
可微分抽象机混合编程系统∗
2019-06-11 07:39武延军
软件学报 2019年5期
周 鹏,武延军,赵 琛
1(中国科学院 软件研究所,北京 100190)
2(中国科学院大学,北京 100049)
自计算机诞生以来,实现帮助计算机自动编写程序的系统一直是人工智能研究者所追求的重要目标之一,相关研究最早可追溯到1971年[1].机器编程的研究总体分为类自然语言代码挖掘和代码生成两大类,代码生成的研究又可划分为程序空间搜索和连续可微分优化法.近年来,随着深度学习的兴起,结合神经网络以连续可微分优化理论为基础构建编程模型的研究也成为一个研究热点[2-4].总体而言,从输入素材角度,可将这些神经网络类编程模型分为基于程序执行轨迹样例的方法[2]和基于程序输入输出数据样例的方法[3,4].
当前,基于执行轨迹的研究方法需要收集逐步的执行轨迹有监督数据,数据成本高,并且该模型学习的本质是通过对不同执行路径的监督数据学习形成算法的神经网络编码,而覆盖不同路径的收集本身意味着要求算法是明确的,因此严格意义上,该模型并没有学习到新的代码,基于输入输出数据样例的方法直接提供输入输出数据训练集,让神经网络尝试从数据中学习从输入转换为输出的规律,该方法面临的问题是从输入到输出的转换规则可能存在多种,即存在有歧义性,并且该方法会面临编程语言过多的规则、实现细节带来的学习复杂度,同时未能输入源程序的背景知识(比如程序员预先学习的编程语言、计算机原理教程),导致模型处理信息不完备,也不能为训练学习过程提供珍贵的编程经验.额外的复杂度加上不完备的信息给模型训练学习带来了巨大挑战,导致习得算法通常非常简单,比如很难处理分支、递归等复杂控制结构,并且泛化能力明显不足.因此,当前单纯地以代码或输入输出数据为输入构建的神经网络编程模型都存在局限性.我们认为,在程序生成或程序语义处理问题上应该跳出编程者视角,尽可能提升习模型建模的抽象层次,在更具抽象层面用公理语义的方式将程序描述为抽象机的状态转换,从而避免从操作语义角度去描述程序的执行语义而陷入编程语言的复杂规范、底层实现细节等操作层面,提升程序处理的抽象层次是本文整个研究的基本动机.同时,我们认为,程序生成的研究不能单纯地只从代码或数据中学习,进一步的研究需要整合软件工程中长期积累的宝贵编程经验为学习过程提供指导,而本文的研究也说明:提升模型的抽象层次,是支持输入并整合编程经验的一个有效途径.
本文研究了一种可将高级编程语言与神经网络组件无缝结合的混合式编程模型(简称 dAMP).该模型的优点是:可以同时使用过程化的高级编程语言元素和神经网络组件元素混合开发应用程序,从而可以弥合两种元素的隔阂,发挥并整合高级过程化编程和神经网络可训练学习编程各自的优势,并为基于神经网络的程序自动生成模型提供经验知识的输入途径.dAMP研究的基本出发点是从抽象层次研究程序生成问题,其整体思路是:首先,从纯机器演算角度构造一个通用的抽象机(AM),用公理语义的方式将程序执行描述为抽象机的状态转换,AM 有独立的对外界无依赖的状态存储和指令集,支持传统的高级编程语言过程化编程;然后,以某种方式将AM 实现为连续可微分抽象机 dAM.该实现方式与典型的神经网络实现是同质的,因此可以无缝对接神经网络组件.借助 dAM,高级过程化程序可以在 dAM上以连续可微分的方式直接执行.dAMP混合编程是研究如何编写程序框架提供经验信息、如何在程序中嵌入神经网络组件为 dAM 编写程序框架以及如何使用训练数据学习生成完整的程序.抽象机的可选取原型目标很多,这里选取 Forth[5,6]编程语言执行模型作为构造抽象机的目标.本文会对 dAM 的实现方式做必要够用的介绍,但重点是给出 dAMP混合编程的关键实现技术,并对 dAMP程序自动生成的学习机制做详细深入的实验分析.
本文的主要贡献:1) 提出了在抽象层研究程序自动生成问题的一种思路,并给出该思路的一个完整验证系统dAMP;2) dAMP给出了一种支持经验输入、编程语言与神经网络组件元素相结合的混合编程模型,并给出其设计实现的关键技术;3) 给出了丰富的实验验证,对dAMP程序自动生成的学习机制做了深入的实验分析.
本文第1节对dAMP框架做一个整体介绍.第2节介绍编程语言模型,包括理解本文需要预备的编程语言概念、语言运行模型知识.第3节介绍连续可微分抽象机实现方法.第4节详细展开实现dAMP的关键技术.第5节实验验证并对模型的学习机制做深入的实验分析.第6节介绍相关性工作.第7节是结束语.
1 整体架构
可微分抽象机混合编程系统总体可分为源程序、编译与处理、连续可微分抽象机和计算图这4个主要组成部分,如图1所示.
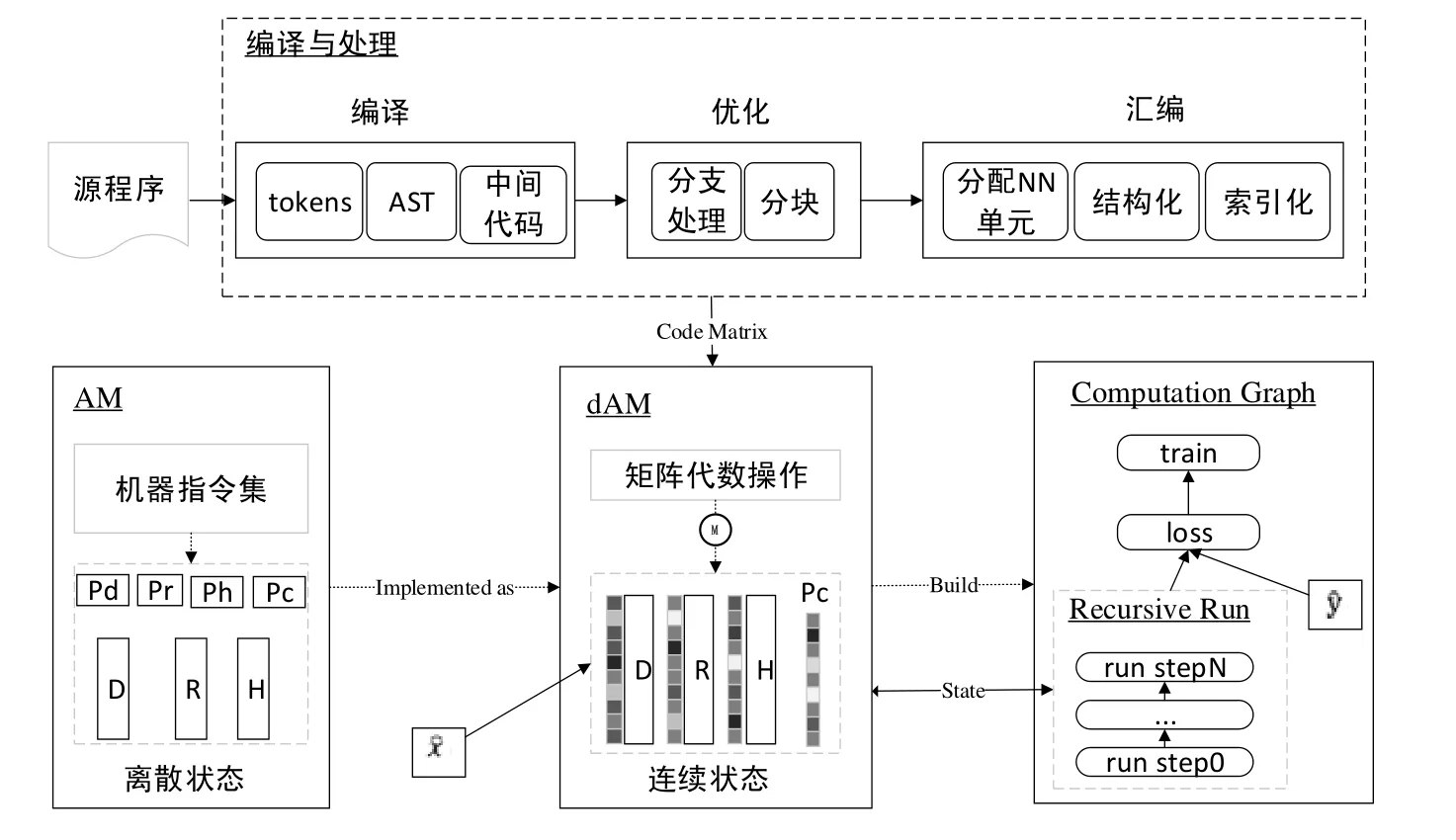
Fig.1 dAMP architecture图1 dAMP整体架构
总体而言,图1的上半部分是对源程序处理,下半部分是程序的运行时环境和训练学习环境.源程序首先经过编译形成中间代码;然后对中间代码做优化处理和汇编处理,生成结构化的适合连续可微分执行的代码矩阵表示;接着,连续可微分抽象机加载训练样本的输入部分ˆx到状态缓存的数据栈并执行代码矩阵,而执行的结果便是构建生成程序执行的计算图表示,其中,计算图的程序执行部分总体是N步递归结构;最后,以 dAM的状态为输入执行计算图,并以训练样本的标记部分ˆy为输入计算loss、以梯度下降可微分优化的方式进行训练学习.图中实箭头连线是数据流,虚箭头连线是控制依赖.下面对这4个主要组成部分分别做介绍.
(1) 源程序
使用Forth高级编程语言和神经网络组件元素(简称nc)混合编写的程序,与常规编程需要编写程序的完整细节不同,dAMP编程程序员可以基于编程经验只描述程序的框架,而把一些细节用待学习的神经网络组件(nc)占位,通过框架和nc结构提供经验信息.
(2) 编译与处理
把源程序转换为更适合dAM高效处理的形式,包括编译、优化和汇编这3个阶段.编译将源程序翻译为中间代码,包括词法分析、语法树生成以及生成中间代码,在中间代码生成期间,会额外做一些宏替换、控制语句处理等操作,比如将循环、条件分支、函数调用等都统一转换为标签跳转、统一分配标签等;优化主要包括对分支的处理和代码划块,分支的处理主要按照控制语句标签定义出现顺序进行序列化编码,实现标签的表格化管理,代码划块主要是将程序代码划分为若干粗粒度的顺序代码块,便于后面将程序的状态转移由行粒度压缩到块粒度,从而显著提升执行效率和模型训练效果;汇编主要工作是将优化后的中间转换为可以在dAM上执行的代码矩阵,包括为神经网络占位符分配神经网络单元、代码的表格结构化管理、控制语句地址标签的表格结构化管理以及在结构化基础上对代码和地址的索引化引用,并将索引化引用以代码原地(inplace)修改或替换方式反馈到代码中,结构化和索引化为在dAM上做连续可微分转化和神经网络学习模型构建做准备.
(3) 连续可微分抽象机
连续可微分抽象机dAM以代码矩阵和训练样本的输入部分ˆx为输入,将程序以逐步的连续状态转换方式解释执行,其执行结果是生成对应的程序计算图表示.dAM 是使用矩阵代数对 Forth语言执行抽象机模型的连续可微分表示,主要包括状态操作和指令集的连续可微分实现.因为和神经网络一样都使用矩阵代数实现形式,因此在dAM上,高级编程语言元素与神经网络单元元素能够无缝结合.
(4) 计算图
计算图是程序生成模型的最终表示,在dAM执行代码矩阵期间构建生成,主要包括程序递归执行、学习目标loss损失函数、训练函数train这3个部分,其中,程序递归执行逻辑表达为递归访问抽象机状态空间的RNN网络,训练期间训练样本的标记部分ˆy为输入.
2 编程语言模型介绍
本节介绍文中用到的预备知识编程语言模型,主要包括Forth语言元素、语言运行模型.其中,语言元素只介绍与文中样例代码相关的内容,如果想详细了解语言细节,请参考文献[7].
2.1 语言执行模型
Forth是一种栈式语言,随着时间推进,其执行虚拟机模型有多个变体,本文采用一个比较经典而简洁的双栈模型,如图2所示,执行虚拟机模型[6]包括一个求值数据栈DataStack、一个子程序(函数)返回栈Return Stack、一个算术逻辑运算单元ALU和一个随机内存存储Main Memory(其中包括以栈的方式管理帧,在本文不是必须的,忽略),另外包括5个内存访问寄存器:PC程序计数器、PSP参数栈指针(数据栈栈顶指针)、RSP返回栈指针、FP帧指针、FEP帧尾指针(FP和FEP可忽略).注意,虽然Return Stack返回栈从名字上看是保存子程序调用返回地址,实际上它还被用于临时数据交换.
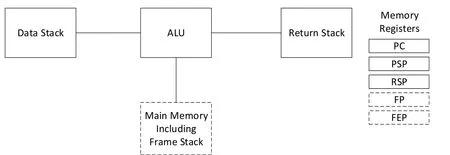
Fig.2 Forth VM图2 Forth虚拟机模型
Forth表达式采用逆波兰式(RPN)表示,因此,这种双栈模型非常适合Forth程序的高效执行.图3以一个简单的例子2+4=6,说明Forth语言执行模型.
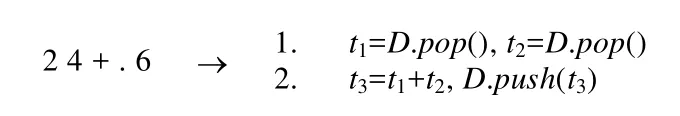
Fig.3 Example of expression evaluation图3 表达式求值示例
2.2 部分语言元素
Forth将指令或函数称为 word,它是一种可扩展语言,支持函数定义(subroutine)和函数调用,新定义的函数又称新word,可以像内置word一样被使用,因此,定义新函数的同时也扩展了Forth语言.表1是相关word功能说明,详细可参考文献[7].
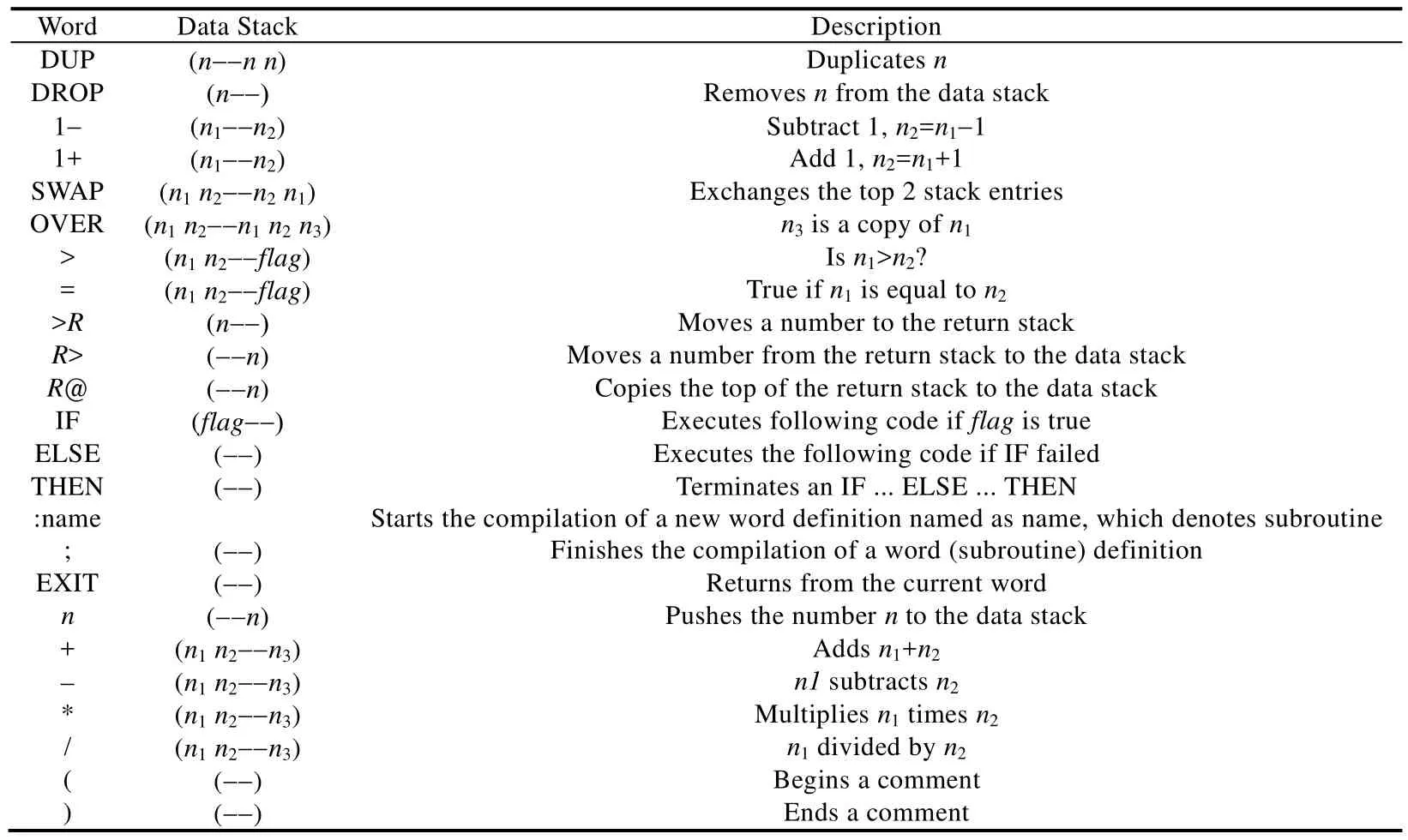
Table 1 Part of Forth words表1 部分Forth指令
3 可微分抽象机实现方法
由第2.1节Forth语言执行模型可知,其程序执行,既可看成指令执行序列,又可从公理语义的角度忽略指令的实现细节,只评估指令执行后对 Forth状态单元的改变.这种完全以状态的迁移来描述程序执行的方式,我们称之为抽象机模型AM.Forth程序在AM上的指令执行可以表示为状态的迁移:

其中,D数据栈、R返回栈、Pc程序指针、Pd数据栈栈顶指针、Pr返回栈栈顶指针,它们构成了 Forth抽象机AM 的状态单元,左边是指令执行前状态,右边是指令执行后的状态.直接的,将 Forth抽象机的离散状态空间映射到可微分抽象机dAM的连续状态空间.dAM的状态用sd=(Dd,Rd,Pcd,Pdd,Prd)表示,dAM执行过程即状态空间S中状态到状态的映射ƒdam:S→S,抽象机的word指令w∈ƒdam可被看作改变dAM状态的函数.
实现连续可微分抽象机的方法原理.
1)状体操作连续可微分实现:首先对Forth抽象机的状态访问的基本操作以矩阵代数的方式实现为连续可微分的,包括读(READ)和写(WRITE)操作,类似于 attention机制,通过把栈指针看成内存单元权重的方式实现READ和WRITE操作,比如数据栈READ操作实现为数据栈指针Pd与数据栈D的矩阵乘法,其原理类似于NTM[3]内存访问实现;然后,基于READ和WRITE线性组合实现PUSH、POP等内存高级操作.
2)Word操作的连续可微分实现:借助矩阵代数运算来表示 word操作,从而实现为连续可微分的,比如word指令的基本功能可分为访问抽象机状态单元或算术逻辑运算,其中,状态访问的实现原理与步骤1)类似,而算术逻辑运算则可借助one-hot矩阵对数据进行编码,然后通过矩阵算术运算计算结果.
4 可微分抽象机混合编程实现关键技术
本节详细说明实现dAMP的关键技术,是本文的重点章节.
4.1 源程序到中间代码编译
· 词法分析
这里给出本文词法分析正规式定义,即生成token的规则,源程序经过词法分析,转换为token序列,如正规式公式(2)所示.

· 语法分析(AST生成)
语法分析以源程序的 token序列为输入生成抽象语法树(AST),Forth通过栈和利用后缀表达式(RPN)的特点进行解析,解析简单同时极其灵活,不需要复杂的语法制导解析过程,因此,当前Forth语言没有类似于C语言的静态BNF产生式来限定语法[8].本文是经过裁剪定制的Forth验证语言,为了描述清晰规范,这里给出实现本文验证用Forth语法分析的BNF主要产生式项,如产生式公式(3)所示.

其中,〈nc〉条目用于产生内嵌神经网络组件,以实现对用神经网络组件与Forth元素混合编写的源程序进行语法分析.为了简单清晰,这里省略了一些简单的term元素和与ifthenelse类似的结构(如while)的产生式.
· 中间代码生成
算法1描述从AST生成中间代码,命名2同to,中间代码指令集的部分指令与Forth指令同名且功能相同,但也有一些专门指令(控制指令为主).
算法1.ast2im(ast,labelAllocator). //ast2im取其读音代表astToim
输入:ast-抽象语法树;labelAllocator-分配管理不重名的跳转标签.
输出:imCode-中间代码.


算法1借助注释描述了相关中间代码指令含义,易混淆语义的指令由表2给出专门解释.
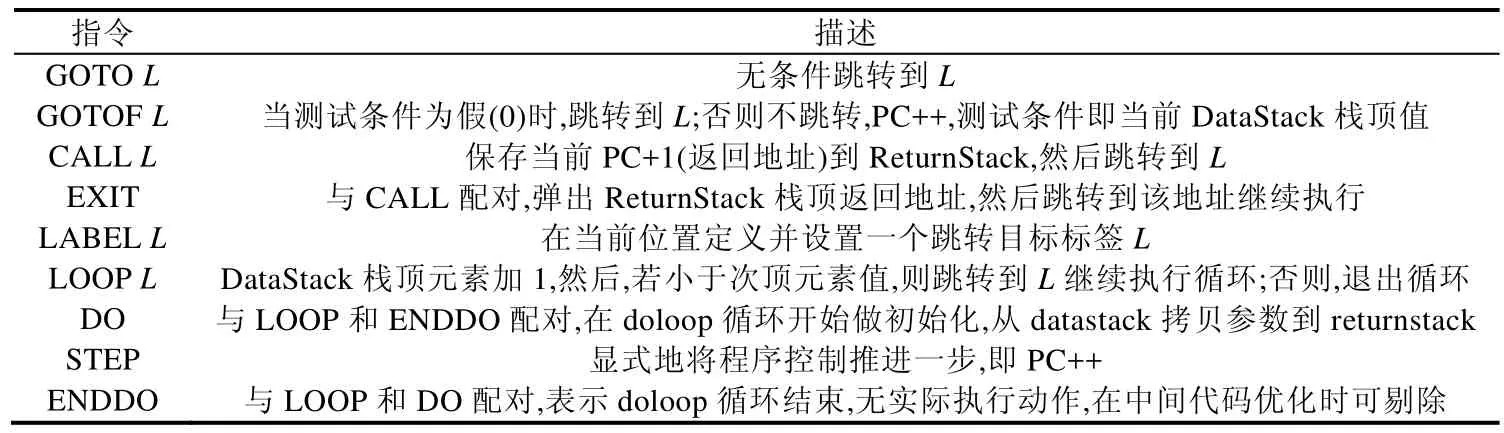
Table 2 Part of intermediate commands表2 部分中间代码指令
源程序以中间代码的形式在可微分抽象机上执行.算法1中,函数调用通过call指令实现,该指令在控制转移前执行保存现场操作,call保存现场只保存返回地址,不处理函数局部变量或函数参数传递.出于简化,本文没实现Frame Stack,典型的Forth实现也没有Frame Stack,但这不影响实现函数的嵌套及递归调用,函数体以exit指令结束,消耗返回地址、恢复控制现场.函数定义的代码生成在生成函数体代码前,先插入一个跳转标签,指向函数结尾,从而保证正确的执行转移.标签地址是符号地址,随后的中间代码优化处理阶段替换为实际地址,参照函数调用的实现技巧可以很容易理解条件分支、循环等控制指令实现方式.
神经网络组件元素nc包括(encoder,transforms,decoder)这3个部分,其功能分别是状态编码、状态转换、状态解码产生状态操作动作,这三者构成一个完整的带有可学习参数的神经网络组件,并可编程客制.
中间代码指令功能单一、支持机械化微码求值实现,算法1的中间代码生成过程将函数定义、函数调用、ifthenelse等复杂结构转换为基本中间指令序列,因此,将源程序转换为中间代码后非常适合转换为逐步的连续可微分执行,即适合在dAM上运行,而混合编程语言语法特点是适合高效创作复杂源程序.
4.2 中间代码优化
为了提高中间代码在dAM上执行效率和dAM执行输出计算图的训练学习效率,需要对中间代码进行优化处理.本节介绍中间代码优化处理的算法.中间代码优化比较复杂也非常关键,需经多遍处理才能完成,每一遍的优化目标不同,因此根据不同目标,我们首先分步骤把算法拆分成若干子算法分别做详细说明,然后整合起来形成中间代码优化总算法.
算法2对中间代码做两次遍历:第1遍按照先后顺序给标签定义,分配从0开始的连续整数编号,生成标签编码表labTable;第2遍根据labTable对所有指令类型为标签跳转或标签定义的指令,用编号重命名其标签属性.
算法2.labRenumber(imCode).
输入:imCode-跳转标签重编号前中间代码.
输出:labRenumberedIMCode-标签重编号后中间代码;labTable-标签重编码表.

算法3与算法2类似,但因为常量不分定义和使用,只需对中间代码做1次遍历:按照遍历时首次访问顺序给常量分配从0开始的连续整数编号,并生成常量编码表conTable(字典类型,键是常量的value属性,值是分配的整数编号),对所有指令类型为常量(constant)的指令,用编号重命名其常量值属性,遇到重复的常量,复用conTable已分配编号.算法3主体代码与labReplace类似,故不详细展开其伪代码.
算法3.conRenumber(imCode).
输入:imCode-常量重编号前中间代码.
输出:conRenumberedIMCode-常量重编号后中间代码;conTable-常量重编码表.
算法4.blockPartion(imCode).
输入:imCode分块前中间代码.
输出:imBlocks分块后中间代码.

把中间代码划分为块,通常,一个块主要由不做控制转移的普通word组成一个元组,块结尾才可能有控制转移word,块的类型包括block块、label块、nc块,分块处理后的中间代码,其每个块可看作一个大word.
算法5将目标标签转换为目标地址,建立标签到地址的映射表,并删除标签定义指令.
算法5.lab2addr(imBlocks).
输入:imBlocks-分块后的中间代码.
输出:addrIM-目的标签转换为目的地址后的中间代码块;tabLab2addr-标签地址对照表.

算法6遍历代码块,为没有以控制转移指令结尾的代码块追加插入step指令,从而确保每个代码块执行结束时都更新PC,即保证程序持续向前推进执行.
算法6.insertStepctl(addrIM).
输入:addrIM-清除目标标签并建立标签到地址映射后的中间代码.
输出:blockStepIM-补全step控制指令后的中间代码块.

算法7是中间代码优化的整个流程,经过5次遍历,生成最终在dAM上执行的优化代码.代码优化是一个复杂但关键的过程,代码优化不仅能显著提高训练学习效率,也为实现结合神经网络的深度学习模型提供了基础.
算法7.optimiseIM(imCode).
输入:imCode-优化前中间代码.
输出:optimisedIM-优化后中间代码;tabLab2addr;conTable;labTable.

代码优化对实现程序连续可微分执行、建模和训练有重要意义.第3节介绍了程序在dAM上的执行被描述为在某个连续状态空间中的连续状态转换,这显然适合以RNN为基础建模.RNN有一个问题是,如果步骤过多,会显著降低训练效果和效率.因此,把以指令字为单位转换为以块为单位的单步执行能显著减少迁移步数,相当于通过压缩状态转换序列长度显著提升训练效果和效率.中间代码将地址空间转换为线性平铺的连续编号、常量和标签跳转编码为连续的整数编号,这些优化处理为基于神经网络的预测训练建模提供了便利.
图4是中间代码优化结果示意图,优化后的代码以不同大小的基本块组织,并以块为单位编址构成线性平铺代码地址空间,每个块都以显式的控制转移指令结尾,如果没有,则在尾部插入step;程序以块为单位逐步(块)执行,如果碰到标签跳转指令,则按照标签目标执行跳转,标签按照第1遍优化时分配的连续整数编码命名,并按照第4遍优化时生成的标签地址对照表tabLab2addr查找在代码空间的实际地址.
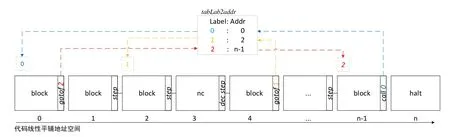
Fig.4 Intermediate code optimization图4 中间代码优化
4.3 程序汇编
本节主要介绍对优化后的中间代码块做进一步汇编处理,汇编处理就是为每个代码块转换为一个可直接操作可微分状态机状态的函数,这个函数就是中间代码块对应的汇编代码,因此,块经过汇编处理后可以在运行阶段直接操作dAM运行并生成计算图.
每个block块或nc汇编代码包括两个部分用于执行时的两个阶段.
· 第1阶段是在符号状态机上以符号执行的方式对中间代码代码块做化简,形成用符号变量、符号栈表示的块代码执行结果.因为符号执行时基于符号变量做计算,因此不依赖栈和变量的具体值,只需为每个块提供一个初始态的符号状态机做操作参数,不需要考虑块序列状态依赖、状态传递等问题.符号执行取得的符号化简结果与状态无关,一次执行永远有效,所以只在中间代码块首次被访问时执行一次并可复用;
· 第 2阶段在连续可微分抽象机上求值:首先需要创建分配一个可微分抽象机,该抽象机除了提供基本操作、指令集等连续可微分实现,还需要分配、初始化和管理各状态组件,包括数据栈、返回栈、栈指针、Pc指针、代码词汇表、代码矩阵、标签地址映射表、常量编码表等,其中,词汇表和代码矩阵是中间代码优化并经过汇编处理后的代码字,代码矩阵是代码编号one-hot表示;可微分抽象机创建并初始化后,便构成状态机的初始状态,中间代码在这个初始状态基础上逐步执行,逐步执行并不意味着一直顺序执行,比如碰到分支跳转指令会改变控制流.
神经网络组件(nc)的汇编处理相对要复杂一些,nc块包括nc.type和nc.value两个部分,vaule包括dec,enc,transforms和label这4个部分,前3个需要专门处理.生成dec的汇编处理结果,需要把dec按照项目循环展开处理,算法8是生成dec的汇编代码指令字算法流程概要结构,算法9是为相应enc编码部分生成汇编代码的算法概要结构.
算法8.dec2decAsse(dec).
输入:dec-神经网络组件(nc)的值的dec解码部分,即中间代码块条目列表.
输出:decAsse-汇编处理后的指令字结构.

算法9.enc2encAsse(enc,transforms,outputDim).
输入:enc-网络组件(nc)值的enc状态编码部分;transforms-状态转换函数列表;outputDim-编码输出维度.
输出:encAsse-汇编处理后的指令字结构.

4.4 程序可微分执行模型
第1步创建连续可微分抽象机dAM,并初始化,包括汇编后的词汇表vocab、代码矩阵、常量编码表、标签地址映射表、PC指针初始指向代码地址0、新建返回栈并初始化为干净状态、数据栈和数据栈指针则由占位符变量初始化,用来接收训练样例输入.dAM对象包含了指令集实现函数和抽象机当前完整状态,初始dAM即初始状态(用Sdam_init表示).程序在dAM上一次执行轨迹就是由从初始状态出发的状态列表exeTrace=[Sdam_init,Sdam_1,Sdam_2,...,Sdam_n],初始值[Sdam_init],每个状态Sdam_i都是在前一个状态上执行某个代码块汇编函数结果.显然,不同的初始状态可能会产生不同的执行轨迹,包括导致PC序列可能存在差异.
程序的可微分执行模型:创建Sdam_init,然后在Sdam_init上继续执行n步,n是针对程序特点和输入规模计算的执行步数,所以程序的执行模型是一个RNN模型,该RNN模型在时间序列上展开后由n步组成,而每一步执行包括两个动作.
· 第1个动作是根据Pc向量从代码矩阵中做指令寻址,其连续可微分矩阵计算可描述为公式(4).
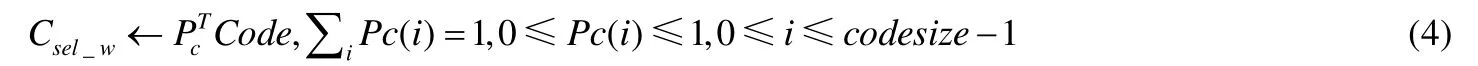
其中,Code是汇编代码块编号的one-hot代码矩阵;Pc是one-hot表示程序指针向量,训练期间,其分量是代码分布权重;codesize是代码包含的代码块个数,或者汇编后词汇表指令字个数;Csel_w是指令寻址权重分布,在锐化处理或者训练稳定后,Csel_w精确选取单个汇编指令.
· 第2个动作是基于Csel_w选择指令执行,该动作有两种实现方式:
➢ 方法1是执行所有代码块,然后按照Csel_w计算attention权重和,可描述为公式(5).
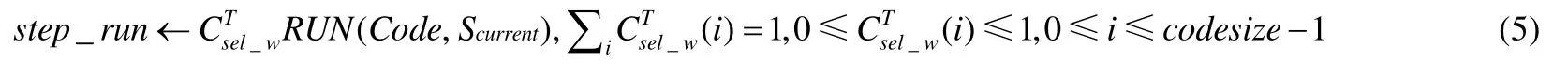
其中,Scurrent是当前状态;RUN(Code,Scurrent)表示在Scurrent状态下分别执行代码Code的每个汇编后指令,一共codesize次,每个执行结果得到一个新状态,所有新状态构成结果状态向量,然后以Csel_w取结果向量权重和就是本次单步执行的结果;
➢ 方法2是对Csel_w做锐化处理,基于锐化结果选定一条指令执行并改变可微分抽象机状态,可描述为公式(6).
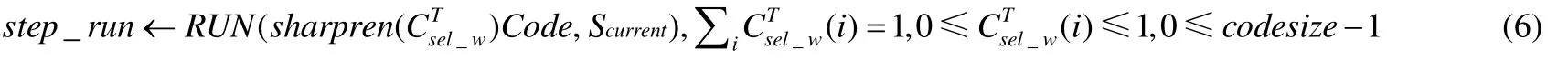
其中,sharpen函数对Csel_w做锐化处理,得到一个one-hot向量,该one-hot向量与Code矩阵乘法取出唯一的指令编号;然后,该指令在当前状态Scurrent下执行的结果就是本次单步执行的结果.
理论上,两种方法都是可行的,但锐化处理因为不需要每次执行所有指令字,所以效率更高.
从初始状态Sdam_init开始,每执行一步产生下一个状态,这些状态最终形成一个完整的状态迁移轨迹.从公式(4)~公式(6)可知,执行过程中,根据Scurrent.Pc以连续可微分方式做指令寻址,根据指令寻址选择汇编指令函数做连续可微分执行,并基于Scurrent和执行结果更新生成下一个状态Snext,其中包括Snext.Pc,Snext.DataStack,Snext.Pd等属性,因此,逐步执行生成n步执行轨迹的过程,就是生成程序的连续可微分计算图表示的过程.
4.5 训练目标函数
模型使用程序执行轨迹的结束状态进行训练,中间状态在训练模型时不需考虑,因此不需要像 NPI[2]那样对执行轨迹的每一步做标注,因而显著降低了训练数据的生成和标注成本.表示训练样本是初始状态,标注目标是结束状态;表示对应于初始状态,在参数为θ的dAM模型上执行n步后得到的状态.模型的训练目标是对于所有的训练样本i,求解使得y与差距最小的参数θ*:

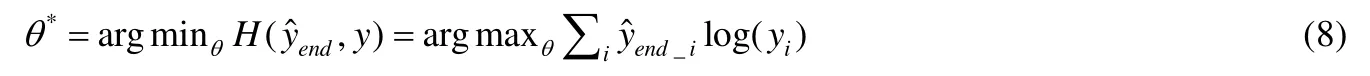
每个状态最多包括DataStack(D),Pd,ReturnStack(R),Pr,Heap(H)这5个状态分量,所以公式(8)可分解为5个分量的和:
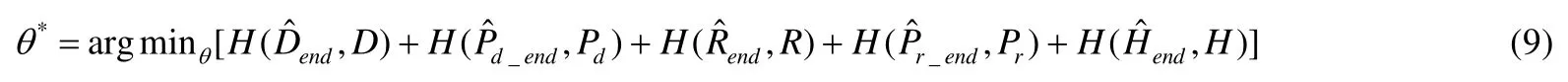
其中,H是交叉熵函数.一般的,在具体算法场景,其损失函数不需要所有5个分量,本文的实验只用到Pd和D两个分量,给定算法场景用不到的分量的交叉熵为 0,因此可在公式中去掉相应交叉熵分量的计算.因为系统是连续可微分的,所以可以使用反向传播算法训练优化损失函数.
5 实验分析
本节对dAMP系统做实验分析,首先给出同一个多位数加法算法的3种代码实现实例,结合具体例子对比分析了 dAMP的代码生成特性、实例选取的原因动机;然后以该算法的程序为例,对模型的训练效果、训练过程中运行时状态对技术设计目标正确性的反馈验证和模型复杂度进行实验分析;最后对系统的性能进行评估.
5.1 多位数初等加法算法
多位数初等加法运算是由低位往高位移动做单位数加法,每步单位数加法基本操是基于低位进位、本位被加数和本位加数计算向高位的进位和本位和,多位数加法是递归执行单位数加法.该样例的好处是问题简单,但包含了顺序语句、分支控制、函数调用、递归等复杂程序结构元素(显然这些结构足以表达其他广泛、复杂的编程问题),因此方便进行简单明了的多方面系统分析,又不失对dAMP全可微分模型编程能力验证,分支、函数调用、递归等控制结构处理能力也是程序生成研究关键之一[2-4].
图5给出了该多位数初等加法的类C语言伪代码、Forth代码以及与Forth实现相对应的dAMP神经网络组件混合代码的实现.图中黑体加粗代码是计算进位和计算本位和的代码的3种对照实现,其中,Forth代码实现是确定性的,需20个word实现,每个word是Forth的一行代码(把20个word放在5行以节省空间);而dAMP实现则是不确定的,不需编写完整算法,其中最复杂的每步计算进位和本位和操作用待训练学习的神经网络组件代替,通过编写框架主要提供2个编程经验输入(这是一个递归算法结构,每步计算进位和本位和的取值范围分别是0~1和0~9).

Fig.5 Elementary multidigit addition图5 多位数初等加法
5.2 模型训练效果分析
· 模型可收敛性实验验证
可通过反向传播算法训练优化是模型的关键,第3节、第4节介绍dAMP实现时,从理论上说明了dAMP是连续可微分的.图6所示实验数据对此进行了验证,该实验以一位加数、一位被加数和进位的输入输出数据为训练样例,以2位~4位(加数加被加数长度共8位)整数加法构建测试样例.由图6(a)可知在Loss稳定收敛,训练约400步时,Loss收敛到非常接近0;由图6(b)可知,在模型训练超过400步时,2位~4位数加法的测试准确率达100%.因此,模型具有很好的收敛性.另外,我们测试了用1位数加法训练得到的模型做2位~34位整数加法,得到了100%的准确率,所以模型具有很好的泛化能力.
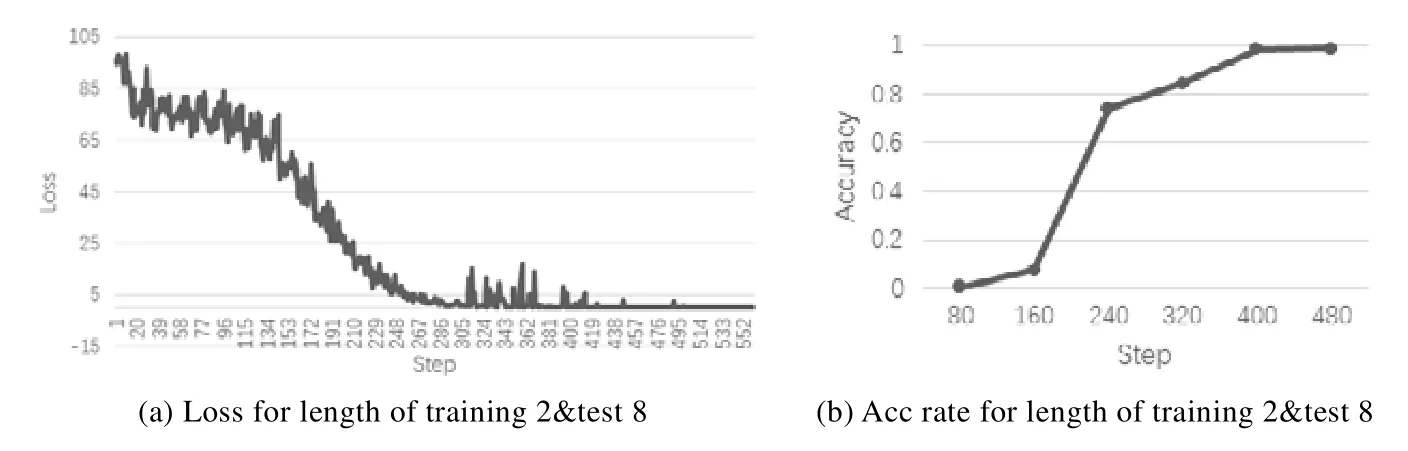
Fig.6 Convergence of model training图6 模型训练收敛情况
· 轨迹步数设置对训练的影响
第4.4节介绍了dAMP程序执行模型是由n步状态迁移构成的exeTrace,因此设置合适的n对模型训练很关键.n的设置需参照中间代码优化后代码块个数和程序的输入规模,比如,如图7(a)所示,当训练加法算法输入规模为2时,n=14左右效果最佳;当n≥16时,明显增加训练步数;当n≤12时,准确率波动很大.同时,图7(b)显示,其Loss收敛很好.这种情况很可能是因n偏小造成过拟所致.
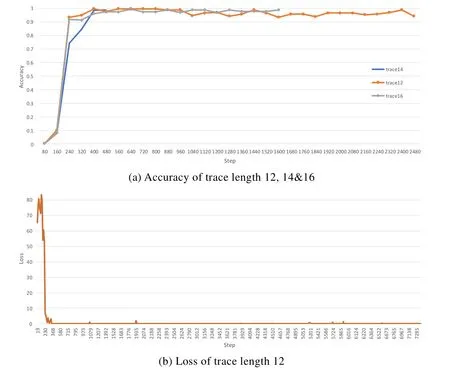
Fig.7 Effect of number of trace step on training图7 轨迹步数对训练的影响
5.3 运行时执行过程验证
验证方法是记录加法程序在dAMP上训练运行时PC的值,分析在一个执行轨迹周期中其值的变化是否符合预期.图8(a)是PC的实际执行轨迹,该轨迹取自2位数加法训练过程;图8(b)给出了多位数加法程序经过中间代码优化和汇编后的代码块以及以块为基本执行单位的程序控制转移逻辑作为参照.从图中可以看出,运行时PC移动轨迹完全符合预期,其中,虚框部分证明模型正确执行了函数调用与递归,右上角最后两步停留在 Halt指令不再转移,说明程序执行正常结束.该实验现象也说明,exeTrace设置为20步即可满足要求.
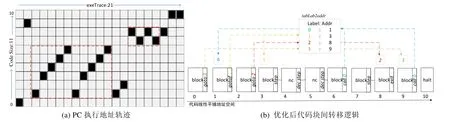
Fig.8 Runtime PC-trace correctness verification图8 运行时PC轨迹正确性验证
5.4 模型复杂度分析
第4.4节给出了程序在dAMP上执行模型是n步exeTrace,因此程序在dAM上执行复杂度主要由n决定.以多位数加法为例,设加数(或被加数)位数为m,则n=2+5m+2+2m+2=7m+6=O(m),即问题输入规模的线性复杂度,该计算过程可参照图8运行时轨迹.类似地,对于冒泡排序,其模型复杂度是O(n2),所以dAMP运行时轨迹复杂度取决于算法框架本身.第 4.2节的中间代码优化将程序按照控制结构分块,将程序从逐指令粒度优化到块粒度执行,从而有效提升执行性能,但因为没有改变程序结构,因此不会达到改变复杂度.另外,将梯度计算放在程序执行结尾而不是执行过程中的每个状态迁移,也是性能优化的一个方面.显然,dAMP混合模型能够利用nc组件消除条件分支等控制结构,但进一步,对于给定问题如冒泡排序,是否能设计影响程序循环或递归结构从而达到优化算法复杂度,还有待未来做专门探讨.
5.5 性能评估
dAMP开发环境为Python3.5.2,NumPy[10]1.14.5,TensorFlow[11]1.10.0 CPU版,Ubuntu 16.04 X86_64,8核心Intel Xeon E5-2407处理器,64G内存,测试环境同开发环境.性能评估选用有代表性的算术操作和关系操作,实验方法为随机生成50组形状为(1,10)的操作数,统计每个操作执行50次运算的总时间,单位为s.Performance数值越小,表示性能越好.为了对dAMP性能有一个横向的评估,实验同时选取了TensorFlow(TF)功能相近的操作,使用相同的数据做测试对照.图9(a)是算术操作性能测评结果,对照 TF.add、TF.subtract、TF.multiply、TF.div,图9(b)是关系操作测评结果,对照 TF.equal、TF.greater、TF.less、TF.greater_equal、TF.less_equal、TF.not_equal.测试数据表明,dAMP表现出很好的性能.这里,性能测试未做任何专门优化,如果使用 GPU加速,则理论上性能还会有明显提升.
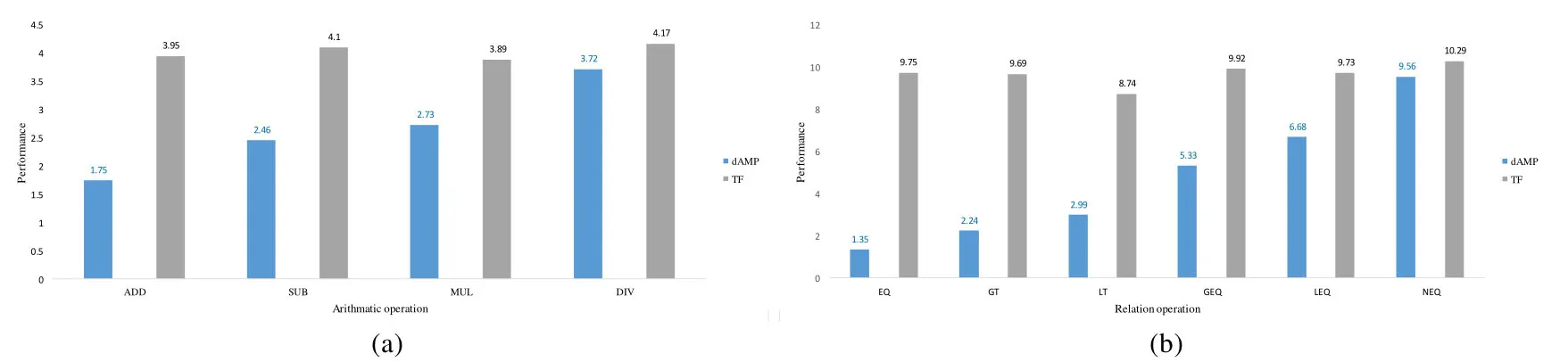
Fig.9 Performance of fundmental operations图9 基础操作性能
6 相关工作
机器编程相关研究始于20世纪70年代[1],经过近50年的发展取得了长足进步,但是其通用能力、泛化能力、程序覆盖能力仍明显不足,因此限制了实际应用.主要相关性研究.
· 类自然语言研究方法
该方法将自然语言处理的研究方法迁移到编程语言领域[12-14].相关工作集中在代码注释、论坛等自然语言语料到代码关键字、标识符等的对照关系处理上,对代码自身信息的直接处理上表现不足.
· 归纳式程序合成方法
该方法将程序生成定义为搜索问题.所有程序样例的全集构成一个离散程序空间,程序生成的过程就是通过观察输入输出样例数据特征,在程序空间归纳搜索与样例数据行为一致的程序,受程序合成研究方法习惯于用规则和抽象提高问题处理效果启发[15-17],本文提出在更具抽象层设计连续可微分抽象机的混合编程的程序处理思路.但是不同于归纳式程序合成把程序生成定义为在离散空间搜索,本文则是基于连续可微分优化的更通用的一种方法.
· 基于连接的神经网络方法
该方法为程序处理寻找一个连续空间表示,将问题看成是在连续空间待学习参数和一套可微分规则组成的系统,程序生成问题被转换为在连续空间采用可微分优化方法来逼近一个解,这是本文最相关的研究方法.典型的 NPI[2]使用神经网络从程序执行轨迹中学习预测下一步调用的子指令,非完全可微分,依赖于收集高成本程序执行轨迹,本质上是算法编码而不是生成.NTM[3]通过注意力机制将外部存储与神经网络内部存储耦合,扩展了神经网络的记忆容量,实现了全微分方式访问外部缓存,为实现 dAMP的连续可微分栈访问操作提供了借鉴.但NTM无指令集,因此无法实现可微分编程控制.Forth[9]提出了一种forth编程语言可微分解释器的初步实现方法但不完整,有很好的借鉴意义.与之相比,本文提出并验证了一种在更具抽象层解决程序生成问题的混合编程研究思路,给出了更完整、成熟、严谨的实现框架,对PC寻址锐化显著提升效率,提出验证了多种训练目标函数以适应不同问题,提出并分析了如何合理设置执行轨迹步数、对关键学习机理进行了理论和实验分析.Deepcoder[4]提出了一种基于神经网络在给定的 DSL语言下计算指令频度的方法,本质上是结合神经网络的归纳式程序合成方法.
7 结束语
本文提出在抽象层研究程序自动生成问题的一种思路,给出其验证系统 dAMP,实现了一种可无缝结合高级过程化编程语言与神经网络组件的混合编程模型,给出了包含顺序块、条件分支、函数调用、递归等常规复杂程序结构元素和神经网络组件结构的程序样例实验分析.显然,这些结构具备表达其他更广泛复杂程序的能力,完整严谨的技术设计和实验分析表明,通过抽象层次提升,这种基于可微分抽象、支持表达复杂问题程序结构的混合编程模型在理论和技术上是可行的.与已有的程序生成方法相比,本文所提方法具有更灵活的可微分编程控制能力、良好的程序自动生成与泛化能力、优秀的性能.
原型验证在理论和技术上可行只是研究工作的一个方面,最终希望走向广泛的应用,而应用不仅关心技术可行性,比如首先可能还关心用户接口,因此我们认为,下一步有必要对以下几个工作进行探讨.
1)通过扩展C语言子集,设计支持神经网络混合编程的类C语法作前端,基于本文的技术作为后端支持,从而更便于程序员编程思想表达,发挥其编程创造性.
2)在前一个工作基础上,设计丰富的神经网络混合编程语言原语,以C语言、Java等语言为例,丰富的编程原语对编程模型走向实际应用有重要意义,dAMP全可微分特性支持嵌入包括神经网络在内任何可微组件,因此理论上可把典型的神经网络模型(如 seq2seq,encoder-decoder,CNN,GAN 等)甚至非神经网络但可微分模型设计为该编程模型原语级支持,以增强其编程表达能力.
3)全面探讨或反向总结该可微分混合编程模型的应用场景适应性或编程潜力,参照Java等大多数编程模型发展经验,这不是一个完全可正向评估的纯技术问题,往往依赖于Java用户生态的编程创造性的反向反馈,即具有开放性和创造性.
在正向上,因为支持丰富复杂的程序结构以及可微分混合编程特性,因此从技术上显然有能力表达广泛复杂的程序,并因新语言结构的融合而引入新编程表达能力.如传统C程序是确定性的,因此主要用于编写完整的程序,求解完全明确的问题之类场景,而该模型特性则支持以传统过程化编程方式在确定性框架下引入非确定性编程支持,而非确定性局部又可借助数据驱动自学习生成,因此适合但不限于“不完全明确但有数据可依赖的问题编程”或者出于降低编程难度或提高编程效率的“非完整编程”.但在编程便利性应用上,还有赖于下一步诸如类C语法前端和原语丰富性设计等工作,从而更好地激发程序员利用模型特性的编程创造性发挥.
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
数码世界(2020年12期)2021-01-20
学校教育研究(2020年11期)2020-06-08
科技与创新(2019年2期)2019-02-14
北京航空航天大学学报(2017年10期)2017-04-20
新高考·高二数学(2016年7期)2017-01-23
股市动态分析(2016年17期)2016-10-20
太空探索(2016年6期)2016-07-10
考试周刊(2016年44期)2016-06-21
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
