
C程序内存泄漏智能化检测方法∗
2019-06-11 07:39朱亚伟左志强王林章李宣东
软件学报 2019年5期
朱亚伟,左志强,王林章,李宣东
(计算机软件新技术国家重点实验室(南京大学),江苏 南京 210023)
内存泄漏会严重降低软件的性能,甚至造成软件在运行时崩溃.在C语言中,内存的分配与释放都是人为控制的,随着计算机软件的规模和复杂度的不断增加,人为的疏忽极易导致内存泄漏.由于C语言在计算机领域的广泛应用,C程序中的内存泄漏问题不可忽视.目前,内存泄漏的检测方法主要是静态分析与动态检测.
· 动态检测方法[1-4]需要执行程序,在程序运行的过程中对内存的分配、使用以及释放进行动态跟踪.由于动态检测能够针对当次的运行结果得到一个明确的结论,因此动态检测相对静态分析,其结果更加准确.但是动态检测的准确性受限于测试用例,无法分析程序执行中不可达位置的错误.目前,成熟的内存泄漏动态检测工具有Purify[5]、Valgrind[6]等,都存在内存开销较高和可扩展性较差的问题.
· 静态分析是在不实际运行程序的情况下对程序代码及其结构进行分析.针对C语言的内存泄漏静态分析方法主要通过分析内存的分配点以及从内存分配点开始的不同路径,在相应的路径中查找与内存分配点对应的内存释放点,验证是否所有路径都存在正确的内存释放.目前,有许多内存泄漏的静态分析工作[7-12],也有一些成熟的静态分析工具,如Fortify[13]、Coverity[14]、Klocwork[15],这些工具在工业界的软件开发中应用广泛.静态分析方法又可根据流敏感、上下文敏感以及域敏感等进行分类,实现这些静态分析方法可以在一定程度上提高内存泄漏检测的准确率,但会极大降低检测效率.
内存泄漏的静态分析目前主要缺点是:当内存泄漏中存在一些特殊案例时,会降低静态分析的准确性,导致内存泄漏的检测出现误报或者漏报.其主要原因在于:
(1) 对分支条件缺少分析,无法识别不可达路径;对全局变量和指针的重定向未做细致分析;忽略指针偏移问题.可以通过流敏感、上下文敏感等静态分析方法在一定程度上解决以上问题,但会造成检测效率大幅降低.
(2) 动态数组的分配问题、链表的分配释放不匹配问题、循环或递归中指针分析的准确性问题(限制循环或递归的展开次数)会导致指针分析不准确.流敏感、上下文敏感等目前已有的静态分析方法无法解决上述问题.
针对静态分析的上述不足,本文利用机器学习算法以提高内存泄漏静态分析的准确性,获得更加准确的内存泄漏检测结果.本文利用已有的内存泄漏案例,即含有标签为虚假内存泄漏和真实内存泄漏的两类数据集,通过使用机器学习算法进行训练,构建内存泄漏分类器以分析程序特征与内存泄漏的相关性.
本文的主要贡献在于:
(1) 本文提出一种C程序内存泄漏智能化检测方法,该方法基于静态分析提取内存泄漏相关特征,能够提高内存泄漏检测的准确性,减少误报和漏报.
(2) 我们实现了内存泄漏的智能化检测工具 I_Mem.该工具使用多种机器学习算法构建内存泄漏检测模型,并基于静态分析提取内存泄漏相关特征,能够提高内存泄漏检测的准确性.
(3) 我们在LLVM-4.0.0上实现了I_Mem,并利用4个开源的C程序(2KLOC)进行实验评估.I_Mem总共发现了114个内存泄漏,漏报为4个,误报为13个,准确率为85.6%.
本文第1节主要介绍背景知识.第2节介绍C程序内存泄漏智能化检测方法,包括方法的基本框架、内存泄漏模型的构建、特征提取与缺陷检测.第3节对本文实现的工具I_Mem进行实验和评估.第4节主要介绍相关工作,包括内存泄露的静态分析方法、内存泄露的动态检测技术和基于机器学习的缺陷检测.第 5节进行总结和展望.
1 背 景
针对内存泄漏的程序静态分析需要在获取所有内存分配点后,关注内存的定义、使用及释放.此外,C语言中由于函数可以返回指针,内存泄漏检测需要对调用点作分析.因此,Saber[8,9]关注C程序中的6种语句,见表1.在表1中,p和q是变量,v表示变量或者堆对象,F是函数.

Table 1 Six types of statements表1 6种语句类型
Saber中使用的静态分析方法是 Full-Sparse Value-Flow Analysis,通过构建 SVFG来检测内存泄漏.其中,VFG(value flow graph)[7,16]表示的是句法上的语义等价,它关注变量的定义、使用,能够表示程序中变量的价值流向.VFG不同于CFG(control flow graph)和DFG(data flow graph),CFG表示的是控制程序逻辑执行的先后顺序,一个程序的CFG被用来确定对变量的一次赋值可能传播到程序中的哪些位置;DFG是在CFG基础上实现的,它描述的是程序运行过程中数据的流转方式及其行为状态.在 VFG中,每一个节点表示变量的定义,每条边表示变量的def-use关系.Saber针对VFG进行改进构建了SVFG.SVFG的构建主要分为3个步骤.
(1) 预分析:根据内存分配相关的API(如malloc)确定内存位置.使用域敏感、调用点敏感、流和上文不敏感的安德森指针分析获取C程序的指针信息.
(2) 全稀疏SSA(static single assigment):在SSA形式中,每个被使用的变量都有唯一的定义,这可以确保精确地def-use关系链.针对所有内存位置,构造每个函数的SSA形式.关注内存位置的间接访问,如load,store以及函数调用操作.用程序内流敏感的指针分析对预分析的指针信息进一步稀疏提高指针分析的准确性.
(3) SVFG:基于全稀疏 SSA,获取程序内所有内存位置的 def-use关系链和 value-flow,并构建 SVFG.每个def-use边会有一个”警卫”来获取分支条件.
2 C程序内存泄漏智能化检测方法
本节我们主要介绍 C程序内存泄漏智能化检测方法的基本框架.本方法是在内存泄漏静态分析的基础上进行改进,利用机器学习技术提高了内存泄漏静态分析的准确性.图1是C程序内存泄漏智能化检测方法的主要框架.
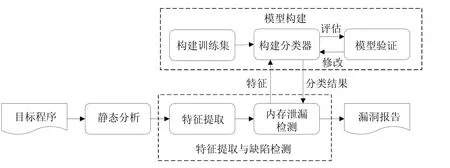
Fig.1 Framework of our work图1 本文的工作框架
该方法主要可分为两个步骤——模型构建阶段以及特征提取与缺陷检测阶段.
(1) 模型构建阶段
➢ 首先,根据已有的内存泄漏构建训练集,构建训练机分为两步:第 1步,构建包含真正内存泄漏与虚假内存泄漏的数据集;第2步,从两个数据集中分别提取内存泄漏特征;
➢ 然后,将训练集输入机器学习的分类器进行训练,并应用交叉验证对分类器进行评估;
➢ 随后,修改分类器类型及参数,选取分类效果最好的作为内存泄漏检测模型.
(2) 特征提取与缺陷检测阶段
➢ 首先,利用静态分析方法分析源程序,获取所有的内存位置(内存分配点o),并构建从o开始的SVFG,提取SVFG中每条路径对应的内存泄漏特征并构成数据集;
➢ 根据内存泄漏特征,我们可将数据集分成两部分:一部分可根据规则直接判断是否为内存泄漏,另一部分需要输入到内存泄漏检测模型中进行判断;
➢ 最后,将内存泄露检测结果与静态分析阶段的分配点的信息相结合,得到漏洞报告.
2.1 模型构建阶段
针对内存泄漏的静态分析中存在的不足,我们提取了 16个内存泄漏特征.本文根据从内存分配点开始的SVFG提取内存泄漏特征,每一个内存分配点对应一个内存泄漏特征.提取的内存泄漏特征信息(内存分配点o,内存释放点指针p)包括3类:类型信息、分支信息、释放信息.类型信息包括数组(判断o是否为数组元素)、结构体(判断o是否为结构体元素)、链表(判断o是否为链表元素),分支信息包括循环分配(o是否在循环内部分配)、循环释放(p是否在循环内部释放)、循环匹配(循环分配与释放次数是否一致)、同一循环(分配与释放是否在同一循环内)、链表匹配(链表的分配与释放次数是否一致)、分支条件(若当前分支中不存在对o的释放,则判断分支条件是否为真),释放信息包括函数间距(从o出发的SVFG最多经过的函数数量)、释放之前为空(p释放之前是否为空指针)、p指向对象数目(释放p时,p指向的对象数目)、别名数目(释放p时,指向o的指针数目)、指针偏移量(释放p时,p与o的偏移量)、全局指针(判断在SVFG中有全局变量指向o)、释放(指针p是否释放).特征见表2.
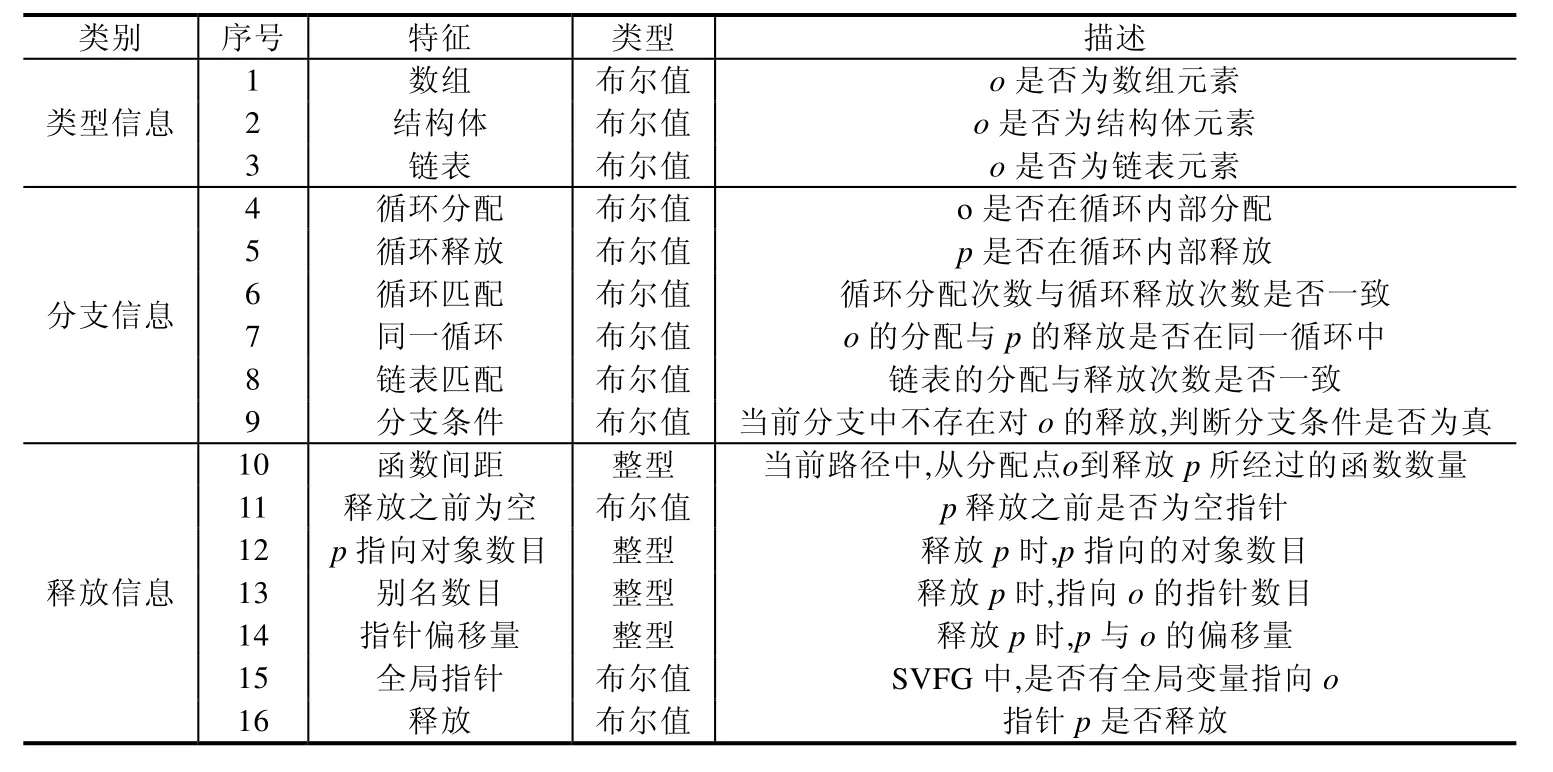
Table 2 Features of memory leak表2 内存泄漏特征
本文针对内存泄漏共提取16个特征,其中,部分特征与内存泄漏静态分析的不足存在如下的对应关系.
(1) 针对内存泄漏有关的数组、链表、循环或递归问题,我们使用特征1、特征3~特征8进行判断.
(2) 特征9用于对分支条件进行判断,特征11、特征12、特征15用于判定全局变量以及指针重定向问题,指针偏移量问题使用特征14进行判断.
(3) 其余特征用于对内存泄漏的一些复杂情况进行辅助判断.
确定内存泄漏相关特征后,我们需针对各种内存泄漏构建训练集.我们使用的是开源的C程序源码(包括一些大型程序和小程序),在原程序中,我们会插入各种内存泄漏以构建尽量丰富的训练集,然后从中区分真正的与虚假的内存泄漏.在人工对训练数据进行标记时,我们发现如下规律.
(1) 特征15、特征16都为假(即在SVFG中,不存在全局变量指向内存分配点,也不存在内存释放点),通常是真正内存泄漏.
(2) 特征11为真(即p释放之前为空指针)、或者特征12大于1(即p指向的对象数目超过1)、或者特征14不为0(存在指针偏移)、或者特征16为假(即未进行内存释放),通常是真正内存泄漏.
在对训练数据进行人工标记后,我们获取每个训练样本的内存泄漏特征,并将这些作为训练集输入分类器进行模型构建.现阶段主流的机器学习算法有 SVM、决策树、朴素贝叶斯分类、隐马尔可夫、随机森林、循环神经网络、长短期记忆(LSTM)与卷积神经网络等.本文采用 3种机器学习算法:SVM[17]、随机森林(RF)[18]和决策树[19].下面介绍3种算法的优缺点.
(1) 决策树是指 C4.5算法,优点是产生的分类规则易于理解,训练时间复杂度较低,准确率较高;缺点是针对连续属性值的特征时计算效率低,且容易过拟合.
(2) 随机森林的优点是训练速度快,易并行化,能够处理高维度的数据,适合做多分类问题;缺点是在处理噪音较大的数据集上容易过拟合,过于随机导致无法控制模型内部运行.
(3) SVM可以通过计算数学函数将训练数据分开,这些函数被称为核函数.常用的核函数有4种:线性、多项式、径向基核函数(RBF)和 Sigmoid函数.根据文献[20,21],使用 RBF核函数将每个特征向量映射到高维空间,这样可以防止过拟合.缺点是对大规模训练样本难以实施,解决多分类问题存在困难.
在构建模型时,需要确定分类器类型及参数,我们使用分类的准确率作为评估标准,然后进行迭代确定最优的分类器类型及参数,步骤如下.
(1) 首先选定第1个分类器类型以及参数并进行训练,使用五折交叉验证得到的准确率作为基线;
(2) 多次修改分类器参数(根据分类器类型可自行调整),记录五折交叉验证的准确率超过基线的分类器类型、参数以及准确率;
(3) 修改分类器类型,并重复第(2)步;
(4) 选取准确率最高的分类器(类型及参数)作为本文内存泄漏检测模型.
2.2 特征提取与缺陷检测阶段
特征提取与缺陷检测主要分为以下 3个步骤:程序静态分析、特征提取、内存泄漏检测.程序静态分析就是第1节所介绍的Full-Sparse Value-Flow Analysis.
2.2.1 特征提取
本文通过构建SVFG并获取特征,算法1阐述了如何通过SVFG来获取内存泄漏特征,该算法的输入是内存位置(内存分配点)集合src以及SVFG.基本思想是:分析内存分配点的信息获取内存泄漏的部分类型和指针信息,分析内存分配点到释放点的路径信息获取内存泄漏的其余信息.
· 首先,在第1行~第5行,我们初始化存放特征信息的向量V,然后遍历内存分配点的集合src,并从内存分配点开始向前遍历SVFG,获取当前内存分配点的部分类型信息和分支信息(如内存分配点是否为数组或者结构体、内存分配点是否在循环中等)存入V中,记录经过的节点集合FNode以及内存释放点集合dst,并初始化BNode集合(用于存放内存释放点向后遍历SVFG经过的节点).
· 然后,在第6行至第11行,遍历内存释放点集合dst,并从内存释放点开始向后遍历SVFG,若当前节点出现在FNode中,则将该节点放入BNode中.
· 最后遍历FNode与BNode,获取当前内存分配点对应的特征信息存入V中.
算法1.SVFG遍历获取内存泄漏特征.


如图2所示,我们给出了一个具体示例展示如何从源程序中提取特征.图2(a)是C程序源码,图2(a)左边为代码行号.图2(b)是根据源码获取的特征以及对应的属性值.其中,O1对应第16行内存分配点的特征信息,O2对应第5行内存分配点的特征信息,O3根对应第6行内存分配点的特征信息.根据图2(b)可知.
·O1所对应的特征1、特征4~特征6、特征9、特征16为TRUE,表明该内存位置在循环中分配与释放,且分配与释放次数一致;特征10的值为3,表示从内存分配点到释放位置经过3个函数.
·O2所对应的特征 15、特征 16均为 FALSE,表明该内存位置没有进行内存释放,也没有全局变量指向该内存位置.
·O3所对应的特征15为TRUE,特征16为FALSE,表明该内存位置没有进行内存释放,但存在全局变量指向该内存位置.
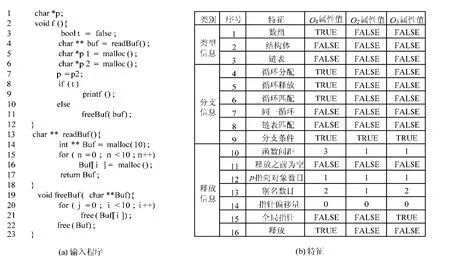
Fig.2 Example of feature extraction图2 特征提取示例
2.2.2 内存泄漏检测
获取所有内存泄漏特征的数据集后,我们首先根据判定规则依次对数据集进行筛选,判断结果主要分为 3类:疑似内存泄漏,表示为T;可能非内存泄漏,表示为F;无法判断,表示为N.内存泄漏判定规则如下.
(1) 若特征15、特征16全部为假(即在SVFG中,没有全局变量指向该内存分配点,也不存在内存释放语句),则判定结果为T.
(2) 若特征15为真、特征16为假(即在SVFG中,存在全局变量指向该内存分配点,不存在内存释放语句),则判定结果为N.
(3) 对于不满足第1条规则且不满足第2条规则的数据,提交给内存泄漏检测模型,得到内存泄漏检测结果.内存泄漏模型中检测结果分为两类:T和F.
根据判定规则(1)和规则(2):若在SVFG中没有全局变量指向该内存分配点,也不存在内存释放语句,则可直接判断为疑似内存泄漏;若在SVFG中存在全局变量指向该内存分配点,但不存在内存释放语句,由于全局变量可能在任何地方释放,我们不做判断,视为警报.因此根据规则(1)和规则(2),我们可直接判断数据对应的分类结果,无需使用内存泄漏检测模型.根据第3条规则,图2(b)中O1所对应的特征应该输入内存泄漏检测模型.根据第1条规则,图2(b)中O2所对应特征的判定结果为疑似内存泄漏.根据第2条规则,图2(b)中O3所对应的特征则无法判断是否发生内存泄露.
提取数据集中判定结果为疑似内存泄漏的分配点,并结合内存位置信息给出漏洞报告.报告中标明疑似内存泄漏,并给出每个泄漏点的文件名、行号以及分配语句.
3 工具与评估
我们基于LLVM编译器(版本4.0.0)实现我们的C程序内存泄漏智能化检测工具I_Mem,工具框架如图3所示.我们的智能化检测工具I_Mem主要分为3个模块:内存泄漏检测模型、特征提取和内存泄漏检测.分别于第2.1节、第2.2.1节和第2.2.2节对应.

Fig.3 Framework of I_Mem图3 I_Mem框架
在实验中,每个C程序的源文件都由Clang编译成LLVM bitcode文件格式,再由LLVM Gold Plugin进行合并,生成整个程序的bc文件.在模型构建阶段,我们使用的SVM分类器是libSVM[22],随机机森林和决策树使用的是机器学习工具 weka[23].我们的实验分为两部分:一是在模型构建阶段对我们的模型进行评估;二是在特征提取与缺陷检测阶段对内存泄漏的检测结果进行评估.
3.1 模型构建阶段
我们从开源的 C程序中提取真正的与虚假的内存泄漏实例来构建机器学习分类器,我们提取内存泄漏示例的开源C程序主要有icecast-2.3.1,cluster-3.0,droplet-3.0,wine-0.9.24以及SPEC 2000中的ammp,equak,然后,通过以下步骤获取真正的与虚假的内存泄漏.
(1) 关注源码中所有的内存分配点,通过添加或者注释内存释放点来获取真正的与虚假的内存泄漏.
(2) 仿照已经获取的内存泄漏实例,在源码中插入各种内存泄漏以构建丰富的训练集,尽量满足各个特征的属性.
通过以上两个步骤,我们可以获取大量的内存泄漏实例用于机器学习分类器的构建.模型构建阶段总过获取了1 728个内存泄漏实例(396个虚假内存泄漏,1 332个真正内存泄漏).构建模型中,我们采用五折交叉验证来确定准确率最高的分类器类型和参数.准确率是正确分类的样本数与总样本数之比.
我们使用五折交叉验证,在1 728个实例中进行模型训练与评估,对于SVM、随机森林和决策树这3种机器学习算法,我们选取每种机器学习算法在训练过程中准确率最高的进行展示,见表3.

Table 3 Results of classification表3 分类结果
如表3所示,SVM的分类准确率为97.7%,随机森林与决策树的准确率99.6%.因为决策树容易出现过拟合现象,因此我们选取随机森林作为我们内存泄漏检测模型.实验结果表明,我们构建的随机森林模型在对真实与虚假的内存泄漏进行分类时是有效的.
3.2 特征提取与缺陷检测阶段
我们的实验分为两部分.
· 第1部分的实验数据来自基准程序Siemens[24].共有4个程序,这些实验对象的规模都比较小,存在的内存泄漏不多,因此,我们在源码中手工植入内存泄漏,特别是植入与数组、循环、链表等有关的内存泄漏,以验证内存泄漏模型在检测各种类型内存泄漏时的有效性.
· 第2部分数据来源于原生SPEC 2000[25],我们选取了3个程序,以验证内存泄漏模型在检测大规模程序时的有效性.
实验对象见表4.

Table 4 Experimental subjects表4 实验对象
我们的方法是在 SVFG的基础上提取内存泄漏特征,并利用机器学习技术进行内存泄漏检测,因此,我们选取Saber来比较本文方法和静态分析方法的效果.Saber通过构建源码的SVFG来判断内存泄漏.在表5中展示了本文方法与Saber在Siemens程序上的对比实验结果.
根据表5中的结果,我们可以得到如下结论.
(1) 两种内存泄漏检测方法的漏报数目都比较低;
(2) 针对内存泄漏的一些特殊案例,如内存泄漏的分配、使用或者释放出现了循环、递归、链表等情况时,Saber误报较多,例如print_tokens程序中的34个内存分配点,Saber的误报是10个,本文只有5个.

Table 5 Experimental results of Siemens表5 Siemens实验结果
表6为SPEC 2000的实验结果.总结两部分实验,我们可以得到如下结论.
(1) 本文方法在静态分析的基础上利用机器学习算法提高了内存泄漏检测在特殊案例上的准确性.
(2) 本文的内存泄漏模型在检测大规模程序时是有效的.

Table 6 Experimental results of SPEC 2000表6 SPEC 2000实验结果
3.3 讨 论
内存泄漏静态分析方法的缺点在于大规模程序误报多,需要人工确认.本文利用机器学习方法获取已有的知识经验,帮助提高内存泄漏静态分析的准确性.在选取内存泄漏特征时,我们研究内存泄漏机理,调研内存泄漏检测方法,从而确定内存泄漏相关特征,并构建内存泄漏检测模型.实验结果表明,本文方法确实有助于提高内存泄漏检测的准确率.在模型构建阶段,我们对构建的内存泄漏检测模型进行五折交叉验证,交叉验证结果准确率高达 95%以上.实验结果表明,我们构建的内存泄漏检测模型在对真实与虚假的内存泄漏进行检测时是有效的.在特征提取与缺陷检测阶段,在Siemens的实验数据上,我们的方法与Saber进行对比实验,Saber的平均准确率只有69.5%,我们的方法准确率高达88.1%;在SPEC 2000的实验数据上,总共184内存分配点,Saber的误报为11个,我们的误报只有2个.
综上所述,我们的实验结果表明,C程序内存泄漏智能化检测方法在针对数组、循环等相关的内存泄漏时能够得到更加准确的检测结果.在静态分析的基础上,利用机器学习算法,使得内存泄漏检测结果更加准确.此外,实验中存在一些不足需要注意:目前,我们只针对 C语言内存泄漏进行检测,并不支持 C++;实验中,我们所选取的是简单的基准程序,并在源码中插入一些内存泄漏特殊案例,并不保证该方法对内存泄漏其他特殊案例检测都具有较高的准确率.但是我们相信,实验的结果确实表明了本文的方法在检测内存泄漏上的可行性及准确性.
4 相关工作
在本节中,我们主要通过以下3个方面来介绍和讨论相关工作:(1) 内存泄漏的静态分析;(2) 内存泄漏的动态检测;(3) 基于机器学习的缺陷检测.
4.1 内存泄漏的静态分析
内存泄漏通常是由于人为的对程序中动态内存的管理不当造成的,内存泄漏会导致内存空间被消耗,且在程序运行期间无法回收和重新利用.内存泄漏十分隐蔽,在程序运行初期不易被发现;但是对于长期运行的程序,特别是服务器,影响十分显著,它会降低程序性能,甚至导致程序在运行时崩溃.特别是在 C语言中,内存的分配与释放都是人为控制的,内存释放这一步骤极容易被忽略,从而导致内存泄漏.
静态分析主要是根据特定的错误模式来查找内存泄漏,或者建立内存状态模型来进行内存泄漏检测.Cherem 等人[7]通过构建数据流图进行数据流分析,分析数值从内存分配点到内存释放点的路径中是否正确传播来检测内存泄露.Saber通过构建C程序的SVFG检测内存泄漏.Orlovich等人[10]首先假设内存泄漏存在,然后进行反向数据流分析,验证该假设是否成立.RL_Detector[11]基于控制流图(CFG)进行数据流分析,利用静态符号执行对于每个资源(包括内存泄露)收集所有路径约束,通过路径约束计算数据流条件并检测资源泄露.Heine等人[12]开发了一个描述指针隶属关系的模型,在该模型中,每个内存对象只能被1个拥有指针指向,因此该指针是唯一的且具有传递性,基于此对程序生成一种约束,用来检测内存泄漏.Cai等人[26]提出了基于上下文无关文法可达性的由调用上下文向引用上下文自动转换的方法,用于辅助内存泄漏动态检测方法,从而提供对象引用路径等更丰富的报告信息,也为将来扩展我们方法中内存泄漏特征提供参考.
内存泄漏静态分析的优点是能够自动化运行,检测速度快;缺点是误报较多.目前,也有一些工作是在静态分析的基础上对内存泄漏进行修复.内存泄漏修复需要首先定位内存泄漏位置,因此,内存泄漏修复的准确性首先取决于内存定位的准确性,其次是插入释放语句的准确性.目前,主要的内存泄漏修复工作有:
· Leakfix[27]基于指针分析和数据流分析,判断内存泄露位置并进行内存泄漏的修复.Leakfix能够保证为一个内存泄露生成多个修复程序,但不能保证生成的修复程序完全解决了该内存泄漏.
· AutoFix[28]是根据已有的静态分析警报,通过指针分析构建 VFG,再根据活性分析判断内存泄漏位置,进行内存泄漏的修复.Autofix通过代码插桩进行内存泄漏的修复,并在一个沙箱中运行程序进行检查,确保修复的安全性.
内存泄漏的修复首先需要确保内存泄漏检测的准确性,不能对误报进行修复;其次,内存泄漏修复需要保证修复的正确性.Leakfix在修复之后需要使用内存泄漏检测工具进行检测,AutoFix则是自动的在修复之后运行程序进行安全性检查.因此,内存泄漏的修复受限于规模,如何提高内存泄漏修复的可扩展性以及准确性依然是一个难题.
本文的主要工作是在静态分析的基础上,利用机器学习技术进行内存泄漏检测,减少了静态分析的漏报和误报,提高了静态分析的准确性,尤其在针对内存泄漏的特殊案例时,能够显著提高内存泄漏检测的准确性.
4.2 内存泄漏的动态检测
内存泄漏的动态检测方法需要运行源代码,在程序运行过程中对内存分配、使用以及释放进行动态跟踪.LeakPoint[1]基于污点传播的思想监控内存对象的状态,追踪内存最后的使用位置以及失去引用的位置.DOUBLETAKE[2]将程序执行拆分为多个块,在每个块运行开始之前保存程序状态,在该块之行结束之后检查程序状态,判断内存是否发生错误.Sniper[3]利用处理器的监视单元(PMU)进行指令采样,来跟踪对于堆内存的访问指令,然后通过离线模拟器分析指令计算堆对象的陈旧度,并重新执行相关指令,捕获程序执行期间的内存泄漏.Omega[4]主要采用指针计数的思想记录内存对象的引用计数.
动态检测相对于静态分析更加准确,但是动态检测无法分析程序执行中不可达位置的错误.动态检测最大的缺点是效率低,耗时长.目前,代码规模和复杂度日渐增加,内存泄漏的动态检测效率远远无法满足工业界的需求,并且随着静态分析技术的发展,内存泄漏静态分析结果的准确率逐渐提高,静态分析的使用更加广泛.因此,本文的方法是基于静态分析,利用规则和机器学习技术进行内存泄漏检测,具有高效率和高可靠性.
4.3 基于机器学习的缺陷检测
目前,机器学习技术已被广泛运用于程序分析中以检测程序缺陷.Alatwi等人[29]实现了一种检测安卓应用程序是否属于恶意软件的方法,其主要思想是将 apk反汇编为源码,然后利用静态分析方法提取代码代征,并选取可用于模型预测的最佳特征组合,构建 SVM 分类器进行检测.Tac[20]主要利用机器学习算法来消除 typestate和指针分析的差距,它从源码中提取35个特征,并训练SVM分类器以检测Use-After-Free.Nagano等人[30]对执行文件进行静态分析,然后利用机器学习的分类算法及自然语言处理技术来识别恶意软件.Grieco等人[31]从二进制文件中提取程序静态特征,从程序执行中提取动态特征,然后利用机器学习技术训练模型来检测内存冲突.
本文的主要工作是通过静态分析提取内存泄漏特征,然后利用规则和机器学习模型检测内存泄漏.我们关注的重点是内存泄漏的特殊案例,因此在检测内存泄漏上准确性更高.
5 总结与展望
本文提出了一种 C程序内存泄漏智能化检测方法,首先构建机器学习模型,然后在内存泄漏静态分析的基础上提取内存泄漏特征,并利用规则和机器学习模型进行内存泄漏的检测.实验结果表明,我们构建的内存泄漏检测模型在对真实与虚假的内存泄漏进行检测时是有效的.相对于目前的内存泄漏静态分析方法,本文方法在针对数组、循环等相关的内存泄漏时检测结果更加准确.
在本文方法的实验中,我们也遇到了一些问题和挑战,这也是我们未来的研究方向:(1) 目前,本文在特征选取与缺陷检测阶段选取的实验数据为简单程序且人为插入了各种内存泄漏,下一步需要选取一些开源的大型程序进行实验;(2) 本文目前关注的重点是C语言中与循环、结构体、数组以及链表有关的内存泄漏,可以扩展至 C++中,关注类以及各类容器有关的内存泄漏问题;(3) 当前的工作可以扩展到其他内存缺陷中,目前提取的特征适用于构建内存泄漏的分类器,我们可以提取更多的程序特征,构建多种内存缺陷检测的分类器;(4) 本文目前的静态分析方法是对每个内存分配点提取一个内存泄漏特征,我们可以进行细化,对于每个内存分配点的每条路径提取一个内存泄漏特征,这样,检测结果会更加准确,检测报告会更加详细.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
云南画报(2021年8期)2021-11-13
北京航空航天大学学报(2021年6期)2021-07-20
计算机系统应用(2021年2期)2021-02-23
软件学报(2020年6期)2020-09-23
计算机测量与控制(2019年4期)2019-05-08
广东第二课堂·小学(2017年9期)2017-09-28
科技视界(2015年24期)2015-08-22
专用汽车(2015年1期)2015-03-01
软件工程(2014年3期)2014-03-15
