、xPii、xPi、DPj和xPij的含义。α为子字典表示误差系数,β为交叉表示抑制系数。式(4)和式(5)所示的幅度和相位目标函数均包含3个部分:第一项为整体表示误差,衡量信号yi在联合字典上表示时的失真情况,用于提高字典的整体保真性和表达能力;第二项为信号分量在对应子字典上的表示误差,衡量信号yi在对应子字典Di上表示的保真性,用于增强子字典的保真性;第三项为交叉表示误差,衡量信号在其他子字典上的表示情况,用于减小子字典之间的相关性。
2.3 算法思想
基于区分性幅相联合字典学习的信号分离算法包括区分性幅相联合字典学习、混合信号稀疏表示和信号重构3个阶段。
区分性幅相联合字典学习采用2.2节的联合字典学习法。学习过程中对混合信号的相位和幅度信息的联合字典分别进行训练,算法分为稀疏编码和字典更新2部分:在稀疏编码阶段对稀疏表示系数进行优化,固定字典D对信号进行稀疏表示,求解系数向量x。采用正交匹配追踪(Orthogonal Matching Pursuit, OMP)算法求解,稀疏性约束采用l0范数。
在字典更新阶段根据信号分量的重构误差对联合字典进行逐列更新。固定稀疏表示向量x,对联合字典进行逐列优化更新,这一优化问题的目标函数为:
D=arg minF
(6)
其中,F为式(4)和式(5)所示的幅度和相位联合目标函数。
训练时考虑到要同时对多个信号源的信号样本进行训练,更新过程中需要同时对联合字典D和子字典进行更新。以包含两个信号分量的混合信号分离为例,建立指示矩阵:
(7)
在训练过程中,对幅度联合字典和相位联合字典分别进行训练。因此训练过程中目标函数可转化为:
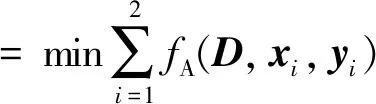
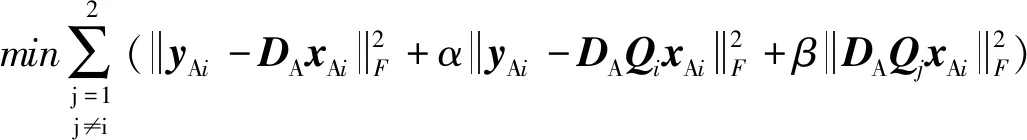
(8)
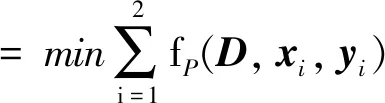

(9)
式(8)和式(9)分别为幅度和相位联合字典训练中的目标函数。经过上述转换,在幅度或相位字典训练中,目标函数只包含字典DA或DP。因此可以采用K-SVD算法更新字典中的原子。具体算法如算法1所示。

算法1 采用区分性幅相联合字典学习的信号分离算法
3 仿真分析
3.1 仿真设置
仿真实验采用3种低截获概率雷达信号:FMCW、Costas和Frank信号,由Low Probability of Intercept Toolbox[15]产生。3种信号样本各产生1000组,随机选择900组样本混合后进行字典学习,剩下的100组用于信号分离测试。信号的采样频率为800 MHz,信号长度为512,幅度为1。其中,FMCW信号采用三角波FMCW波形,包含4个三角FMCW,载频范围为100~200 MHz,调制带宽为20~40 MHz;Costas信号基准频率f0为50~60 MHz,频率序列为[3 2 6 4 5 1]×f0;Frank信号采用8个步进频率且每个步进8个采样点,载频范围为100~200 MHz。3种信号两两混合后得到3种混合情况:Costas+Frank、FMCW+Costas和FMCW+Frank,每种混合情况下分别进行幅度和相位样本混合,得到6个混合样本集。字典学习中K-SVD算法的迭代次数为5次。限定稀疏表示原子个数为字典原子总数的2%。α取值为1,交叉表示抑制系数β根据不同取值进行测试。
为了衡量算法的信号分离性能,定义信号保真度(Signal Fidelity Ratio, SFR)。SFR用于衡量各信号分量的分离误差。分离信号由3部分组成:原信号yi、交叉表示误差ecross和估计误差e。其中交叉表示误差受信号之间以及字典之间的相似性影响,在总的误差中占一定比例。因此保真度SFR的定义为:
(10)
3.2 字典原子数的影响
在区分性幅相联合字典学习算法中,字典原子数N不仅是字典冗余性能的关键指标,也是影响交叉表示现象的重要指标。原子越多,字典的冗余性越好,信号表示时的稀疏性越好,但也意味着原子之间可能存在更高的相关性,其交叉表示程度更高。因此为衡量字典原子数对字典性能的影响,在不同原子数设置下学习字典,比较混合信号分离后的保真度SFR。设置字典原子数从300~600变化,交叉表示抑制系数为0.3。表1为不同原子数情况下,字典的分离性能变化情况。
从表1可知,随着原子数的增加,SFR先逐渐增加后减小。这说明随着字典冗余性能的提高,字典的稀疏表示性能和分离性能有一定的提升。当字典原子数增大到一定程度以后,由于原子之间的相关性提高,信号中有部分能量分布在其他信号的字典上,增大了估计误差。这一现象说明字典学习算法应用于信号分离时,原子数设置并不是越大越好,因为字典原子越多,子字典之间原子的相似性越高,导致分离效果下降。根据分离情况,在后续实验中子字典原子数设为500,即学习的联合字典维度为512×1000。
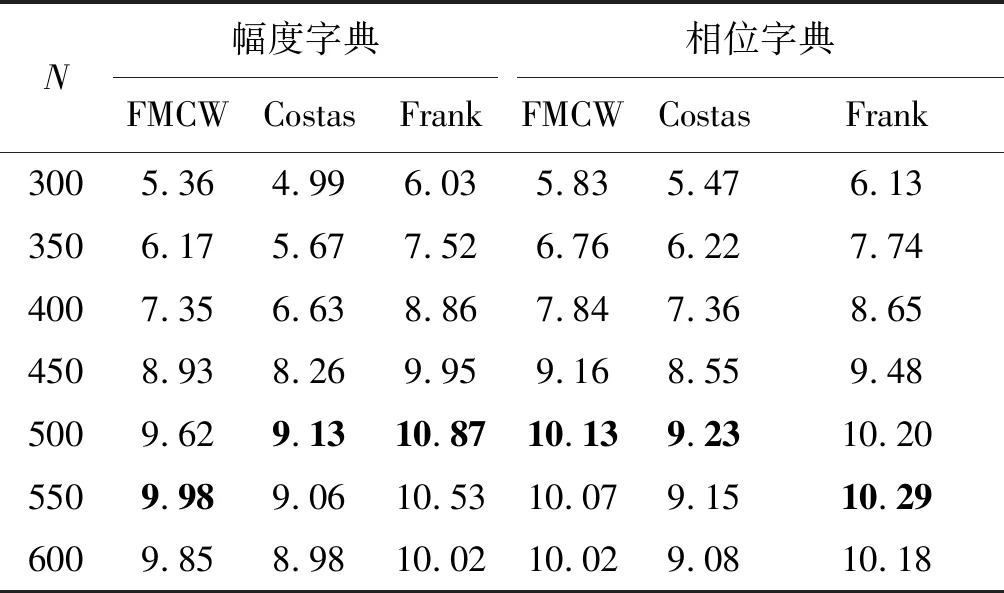
表1 不同字典原子数下信号分离的SFR
3.3 交叉表示抑制系数的影响
交叉表示抑制项是实现区分性幅相联合字典学习的关键。在区分性幅相联合字典学习的目标函数式(4)和式(5)中,通过交叉表示抑制系数β调节字典性能。一方面,提高系数β会增加交叉表示误差在总误差中的权重,可以在学习过程中减小子字典之间的相关性;另一方面,系数β过高会使整体表示误差抑制项和子字典表示误差占总误差的权重相对下降,导致学习的字典中原子的多样性降低,信号保真度降低。表2为不同交叉表示抑制系数情况下,信号分离的SFR变化情况。

表2 不同交叉表示抑制系数下的SFR
从表2可知,随着交叉表示抑制系数的增大,信号的分离效果逐渐提高,这说明目标函数中加入交叉表示抑制项能够有效降低字典之间的相关性,提高子字典的区分性,从而提高信号分离性能。当β为0.4时, Costas信号幅度、Frank信号幅度和相位以及FMCW信号相位的SFR达到最大值。而当β进一步增大时,信号的幅度和相位的分离效果有所下降,这是因为当交叉表示抑制误差在字典学习误差中的权重过大时,字典的功能将更加侧重于区分性,此时字典中原子的多样性降低,保真性要求降低,因此导致混合信号在联合字典上的表示误差增大,分离信号的保真性下降。因此在后续的实验中,交叉表示抑制系数β设为0.4。
3.4 算法性能比较
所提出的基于区分性幅相联合字典学习的信号分离算法在传统算法的基础上构建了幅相联合字典,同时基于区分性字典学习方法改进了目标函数。因此将所提出的区分性幅相联合字典学习信号分离算法与基于幅相字典学习(Amplitude-Phase Dictionary Learning, APDL)的信号分离算法的分离效果进行比较。表3为2种算法对3种信号混合的分离性能指标比较。
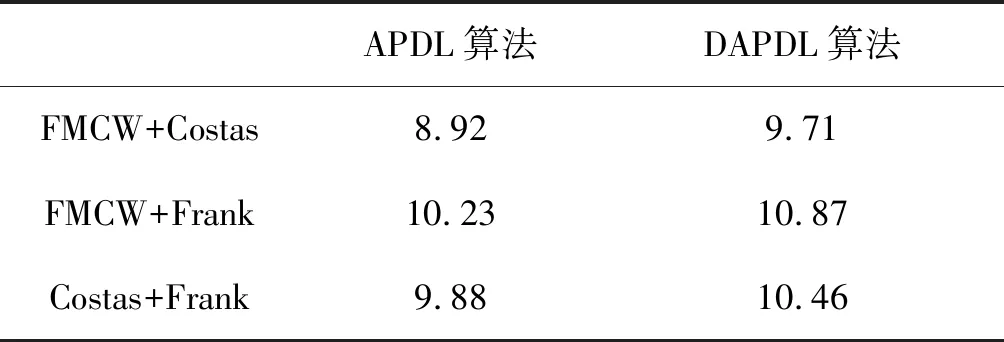
表3 2种算法SFR对比
从表3可知,DAPDL的信号分离算法的分离性能优于APDL的信号分离算法。DAPDL算法在进行信号学习时加入的交叉表示抑制项有效地抑制了信号在不同字典上的交叉表示,降低了字典之间的相关性,获得了更好的分离效果。此外,在3种混合情况下,FMCW+Costas信号分离的SFR相对较低,这是因为这2种信号同为频率调制信号,信号之间的相似程度比其他2种混合情况更高。因此,在APDL算法和DAPDL算法中FMCW+Costas信号学习得到的字典之间的相关性高于另外2种情况,SFR相对较低。
为了进一步说明交叉表示抑制项在DAPDL算法中的作用,选取FMCW信号的幅度样本y1和Costas信号的幅度样本y2进行混合,分别在APDL算法和DAPDL算法学习的联合字典上进行信号分离,其中DAPDL算法中交叉表示抑制系数β设为0.4,分离效果如图5所示,图中物理量均做归一化处理。从图中可以看出,基于DAPDL算法分离的信号更加逼近原信号,误差更小,算法性能更好。

(a) FMCW信号y1(a) FMCW signal y1

(b) Costas信号y2(b) Costas signal y2
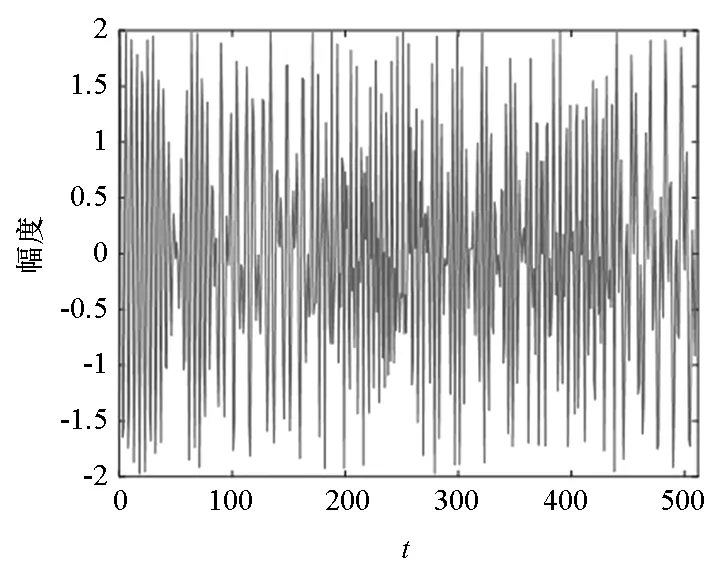
(c) FMCW和Costas的混合信号y(c) Mixed signal y of FMCW and Costas

(d) APDL算法分离的FMCW信号y1(d) Separated FMCW signal y1 of APDL algorithm
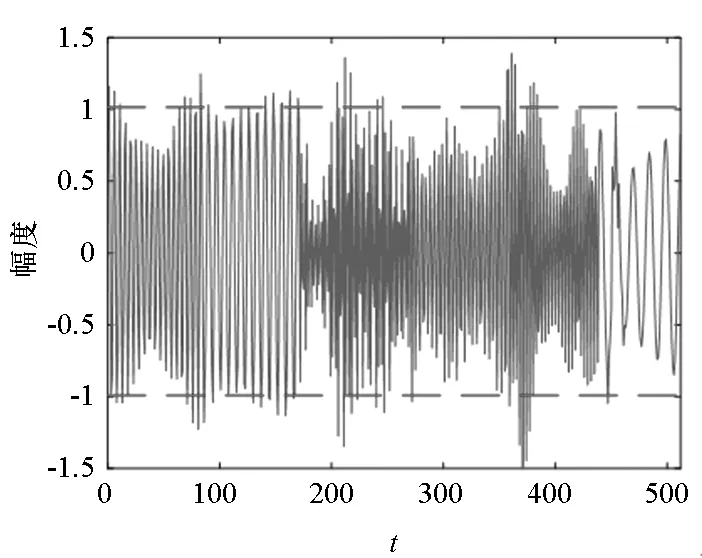
(e) APDL算法分离的Costas信号y2(e) Separated Costas signal y2 of APDL algorithm
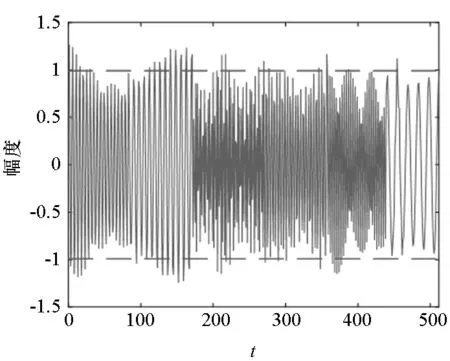
(g) DAPDL算法分离的Costas信号y2(g) Separated Costas signal y2 of DAPDL algorithm图5 DAPDL算法和APDL算法的分离效果对比Fig.5 Comparison of DAPDL and APDL
4 结论
减小信号在字典上的表示误差是提高信号分离效果的关键。基于此,提出采用区分性幅相联合字典学习的信号分离算法。算法对混合信号中各信号分量在其他字典上的交叉表示现象的原因进行了详细分析,然后在字典学习的目标函数中加入交叉表示抑制项,从而减小信号间的交叉表示,提高信号分离效果。理论分析和仿真结果表明,交叉表示抑制项的加入和联合学习法有效地抑制了信号在其他字典上的表示误差,采用区分性幅相联合字典学习的信号分离算法的分离效果有进一步的提高。
猜你喜欢
股市动态分析(2021年25期)2021-12-30
小学阅读指南·低年级版(2019年11期)2019-07-01
奥秘(创新大赛)(2019年3期)2019-03-13
宇航计测技术(2018年3期)2018-09-08
小天使·一年级语数英综合(2017年11期)2017-12-05
中学生数理化·八年级物理人教版(2017年6期)2017-11-09
制造业自动化(2017年2期)2017-03-20
百科探秘·航空航天(2016年5期)2016-11-07
读者(2016年14期)2016-06-29
中国检察官(2015年12期)2015-02-27
