
基于嵌入模型的混合式相关缺陷关联方法∗
2019-06-11 07:39吴逸文王怀民
软件学报 2019年5期
张 洋,王 涛,吴逸文,尹 刚,王怀民
1(国防科技大学 并行与分布处理国防科技重点实验室,湖南 长沙 410073)
2(国防科技大学 计算机学院,湖南 长沙 410073)
社交化编程(social coding)最早由开源社区GitHub提出,旨在提供一个对开发者友好的软件开发环境,帮助开发者进行高效的互联、协同、开发[1].社交化编程的出现,极大地增强了代码复用[2]以及缺陷解决效率[3];开发者可以自主地参与报告和讨论缺陷,这样一来,缺陷报告作为一类重要的软件开发知识,经常会被不同开发者在不同的时间报告出来;实践中经常会出现两个缺陷报告含有相关的信息,开发者可以在缺陷讨论过程中,通过URL链接将相关的缺陷报告关联起来[4].
链接相关缺陷的过程,对于开发者快速、有效地修复缺陷是十分重要的.当一个开发者提交一个新缺陷报告后,其他开发者会参与讨论并对这个缺陷的价值进行评价.在他们的讨论过程中,参与者可能会链接相关的其他缺陷报告来寻找可能有用的资源和信息.最终,受助于这些链接和讨论,缺陷被解决和关闭.然而,现实世界的链接过程需要耗费大量的时间和人力.尤其对于那些规模庞大的软件项目,开发者可能需要查找大量的历史缺陷数据,才能通过它们的文本描述信息定位到相关的缺陷,并且这样的基于人工的关联方法主要依赖于个体开发者的经验和知识.因此,设计并实现自动化的缺陷关联方法能够帮助开发者更加聚焦他们的缺陷解决,也能够帮助项目管理者获取缺陷间的关联关系,从而提高软件的开发、维护效率.
本文以开源社区 GitHub中的软件项目为研究对象,主要聚焦 GitHub中缺陷之间的自动化关联问题.因为GitHub是目前全球最大、最著名的开源社区,截止2018年3月,它已经托管了超过8千万的软件版本库.近年来,学术界也产生了大量基于GitHub数据开展的研究工作[2-6].一方面,在传统的缺陷跟踪系统中,例如BugZilla,目前学术界和工业界已经出现了很多辅助开发者进行重复缺陷检测[7]、缺陷定位[8]、相似缺陷推荐[9]的方法,然而针对GitHub缺陷跟踪系统的缺陷关联研究目前尚未出现;另一方面,现有相关工作提出的方法主要基于传统的信息检索(IR)技术,通过自动化地抽取给定缺陷报告的文本信息(由单词、句子组成)来搜索相关缺陷报告或文件,例如余弦相似度(cosine similarity)和TF-IDF.但传统的IR技术主要关注语料库中单词与单词之间的关系,忽略了单词的上下文语义信息.最近,一些自然语言处理(NLP)领域的研究工作开始利用深度学习技术[10-12],例如词嵌入模型,对单词的上下文信息进行刻画.并且,一些研究者也开始尝试利用深度学习技术来解决软件工程问题并取得了不错的结果[13-15].
在本文中,我们将关联相关缺陷的问题抽象为推荐(recommendation)任务,为了解决该任务,我们提出了一种基于嵌入模型的混合式相关缺陷关联方法.该方法将传统的IR技术(TF-IDF)与深度学习技术(词嵌入模型和文档嵌入模型)结合起来,能够自动化地为新缺陷推荐相关的缺陷报告.对于我们数据库中的每个缺陷报告,我们将其文本信息(标题和描述)抽取出来并保存到文档里.接下来,我们利用3种子方法(TF-IDF、WE和DE)分别表征每个缺陷文档的向量,并计算他们之间的相似度得分.其中,TF-IDF主要从词频的角度提取不同单词间的关联关系,WE和DE则分别从单词和文档出现的上下文角度提取单词间以及文档间的关联关系.最后,我们将3个子方法得到的相似度得分相加得到最终得分,进而基于该得分对相关缺陷进行推荐.
为了评价本文方法的有效性,我们选取了两个著名的 GitHub项目作为研究对象:Request项目和 Moment项目.在实验验证过程中,我们将本文方法和4种基准方法(baseline approach)进行比较,包括NextBug[9]以及我们的3种子方法.具体来说,我们设计了以下4个具体研究问题.
· RQ1:与基准方法相比,本文方法在性能上可以有多少提升?
· RQ2:本文方法对于缺陷语料库是否有很强的依赖性?
· RQ3:本文方法对于训练集规模的依赖如何?
· RQ4:本文方法的训练时间开销如何?
实验结果表明,基于嵌入模型的混合式相关缺陷关联方法充分地考虑了软件缺陷的词频和上下文信息,可以明显地提高基准方法的性能;并且对于不同的缺陷语料库,本文方法的性能仍然具有一定的可靠性;且本文方法的训练时间开销较小,具有很高的应用扩展性.
本文第 1节对相关研究背景进行介绍,结合相关工作引出本文研究问题及方法.第 2节详细介绍本文提出的方法框架和技术细节.第 3节对实验验证的方法和评价指标进行介绍.第 4节介绍具体研究问题下的实验结果.第5节介绍案例分析.最后总结全文.
1 研究背景
为了更好地阐述本文工作,我们首先对相关背景知识和相关工作进行介绍.
1.1 语义相似度与嵌入模型
测量两个文本的语义相似度是一类经典的研究问题,现有的解决模型也从向量空间模型(例如 TF-IDF)、n-gram语言模型、主题建模(例如LDA[16])向更多的基于人工神经网络的语言模型[11,12,17]发展.2013年,Mikolov等人[11,12]提出了两个基于人工神经网络的语言模型,分别是continuous bag-of-words和continuous skip-gram,并针对大规模文本数据提出了有效的负采样(negative sampling)方法.
词嵌入模型(word embedding,简称WE)[11,12]是自然语言处理领域非常著名的深度学习模型,它主要将每个单词映射到n维的向量空间.词嵌入模型主要基于这样的假设,即出现在相似上下文的单词间通常会有相似的语义.因为表征单词的每个维度都代表着单词的语义或语法特征,因此越相似的两个单词会在向量空间中具有越近的向量距离.
文档嵌入模型(document embedding,简称 DE)[10]旨在对词嵌入模型进行扩展,以实现更高级别(文档级)的向量表示.在其训练过程中,每个文档都映射到一个唯一的向量,由矩阵中的列表示,每个单词也映射到一个唯一的向量.然后对文档向量和单词向量进行平均或连接处理,以预测上下文中的下一个单词.
由于词嵌入模型和文档嵌入模型都是从未标记的数据中学习的,因此可以适用于没有足够标签数据的任务.此外,嵌入模型更侧重于单词和文档的上下文,所以可以很好地补充传统的 IR技术,例如,TF-IDF.最近,一些研究表明,嵌入模型在软件工程任务中也表现良好[13,14].例如,Xu等人[13]将预测语义可链接的知识单元问题(即stack overflow中的帖子及其回答)抽象为多类别分类问题,并使用词嵌入模型和CNN解决该问题.Ye等人[14]提出,可以通过将自然语言语句和代码片段作为共享表示空间中的含义向量进行投影,来拟合词汇差距.他们在API文档、教程和参考文档上训练了词嵌入模型,然后将它们聚合在一起,来计算文档之间的语义相似性.这些研究的提出,促使了我们将嵌入模型整合到我们的方法中.
1.2 缺陷修复和重复缺陷检测
在缺陷跟踪系统中,缺陷修复一直是一个复杂、需要不断迭代且耗时的过程,它涉及整个开发人员社区,从而引发特定的协同问题[18].已有的对于缺陷解决过程的研究主要关注缺陷分类[19]和推荐相关开发者[20].其中,Guo等人[21]分析了缺陷修复过程如何受人们的声誉、缺陷报告编辑活动以及地理和组织关系的影响.Zimmermann等人[22]使用混合式方法来表征缺陷re-open的过程,并定量评估了各种因素的影响.最近,对缺陷修复过程的研究扩展到去链接其他相关资源,例如相关代码提交[23]、相关文件[24]和来自问答网站的相关帖子[25].具体来看,Bachmann等人[23]提出了一个名为Linkster的工具,以便于识别缺陷与代码提交之间缺失的链接信息.Ye等人[24]引入了一种自适应排序方法来关联相关的领域知识,它主要通过功能性地分解源代码文件、代码中使用的库组件的 API方法描述、缺陷修复历史等.我们之前的研究[25]也探讨了缺陷严重性与链接 Stack Overflow问答网站帖子的大众属性之间的相关性.
为了帮助修复缺陷,许多研究开始分析重复缺陷检测问题[7,26].例如,Wang等人[26]通过分析缺陷报告和执行信息中的文本信息,来检测两个缺陷报告是否相互重复.Sun等人[7]提出了一种信息检索方法 REP来识别重复的缺陷报告.REP考虑了缺陷报告中提供的更多信息,并扩展了BM25F方法以更准确地测量文本相似性.最近,一些研究人员开始研究相似缺陷报告推荐的问题,例如Rocha等人[9]提出了一种名为NextBug的推荐方法,依靠传统的信息检索技术来计算缺陷报告之间的余弦相似度.他们的结果显示,用于相似缺陷推荐的 NextBug在性能上优于之前的重复缺陷报告检测技术REP.在本文的后续实验中,我们也将NextBug作为基准方法之一,用以参照比较本文方法的性能.
1.3 GitHub中的缺陷关联问题
在 GitHub中,每个托管的项目都与一个缺陷跟踪系统相关联,该系统提供缺陷跟踪过程中的常用功能,例如提交缺陷报告、根据缺陷的性质进行标记、标记缺陷不同时间点的解决状态等[27].GitHub中的缺陷解决过程是一个协同且复杂的过程:在开发者提交新的缺陷报告后,其他开发者会参与讨论并对该缺陷进行评估,以确定是否值得解决,如果是,则优先考虑该缺陷的解决过程.关联的链接可以视为缺陷解决过程中的重要一步,因为在讨论过程中,利益相关者可能会在评论中链接其他相关缺陷报告来提供他们认为有用的资源和信息.因为使用了Flavored Markdown技术,在GitHub平台上,开发者可以轻松链接到相同项目的另一个缺陷报告(如图1所示,在缺陷request/request#2397中,开发者tzachshabtay进行了评论并给了一个链接,指向编号234的缺陷报告).最终,在这些链接和讨论的帮助下,该缺陷将被解决和关闭.
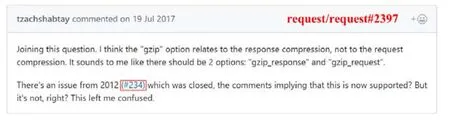
Fig.1 An example of issue linking in the GitHub project图1 GitHub项目中缺陷链接的示例
为了及时起到作用,关联相关缺陷报告的链接应该被迅速地发现和提出.但实际上,这些链接出现的时机主要取决于各个开发者的经验和知识,所以会产生很多不同.而现实世界查找相关缺陷报告并进行链接的过程是非常耗时的,很大程度上依赖开发者人工的搜索和定位.例如,图2显示了Moment项目中实际链接相关缺陷报告的时间延迟分布(在我们统计中,时间延迟表示从缺陷创建到第 1个链接出现的时间,以天为单位).我们发现,Moment项目的开发者平均需要37.9天(中位数:2.8天)才能链接到相关缺陷报告,并且箱图中有许多异常值,这表示在很多缺陷报告中,开发者需要更长的时间才能发现相关的缺陷报告.
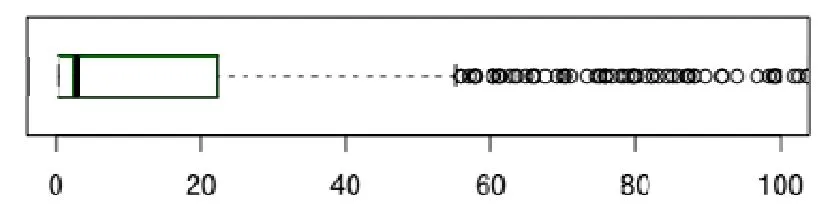
Fig.2 Distribution of link latency (day) in Moment project图2 Moment项目中链接延迟(天)的分布
因此,我们需要能够用于链接GitHub项目中相关缺陷的自动化工具.尽管在传统的缺陷跟踪系统中已经提出了许多用于链接相关缺陷资源的自动化方法[7-9],但据我们所知,目前还没有研究对 GitHub项目中的缺陷自动链接问题进行过分析.通过本文,我们试图对这一类问题进行研究,并提出缺陷自动关联的初步方法.
2 方法概述
本文将相关缺陷自动关联问题抽象为推荐问题,即对于开发者给出的查询缺陷,我们的任务是自动化地推荐与该缺陷相关的其他缺陷.下面我们将详细地介绍我们的方法框架和技术细节.
2.1 总体框架
图3显示了本文方法的整体框架.首先,我们从所有缺陷数据中提取它们的文本信息.然后,对于每个缺陷报告,我们将其标题和描述组合到一个文档中.接下来,我们使用以下步骤预处理这些缺陷文档.
· 步骤1:从每个缺陷文档中提取所有单词.
· 步骤2:删除停用词、数字、标点符号和其他非字母字符.
· 步骤 3:使用 Lancaster stemmer技术(https://www.scientificpsychic.com/paice/paice.html)将剩余的单词转换为它们的根形式,以减少特征维度并将相似的单词统一为一个共同的表示.例如,像“interests”这样的复数名词将被替换为单数形式的“interest”,诸如“ate”、“eaten”和“eating”等表示不同时态的形式将被替换为不定形式“eat”.
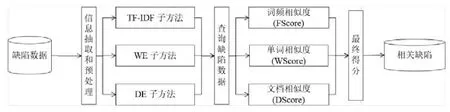
Fig.3 Framework of our approach图3 本文方法的总体框架
基于预处理过的缺陷文档数据,我们分别使用 3种子方法(TF-IDF,WE和 DE)来计算查询缺陷和每个候选缺陷之间的相似性得分(FScore:词频相似度;WScore:单词相似度;DScore:文档相似度).虽然这3个得分都可以代表缺陷间的相似性,但它们之间是互相补充的,因为:
·FScore是基于TF-IDF子方法生成的,它更关注缺陷之间的词频关系,主要考虑整个缺陷语料库中的出现的单词频率信息.
·WScore是基于WE子方法生成的,它更侧重于单词的上下文信息.
·DScore是基于DE子方法生成的,它更侧重于缺陷文档之间的相关性.
最后,我们将这 3个分数相加,得到每个缺陷对之间的最终相似度得分,并根据这一得分推荐相关缺陷.其中,得分越高说明两个缺陷报告之间的语义相似度越高.
接下来,我们详细介绍3种子方法的技术细节.
2.2 TF-IDF子方法
TF-IDF(term frequency-inverse document frequency)是目前最流行的信息检索技术之一,图4表示了TF-IDF的简要工作流程,其主要思想是:如果一个单词在一个文档中出现多次而在其他文档中只出现很少次数,则该单词具有区分文档的良好能力,因此该单词具有高TF-IDF值.

Fig.4 Brief process of TF-IDF sub-method图4 TF-IDF子方法的简要流程
特别地,给定一个单词t和一个文档集合D={d1,d2,…,dN},我们可以利用如下所示的公式计算文档di中单词t的TF-IDF值.
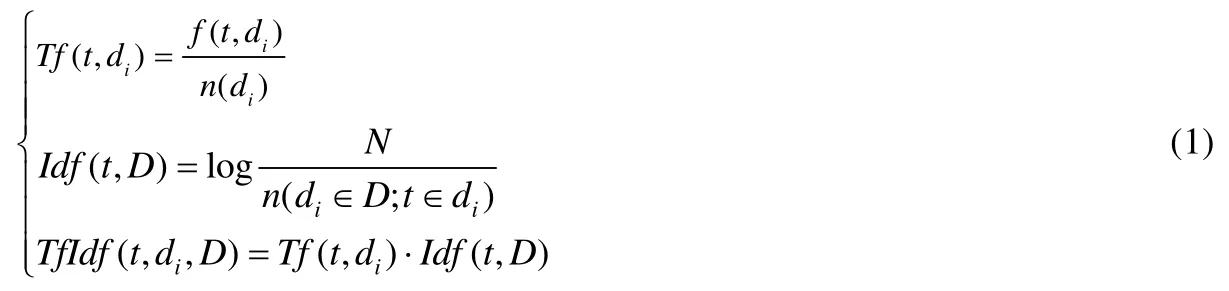
其中,f(t,di)表示单词t出现在文档di中的频率,而n(di)表示文档di中的单词总数.之后,我们通过使用余弦相似度来计算两个文档的相似性,因为它是目前一种流行的计算相似度的方法,并且已经被证明非常适用于TF-IDF向量.因此,给定两个TF-IDF向量Vf1和Vf2,它们的词频相似度得分FScore计算方法如下.

2.3 WE子方法
Mikolov等人[11,12]提出了一种流行的词嵌入模型,称为continuous skip-gram,它可以有效地训练并支持各种语言任务的处理.因此在本文方法中,我们使用该continuous skip-gram模型来获取词嵌入向量.为了学习目标词的向量表示,该模型将上下文信息定义为围绕目标词的固定数量的词(如图5所示).
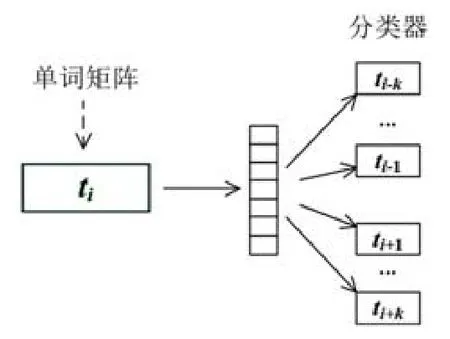
Fig.5 Brief process of WE sub-method图5 WE子方法的简要流程
因此,给定一个单词集合T={t1,t2,…,tn}和目标单词ti以及上下文窗口大小k.Continuous skip-gram模型的目标是最大化以下阈值Lt.
其中,ti-k,…,ti+k是目标单词ti的上下文.概率Pr(ti-k,…,ti+k|ti)的计算公式如下.
其中,我们假设上下文单词和目标单词是相互独立的.此时,Pr(ti+j|ti)定义如下.

其中,It和Ot是单词t的输入和输出向量,T是所有单词的词汇集合.通过训练整个语料库,语料库词汇表中的所有单词可以表示为δ维向量,其中,δ是可变参数并且通常被设置为诸如200的整数.
之后,我们将每个单词转换为固定长度的向量.这样,每个文档可以表示为一个矩阵,其中每行代表一个单词.考虑到不同的文档具有不同数量的单词,我们通过平均文档包含的所有单词向量将文档矩阵转换为一个向量.特别地,给定具有n行的文档矩阵,我们将矩阵的第i行表示为ri,并且利用如下公式生成变换的文档向量Vt.

最后,对于给定的两个文档向量Vw1和Vw2,我们同样使用余弦相似度来测量它们的单词相似度得分WScore,计算公式如下.

2.4 DE子方法
为构建文档嵌入模型,我们使用向量分布的bag of words(PV-DBOW)方法[10].它作为skip-gram的实例,能够学习任意长度单词序列的向量表示,例如句子、段落,甚至整个大文件.图6显示了文档嵌入模型的简要流程.
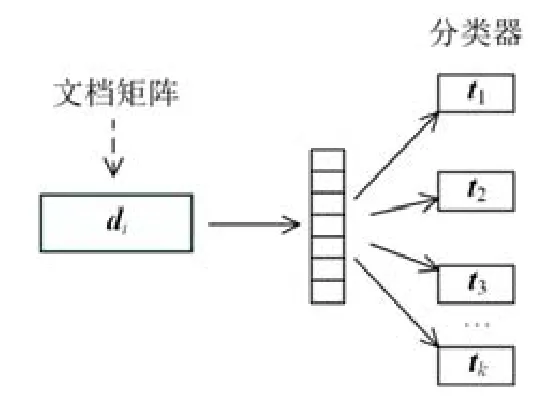
Fig.6 Brief process of DE sub-method图6 DE子方法的简要流程
具体地,给定一组文档D={d1,d2,…,dN}和从文档di中采样的单词集合T(di)={t1,t2,…,tk},模型可以学习出一个文档di(每个单词tj来自T(di)采样)的δ维嵌入向量(V∈Rδ,t∈Rδ).该模型通过分析在文档di中出现单词tj
dij的频率并试图使下面的阈值Ld最大化.

其中,概率Pr(tj|di)的计算公式如下.

其中,T是D中所有文档中所有单词的词汇集合.最后,给定两个文档向量Vd1和Vd2,我们计算其文档相似度得分DScore如下.

3 实验验证
为了评估本文方法的有效性,我们对GitHub项目进行了实证研究.下面我们分别从实验数据、Ground truth构建、评价指标和实验设置这4个方面进行阐述.
3.1 实验数据
我们选择了两个著名的 GitHub项目作为我们的研究对象:Moment(一个轻量级的 JavaScript日期库)和Request(一个简化的HTTP请求客户端).我们选择它们主要有两个原因.
(1) 它们非常著名,并且在GitHub上有很多stars和forks.
(2) 它们都是具有较长生命周期的活跃项目,拥有众多经验丰富的开发者以及大量历史数据.
表1总结了它们的基本统计数据(截至2018年4月).我们可以发现,它们都很早就在GitHub上托管并且有很多的缺陷报告数据(超过千个).

Table 1 Basic descriptive statistics of studied two projects表1 两个研究项目的基本数据统计
使用GitHub API,我们收集了2018年4月之前两个项目的所有缺陷报告数据,包括缺陷ID、缺陷状态(开放、关闭)、缺陷标题和描述等.
3.2 Ground truth构建
我们的Ground truth构建主要基于实际出现的缺陷URL链接,即如果两个缺陷报告之间存在URL链接,我们认为它们是相互关联的.具体来说,我们定义缺陷A和缺陷B是一对链接对,(A,B)或A→B,当且仅当在缺陷A的讨论中包含链接到缺陷B的URL链接.在实际解析过程中,我们使用GitHub的“cross-referenced”API来查找项目所有缺陷的链接信息.
请注意:在本文工作中,我们只考虑项目内部链接,暂不考虑跨项目的缺陷链接.最后,我们在Request项目中总共发现了1 110个缺陷链接对,在Moment项目中发现了2 406个缺陷链接对.
3.3 评价指标
为了评估我们方法的有效性,我们使用了 3个评价指标:Top-k召回率(R@k)、平均精度(MAP)、平均排序等级(MRR),它们通常被用于评估软件工程任务中的推荐系统性能[8,9,15].特别地,给定一个待查询缺陷i,我们将其实际的缺陷链接集合定义为Lk(i),并将推荐系统产生的top-k推荐集合定义为R(i).下面我们介绍R@k、MAP和MRR的具体计算过程.
·R@k:其目的是检查top-k推荐结果是否正确.对于待查询缺陷i,其R@k可以计算如下.

· MAP:它被定义为所有评估查询结果获得的平均精度值(AvgPrec)的平均值.单个待查询缺陷i的AvgPrec计算方法如下.

其中,Prec@k是排名列表中top-k问题的检索精度,即top-k推荐中存在待查询缺陷i的实际缺陷链接数目的百分比.
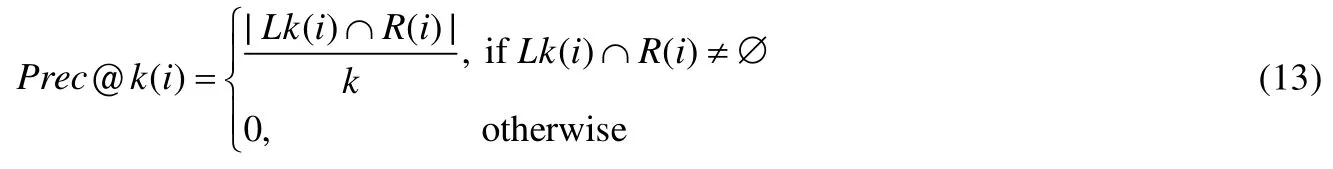
· MRR:它被定义为所有推荐结果对应的倒数排序(reciprocal rank,简称 RR)值的平均值,其中,单个查询缺陷i的RR值是第1个正确答案的排序firsti的倒数.
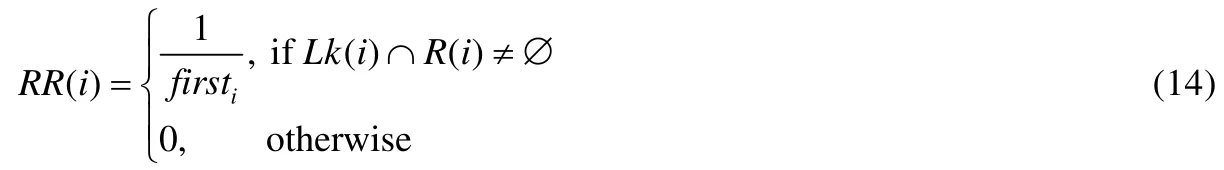
3.4 实验设置
在我们的实验中,我们将数据集内拥有实际链接的、所有已关闭的缺陷都视为待查询缺陷.给定一个待查询缺陷i,我们按照与i的相似性得分大小将所有待判断缺陷进行排序,从而推荐top-k个最相似的缺陷.需要注意的是,我们只推荐在待查询缺陷i产生之前出现的缺陷,即它们的缺陷ID必须小于i的ID.在具体代码中,我们主要使用Python的Gensim包来实现我们的嵌入模型方法.特别地,对于WE和DE子方法,我们将上下文窗口大小s设置为5,将初始学习速率α设置为0.025,并且将表征向量d的维度设置为200.
4 实验结果
在本节,我们介绍具体的实验结果.根据设计的 4个研究问题,我们分别对每个研究问题的研究动机、分析方法、分析结果进行详细阐述.
4.1 RQ1:与基准方法相比,本文方法在性能上可以有多少提升?
4.1.1 研究动机
在第 1个研究问题中,我们试图调查本文方法在缺陷自动化关联任务中的有效性.此外,由于本文方法结合了TF-IDF和深度学习技术来计算两个GitHub缺陷文本之间的语义相似性,我们希望分析这种混合式方法是否以及在多大程度上可以改善现有的方法和我们的3种子方法的性能.
4.1.2 分析方法
因为目前并没有专门针对 GitHub缺陷自动关联问题提出的方法,所以我们将本文方法与传统缺陷跟踪系统中最先进的方法(NextBug[9])进行比较.NextBug主要基于传统的IR技术,依靠余弦相似度得分来推荐相似的缺陷报告.此外,为了验证我们的混合式方法的优越性,我们将本文方法与我们的3种子方法(TF-IDF、WE和DE)进行比较.因此,我们在实验中设置了4种作为参考比照的基准方法:NextBug、TF-IDF、WE和DE.通过分别使用本文方法和基准方法对Request项目和Moment项目缺陷数据进行训练、测试,我们比较了不同方法在R@1、R@5、R@10、MAP和MRR评价指标值上的差异.
4.1.3 分析结果
(1) Request项目:图7给出了在Request项目缺陷数据中,进行相关缺陷推荐的性能比较结果.
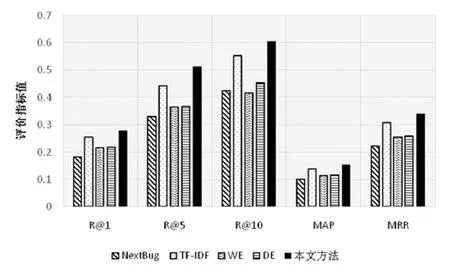
Fig.7 Performance comparison results in Request project图7 Request项目内各方法性能比较结果
我们发现,本文方法可以实现较高的推荐性能.其中,R@1值为 27.7%;R@5值为 51.2%;R@10值更是达到60.6%,即当推荐10个候选缺陷时,有60.6%的概率候选缺陷即为真正的实际关联缺陷.
其次,我们发现本文方法在所有评价指标上都优于NextBug.相对于NextBug的性能值,本文方法在R@1、R@5、R@10、MAP和MRR上分别提升了51.4%、56.1%、42.9%、53.0%和52.0%.
此外我们发现,与我们的3种子方法相比,本文方法在所有指标方面也实现了更好的性能.相对于3种子方法性能值,本文方法分别在R@1、R@5、R@10、MAP和MRR上提升了9.1%~28.8%、15.6%~40.3%、9.4%~19.0%、10.9%~34.2%和10.8%~33.5%.
(2) Moment项目:图8给出了在Moment项目缺陷数据中,进行相关缺陷推荐的性能比较结果.
我们同样发现,本文方法可以实现较高的推荐性能.其中,R@1值为22.2%;R@5值为40.0%;而R@10值达到49.5%,即当推荐10个候选缺陷时,有49.5%的概率候选缺陷即为真正的实际关联缺陷.
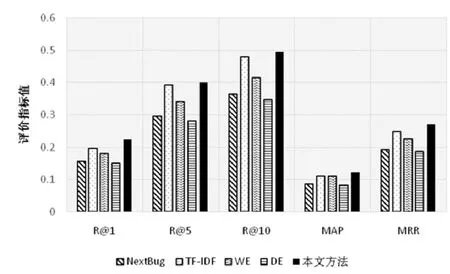
Fig.8 Performance comparison results in Moment project图8 Moment项目内各方法性能比较结果
我们同样发现,本文方法在所有评价指标上都优于 NextBug.相对于 NextBug的性能值,本文方法分别在R@1、R@5、R@10、MAP和MRR上提升了41.4%、35.1%、36.0%、40.7%和40.4%.
此外,我们同样发现,与我们的3种子方法相比,本文方法在所有指标方面也实现了更好的性能.相对于3种子方法性能值,本文方法分别在R@1、R@5、R@10、MAP和MRR上提升了12.7%~47.0%、2.0%~42.3%、2.9%~42.7%、9.0%~45.8%、10.9%~34.2%和9.3%~45.7%.
小结:总的来看,本文方法可以很好地抽取缺陷文档内单词和文档的上下文信息,在推荐性能上要优于现有的NextBug方法.此外,混合式的推荐方法在性能上也优于单独的3种子方法.
4.2 RQ2:本文方法对于缺陷语料库是否有很强的依赖性?
4.2.1 研究动机
在本文方法中,我们从每个项目的缺陷文本中学习语料库和嵌入模型,这些缺陷语料库反映了开发者报告缺陷的方式以及它们使用的词汇特点.因此,在第 2个研究问题中,我们想要研究从不同项目的缺陷语料库中学习嵌入模型是否以及在何种程度上会影响本文方法的性能.对该问题的研究将有助于我们理解合适的语料库对于特定项目相关缺陷推荐任务的重要性.
4.2.2 分析方法
我们通过交叉使用Request项目和Moment项目的缺陷语料库来验证本文方法的推荐性能,即对于Request项目和Moment项目,我们分别使用它们自身的缺陷语料库和另外一个项目的缺陷语料库来进行测试.
4.2.3 分析结果
(1) Request项目:图9给出了在Request项目中使用不同项目缺陷语料库时的性能比较结果.
我们发现,对于 Request项目,与从它自己的缺陷语料库学习相比,从其他项目的缺陷语料库中学习会降低本文方法的性能.具体而言,在R@1、R@5、R@10、MAP和MRR上,本文方法的性能分别下降了6.6%、12.6%、14.3%、4.3%和8.2%.
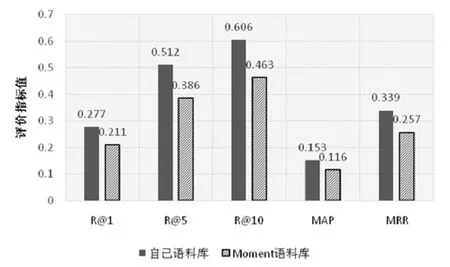
Fig.9 Performance comparison results when using different issue corpus in Request project图9 Request项目内使用不同缺陷语料库的性能比较结果
(2) Moment项目:图10给出了在Moment项目中使用不同项目缺陷语料库时的性能比较结果.
我们发现,对于 Moment项目,与从它自己的缺陷语料库学习相比,从其他项目的缺陷语料库中学习同样会降低本文方法的性能.具体而言,在R@1、R@5、R@10、MAP和MRR上,本文方法的性能分别下降了5.7%、7.1%、8.7%、2.8%和6.1%.
然而我们发现,虽然使用其他项目的缺陷语料库时本文方法的性能会下降,但本文方法仍然要优于基准方法NextBug.在Request项目中,本文方法在各个评价指标上比NextBug有至少9.2%的提升;在Moment项目中,本文方法在各个评价指标上比NextBug有至少5.1%的提升.
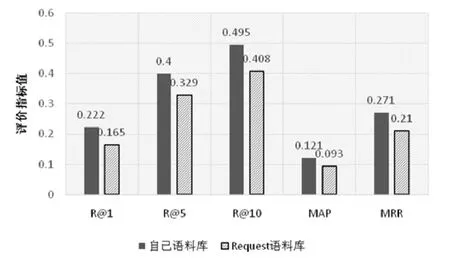
Fig.10 Performance comparison results when using different issue corpus in Moment project图10 Moment项目内使用不同缺陷语料库的性能比较结果
小结:实验结果显示,特定、合适的项目缺陷语料库可以给本文方法带来更好的性能.但是,即便利用其他项目的缺陷语料库来学习嵌入模型,本文方法的推荐结果仍然具有一定的可靠性.
4.3 RQ3:本文方法对于训练集规模的依赖如何?
4.3.1 研究动机
因为本文方法所有的子方法(IF-IDF、WE和DE)都需要在一定规模的数据集上进行训练,所以我们需要考虑训练集规模对于本文方法性能的影响.因此,在第 3个研究问题中,我们希望分析本文方法在不同规模训练集下性能的变化.
4.3.2 分析方法
我们分别根据Request项目和Moment项目的训练集规模,按照10%,20%,…,100%的比例各分为10组训练集,并对基于不同规模训练集训练得到的模型进行性能测试和比较.
4.3.3 分析结果
图11和图12分别显示了在Request项目和Moment项目中,使用不同规模的训练集,本文方法在R@1、R@5、R@10、MAP和MRR上的指标值变化情况.我们发现,与其他机器学习算法相似,本文方法在不同规模训练集下的性能存在差异.例如在Request项目中,使用10%缺陷数据用于训练,本文方法的R@10值仅为0.25;而当使用90%缺陷数据用于训练时,R@10值可达到0.57,非常接近我们前面的测试结果0.61(100%训练集).同样,在Moment项目中,使用10%缺陷数据用于训练时,本文方法的R@10值仅为0.25;而使用90%缺陷数据用于训练时,R@10值可达到0.46,接近我们前面测试结果0.50(100%训练集).
另外,我们发现,随着训练集规模的增加,在Request项目和Moment项目中,各个指标值均有增长趋势.这表示大量的模型训练样本将有助于进一步提高本文方法的性能.
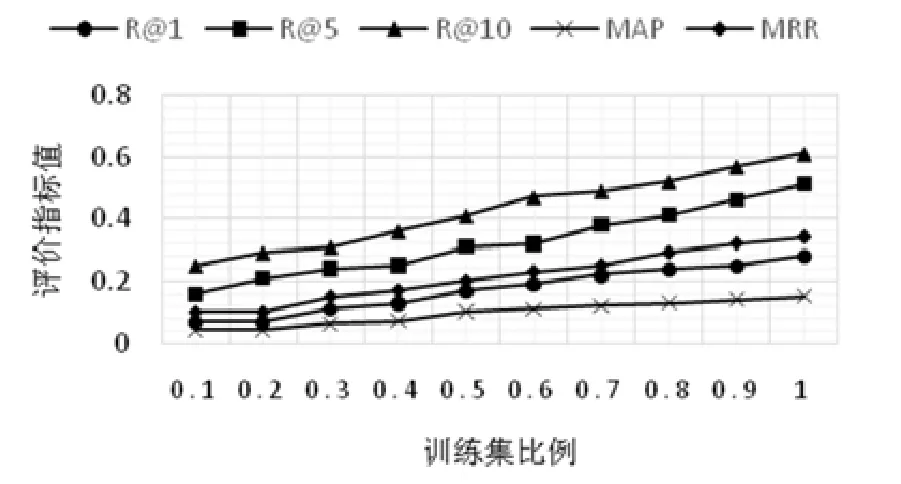
Fig.11 Performance comparison results when using different scale of training dataset in Request project图11 Request项目内使用不同规模训练数据集时的性能比较结果
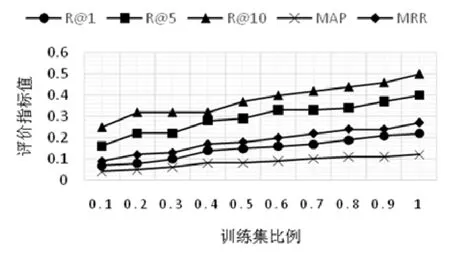
Fig.12 Performance comparison results when using different scale oftraining dataset in Moment project图12 Moment项目内使用不同规模训练数据集时的性能比较结果
小结:本文方法的性能随着训练集规模不同会产生差异,训练集规模越大,本文方法的性能越好.下一步可以设计实现增量式的模型训练方法,即每次只针对新加入的缺陷数据进行训练,从而降低模型的训练成本.
4.4 RQ4:本文方法的时间开销如何?
4.4.1 研究动机
因为本文方法所有的子方法(IF-IDF、WE和DE)都需要进行预处理和训练才能用于实际的推荐任务,因此我们需要考虑模型训练的时间开销问题.因此,在第4个研究问题中,我们希望分析本文方法的训练时间开销,以了解本文方法的实用性.
4.4.2 分析方法
我们通过记录程序执行的开始时间和结束时间,来获得本文方法的训练时间开销.实验运行在 Windows 8 OS(64位),8GB RAM,Intel(R)Core(TM)i5 2.6GHz的PC上.
4.4.3 分析结果
在我们的训练过程中,Request项目包含了2 896个缺陷报告和223 595个单词(预处理后),其词汇量(单个单词数)大小为129 750.而Moment项目包含了4 509个缺陷报告和287 757个单词,其词汇量为153 673.图13给出了本文方法的训练时间开销统计结果.
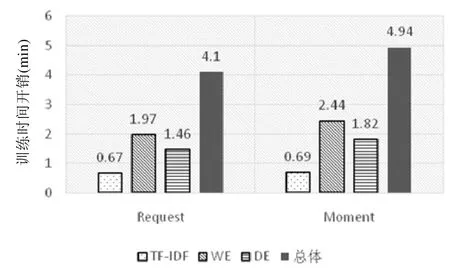
Fig.13 Training time cost in minutes图13 训练时间开销(min)
我们发现,在两个项目中,TF-IDF子方法比其他两个子方法都需要更少的训练时间,因为它只训练所有缺陷文本的单词语料库;而WE和DE子方法都需要训练单词和文档的神经网络,所以训练时间较长.从总体结果来看,对于Request项目缺陷的训练时间开销仅为4min左右,而对于Moment项目缺陷的训练时间开销只需要大约5min.
小结:训练时间开销结果表明,本文方法可以被很快地离线训练,且只需完成一次模型训练,即可用于相关缺陷的关联推荐.较少的训练时间开销也说明本文方法具有很强的应用扩展性,我们可以进一步基于本文方法研发相关工具和插件.
5 案例分析
为了进一步分析本文方法,我们对实际的缺陷链接对进行了案例分析.案例1(如图14所示)给出了request/request#880和 request/request#1005这一缺陷链接对.我们发现,这两个缺陷之间存在许多相同单词,例如“optional”、“dependencies”和“cookie”.推荐结果表明,NextBug、TF-IDF 和 DE 方法都无法捕获这两个缺陷之间的关联关系,而WE和本文方法都正确判断了它们之间的关联关系.所以当两个相关缺陷存在许多相同单词时,词嵌入模型可以很好地通过分析单词之间的上下文语义信息来帮助本文方法捕获缺陷之间的关联关系.

Fig.14 Case study of request/request#880 and request/request#1005图14 request/request#880和request/request#1005的案例分析
案例2(如图15所示)给出了缺陷链接对request/request#699和request/request#803,我们发现,这两个缺陷并没有很多共同的单词,只有“Error”、“getaddrinfo”和“ENOTFOUND”这几个单词相同.

Fig.15 Case study of request/request#699 and request/request#803图15 request/request#699和request/request#803的案例分析
推荐结果显示,NextBug、TF-IDF和WE方法都无法捕获它们的链接关系,而DE和本文方法都正确判断了它们之间的关联关系.这表明,当两个相关缺陷没有太多文本信息或没有多个共同单词时,文档嵌入模型可以很好地通过分析缺陷文档之间的上下文语义信息来帮助本文方法捕获缺陷之间的关联关系.
因此,通过案例分析,我们发现融合词嵌入模型和文档嵌入模型后,本文方法可以更好地捕获两个相关缺陷之间的关联关系.
6 结束语
本文提出了一种基于嵌入模型的混合式相关缺陷关联方法,用于在GitHub项目中自动链接相关缺陷.本文方法结合了传统的信息检索技术(TF-IDF)和深度学习技术(词嵌入模型和文档嵌入模型).在我们的实证验证中,我们将本文方法与NextBug方法(传统缺陷跟踪系统中的最先进方法)以及其他3种基准方法(即我们的3种子方法)进行比较.实验结果表明,本文提出的方法可以很好地融合缺陷语料库的上下文信息,在性能上要优于基准方法.此外,我们发现本文方法在项目特定的训练语料库下有助于提高嵌入模型的性能,即使对于不同项目的缺陷语料库,本文方法的推荐结果仍能表现一定的可靠性.并且,较短的时间开销表明本文方法可以有效地进行离线训练,具有很强的应用扩展性.
猜你喜欢
客联(2022年3期)2022-05-31
外语学刊(2021年1期)2021-11-04
中国新闻周刊(2021年26期)2021-07-27
天津外国语大学学报(2020年1期)2020-03-25
电脑爱好者(2017年7期)2017-05-06
经济(2016年29期)2016-12-27
CHIP新电脑(2016年3期)2016-03-10
外语教学理论与实践(2014年4期)2014-06-13
