
基于加权二部图的个性化方案推荐
2019-06-06 01:28耿秀丽
上海理工大学学报 2019年2期
杨 珍,耿秀丽
(上海理工大学 管理学院,上海 200093)
随着互联网的快速发展,数据日益以几亿级别的速度增长,导致所需信息的获取难度提升,推荐系统就是为了解决信息超载问题而出现的,它主要根据用户历史行为推荐相似产品或服务。电子商务类网站的推荐系统已经较为成熟,如阿里巴巴、亚马逊等,都采用推荐技术向用户推荐其可能感兴趣的产品,挖掘潜在客户,从而提高产品收益。方案设计是根据顾客需求确定设计方案的过程,随着市场环境的变化,客户需求越来越有个性化,企业需要设计个性化的产品/服务方案。传统产品/服务设计方案的生成方法主要有配置技术、规则技术等,本文采用电子商务领域成熟的推荐技术研究个性化方案推荐技术,用于提高方案设计的精度和效率。
推荐技术是推荐系统的核心技术,根据以往顾客需求偏好、行为信息等建立兴趣模型,并用推荐算法向新顾客推荐其未曾产生行为的产品或服务。协同过滤算法(collaborative filtering algorithm,CFA)作为推荐技术中应用比较成熟的算法之一,其基本思想是根据顾客需求行为的相似度来推荐资源。协同过滤算法的缺陷包括数据稀疏性、冷启动性及用户偏好各异等。其中,稀疏性是指用户对已有产品或服务方案评分很少,导致形成的数据矩阵稀疏。冷启动性是指在已有用户-项目规则库中,没有可以依据的新用户行为记录,难以对其推荐预测目标。协同过滤算法理论研究主要分为两种:基于模型的方法和基于内存的方法[1]。基于模型的CFA一般通过数据集训练出用户兴趣模型,并基于此模型对新用户进行推荐;而基于内存的方法则是通过建立用户-项目的评分矩阵,既可以预测用户缺失的数据,弥补数据稀疏性的问题,又能够向用户推荐相似的项目[2]。基于模型的方法构造模型的前期时间较长,但对用户的响应速度最快,而基于内存的方法可以节省模型构建时间,且注重内部数据的完整性。本文侧重于研究基于内存的CFA,并融合了基于模型的CFA建模的思想,即结合两者的优势。
协同过滤算法具有稀疏性、冷启动及用户偏好不一致等问题,基于内存的CFA也有类似问题,学者们对其进行了改进或修正,主要包含以下两种情况:一是通过相似性度量的修改、最近邻的选择等提高推荐准确度;二是结合其他算法的CFA提高推荐效率,如结合矩阵分解、概率模型、贝叶斯模型及云模型等。针对第一种情况,文献[3]采用基于改进相似度的CFA,构建网络项目的特征相似性模型,得到项目特征邻居并选择前N项推荐给用户,实现网络干扰的有效过滤,从而避免稀疏数据评价中产生的不足;文献[4]提出基于最近邻的CFA,保证推荐精度提高的情况下,降低计算过程的复杂度;文献[5]根据用户历史行为数据差异性,提出基于改进用户相似度的算法,在相似度计算过程中添加平衡阈值,显著优化用户相似性并得到好的推荐结果。文献[4-6]主要采用基于最近邻的改进CFA方法,相互弥补最近邻和CFA两种方法的优劣势,进而提高推荐精度。如文献[6]在推荐算法中引入聚类方法,通过用户评分构建动态多维用户网络,采用改进K-means 算法对用户聚类,将预测目标推荐给用户,形成应用于动态多维社会网络中的个性化推荐算法,从而提高推荐精度。上述文献中CFA的研究仅仅解决协同过滤中的数据稀疏性、冷启动、用户偏好不一致中的某项问题,并未全面考虑一次性解决这3个问题来提高推荐效率。本文综合考虑这3个问题,提出基于二部图的个性化推荐方法。首先,针对CFA的稀疏性问题,已有研究都是从弥补数据稀疏性的角度研究,文献[7]采用二部图算法,清理掉孤立的网页服务结点和工作流结点,提高数据完整性以及网页服务的推荐效率;文献[8-9]采用二部图与CFA结合的算法,解决数据稀疏性问题。考虑到二部图可以缓解CFA稀疏性,但合并数据精度不高,本文引入文献[10]中加权二部图的思想,合并关联度高的稀疏数据,形成完整性数据,提高数据处理的效率。其次,针对CFA的冷启动问题,相关文献研究采用基于内存的CFA预测目标,即改进自身算法,或是结合其他算法弥补CFA缺陷,而本文基于加权网络改进CFA,对新用户预测推荐方案,提高预测目标的精确性,解决冷启动问题。最后,针对用户兴趣各异的问题,本文提出采用基于用户特征以及方案特征评分的协同过滤算法,不仅解决了用户偏好相异的问题,而且能够依据用户的简单需求提供合适的方案,即通过计算产品功能性特征的相似度,将相似度高的产品予以推荐。
本文采用加权二部图与加权网络的协同过滤混合算法,考虑用户偏好相异,将用户特征引入推荐系统,合理化资源分配过程,提高推荐精度。该方法的具体过程分为3个部分。首先,确定用户的特征属性以及方案属性,对原始数据库中的用户特征采用加权二部图将用户进行分类,形成新的用户集;然后,采用加权二部图计算方案特征相似度,将相似度高的用户进行聚类,并采用TOP-N方法将相似用户进行排序,形成规则库;最后,采用协同过滤算法将新用户的特征与规则库中的用户特征进行匹配,并推荐已有的定制方案。
1 研究框架
U=U1,U2,U3,···,UmUi(1≤i≤m)S=S1S2假设企业中的数据库包含用户数据集和方案数据集,用户集 ,表示用户类型,用户定制产品的方案集表示方案类型。用户集中的特征集为其中,与U组成用户-特征的二维矩阵。方案集中的产品特征集为与 Sj组成方案-特征的二维矩阵。本文是对用户与方案间的特征匹配,首先汇集用户已定制的方案,采用加权二部图,即确定用户-方案间的权重,根据用户相似特征分类,形成用户-方案规则库;然后采用基于加权网络的CFA,对新用户C=C1,C2,C3,···,Ck推 荐定制方案, Ch(1≤h≤k)表示单个用户 ,其 所 提 需 求 特征CP=CP1,CP2,CP3,···,CPlCPq(1≤q≤l)与用户-方案规则库中的用户特征进行相似度匹配,对方案集进行TOP-N排序并推荐,框架如图1所示。
2 基于加权二部图的用户-方案模型
为了提高个性化方案推荐方法提供可靠方案的准确率,本文提出采用加权二部图方法,合并高相似特征的用户,建立用户-多方案模型并对用户方案排序,建立用户-方案规则库,这是整个方案推荐过程中的核心部分。因此,采用CFA匹配新用户与规则库中的用户,推荐相应方案集,即如果有新用户需要定制方案,可以根据其描述特征,从已有用户-方案规则库提取用户特征匹配的规则,筛选适合的用户方案予以推荐。
2.1 二部图的概念
Guimera提出的原始二部图,是指从随机图的期望值中,得出边缘集数的累积偏差。无向图G =(V,E),G的每条边为E,其顶点集合V可分为2个子集U和S。
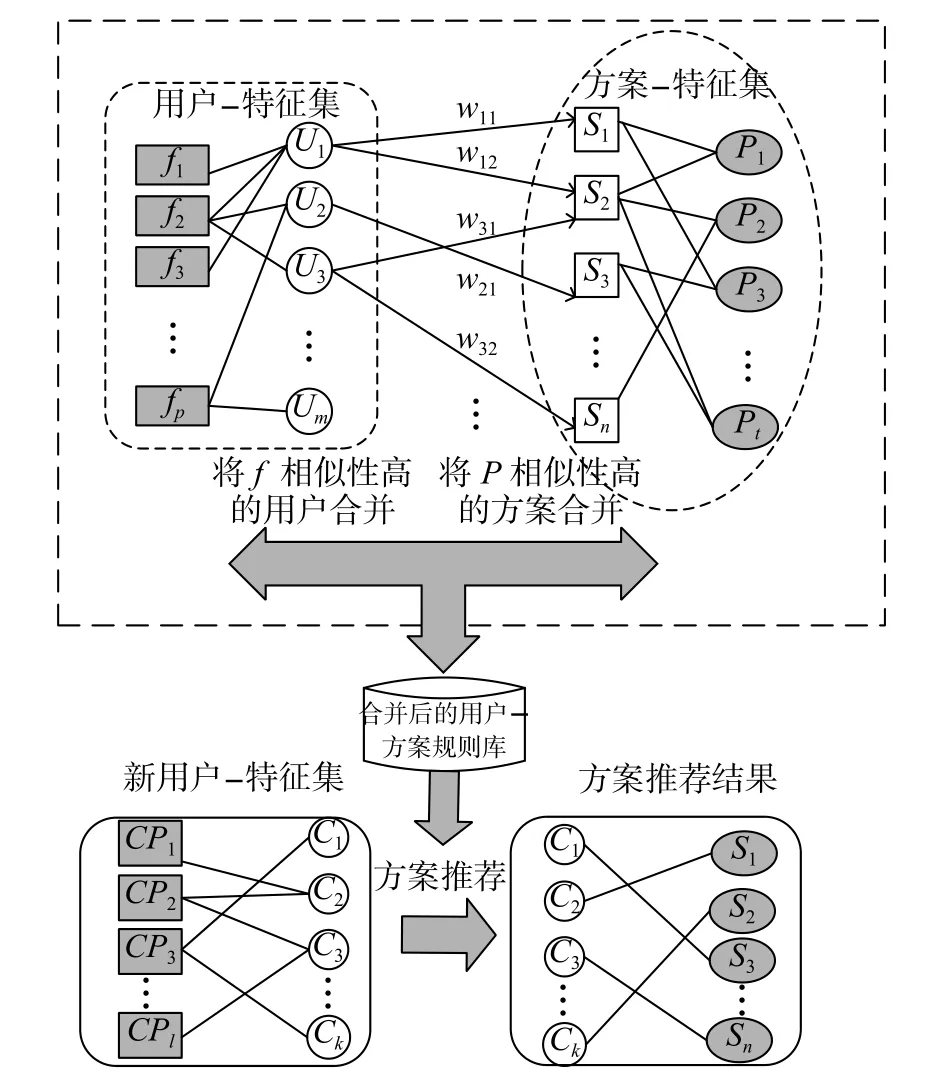
图1 用户-方案评分二部图Fig. 1 User-scheme score bipartite chart
定义1[7]二部图。
二部图是一类特殊的图,图中结点根据特性分为两类,其中,被归到同一类中的结点都具有相似的特性。边则连接来自不同类的2个结点,表示结点之间的关联。定义二部图
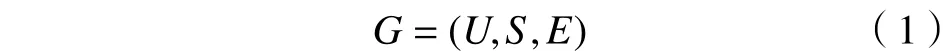
式中:U为图的一类结点的集合,U= {Ui}, Ui为一类结点集合的元素;S为另一类结点的集合,S={Sj},Sj为另一类结点集合的元素;E为两类结点连接的边的集合,E={eij},eij为集合的元素。
定义2[7]邻边。
二部图邻接矩阵A,B用于表示二部图中的信息。aij,big为邻接矩阵中的元素。
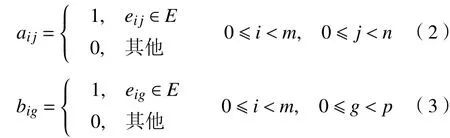
aij数值用于判断结点间是否有连接,即用户Ui有无选择方案Sj,若选择,则aij值为1,反之值为0,m和n分别表示二部图中两类结点的数量。big是指用户Ui有无描述特征fg,若有,则该值为1,反之为0。
定义3[7]权重。
边的权重是指边两端的结点间关联的重要程度,用户-方案之间的权重为 wij,表示方案Sj在Ui所有方案中评价值的比重,即用户对方案的偏好度, wij越大,表示用户对方案越认可,则用户和方案之间的关联性越强。
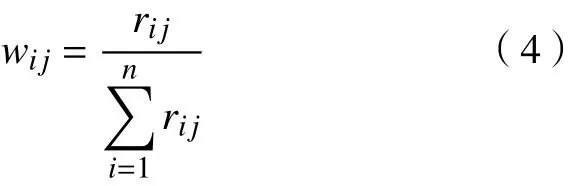
式中,rij表示用户Ui对方案Sj的评分。
定义4 评分矩阵。
方案-特征间的评分表示为SPnt,是指特征在方案中的重要程度。用户Ui对非功能性特征fg评分结果为 ,用户对每个特征的认可程度从差到好表示为1-5,0表示用户未选择该特征,评分结果形成二维矩阵B。
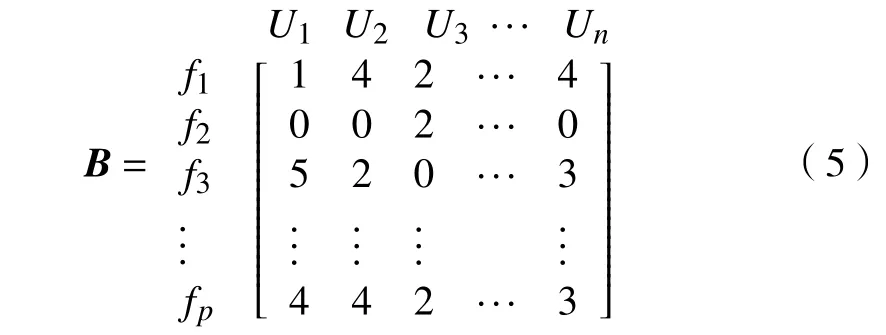
如果用户没有选择任何特征标签,可以根据其定性描述,将其按专家打分重要性进行分类,转化成定量化数据,从而解决模糊不确定的评价信息。
定义5 评价指标。
针对定性化描述的评价指标,具有模糊不确定性,而式(6)通过定量化方式来计算方案分配给用户的比重。本文通过专家评分将定性指标转为定量数据,采用式(6)计算出具体评分指标值。
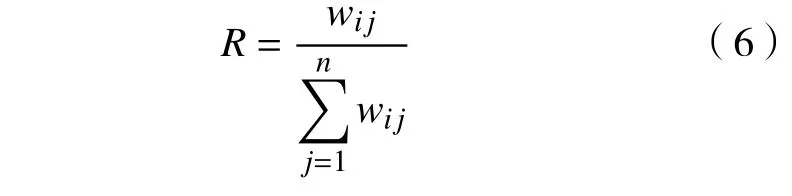
式中:R表示适合用户Ui的方案Sj排名计算方式; wij表示方案Sj在Ui所有方案中评分值的比重,为方案Sj被采用后被用户评价的分值总和。
定义6[10]二部图相似度。
当新用户选择方案时,根据其所描述的功能性或非功能性特征,计算新用户Us特征fg与规则库中用户Ui特征相似度为simCU。

式中:big,bsg表示用户Ui和Us是否选择特征fg,表示用户Ui和Us对特征fg的评价值;对共同评分特征的加权值。
2.2 基于加权二部图的用户-特征聚类过程
考虑到新用户先前没有方案推荐行为记录,难以计算该用户和其他用户的相似度,即推荐算法的冷启动问题,也是目前推荐系统面临的关键问题。所以,在用户-方案规则基础上引入特征标签,形成用户-特征的推荐方案模型。采用加权二部图对用户特征分类,用户将已有的特征评分矩阵投影在二部图中,通过式(6)对用户非功能性特征进行聚类,形成新用户集这样既减少冗余数据,节省存储空间,又便于个性化方案的查询和推荐,具体如图2~4所示。

图2 用户-方案初始集Fig.2 User-scheme initial set
图3 用户-特征评分Fig.3 User-feature score
图4 新的用户-方案集Fig.4 New user-scheme set
首先取出用户对特征的评分,其次利用式(6)求出用户特征的相似度,将相似性高的近邻用户对应方案以及用户-方案间的权重合并,形成一对多的方案集,既能压缩用户集,节约存储空间,又能根据用户-方案规则库中的用户特征匹配方案推荐,给予新用户更多选择推荐方案的机会。
对于大型体育赛事而言,观众是其最为重要的因素之一,研究观众的消费特点是运作管理大型体育赛事的前提所在。通过对三省省会城市观赏型体育消费者的调查,到实地观看体育赛事的男性比例为78.2%,女性为21.8%.表明较女性而言,男性更容易接受竞争与对抗的体育赛事。在影响观众的负面消费因素中,竞赛水平欠佳、门票价格无法接受、运动员水平有限分别位于前三(如表2所示)。
2.3 基于加权二部图的方案过滤推荐
依据形成的新用户-方案集,针对局部用户对应的方案集太多,如果都推荐给用户,难以保证满意度且效率低。对此,采用二部图的邻居元素、权重以及二部图评价指标的计算方式,将同一用户对应方案集由高到低排序,选取前N项的方案推荐,具体的过程用伪代码描述如下:

现介绍具体步骤。
步骤1首先通过以往用户方案的评价信息,计算并输入到二部图中,连接2个二部图构建用户-方案集,方案-特征集如图5所示。SP表示方案特征的评分。
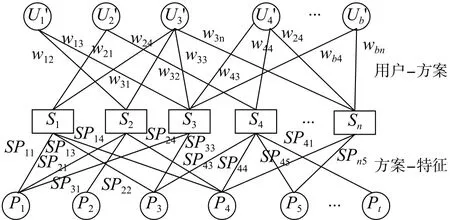
图5 二部图组合Fig.5 Combination of bipartite graphs
步骤2遍历二部图的结点,如用户结点对应的方案结点为S2和S3,这是用户-方案集的二部图,方案S2对应特征为 P1,P2,P4,方案S3对应特征为P1,P3,这是方案-特征的二部图。本步骤计算方案-特征之间的关系,先计算特征P在方案中对应的比重,如P1在S2的比重为P2,P4同理,得出加权分
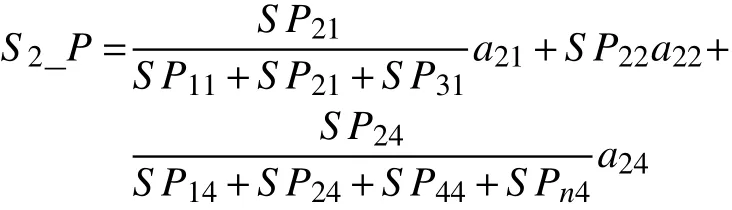
同理,

式中:a21表示 S2与 P1之间的评分;a22,a24,a31,a33同理。
步骤3计算方案S2和S3在用户结点的比重,对的值排序,筛选自己所需的方案。
通过以上步骤,本文对特征相似的用户聚类及对应方案排序和推荐,形成用户-方案规则库,便于给新用户推荐已有定制方案,提高方案推荐的效率。
3 改进的协同过滤算法
3.1 相关概念
皮尔森系数常用于推荐系统中的相似性计算,确定非功能属性值的相似性。式(8)为皮尔森相关系数的计算方法。
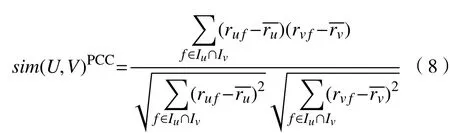
式中:Iu和Iv分别表示用户U和V评价过的非功能性特征F的集合;和分别表示用户U和V对非功能性特征的评分;和分别表示用户U和V对共同评价非功能性特征F的平均值。所以,用户相似度的数值属于闭区间[-1, 1],值越大表示用户U和V越相似。
式(9)为Jaccard系数的计算方法。

3.2 基于加权网络的协同过滤算法
为了解决新用户的方案定制推荐问题,建立一个加权网络的评分项目,其中,每条边的权重值为共同评分用户的数量。此外,为了预测推荐目标的精确性,本文通过阈值限制匹配用户,所以,在加权网络中,2个用户必须满足其共同评分项的数量大于阈值这个条件,从而过滤掉权重低于阈值的用户集[11]。

由于皮尔森相关系数主要在求解2个用户之间评分相似度起作用,Jaccard系数侧重于解决项目的评分相似度方面的问题,但是,都存在数据稀疏性问题,导致目标预测结果不精确。而连接强度通过拓扑结构弱化了稀疏性问题,一定程度上提高了预测准确率。综合考虑以上3种方法,本文提出采用新用户相似度计算公式:
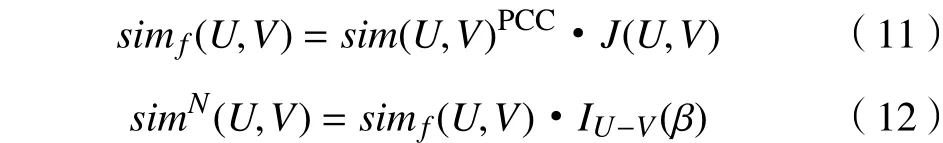
4 实例研究及对比分析
4.1 实例研究
某汽车4S店想要提高销售的效率,希望定制产品的个性化推荐方案,能够准确地推送给新用户,满足其需求。与文献[12]建立用户偏好模型不同,本文建立用户-特征和方案-特征2个模型,并用二部图建立2个模型间的联系。通过整理以往顾客购买产品历史记录信息,本文主要选取用户购买实用性的家庭装车型,选择代表性强的数据,得出用户特征包括: 变速箱f1,座位数f2,经济环保f3,安全性f4,舒适性f5,售后服务f6,成本f7,用户选择的方案包括:小型车S1,S2,S3,SUV车型 S4,S5,S6,MPV车型S7,S8。方案特征包括:动力性P1,燃油经济性P2,制动性能P3,汽车通过性P4,轮胎性能P5,载客数P6,汽车噪音P7,排放性能P8,安全性P9。具体的指标如表1和表2所示。
该企业的汽车销售数据库包括用户方案对应的非功能性和功能性特征的数据。首先将非功能性数据,即用户特征集取出,设置相似度阈值为0.9,并基于用户特征计算相似度,超过给定阈值则合并用户对应的方案集;其次采用基于二部图排序的方法,筛选并得到某用户的多方案,筛选前N项的方案给予推荐;最后采用改进CFA,对新用户的某些需求特征与生成的方案规则库匹配,现介绍具体的步骤。
步骤1根据汽车购买用户特征,f2,f3,f4,f7由低到高用1-5表示,f1,f5,f6由低到高用1-4表示。采用式(6)计算特征数据相似度,但如果用户并未对特征打分,依据其定性描述,采用专家已评定好的标准将其转化为定量化数据。采用二部图相似度式(6),计算用户评价汽车特征的数据,如图6所示,其中,权重设置为0.5。

表1 用户特征指标Tab.1 User characteristics indicators

表2 方案特征指标Tab.2 Programme characteristic indicators
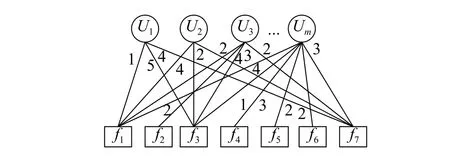
图6 用户-特征图Fig.6 User-feature chart
以U1和U3的相似度计算为例,超过阈值0.9,因此,合并U1和U3的用户特征,将U1和U3定制的方案聚集并组成。同理,合并用户之间特征相似度超过0.9的方案,并以用户共同评价特征的最大值作为新用户评分值,相异的评价特征不变并保留,得出用户-方案集其中,用户方案权重由用户对方案评分的比值决定,并代入图7,具体过程如图8所示。

图7 合并后的用户-方案集Fig. 7 Merged users-scheme set
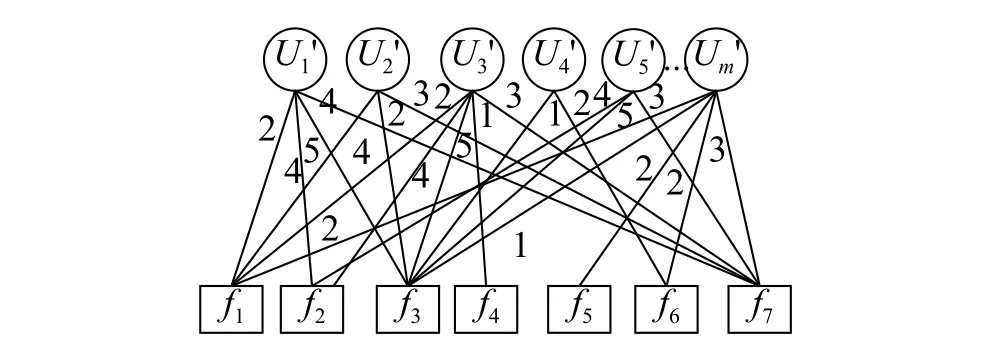
图8 合并后的用户-特征集Fig. 8 Merged user-feature set
步骤2采用加权二部图对每个购买汽车的用户其对应的方案集排序,即根据方案特征的评分,通过1,2,3来表示方案特征的好坏,采用加权二部图的方法计算并排序,选取排名靠前N项的方案推荐,具体如图9所示。
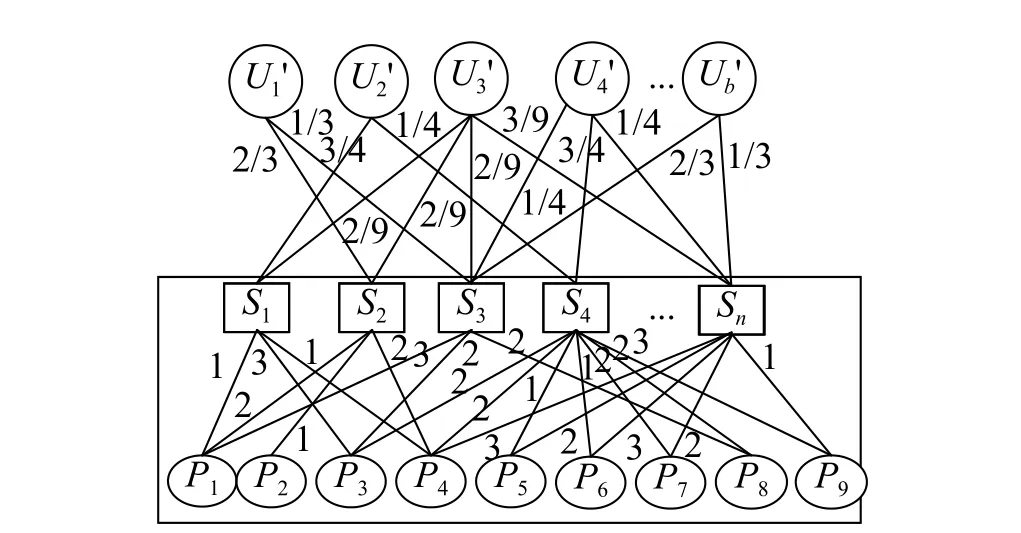
图9 用户方案-特征集Fig.9 User scheme-feature set
步骤3基于步骤3生成的方案规则库,给欲购买汽车的新用户提供便利。当新用户进入4S店购买汽车时,让其提出需求汽车的非功能性特征F,采用1-5这5个等级评分。据此,本文采用CFA方法对相似度进行改进,将Jaccard系数阈值设置为0.8以及连接强度阈值都为0.6,如果计算出的连接强度或者Jaccard系数低于这个阈值,直接省去从用户-方案规则库中匹配的过程;如果满足这个阈值范围,则计算新相似度并用TOP-N算法排序,找出相似性最大的用户所对应的方案集并推荐,如图10所示。

图10 新用户-特征集Fig.10 New user-feature set
以新用户C1特征匹配过程为例,将新用户C1与规则库中的用户的非功能性特征匹配,采用式(7)~(11)计算,得出 J=11/18,虽然满足给定的阈值0.6,但是,J不满足给定值0.8,所以,省略此匹配用户,与其他用户特征重新匹配。将都符合给定的阈值,则继续计算所以,同理,根据特征计算其他用户与新用户C1的相似度,如等,并排序。由此得出与新用户C1的相似性最大,从而将经过筛选后的方案推荐给C1,的非功能性特征,包含汽车变速箱自动、耗油多、安全高、价位在20~30万左右。据此,其所对应的方案Sn,汽车功能必须是越障能力高、轮胎防抱死性能好、汽车噪音中等、能保护头颈,如SUV类型的车可以推荐给用户。由此可见,本文的算法可以满足潜在的或者不熟悉产品功能特征的但又想获取性价比高的方案的用户需求,既能帮助企业提高收益,又能提高方案推荐效率。
4.2 算法性能的对比分析
针对协同过滤算法的缺点,考虑数据稀疏性、冷启动及用户偏好不一致这3个问题,采取基于加权二部图的个性化推荐方法来解决。加权二部图方法是通过计算用户-方案相似度,形成用户-方案规则库。推荐方案分为采用和未采用两种形式,采用方案分为规则库推荐和未推荐,分别用tp和fp表示;未采用方案分为规则库推荐和未推荐,分别用tn和fn表示。 为了证明该算法的优越性,本文提出采用F-Score评价体系[13],衡量该算法与传统协同过滤预测目标的性能,主要包含准确率P,召回率R以及F-Score评价体系,具体定义为

准确率和召回率是用于衡量该算法构建规则库的覆盖率以及推荐精度,而F-Score是衡量这两者间的综合指标。本文以对某汽车4S店的方案的问卷调查数据为例,根据传统协同过滤算法、已有的加权二部图算法以及本文算法对Top-N中的前100,200,300,400,500项方案,分别计算评估体系的参数的总体平均值,结果如图11所示。
由图11可知,本文算法相比较协同过滤算法、加权二部图算法而言,优越性很大。如在前300项的数据下,传统CFA的综合F-Score评价指标为0.47,加权二部图的F-Score评价指标为0.60,而本文算法F-Score评价指标为0.783,明显高于其他2个算法。在方案数较少的情况下,CFA和加权二部图的F-Score评价指标值不相上下,直到方案数在200之后,综合指标的差距才开始拉大,并且加权二部图推荐性能明显优于CFA。从图11中可知,随着方案数的增加,相比较CFA、加权二部图的推荐效果,本文算法的推荐精度性能优势越明显,说明在推荐目标方案方面,本文算法更加有效,进一步证明本文算法能够更好地预测新用户的目标方案。

图11 不同算法F-Score比较结果Fig. 11 F-Score comparison results of different algorithms
5 结束语
针对协同过滤算法执行过程中存在数据稀疏性、用户兴趣各异以及冷启动问题,提出基于加权二部图的个性化推荐算法予以解决,提高了推荐效率。本文算法的优点如下:
a. 采用二部图方法计算用户特征的相似度,将相似度高的用户聚类,形成一对多的用户方案集,节约了数据库存储空间,减轻了数据稀疏性。
b. 针对聚类后的用户方案集,根据用户对方案特征的评分,采用加权二部图计算方案评分值,并用TOP-N排序,保留前N项方案,解决了用户兴趣各异的情况,为新用户推荐不同的方案。
c. 对于零购买记录的新用户,本文采用改进相似度,即将皮尔森系数、Jaccard系数以及连接强度相结合,如对Jaccard系数以及连接强度设定阈值,相似度不满足该阈值,直接省略推荐过程,反之,将与新用户相似性高的用户方案予以推荐。该方法解决了以往推荐算法的冷启动问题,提高了算法执行时间以及推荐效率。
以上是本文算法的优点,但对于小型数据库而言,方案相似度TOP-N排序方法效果不很明显。此外,本文算法在实例分析中,也只是展示方案了解和实施过程,即将用户-方案库中的方案推荐给新用户,并未针对用户某些特殊需求,定制特殊方案,这也是本文下一步想拓展的研究方向。
猜你喜欢
好日子(2022年3期)2022-06-01
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
临床骨科杂志(2020年1期)2020-12-12
制造技术与机床(2019年9期)2019-09-10
陕西画报(2018年6期)2018-02-25
探测与控制学报(2015年4期)2015-12-15
科技视界(2014年25期)2014-04-27
数码精品世界(2009年3期)2009-03-30
建筑创作(2001年3期)2001-08-22
