
多核网络分组处理系统的数据分段卸载发送机制
2019-06-19 01:35吕高锋戴幻尧
国防科技大学学报 2019年3期
杨 惠,李 韬,吕高锋,全 巍,戴幻尧
(1. 国防科技大学 计算机学院, 湖南 长沙 410073; 2. 中国洛阳电子装备试验中心, 河南 洛阳 471003)
随着互联网规模的不断扩大和新兴网络技术的应用,不断增长的网络流量对网络核心设备的处理能力提出了更高要求。多核处理器计算性能高和软件编程灵活性强的优势,使得大量的软件路由器和软件交换机在多核平台上被部署。具备高可编程性的通用多核处理器是网络设备中广泛采用的数据平面处理核心器件[1-5]。然而,传统网卡只能支持最大分段长度(Max Segment Size,MSS)大小的数据传输,当请求大量数据时,传输控制协议(Transmission Control Protocol,TCP)发送方必须将大块数据拆分成MSS大小的数据块,然后进一步封装为数据包形式,以便最终在网络中进行传输。由于多核处理器需要对每个分段进行处理,降低了其处理效率。TCP分段卸载(TCP Segment Offload, TSO)技术的提出[5],利用网卡分割大数据包,降低中央处理器(Central Processing Unit,CPU)发送数据包的负载,从而支持大报文的直接发送,报文的切分与校验等分组深度处理全部交给硬件实现。然而,基于TSO技术的网络分组深度处理需要软硬件的协同工作,在软硬件协同分组处理流程中,软硬件的通信开销过大会严重影响系统进行分组深度处理的性能。另外,报文的拆分校验等处理流程全部交由硬件实现,硬件复杂度高。
本文通过分析基于多核的大报文发送流程中的软硬件各个部分的开销,消除和弱化大报文发送的性能瓶颈,基于软硬件协同的轻量级分组输入/输出(Input/Output,I/O)技术和支持大报文发送的传统TSO技术,提出了一种面向高速分组转发的数据分段卸载发送机制。
1 相关研究
TSO技术支持TCP发送方CPU直接将大块数据(最大支持64 KB大小)交给网络设备处理,由网络设备进行TCP段的分割,将一部分CPU的处理工作转移到网卡,从而减少CPU必须处理的数据包数量,达到提高网络处理性能的目的。支持TSO技术的网卡,需要支持TSO和分散-聚集(Scatter-Gather, SG)技术,以及TCP校验和计算功能,由网卡驱动或网卡硬件完成报文分段和TCP校验和计算功能,因而TSO技术需要网络设备驱动或者网络设备提供报文分段功能,对于网络设备的要求较高,软硬复杂度高。更为通用的分段卸载(General Segment Offload, GSO)技术将大报文分段的时机推迟到将数据报文提交给网络设备驱动之前完成,并且支持TCPv4之外的其他协议类型,如TCPv6、UDP和DCCP等。该技术需要网络设备支持通用GSO和SG功能,性能提升效果比TSO技术低。
Scatter-Gather是一种与非连续物理地址传输的块直接内存存取(Direct Memory Access,DMA)[6]方式相对应的DMA方式。它通过一个链表描述物理不连续的内存地址,将链表首地址送往DMA控制器。DMA 控制器传输完一块物理连续的数据后,不发中断,根据链表记录内容传输下一块物理不连续的数据,直到链表中所有描述符内容传输完成发起一次中断。网络设备支持该技术需要支持从多个不同区域获取报文数据并且组装在一起。
为了减少报文处理过程中软硬件交互中断的代价,Packetshader采用大报文缓冲区的方式,静态地预分配两个大的缓冲区(skb控制信息缓冲区和分组数据缓冲区),通过连续存储每个接收分组的skb控制信息和分组数据,避免缓冲区申请/释放以及描述符的转换操作,有效降低分组I/O开销和访存开销。[3]面向高速分组转发提出的自描述缓冲区 (Self-Described Buffer, SDB)管理机制[7-8],将描述符、skb控制信息以及分组数据连续存储在一个缓冲区中,大大降低系统的缓冲区管理开销,实现了无中断的报文传输,但所有报文在发送给网络设备之前,都要拷贝到SDB管理的固定缓冲区中,拷贝代价高,成为制约大报文发送性能的瓶颈。
2 支持轻量级I/O的软硬件协同分组处理系统
2.1 系统描述
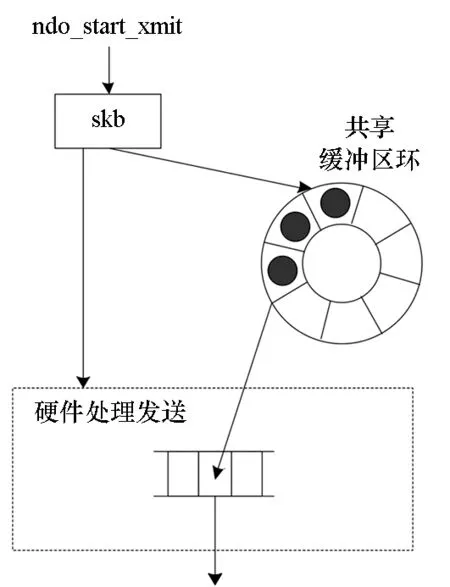
图1 支持轻量级I/O的报文发送机制Fig.1 Packet sending mechanism with lightweight I/O
多核轻量级的分组I/O技术,是一种低开销的分组处理软硬件通信机制,通过缓冲区管理卸载技术等,实现分组的零拷贝、无中断的下发,从而降低分组在软硬件的通信开销[9-10]。支持轻量级I/O的软硬件协同分组处理系统[11]将包含控制信息的描述符和分组数据连续存储在多核共享的地址连续的存储缓冲区中。共享缓冲区不再采用核调度的软件管理方法,而是卸载到专用网络加速引擎上由硬件管理。在系统初始化时,将共享缓冲区的描述符填入硬件管理的空闲描述符块队列中;当数据报文到达,根据空闲描述符队列存储的地址,分配一个空闲描述符,与数据报文组装好通过外设组建高速互联(Peripheral Component Interconnect Express, PCIE)送往共享缓冲区对应的地址空间;而数据报文从共享缓冲区地址空间下发时,如图1所示,首先为要发送的报文获取一个共享缓冲区区域,将报文内容直接由skb->data指向的线性缓冲区拷贝到共享缓冲区中,完成拷贝后,将skb释放,构造一个发送描述符控制块,通知专用网络加速引擎有新的报文需要发送,专用网络加速引擎根据发送描述符控制块指示的报文DMA地址,读取共享缓冲区中的报文内容,完成报文发送。专用网络加速引擎硬件回收对应的描述符,并重新进入空闲描述符队列,等待新的数据报文使用。该共享缓冲区以块为单位组织、申请和释放,解放了核对共享缓冲区地址的管理。描述符和报文块以单向链表的形式,在共享缓冲区内组织。因此,系统在处理分组时,只要空闲描述符队列具有空闲描述符,数据报文即可上传至共享缓冲区,等待CPU核处理,无须中断响应,也无须多次访存缓冲区。
2.2 瓶颈分析
为对报文发送开销进行分析,做出如表1所示的假设。

表1 发送分段开销假设
标准网卡不支持大报文发送流程如图2所示,skb指向应用需要传输的数据及其报文头内容,使用线性缓冲区存放报文内容,构造报文时,skb指向的报文长度最大仅为1514 B。网卡硬件根据描述符指向的地址获取报文内容并将报文发送。标准网卡普通发送n个1.5 KB报文的报文处理开销可表示为:n·Na+n·NS+n·ND+n·NDMA-R。
图3为标准网卡支持大报文发送TSO机制流程图,大报文被发送到网卡硬件才进行报文的分段。发送n·1.5 KB报文处理开销可表示为:n·Na+NS+ND+n2·NDMA-R+n·NHF。

图2 标准网卡不支持大报文发送流程图Fig.2 Sending flow on standard network card (large packet sending is not supported)

图3 标准网卡支持大报文发送TSO机制流程图Fig.3 Sending flow on standard network card (TSO)
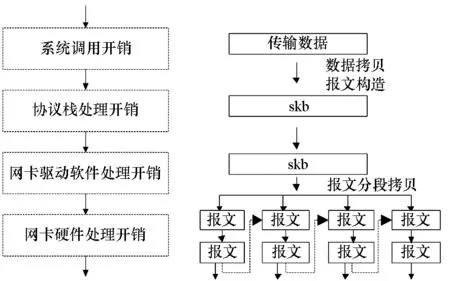
图4 支持轻量级分组I/O的网卡大报文发送流程图Fig.4 Diagram of sending flow for based on the multi-core packet processing system with lightweight I/O
图4为支持轻量级分组I/O的网卡实现大报文发送流程图,大报文被发送到网卡驱动软件进行处理后,完成报文的分段,为每个分段添加报文头部、重新计算每个分段的校验和等功能,并拷贝到指定的多核共享缓冲区中,也就是skb指向报文的内容需分段拷贝至共享缓冲区后才能发送出去,无须硬件支持报文拆分组装功能,减小了大报文在协议栈处理的开销,但驱动层存在报文拷贝开销,且报文分段效率相较于硬件分段较低。发送n·1.5 KB路径报文处理开销约表示为:n·Na+NS+n·ND+n·Nc+n·NDF+n·NDMA-R。
图5为提出的数据分段卸载开销示意图,大报文被发送到网卡驱动软件并被处理后,完成报文的分段,省去了报文拷贝到指定软件缓冲区中的开销。发送n·1.5 KB报文发送路径报文处理开销约表示为:n·Na+NS+ND+n·NDF+n·NDMA-R。
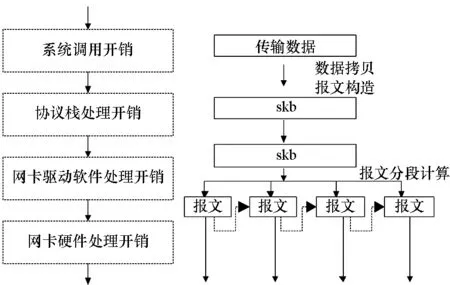
图5 数据分段卸载开销Fig.5 Cost for packet segment offloading
3 数据分段卸载发送机制
3.1 驱动分段及分段报文存储机制
为了降低硬件分段的处理和缓冲区报文拷贝开销,将大报文在驱动层完成切分,只拷贝报文头到共享缓冲区,拷贝的同时驱动完成报文头内容的更新,报文体切分后依然存放在原内存空间。相较于网卡支持的TSO机制,硬件切分报文头,更新报文头内容的工作卸载到驱动实现,同时降低了发送拷贝代价。于是驱动拆分报文后,分段报文的存储方式为,分段报文头存储在共享缓冲区中,分段报文体依然存放在线性缓冲区和页缓冲区中。
图6为数据分段卸载方法中驱动分段及分段报文存储原理图。解析报文头,对于TCP报文,确认报文分段数目以及是否需要进行报文分片。对于需要分片的报文,根据需要分片的数目,将一个大报文的报文头拷贝多份至共享缓冲区中,并同时更新报文头,形成切分后的报文头1、2、3、4。分段后的小报文,第一段的报文头存储在共享缓冲区,第一段的报文体依旧存储在线性缓冲区,第二段的报文头存储在共享缓冲区,第二段的报文体一部分存储在线性缓冲区,其余部分存储在页缓冲区中。为所有的分段报文的头和体构造一个发送描述符链,硬件根据发送描述符链获取每个报文分段或所有分片的每个报文分段所在位置,并获取每个报文分段或所有分片的每个分段报文内容。将多个报文分段拼装成一个报文或多个分片报文,完成TCP校验和计算以及循环冗余校验(Cyclic Redundancy Check,CRC)和计算后,完成报文发送。
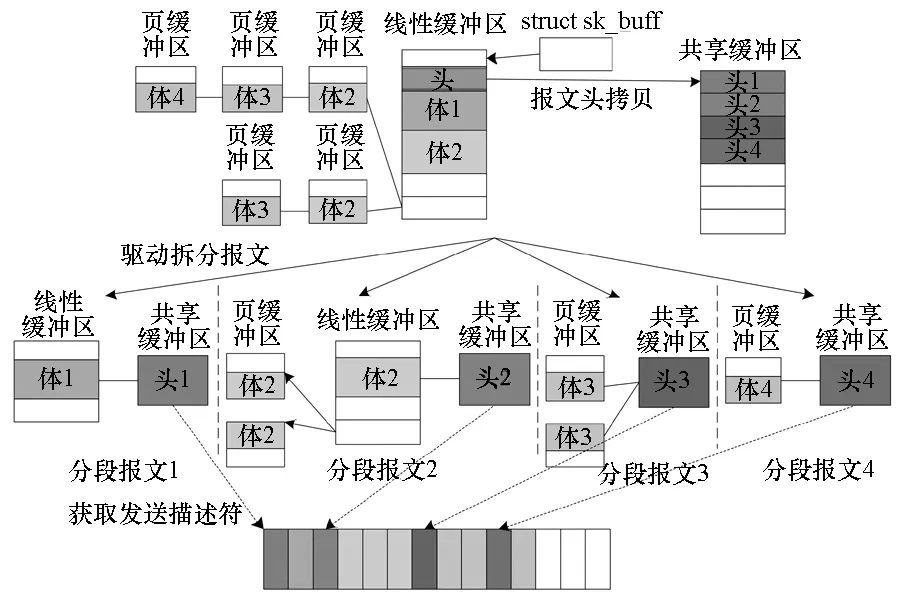
图6 驱动分段及分段报文存储原理图Fig.6 Drive segmentation and storage principle diagram
3.2 数据分段卸载发送方法
数据分段卸载发送方法流程如图7所示。
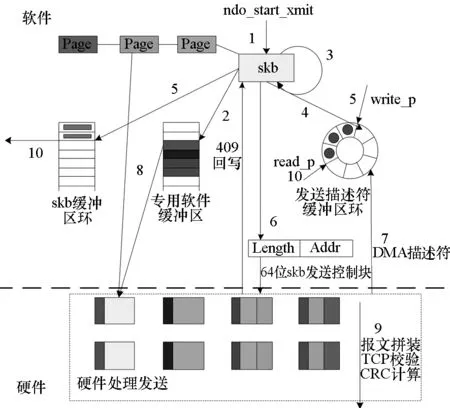
图7 数据分段卸载发送方法流程图Fig.7 Sending flow for data segment offloading and sending mechanism
步骤1:获取skb线性缓冲区和页缓冲区数目,解析报文头,对于TCP报文,确认报文分段数目以及是否需要进行报文分片(skb->len>1514 B);
步骤2:对于需要分片的报文,根据需要分片的数目,将报文头拷贝至共享缓冲区的多个分区中,完成每个分片报文头内容的更新,无须分片则跳过此步骤;
步骤3:根据报文分段,为每个分段完成DMA映射;
步骤4:为每个分片的每个报文分段,包括专用缓冲区、线性缓冲区、页缓冲区分别获取一个发送描述符,填充相关字段,构造描述符链表。在获取描述符时需获得锁,确保不会有多个进程获得同一个描述符;
步骤5:将skb缓存到skb缓冲区环,并更新发送描述符缓冲区环的写write_p指针;
步骤6:构造一个发送描述符控制块,通知硬件有新的报文需要发送;
步骤7:硬件根据发送描述符控制块的内容DMA读发送描述符链,获取所有分片中每个报文分段所在的位置;
步骤8:根据描述符中指示报文分段地址,DMA读取所有分片的每个分段报文内容。将属于同一个分片的多个报文分段拼装成一个分片报文;
步骤9:网卡硬件计算TCP校验以及CRC,完成报文发送后,向发送描述符进行回写,通知软件报文发送完成;
步骤10:驱动处理中断或软中断,检查发送描述符的回写状态,若发送完成则将skb从skb缓冲区环出队,完成skb的释放,并更新发送描述符缓冲区环的read_p指针。
上述步骤4中,为每个分片的每个报文分段,包括专用缓冲区、线性缓冲区、页缓冲区分别获取的发送描述符所构造的描述符链表,以支持链式DMA,允许碎片化的存储中的数据一次DMA完成,描述符链表中的每个发送描述符,都包含了64位存储地址信息、长度信息等。
上述步骤6中,构造的描述符控制块描述的信息为描述符链表存储的地址及长度信息,描述符控制块由驱动构造好之后,以写寄存器的方式通知网卡硬件,以实现将整个描述符链表读取到硬件的功能。
4 性能评估
为有效验证大报文数据分段卸载发送功能和性能,设计并实现了原型系统。原型系统基于国防科技大学计算机学院自主研发的高性能通用64位CPU FT-1500A[12]与自主研制的网络专用协加速引擎网络处理引擎(Network Processing Engine,NPE)[7]构建。其中网络专用协加速引擎在现场可编程门阵列(Field-Programmable Gate Array,FPGA)上实现,FPGA器件采用Stratix V 5SGXMA3K3F40C2X。
本实验的软件测试环境包括:ubuntu 14.04操作系统、NPDK 2.0版本软件开发环境提供的NPE网口驱动[13-14]、用户配置程序。
NPDK环境将所有软硬件的初始化函数封装在环境库内,调用初始化函数create_net_device(dma_cnt,disp_mode),dma_cnt表示硬件启动多少个DMA通道,与软件处理线程数对应,每个DMA通道对应一个处理线程,绑定在一个指定的CPU核上运行;disp_mode指定报文分派模式,循环分派或端口绑定分派。在不超过硬件最大支持DMA通道数情况下,通过重复调用pthread_create(&p_t,&attr,start_npe_thread,tp)函数,选择自由创建多个处理线程,创建线程数与dma_cnt数相同,start_npe_thread即为业务处理线程。线程创建后,显示指定线程绑定到哪个CPU核上运行,线程的创建与CPU亲和设置都使用标准的libpthread库函数。线程轮询到报文后,立即调用报文发送函数进行发送,完成一个报文的转发操作。发送函数send_pkt(*pkt, outport, pkt_len),pkt表示报文指针,outport表示输出端口号,pkt_len表示发送长度。
为支持提出的数据分段卸载发送机制,对软件做出的修改有:增加驱动对大报文的各个分段进行DMA映射功能;增加对TSO功能的支持(netdev->features属性修改);增加驱动报文分段功能;驱动下发描述符由单个变为多个,修改skb软中断,读取发送状态寄存器,修改skb回收机制。对硬件做出的修改有:增加skb发送状态计数器寄存器;支持一次处理多个描述符,同一报文内容可能需要从不同的区域获取,将这几个区域的报文内容获取后拼装,完成TCP校验、计算和更新。
数据发送性能测试场景如图8所示。将由国产CPU、高性能FPGA和存储阵列构建的支持数据分段卸载发送机制的原型系统,通过光纤和千兆网线连接服务器的万兆网卡和千兆网卡接口。服务器万兆网卡接口和原型系统配置成同一网段,由串口登录到存储板CPU。
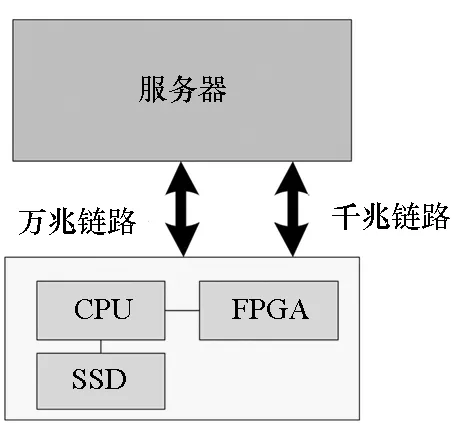
图8 数据发送性能测试场景Fig.8 Test scenario for data transmission performance
表2为支持数据分段卸载发送机制前后性能对比。由表2实验数据可以看出,当配置性能测试参数为单线程时,不管是iscsi的读性能还是iperf的发送性能,在系统支持大报文的数据分段卸载发送机制后,降低了协议栈分段、驱动拷贝等开销,性能有较大的提升。

表2 支持数据分段卸载发送机制前后性能对比Tab.2 Performance comparison before and after supporting data segmentation offloading and sending mechanism
受限于国产高性能CPU面向通用计算,并没有针对网络处理应用的性能瓶颈,单线程单队列单分区的iscsi读性能并没有达到线速。因此,建立iscsi多个链接,测试在CPU不构成性能瓶颈的前提下,发送性能是否达到线速,如图9所示。
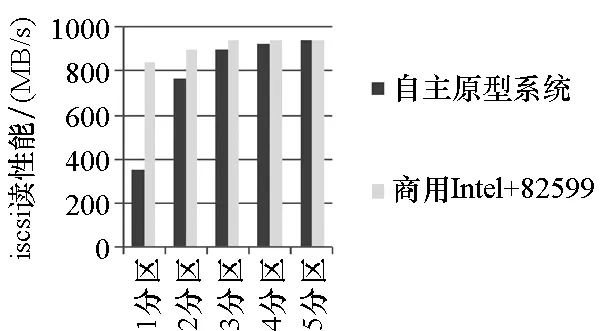
图9 自主原型系统与商用网卡系统iscsi读性能对比Fig.9 The iscsi read performance comparison of domestic prototype system and business-used network
使用fdisk /dev/dfa命令,将SSD固态盘依次分为1~5个区进行测试,在/etc/iet/ietd.conf文件中为每个分区增加一个iscsi节点设置。每次分区完之后使用/etc/init.d/iscsi-target start命令,启动iscsi-target服务,建立基于多个分区的多个iscsi链接。在服务器上与存储板建立1个或多个iscsi连接后,依次测试1~5个分区时iscsi读性能,即数据发送性能,使用fio测试工具统计测试iscsi性能。
对比打开TSO功能的82599商用网卡[13]加Intel处理器构建的系统[15],当iscsi建立链接为5个时,支持数据分段卸载发送机制的自主原型系统与商用网卡构建系统均达到了线速水平。
5 结论
实验结果显示,支持数据分段卸载发送机制的自主原型系统,iscsi读性能和iperf发送性能均有较大提升,相较于商用网卡构建系统,均达到了线速水平。数据分段卸载发送机制支持轻量级分组I/O,软硬件复杂度较低,能够更好地支撑基于通用多核多线程的高速分组转发。
猜你喜欢
词学(2022年1期)2022-10-27
测绘学报(2022年12期)2022-02-13
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
计算机应用与软件(2020年6期)2020-06-16
电子制作(2019年2期)2019-02-14
火控雷达技术(2018年4期)2019-01-15
沈阳工业大学学报(2018年1期)2018-01-08
自动化学报(2016年4期)2016-11-08
中国工程机械学报(2016年5期)2016-03-07
