
S698PM宇航芯片的软件支持及信息处理性能测试
2019-06-13 06:01龚永红许怡冰蒋晓华唐芳福沈祖崮
航天控制 2019年2期
颜 军 龚永红 许怡冰 蒋晓华 唐芳福 沈祖崮
珠海欧比特宇航科技股份有限公司,珠海 519080
1 概述
随着现代航空航天飞行器智能化和信息化水平的不断提高,其飞行控制任务变得越来越复杂,处理的信息量及计算量剧增,对飞行控制任务的实时性、可靠性要求变得更加苛刻,对所采用的处理器要求也越来越高。SPARC架构处理器于2000年左右被引入中国,在航天领域获得成功应用,至今仍是中国航天领域的主流处理器[1]。
欧比特公司自主研制的与LEON4核完全兼容的抗幅照S698PM宇航处理器于2013年推出芯片。该芯片是世界上第一款基于LEON4核的SOC芯片,芯片除了具有LEON4核的优点外,还集成了丰富的片内外设[2]。S698PM宇航芯片已经成功应用于多个型号项目。
围绕着S698PM宇航芯片,欧比特联合多方研制推出了一整套的软件生态系统,包括:操作系统BSP包、软件集成开发环境和软件调试工具等。
2 针对S698PM的VxWorks6.7 BSP软件
S698PM支持目前市场上主流的多种嵌入式操作系统(EOS),包括VxWorks和RTEMS等。欧比特公司专门为这些嵌入式操作系统移植开发了针对S698PM处理器的板级支持包(BSP)。
OBT VxWorks BSP是欧比特公司在VxWorks 6.7操作系统基础上针对S698PM多核处理器开发的BSP包软件。在SMP系统中,当任务同时运行时,可能会产生锁死的情况和负载不均衡问题[3],为了防止这两种问题发生,在OBT VxWorks BSP中设计了多任务调度机制、中断机制和互斥机制等软件技术约束管理任务,解决了SPARC并行多核架构的软件处理问题[2]。
2.1 BSP设计
2.1.1 中断机制设计
OBT VxWorks BSP为S698PM 4个CPU分配中断,通过CPU内部的LOCAL APIC控制器处理中断[4]。OBT VxWorks BSP以优先级为准则,对中断进行判定和排队,对中断队列中的中断进行分派。
在OBT VxWorks BSP中,每一个中断都可以挂载在4个CPU上,但同时只允许一个CPU响应中断[5]。OBT VxWorks BSP对LOCAL APIC进行编程,让所有中断都被一个CPU处理,默认设置为CPU0。通过函数intCtrlISREnable()对全局变量VXB_INTCTLR_SPECIFIC_N进行赋值(0、1、2和3),决定由哪个CPU来处理中断。当外部中断发生时,如果CPU0的中断锁打开,则CPU0处理中断,并发送Message通知其它CPU,否则中断会被发送到其它的CPU处理,其设计流程如图1所示。
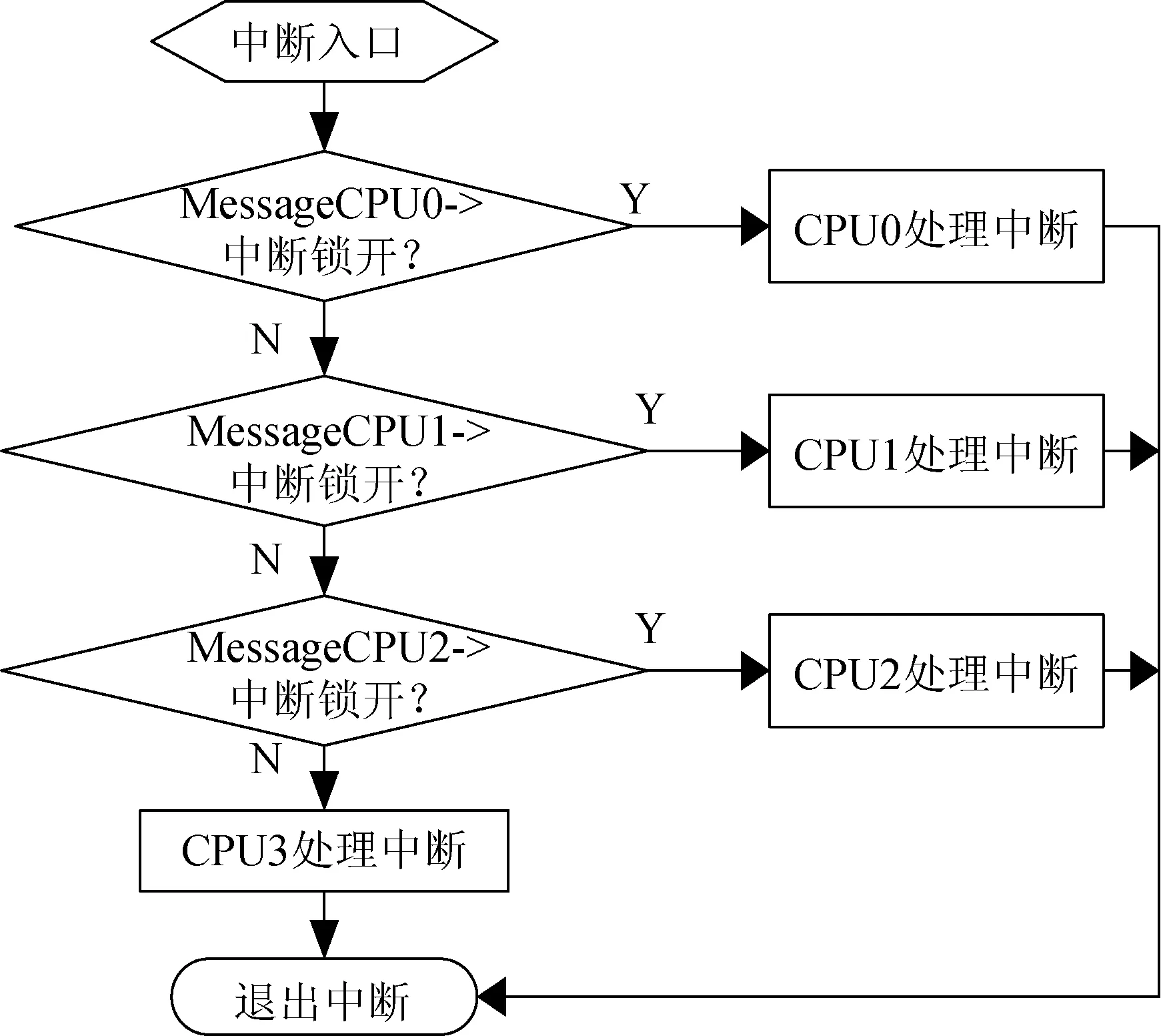
图1 中断设计流程
2.1.2 互斥机制设计
在OBT VxWorks BSP中提供了中断自旋锁和任务自旋锁,分别控制任务和中断对临界段的访问。当任务获得某个中断自旋锁时,运行该任务的CPU核会自动关中断,保护该任务的临界资源。中断自旋锁可以在任务和中断中调用,任务自旋锁只允许有任务自旋,运行该任务的CPU核不允许其他任务的优先抢占。
在中断自旋锁中,设计了自旋锁的归属字段、在每一个核下的使用情况、运行的中断级别和任务控制块。在初始化时,这些参数设置为0,代表不被任何处理器使用。获取中断自旋锁要先判断是否已经被其它任务或者中断取得,如果没有则获取该锁,同时改变该锁的状态,将自旋锁的归属字段设置为当前CPU的ID号,表示自旋锁正在被该CPU占用,将该CPU ID下的使用情况设置为USING。
在任务自旋锁中,设计了拥有权的标识、下一个可获取该锁的任务标识和锁的状态。在获取任务锁时应判断该锁是否为空闲状态,获取后改变该锁的状态,同时设置下一个获取该锁的任务ID,并设置锁的状态为忙碌,使用完成后应释放该锁,设置锁的状态为空闲。
2.2 与传统SPARC VxWorks的比较
目前航天系统中常用的SPARC处理器VxWorks操作系统还是基于5.4内核版本,VxWorks 5.4使用了几十年,虽然可靠性经过了充分验证,但随着硬件的发展,已经越来越显示出弊端。与之对比,VxWorks6.7结合OBT VxWorks BSP的系统在以下几个方面进行了加强和优化。
2.2.1 实时进程处理对比
在运行多任务时,传统SPARC只能按照优先级顺序进行调度,当有紧急需要处理的实时任务插入时,操作系统只能将当前运行的任务挂起,去执行实时任务,虽然实时任务得到了执行,但这是在牺牲当前任务实时性的前提下实现的,这种机制无疑不是最佳的解决方式。
为了既能保证当前任务的实时性,又能立即执行实时任务,在OBT VxWorks BSP中设计了实时任务保护控制模块,存放在分区表中,该分区中控制模块运行的程序与内核独立。
当有实时任务插入时,将该任务放入到实时任务保护控制模块中,由于分区控制模块与内核独立,因此可以立即执行该实时任务,并且不会影响内核原先的调度,与内核运行的任务没有关系。可以看出,OBT VxWorks BSP设计的实时任务保护控制模块解决了传统SPARC对实时任务处理的不足。
2.2.2 多任务处理对比
传统SPARC不支持多任务同时运行,其处理多任务的方式还是按照优先级进行顺序执行。当处理一个较为复杂的算法任务时,严格按照代码的顺序去执行[6],这样会导致处理的时间过长,效率低下。而在OBT VxWorks BSP中,可以将该算法按照需求进行拆解,拆分成多个任务同时执行,而且可以指定任务均匀的分布在4个CPU中运行,各个CPU独立运行各自的任务,不用等待,因此相比传统SPARC BSP来言,大大减少了处理算法的时间,而且大大提升了执行多任务的效率。
2.2.3 网络协议栈对比
传统SPARC中网络协议功能较少,仅支持IPV4和FTP协议的基本内容,当用户需要使用其它复杂的网络协议时,需要花费时间进行开发。
OBT VxWorks BSP在传统SPARC网络协议中增加了目前主流的IPV6协议,TCP协议和UDP等网络传输协议,并且采用组件的方式对这些网络协议功能进行了封装,用户只需在Workbench图形界面中进行简单的配置就能实现所需功能,与传统SPARC开发相比节省了开发时间。
2.2.4 传输文件速率对比
传统SPARC采用文件系统的方式实现文件传输,如TSFS、dosFS和TFFS。这3种方式均采用IO方式实现文件的传输,虽然能实现流量传输,但在传输大文件时,其IO方式传输还是显得速率低下,且这3种文件系统能保存的文件大小只有几百K,因此在大文件传输时,需要用户将文件进行拆分,按照单个文件的形式按顺序传输,同时接收方需要对这些文件进行重组,为了保证传输的安全性,需要用户指定严格的协议来制约,增加用户的开发时间。
OBT VxWorks BSP针对上述现象,在传统SPARC中增加设计了NFS文件系统,通过100M以太网方式实现文件的传输,提高了通讯的速度,且文件大小没有限制,不用用户进行分包和组包工作,如图2所示。

图2 文件系统对比图
从图2可以看出,传统SPARC VxWorks传递大文件时需要进行多次传递工作,而OBT VxWorks BSP NFS文件系统只需一次就能完成文件传输,大大的缩减了传输文件的时间;且由于OBT VxWorks BSP NFS文件系统采用了TCP协议,因此其安全性能得到保证。
OBT VxWorks BSP不仅支持S698PM,也支持其他SPARC处理器,如:AT697、GR712等,借助OBT VxWorks BSP完全可以使VxWorks6.7成为航天用SPARC处理器主流操作系统。
3 S698PM信息处理性能测试
S698PM芯片集成4个高性能处理器核心,提高了单芯片的处理能力;采用7级指令流水,提高了指令执行效率[6];采用128-bit的AHB作为处理器核间的互联总线,降低了处理器总线冲突,提高了处理器间的通讯效率;片内集成了512KB的大容量二级缓存,提高了处理器核访问存储器的命中率和效率[7];片外支持DDR2高速存储器,提高了存储器控制器访问外部存储器的速度。这一系列的措施,使得S698PM芯片较其它同类型芯片在性能上有了大幅度的提升。
使用基准测试程序Dhrystone和Whetstone分别对S698PM芯片的整型处理能力和浮点处理能力进行测试。Dhrystone是测量处理器运算能力最常见的基准程序之一,常用于处理器整型运算性能的测量。Dhtrystone基准程序由主程序和3个函数、8个过程组成。各函数和过程分别用来测试字符串、记录及整数运算。Dhrystone的计量单位为DMIPS。Whetstone用于测浮点计算能力,计算单位是MFLOPS。S698PM在各个频点的性能指标数据如图3。

图3 S698PM芯片在不同主频时的处理性能实测值
将S698PM芯片做横向比较,汇总各类官方数据,对比目前市场上主流高可靠嵌入式SPARC SOC芯片的处理能力及性能(为了便于比较,所有SOC芯片的综合处理性能指标统一换算为DMIPS/MHz,浮点处理性能指标统一换算为MFLOPS/MHz),可得出如下几种比较图:
图4 SPARC SOC芯片最高主频比较图

图5 SPARC SOC芯片处理性能比较图
可以看出:S698PM SOC芯片无论是最高频率还是综合处理性能、浮点处理性能等方面都很有优势。
4 FFT算法在平台上的设计与实现
FFT算法是频域图像处理中最重要的核心算法之一,是影响数字图像处理软件系统整体效率的关键,工程实用性强。FFT具有原位性特征,较适合进行并行运算处理。
传统设计多采用AT697与VxWorks5.4操作系统实现FFT算法,速度较慢,难以满足日益增长的高速数据处理要求。本设计采用S698PM处理器和VxWorks6.7操作系统实现FFT算法,通过多核并行,大大提高运算效率。设计的难点是处理好FFT算法本身的并行化以及实现S698PM 4个处理器核的协调工作。
FFT的一般输入形式是一组包含N个复数的数组。N一般是2的幂次级。有许多不同的方法来实现FFT,但最典型的是时间抽取法[8]。以8个数据输入点的FFT变换为例,时间抽取的蝶形变换方法如图6。

图6 FFT时间抽取的蝶形变换图
左边的x[i]是FFT输入,右边的x[i]是FFT输出,箭头表示每个中间阶段的输入到输出。
蝶形运算的一般规律:原位运算。观察8点DIF-FFT运算流程图可以归纳出来,其每级每列计算都是由N/2个蝶形运算构成,由1次复数乘法和2次复数加减法组成。
某一列的任何2个节点k和j的节点变量进行蝶形运算后,得到结构为下一列k,j两节点的节点变量,与其他节点无关,所以可以采用原位运算。计算完一级后立刻把结果存进原来的内存单元,再进行下一级的运算。那么输入到结果输出其内存单元不变,如N=1024,则整个FFT只需要1024个长整型单元即可。这样就可以大量节省储存单元,方便处理器低资源运行。
分析图6可以看出,如果是2个CPU核参与并行处理,可以完全并行完成到最后阶段,不需要CPU之间的数据交换。在最后一个阶段,每个CPU需要使用其他CPU产生的结果,因此需做同步处理,等待所有CPU都处理完成后再进行。而如果是4 个CPU参与并行处理,并行处理可以进行到倒数第二阶段,之前都不需要进行数据交换。而倒数第二阶段和最后一个阶段开始之前都需要进行CPU同步,等待所有CPU处理完成后再进行。
一般来说,阶段数M与输入点数N的关系为M=log2N。例如8192个输入点的FFT运算,总共有13个阶段需要处理。前11阶段,即大部分工作,可以完全独立地在4个CPU上并行完成,每个CPU处理一块2048个点的输入。以上处理完后需要同步,再并行完成倒数第二阶段运算,之后再同步,并行完成最后一个阶段的运算。
系统上电时,CPU0开始运行,CPU1/CPU2/CPU3处于关闭模式,CPU0执行其对应的VxWorks任务,在任务中使能其它3个CPU。其它的CPU被唤醒后,开始执行属于自己的VxWorks任务,任务的主要功能是进行FFT运算处理,任务最开始是等待一个信号量A,这个信号量由CPU0给出。
当CPU0在任务中建立了测试数据,完成了数据队列排序,初始化好共享内存中的控制块后,向其它CPU发送信号量A,并进入运算流程。其它CPU得到信号量A后开始并行处理当前阶段的FFT运算,运算完成后向CPU0发送信号量B,然后返回到之前等待信号量A的状态。CPU0收到所有CPU发送过来的信号量B后,表示所有CPU完成了工作,结束本阶段的运算处理,进入下一个运算阶段,下一阶段的执行过程与上述相同。最后阶段完成后,FFT的运算结果会保持在制定内存中,CPU0负责打印输出结果。
基于VxWorks操作系统的FFT程序编辑完后,使用SPARC编译器进行编译。运行DMON调试器,连接S698PM硬件平台后下载程序并执行,观察到的程序运行结果如图7。

图7 FFT算法程序在S698PM平台上的执行结果
以上的测试条件为:8192个输入点,100次FFT循环计算;S698PM处理器启用了L2高速缓存,处理器主频为400MHz,总线频率200MHz。对比同等条件下在S698P4处理器平台以及AT697平台下的测试结果,最终测试数据比较如图8所示。

图8 FFT运算运行结果分析
实测表明:在设计合理的情况下,使用S698PM处理器4核进行FFT运算比使用单核运算,运算速度提高了3.26倍,对比AT697处理器平台,运算速度提高了约20倍。实验数据充分说明:S698PM处理器无论是峰值处理能力还是并行化运算性能都比前代产品有了较大的提升。
5 结束语
综上所述,S698PM是一款高可靠、高性能、高集成度的SPARC V8 SMP架构多核SOC芯片,其设计合理,片上外设资源丰富,芯片可广泛应用于航空、航天领域,特别适用于需兼顾大量运算和复杂控制的宇航电子系统。同时,S698PM芯片的软件支持到位,支持多种嵌入式操作系统,专门设计的操作系统BSP包降低了用户使用多核处理以及开发并行应用程序的门槛,并且这些软件系统都经过了大量的应用验证。
猜你喜欢
测控技术(2018年8期)2018-11-25
时代英语·高二(2017年4期)2017-08-11
解放军健康(2017年5期)2017-08-01
单片机与嵌入式系统应用(2015年1期)2015-09-12
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
单片机与嵌入式系统应用(2013年2期)2013-08-14
电子设计工程(2013年10期)2013-08-10
赤峰学院学报·自然科学版(2012年19期)2012-10-14
微处理机(2012年4期)2012-06-13
