
C/C++程序缺陷自动修复与确认方法∗
2019-06-11 07:39周风顺王林章李宣东
软件学报 2019年5期
周风顺,王林章,李宣东
(计算机软件新技术国家重点实验室(南京大学),江苏 南京 210023)
随着信息技术的不断发展,计算机软件已经成为现代社会最重要的基础设施之一.但是由于程序员的疏忽和软件系统复杂度的增加,这些程序中不可避免地存在缺陷.尽早地发现并排除这些潜在的缺陷,是学术界和工业界普遍的共识.程序缺陷自动修复技术可以根据给定的错误程序自动生成程序修复候选项,进而修复程序中的缺陷.其修复过程中产生的补丁可以直接用于修改程序,也可以帮助开发人员改进代码.因此,程序缺陷自动修复成为我们关注的重点.
程序缺陷自动修复的一般流程包括缺陷定位、候选项生成、验证及选择.程序修复方法首先通过缺陷定位方法将给定的带有缺陷的程序的所有语句按某种规则排序,得到可疑语句的排列;然后将这些语句作为疑似缺陷逐个传输给修复候选项生成算法.修复候选项生成算法会检测当前缺陷的位置,决定是否能够输出候选项:如果能够,则输出候选项给测试集进行验证,通过验证的候选项将作为结果输出;若该疑似缺陷的位置无法输出修复候选项,则从语句排列中获取下一个可疑语句,重新运行修复候选项生成算法以继续寻找潜在的修复候选项.
修复真实缺陷,一直以来是程序缺陷自动修复研究的目标.目前,学术界对现有的修复技术在真实缺陷上的修复能力存在一定争议[12],关于缺陷修复的讨论也有很多.2015年,Qi等人[3]对GenProg和AE两个工作在105个真实缺陷上的修复进行了手工检查.其中,Genprog的修复结果中只有两个是语义正确的,而AE的修复结果中只有3个是语义正确的.由此可见,现有的修复技术存在着修复率低,无法保证修复结果的正确性等问题.
近年来,程序合成技术和机器学习、深度学习等AI技术不断进步,在软件工程中有着广泛的应用.这两项技术的发展在解决程序自动修复问题上引起了我们新的思考.程序合成[45]是指从程序语言自动地构造程序,使其满足特定的规约.程序合成器通常是在程序空间内进行搜索,以生成满足各种约束的程序.程序合成通常被使用在代码补全、软件开发、算法设计中[6].近年来,程序合成除了规约外,还允许用户额外地提供可能的程序空间框架,一般是语法层面的.这样的做法有两点好处:首先,语法为假设空间提供了结构,这可以使搜索的过程更加高效;其次,生成的程序也是可解释的,因为它们是从语法中衍生出来的.程序合成工具SKETCH[7]首先提出了这个想法,它允许程序员编写部分程序框架(带有空白的程序),然后根据规约自动填补这些空白.深度学习中,长短期记忆网络(LSTM)[8]是一种特定形式的循环神经网络(RNN).LSTM 的关键是细胞状态,细胞的状态在整个链上运行,只有一些小的线性操作作用于其上,信息很容易保持不变地流过整个链.同时,LSTM有一种精心设计的称为门的结构,可用来选择式地删除或添加信息到细胞.LSTM的这些特性使得LSTM广泛用于序列预测问题.
本文针对现有的修复技术存在的问题,结合程序合成技术和深度学习技术,提出了一种基于程序合成的代码缺陷自动修复方法.一方面,人工整理常见的缺陷形成缺陷模式并总结修复方式,帮助修复常见的缺陷;另一方面,通过深度学习的方法,从满足相同规约的正确程序集中学习正确程序的书写结构,帮助预测错误程序错误点的应有的语句结构.在选择验证的过程中,我们使用程序合成的方法将样例程序作为约束,保证合成后代码的正确性.本文的主要工作在于:
(1) 本文提出了一种基于程序合成的 C/C++程序缺陷自动修复方法,总结了 C/C++程序中常见的错误模式,并建立了书写结构模型.使用缺陷定位方法——基于重写规则的定位方式和基于程序频谱的方式,得到程序中可能的缺陷位置.使用修复选项生成方法——基于重写规则的修复选项生成方法和基于预测的修复选项生成方法,得到缺陷的修复选项.
(2) 本文提出了基于程序合成工具 SKETCH[7]的修复选项选择与确认方法.将带有修复选项的 C/C++程序转化为SKETCH代码,并进行预处理,将该程序的示例程序作为程序的规约并加入SKETCH代码.使用SKETCH执行程序合成,直到找到满足规约的修复,得到正确的修复结果.
(3) 基于上述方法,本文实现了一个C/C++程序缺陷修复的原型工具.
本文第1节主要介绍基于程序合成的代码缺陷修复方法的基本框架.第2节展示实验结果.第3节主要介绍相关工作,包括基于搜索的缺陷修复和基于约束求解的缺陷修复.第4节进行总结和展望.
1 基于程序合成的C/C++程序缺陷自动修复方法
本节我们提出基于程序合成的C/C++程序缺陷自动修复方法的基本框架(如图1所示).
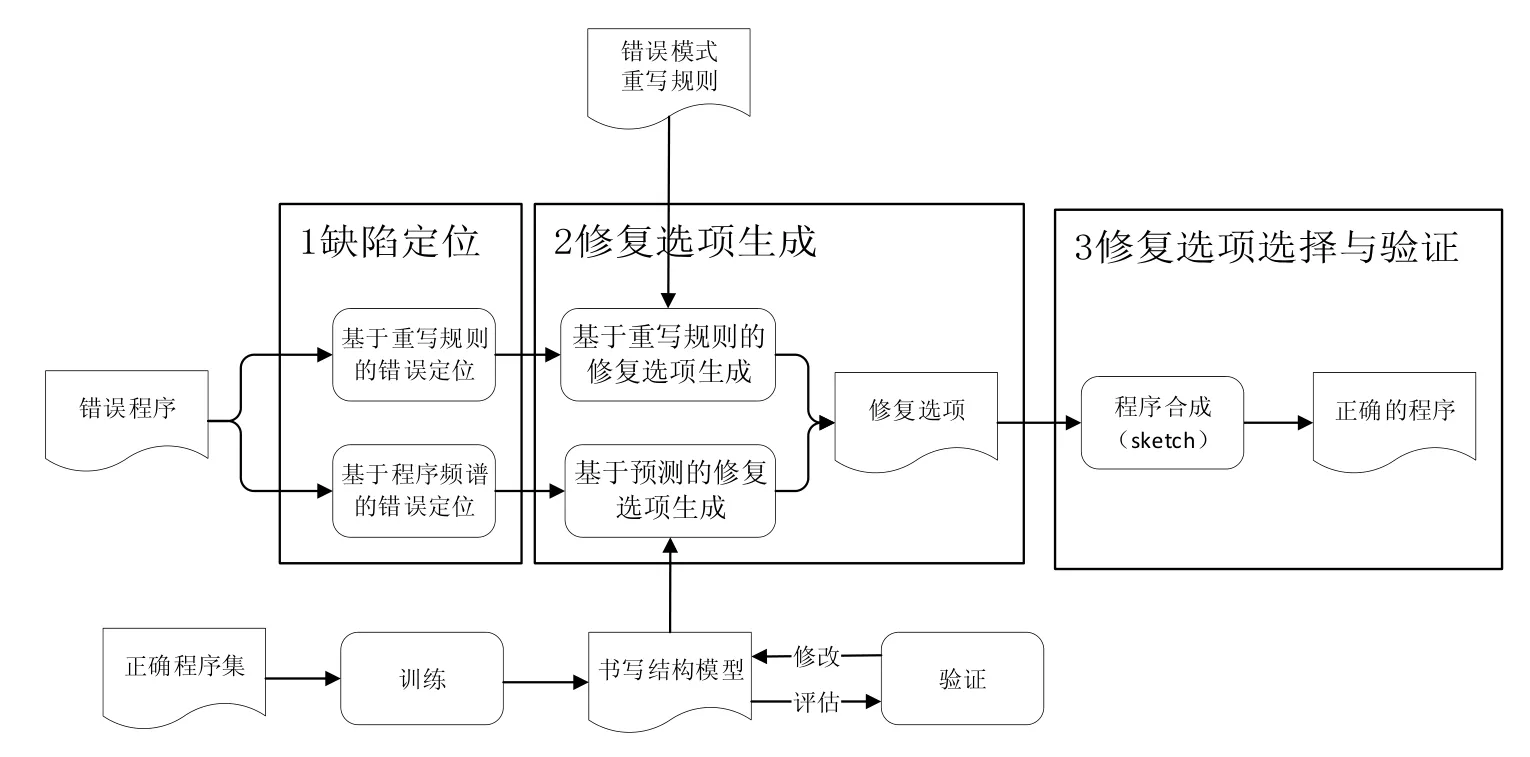
Fig.1 Framework of the method图1 方法框架
程序自动修复的流程包括缺陷定位、候选项生成、候选项验证.本方法使用缺陷定位方法——基于重写规则的定位方法和基于程序频谱的定位方法,得到程序中可能的缺陷位置;使用修复选项生成方法——基于重写规则的修复选项生成方法和基于预测的修复选项生成方法,得到缺陷的修复选项.同时,在修复选项验证步骤中使用程序合成的方法,保证合成后程序的正确性.该方法分为 3个主要步骤:缺陷定位、修复选项生成、修复选项验证和一个准备步骤——重写规则总结和书写结构模型构建.
(1) 重写规则总结和书写结构模型构建.
对于重写规则,我们对错误程序进行整理,总结其中常见的错误模式,并人工给出修复方法,将错误模式和修复方法配对形成重写规则.对于书写结构模型,我们收集满足相同规约的正确程序,提取其中的书写结构并序列化.将所得的序列化数据使用长短期记忆模型进行训练.使用梯度下降算法,当定义的损失函数在验证集上的变动小于设定的阈值时停止训练.将此时的模型用于书写结构预测.
(2) 缺陷定位.
我们使用基于重写规则和基于程序频谱两种方式进行缺陷定位.在基于重写规则的定位中,我们将错误模式与错误程序的抽象语法树进行匹配,得到可能的缺陷节点.在基于程序频谱的定位中,我们在错误程序上执行测试用例,根据语句覆盖信息,计算程序中语句缺陷疑似度,按疑似度从高到低进行排序,将疑似度高的语句作为缺陷位置.
(3) 修复选项生成.
对于使用重写规则确定的缺陷位置,我们直接使用重写规则中的修复方法生成修复选项.对于使用程序频谱确定的缺陷位置,我们将缺陷处前面的序列化数据作为书写结构模型的输入,预测缺陷处的书写结构,使用当前位置可见的变量进行扩展,得到多个修复候选项.
(4) 修复选项验证.
首先,将错误程序、缺陷定位信息以及修复选项结合,得到扩展的带有选择表达式的 C/C++程序,并转化为相应的SKETCH程序;然后,将程序需要满足的规约作为约束,求解每一处选择表达式的选项,确认修复候选项.
1.1 重写规则总结和书写结构模型构建
1.1.1 重写规则
每一条重写规则由两部分组成:一部分表示缺陷模式,另一部分表示修复选项.我们对学生作业程序中常见的错误进行整理,总结了一些常见的错误模式及修复选项,具体见表1.
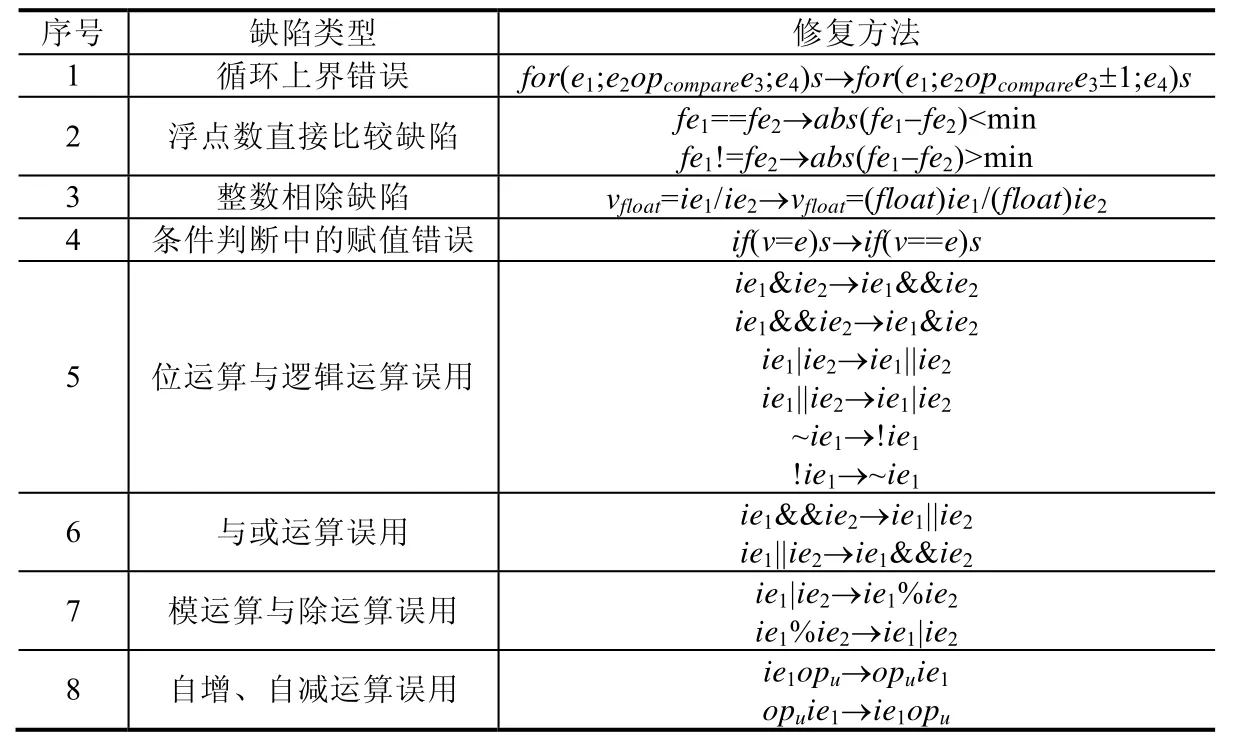
Table 1 Rewrite rules表1 重写规则
本节给出了目前已整理的 C/C++代码中常见的重写规则,这些重写规则比较通用,其中主要的缺陷是运算符误用和代码逻辑的错误.在一些特定的程序中,可能会出现某些特殊的缺陷,如果该缺陷存在特殊的模式,同时也有比较固定的修复方法,那么我们也可以针对这些缺陷设计特定的重写规则,以实现对这些缺陷的修复.
1.1.2 序列化
代码数据不同于普通的文本数据,它具有复杂的结构,若直接将代码视为序列化数据,便会失去其中的结构信息,长短期记忆网络也难以从这种缺乏关键信息的数据中学习书写结构.而抽象语法树既可以用来表示程序语义,同时也可以表示程序结构,因此,我们采用抽象语法树对程序进行解析.并且我们在深度优先遍历抽象语法树的基础上,用“{”和“}”将每个中间节点包围起来,以此来加强序列化数据中的结构信息.
如图2是一段简单的代码,其语法树形式如图3所示,其序列化数据如图4所示.
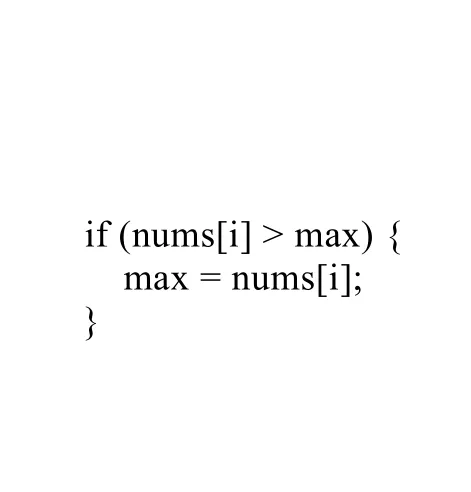
Fig.2 Code fragment图2 代码片段
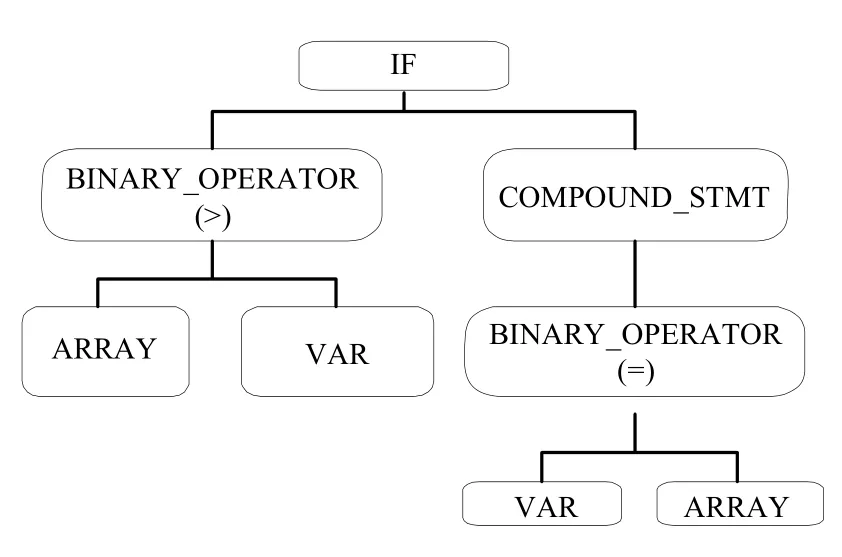
Fig.3 Structure of syntax tree图3 抽象语法树结构
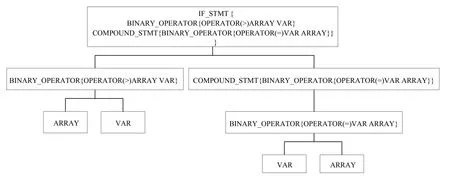
Fig.4 Serialized data图4 序列化数据
1.1.3 书写结构模型设计
LSTM广泛应用于序列预测,我们也使用LSTM来预测缺陷处的书写结构.我们使用最基本的LSTM模型,该模型的输入为k个token.通过one-hot编码将token转化为特征向量,并输入到隐藏层的LSTM cell.隐藏层的输入还包括上一时刻细胞状态ct-1以及隐藏层状态ht-1.该层的输出为当前时刻细胞状态ct以及隐藏层状态ht.将隐藏层的输出h输入模型的softmax层,得到预测结果的概率分布,向量中第i个元素的值代表结果为词汇表中第i个token的概率.
细胞状态ct以及隐藏层状态ht计算公式如下:
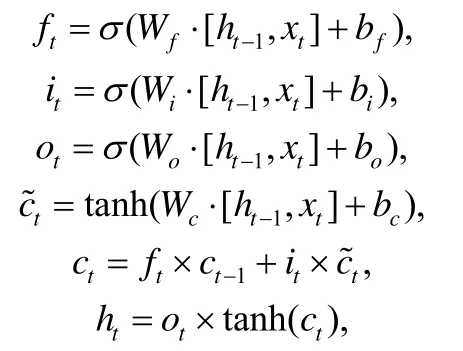
其中,xt为当前token的one-hot编码,ct-1为上一时刻细胞状态,ht-1为上一时刻隐藏层状态.
损失函数定义为softmax的输出向量和样本实际标签交叉熵的平均值[8].
模型训练时,采用梯度下降优化算法,当损失函数的变化率小于设定值时停止训练.
1.2 缺陷定位
缺陷定位是程序修复的重要一步.本文使用了两种缺陷定位方法:基于重写规则的缺陷定位方法与基于程序频谱的缺陷定位方法.
1.2.1 基于重写规则的缺陷定位
在第 1.1节中,我们设计了重写规则,并给出了若干条重写规则实例.重写规则包括了缺陷模式和修复选项,其中,缺陷模式描述了程序中可能的缺陷.我们可以将重写规则中的缺陷模式与源程序在语法树上进行模式匹配,得到程序中可能的缺陷位置.
算法1.基于重写规则的缺陷定位算法.
输入:重写规则Rule,源程序的抽象语法树T.
输出:可能的缺陷位置:抽象语法树上的节点集合S.

该算法的目的是将缺陷模式与抽象语法树进行匹配.
· 算法第6行~第12行的广度优先遍历是主体部分;
· 算法的第4行将源程序抽象语法树的根节点加入队列Q;
· 第7行从队列Q中取出一个节点,将该节点与缺陷模式DT的根节点进行匹配:若完全匹配,那么该节点为可能的缺陷节点,算法的第9行将这个节点加入集合S;若不匹配,算法的第11行、第12行将该节点的所有子节点加入队列Q;
· 之后,按照广度优先遍历的顺序依次与缺陷模式进行比较.
1.2.2 基于程序频谱的缺陷定位
使用重写规则,我们可以定位出程序中那些具有固定模式的缺陷.但对于程序中更加一般的缺陷,比如表达式计算错误,我们无法给出明确的重写规则.对于这样更加一般的缺陷,我们将采用基于程序频谱的定位方法.程序频谱从某些角度记录了程序的执行信息,例如条件分支的执行信息或无循环的内部程序路径,它可以用来跟踪程序的行为.当执行失败时,可以通过这些信息来识别导致缺陷的可疑代码.选用程序频谱的定位方式虽然并不一定精确,但可以快速确定哪些语句与缺陷相关,缩小对缺陷语句的搜索范围,后期对修复候选项的选择与验证也能弥补这种定位带来的不精确.
对于一个错误程序,我们首先获得一组测试用例,其中包含通过的测试用例和失败的测试用例.这两类测试用例对程序语句的覆盖情况不同,失败的测试用例覆盖的语句更有可能存在缺陷.利用这两类测试用例的覆盖情况,使用特定的公式,我们就能计算出不同语句存在缺陷的疑似度.按照疑似度对语句进行排序,并依次尝试进行修复.本文计算疑似度使用的是Tarantula[9,10]计算公式,具体如下:
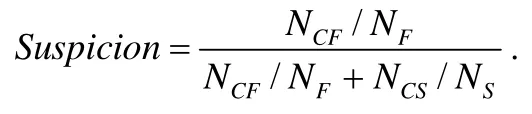
其中,NCF表示覆盖语句的失败的测试用例数量,NF表示所有失败的测试用例数量,NCS表示覆盖语句的通过的测试用例数量,NS表示所有通过的测试用例数量.
表2含有一个简单程序,其目的是求一组数据去除最大值、最小值后的平均值.其中,语句6存在缺陷,正确应为max=score[i].表右侧是5个测试用例(具体见表下部),其中有2个通过的测试用例,3个失败的测试用例.表中圆点表示该测试用例覆盖的语句.
根据语句覆盖情况,使用上述的公式,得到表3语句疑似度计算结果.从表3中可以看出,语句6存在缺陷的疑似度最高;同时,语句6也正是存在缺陷的语句.
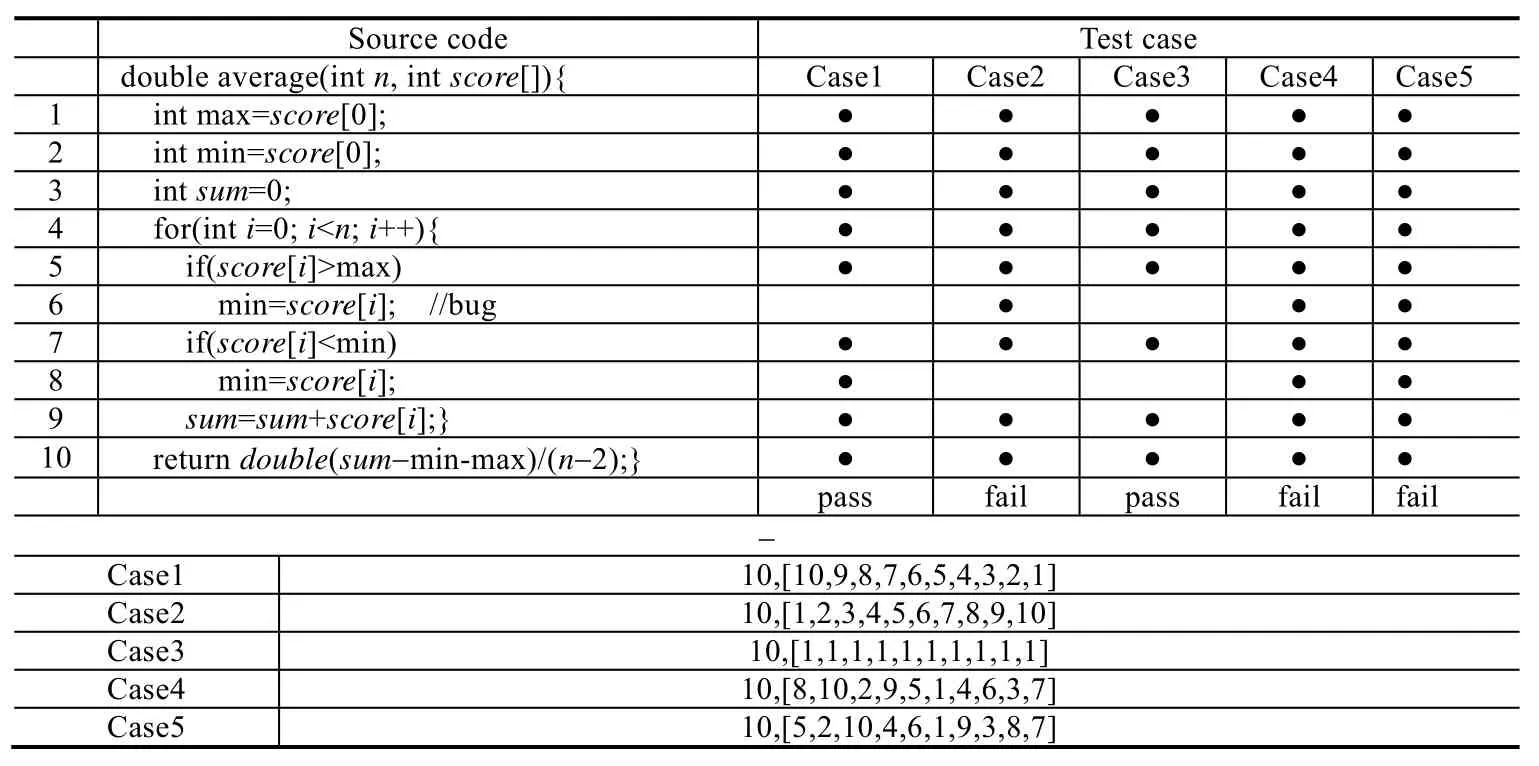
Table 2 Example of program spectrum表2 程序频谱示例

Table 3 Result of sentence suspicion表3 语句疑似度计算结果
1.2.3 两种定位方式对比
重写规则是我们在调研南京大学《程序设计》课程中连续2年11题课程作业、316个学生作业提交后,人工总结常见的错误类型(详见表1)及针对该类错误的修复方式形成的,基于重写规则的缺陷定位方式主要也是定位这些人工总结出来的具有固定模式的缺陷.但人工总结难免有所遗漏,基于程序频谱的缺陷定位针对的就是重写规则遗漏的部分,与基于重写规则的缺陷定位方式互为补充.
1.3 修复选项生成
在第1.2.1节中,我们介绍了基于重写规则的缺陷定位方法和基于程序频谱的缺陷定位方法.在得到可能的缺陷位置后,我们将分别使用两种修复选项生成方法——基于重写规则的修复选项生成和基于预测的修复选项生成,对缺陷位置生成修复选项.
1.3.1 基于重写规则的修复选项生成
在第 1.2.1中,我们通过重写规则得到了可能的缺陷节点.重写规则中包含了修复选项,我们可以利用重写规则,对由重写规则得到的缺陷节点,生成实际的修复选项.
算法2.基于重写规则的修复选项生成算法.
输入:重写规则Rule,抽象语法树上的缺陷节点node.
输出:针对缺陷节点node的修复选项集合S.


该算法在第1行匹配标识符(变量名)与语法树节点的对应关系,保存在字典NDict中.之后,在第6行~第12行按照广度优先的方式遍历每一个修复选项ct的所有节点,在第9行将其中的标识符节点替换.替换掉标识符节点的ct就是针对缺陷节点node的实际修复选项,最后在第13行将ct加入集合S中.
1.3.2 基于预测的修复选项生成
在第 1.2.2节中,我们介绍了基于程序频谱的缺陷定位,通过该方法定位到缺陷位置后,我们通过预测的方法来生成修复候选项.在深度学习中,长短期记忆网络能解决长期依赖问题,适合处理序列预测问题,因此我们选用长短期记忆网络作为写结构模型.针对每一处缺陷位置,我们按照之前序列化的方法,将缺陷位置前的正确代码序列化,并截取固定长度作为书写结构模型的输入.反复迭代产生预测,直到匹配到完整的一对“{”,“}”.将模型产生的预测结果作为该处缺陷可能的书写结构.
由于在序列化的时候我们对变量名进行了抽象,在实际生成候选项时,我们根据书写结构,使用当前可见的变量名替换结构中的对应部分,产生候选项集.
1.4 修复选项验证
传统的验证方法多使用测试的方法,通过所有的测试用例就认为修复正确,但这样并不能保证真正的正确.2015年,Qi等人[3]对GenProg和AE两个工作在105个真实缺陷上的修复进行了手工检查.其中,Genprog的修复结果中只有两个是语义正确的,而 AE的修复结果中只有 3个是语义正确的.我们采用程序合成的方法,并使用程序合成工具SKETCH来进行候选项验证,确保合成后程序的正确性.我们将错误程序、缺陷定位信息以及修复选项结合,得到扩展的带有选择表达式的C/C++程序,并转化为相应的SKETCH程序.然后,将正确的样例程序作为SKETCH程序合成器的约束,在规定时间内求解SKETCH程序.如果在设定的时间内能够求解得到每一处选择表达式的选项,就以此确定 C/C++程序中对应的选择表达式选项,得到正确的 C/C++程序.如果超出规定时间或无解,则认为没有正确的修复选项,修复失败.
2 工具与评估
本文实现了一个基于程序合成工具 SKETCH的 C/C++程序缺陷自动修复原型工具 AutoGrader,该工具可以修复 C/C++程序上的常见缺陷.为了验证工具在缺陷修复上的有效性,本文以学生作业程序为对象,设计了相关实验,并对比了GenProg和AE两个工具在缺陷修复上的效果.
2.1 工具框架
图5展示了我们工具的框架,其中,底层的是工具的输入,包括待修复的C/C++程序、重写规则和正确程序集;中间部分是工具主要实现的模块,包括解析模块、模型构建模块、缺陷定位模块、修复选项生成模块、SKETCH程序合成模块;最上层是工具的输出.
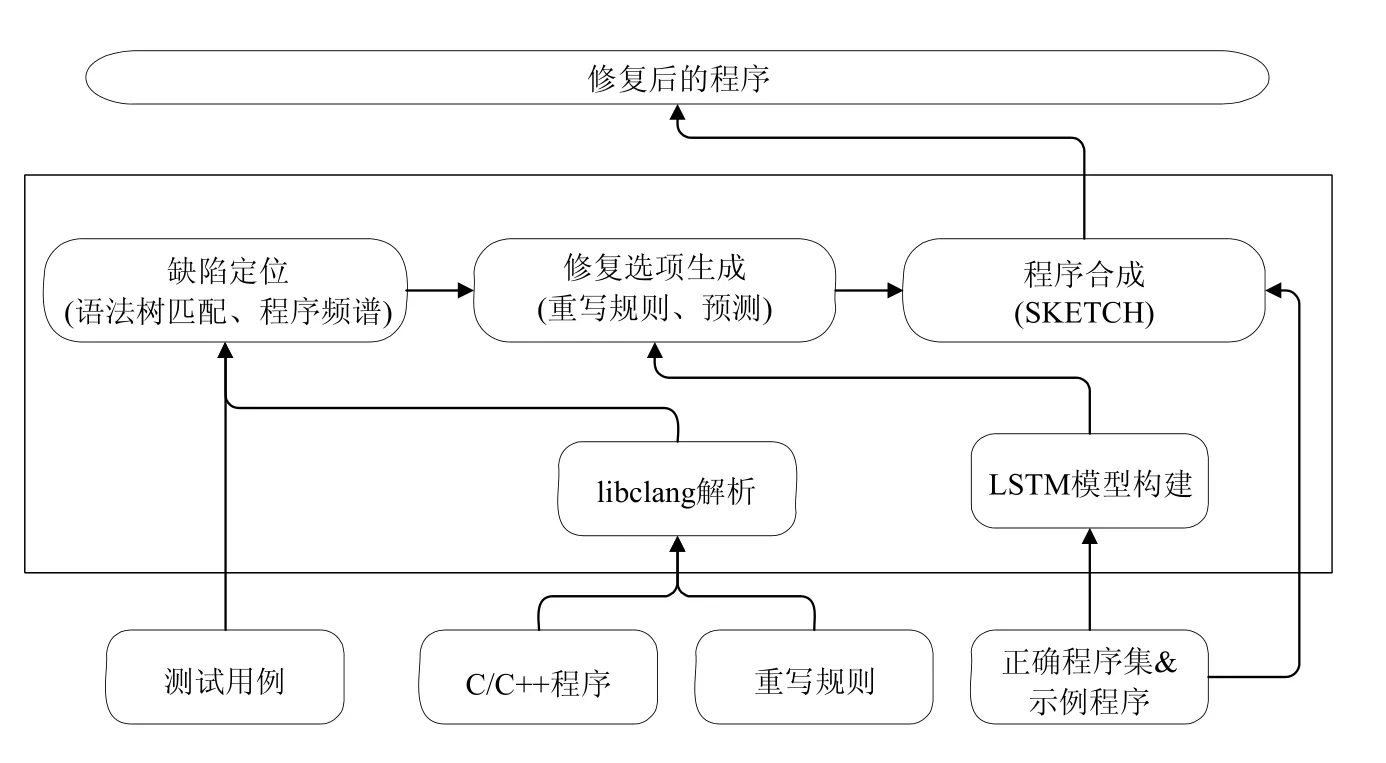
Fig.5 Framework of the tool图5 工具框架
2.2 实验对象
SKETCH合成工具仅能处理小规模的问题,一方面由于大规模程序过于复杂,SKETCH求解器的能力不足;另一方面,由于大规模程序往往包含过多的函数库,使用 SKETCH手工实现过于复杂.因此,我们的实验对象主要是学生作业程序.学生作业程序都是小规模程序,同时可能会包含一些相似的错误.
我们收集了2016年~2017年间,南京大学《程序设计》课程的作业,累积11个任务、316个学生提交.经过分析整理,我们选取了两个任务的学生作业.任务 1是求一个整型数组在除去最大值和最小值之后的平均值,任务 2是对一个正整数进行质因子分解.除去编译发生错误的情况,共有 19题错误作业,这些错误程序规模都在20行~30行左右,包含1~3个错误.错误类型分布见表4.

Table 4 Distribution of error types表4 错误类型分布
2.3 实验设计
基于本文实现的 C/C++程序缺陷自动修复工具 AutoGrader,选取了学生的作业程序进行实验.作业程序有着明确的实验要求,我们提前给出了示例程序,使用示例程序作为 SKETCH合成的规约.在实验中,我们主要讨论以下几个问题.
(1) AutoGrader在作业程序上的修复效果如何?
(2) AutoGrader对比其他工具有哪些优势?
(3) AutoGrader所采用的缺陷定位方法能否定位到实际的缺陷位置?
实验的运行环境如下:CPU Intel Core i7-4790GHz,内存16GB,系统Ubuntu16.04.
2.3.1 修复效果
表5展示了我们的实验结果.表中Question表示程序的问题,Program表示程序编号,LOC表示程序的代码行数,Defect表示程序的缺陷数量,其余列表示对应方法修复缺陷的时间(以s为单位),×表示未能完成修复.我们使用了GenProg和AE这两个工具进行了对比实验.
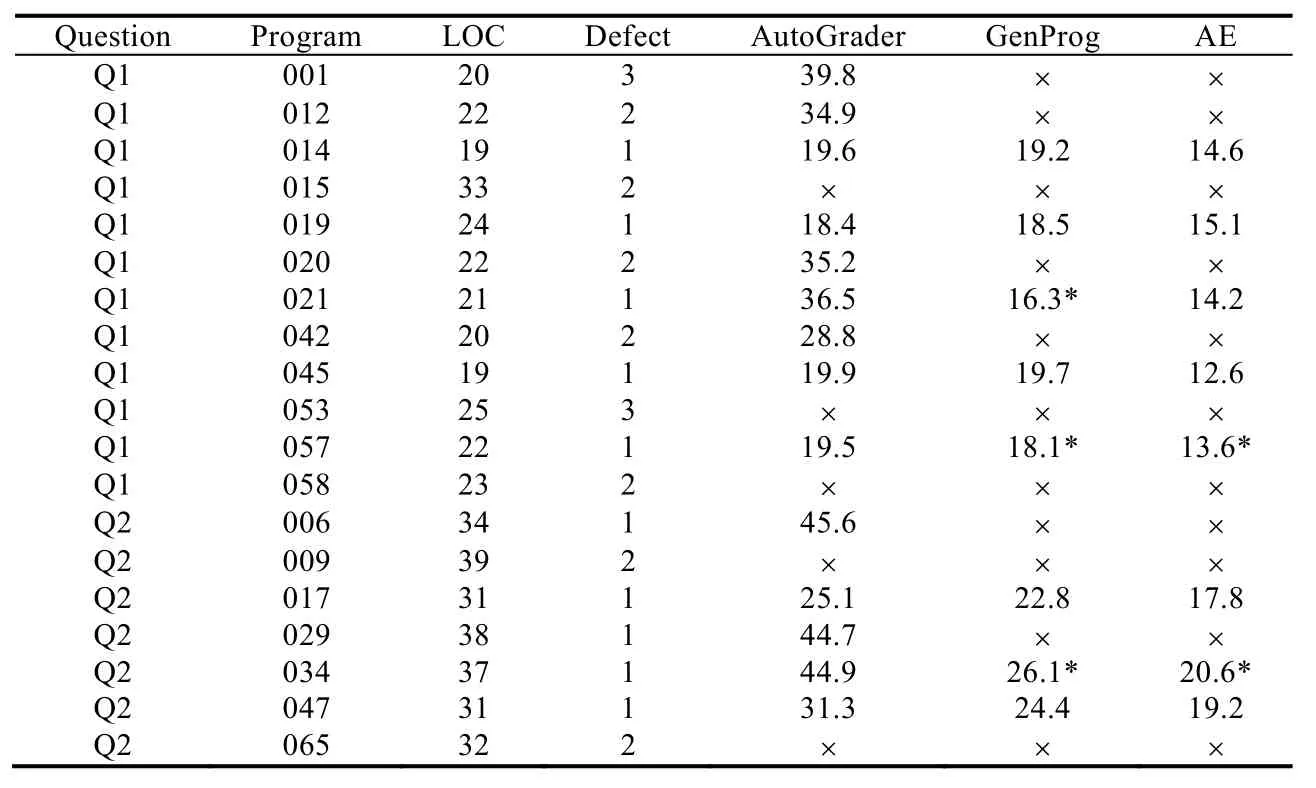
Table 5 Results of repair表5 修复结果
通过实验数据表明,我们的工具对作业程序的修复有如下优点.
(1) 对这19个错误程序,我们的工具可以对其中的14个进行修复,修复率为73.7%,修复时间都在60s以下;GenProg和AE仅能对其中的8个程序进行修复,尽管修复所需的时间更短,但我们的工具具有更高的修复率.
(2) GenProg和AE仅能修复只含有一个缺陷的程序,我们的工具可以修复多个缺陷.
(3) 由于我们在 SKETCH合成中引入了示例程序,这保证了我们的工具修复后的程序是正确的.而对于GenProg和AE,修复的程序仅能通过测试用例.表格中带*的数据表明:修复后的程序通过了测试用例,但不是一个正确的修复.
2.3.2 定位与修复分析
我们的工具使用了基于重写规则和基于程序频谱的缺陷定位技术,为了验证缺陷定位技术是否能够定位到程序中实际的缺陷,我们人工对比了程序中实际的缺陷与工具定位的可能的缺陷位置.
表6展示了程序中实际的缺陷位置与定位技术得到的缺陷位置.
Real Defect表示程序的实际缺陷行号,Defect Location表示定位得到的缺陷行号.从表中看到,程序中实际缺陷一共30个,定位技术得到的缺陷个数为59个.所有实现修复的程序中,定位技术都覆盖了实际的缺陷.对于未实现修复的程序,除Q1 053外,由于定位得到的缺陷未覆盖实际缺陷,因此无法实现修复.对于程序Q1 053,定位覆盖了实际缺陷,而由于错误比较特殊,未产生正确的修复选项,因此无法修复.
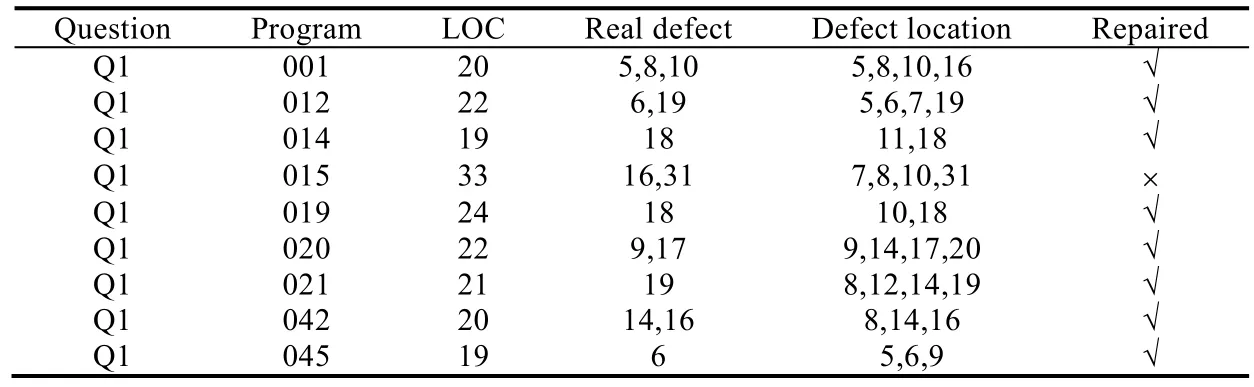
Table 6 Results of defect location表6 缺陷定位结果
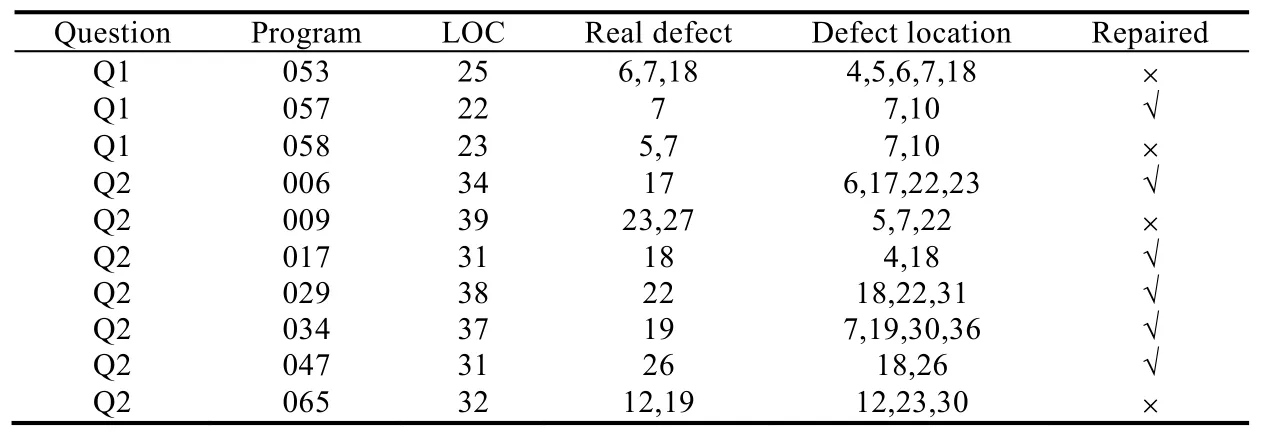
Table 6 Results of defect location (Continued)表6 缺陷定位结果(续)
3 相关工作
3.1 基于搜索的缺陷修复
在基于搜索的方法中,生成程序补丁的过程被看作是从搜索空间中寻找最优解的过程.对于待修复的程序来说,该方法将对程序的修改作为潜在补丁,获得补丁空间.在搜索过程方面,多使用启发式方法、演化算法等方法寻找补丁.
GenProg方法[11]由 Weimer等人于 2009年提出.GenProg将程序看作抽象语法树,将代码段看作子树.GenProg的核心算法是遗传算法,其中,变异操作包括复制别处语句替换当前语句、在当前语句后插入其他语句、删除当前位置的语句.遗传操作为选择两个适应度高的程序,交换其中的变异操作.如果修改后的程序通过的测试用例越多,程序的适应度就越高.2012年,Le Goues等人对Genprog方法进行了大型实验[12],选择了105个大型程序中的缺陷进行修复,成功修复了105个缺陷中的55个.GenProg是缺陷修复技术兴起的代表性工作.
2013年,Weimer等人对GenProg方法进行改进,提出了AE方法[13].他们认为GenProg方法生成的候选补丁数量太多,为了尽可能地减少生成的候选补丁数量,AE方法提出了等价类的概念.通过设置一系列规则,快速检查特定类型的等价变换,在修改时避免产生等价变换.验证结果表明,修复的时间开销为原来的三分之一.
2013年,Kim等人提出了PAR方法[14].该方法从开源项目Eclipse JDT中分析了6万个开发者人工修复的补丁,总结了常见的10种代码修复模板,并将模板与GenProg相融合生成补丁.PAR方法生成的补丁具有更好的可读性.
2014年,Qi等人认为 GenProg方法中的遗传算法存在计算开销大、难以识别有效补丁的问题,并提出了RSRepair方法[15],将遗传算法替换为随机搜索.实验表明:RSRepair和 GenProg有着相近的修复能力,并能有效减少生成补丁的时间.
2016年,Fan提出了Prophet方法[16].通过使用机器学习方法,对开源项目中正确代码的特征进行学习.在实际修复过程中,Prophet方法对可能的修复补丁,分析补丁特征和代码上下文,通过概率模型计算补丁可能修复程序的概率.最后,根据概率排序对补丁依次进行验证.
3.2 基于约束求解的缺陷修复
基于约束求解的缺陷修复将在搜索空间寻找补丁的过程转换为约束求解问题,通过约束求解器获得可行解并转换为修复补丁.由于约束求解的特性,这类修复方法往往能够获得精确的结果,但也会消耗更多的时间.
该类算法的先驱是2012年的SemFix方法[17],一种C语言的基于约束的修复算法.该算法使用基于组合的程序合成方法生成补丁.将测试用例转换为约束,使用SMT求解器求解,得到最终补丁.
2014年的Nopol方法[18]是一种专门修复if条件缺陷的方法,针对条件错误或者条件语句缺失这两种常见缺陷进行修复.在实际修复过程中,使用天使定位算法,获得可能的缺陷位置.与 SemFix方法不同,Nopol仅针对if条件表达式,搜索空间小,可应用于大规模程序.
2015年,Mechtaev等人提出了DirectFix方法[19],该方法为了提高SemFix方法生成的补丁质量,用语法树上被改动的元素个数定义差别,最终生成语法树上差别最小的补丁.
3.3 其他方法
2010年起,Pei等人提出一种基于契约的方法Autofix[20-22].Autofix是一种基于契约的修复方法,该方法需要程序契约中的规约信息作为输入,例如函数的前置和后置条件等.通过从程序中抽取执行序列来对程序行为特征进行抽象,并根据语法特点和程序执行信息来定位疑似缺陷语句.随后选择不同的修复模式,运用值替换、表达式替换等方式生成补丁代码.该方法可用于Effiel语言的bug修复.
Gao等人针对C程序中与内存泄露相关的缺陷,提出了Leakfix方法[23].该方法能够修复大量内存泄漏问题,其主要修复方式是在程序合适的位置插入存储单元分配语句.
Su等人提出了SRAFGEN方法[24],该方法将大量程序按照控制流结构分类.从错误程序所属的类别中,根据“程序间距离”算法找出与错误程序最相似的程序.以此程序为基础,根据对应的结构,匹配相应的语句,产生修补方案.
Gulwani等人提出了CLARA方法[25],该方法根据控制流结构聚类相似的程序,并为每一类选出一个代表程序.对于错误程序,根据控制流结构划分到相应的类,并尝试与该类的代表程序匹配,产生条件匹配对,所有条件匹配对中的条件作为可能的修改操作.最终使用0-1线性规划选取最终的修改操作.
4 总结与展望
本文提出了一种基于程序合成的 C/C++程序缺陷自动修复方法.使用缺陷定位方法——基于重写规则和基于程序频谱,得到程序中可能的缺陷位置.使用修复选项生成方法——基于重写规则和基于预测,得到缺陷的修复选项.并使用程序合成的方法进行修复选项验证,保证合成后程序的正确性.
在本文方法的实验中,我们也遇到了一些问题和挑战,这也是我们未来的研究方向:(1) 目前,本文关注的是单条语句的修改,并没有考虑增加语句或删除语句的情况,这是我们下一步研究的方向;(2) 目前,本文采用了基于重写规则和程序频谱的缺陷定位,基于重写规则的缺陷定位依赖一定的先验知识,而基于程序频谱的缺陷定位与精确定位还有一定的差距,下一步将尝试加入更多的程序缺陷定位方法,以处理如指针错误等更多类型的缺陷;(3) 目前,本文在通过预测的修复选项生成过程中,使用当前可见的全部变量替换语句结构中的相应部分,可以考虑提前过滤掉部分无关的修复选项;(4) 目前,数据集程序数量较少,下一步将继续收集更多的学生作业程序,在更多的学生作业程序上验证我们方法的有效性.
猜你喜欢
诗选刊(2022年6期)2022-05-25
计算机系统应用(2022年2期)2022-05-10
电子技术与软件工程(2021年18期)2021-11-21
学与玩(2018年5期)2019-01-21
文苑(2018年18期)2018-11-08
中国诗歌(2015年12期)2015-11-17
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
计算机工程与设计(2014年4期)2014-02-09
小雪花·初中高分作文(2009年8期)2009-11-16
