
基于多任务双向长短时记忆网络的隐式句间关系分析
2019-06-03 10:52田文洪高印权黄厚文黎在万张朝阳
中文信息学报 2019年5期
田文洪,高印权,黄厚文,黎在万,张朝阳
(电子科技大学 信息与软件工程学院,四川 成都 610054)
0 引言
句子是自然语言处理中除字、词、短语外另一个重要的研究层级。篇章句间关系识别(discourse relation recognition)是句子层级研究中不可或缺的环节。篇章句间关系识别的主要任务是,研究一段文本中前后相连的两个论元之间的逻辑关系(例如,比较关系、拓展关系、并列关系和因果关系等)。该任务是自然语言理解的基础研究问题。正确地判断文本句间逻辑关系意味着能够有效地理解文本的语义关系。因此,该任务能够有效地提升对话系统、自动问答等系统的性能,对多种自然语言处理任务的解决起到辅助作用。
篇章句间关系识别可以根据是否存在逻辑连接词分为两类: 存在逻辑连接词(例如,所以、然而等)的显式句间关系识别(explicit discourse relation recognition);不存在逻辑连接词的隐式句间关系识别(implicit discourse relation recognition)。如例1所示,该句中存在表示因果关系的连接词“因为”“所以”,因此,该句子的篇章关系为显式句间关系。例2中的句子虽然没有逻辑连接词,但是可以根据前后两句的内容推测出前一个分句是后一个分句的原因。因此,该例句的篇章句间关系是因果关系。形如例2的句子称为隐式句间关系语句。连接词的存在与否是判断篇章关系类型的重要依据。
例1因为今天下雨,所以道路湿了。
例2今天下雨,道路湿了。
本文所研究的内容主要针对隐式篇章句间关系的识别,使用的语料为张牧宇等[1]在2013年发布的哈工大社会计算与信息检索研究中心中文篇章级语义关系语料库(HIT-CIR Chinese Discourse Relation Corpus),在张牧宇等的另一文献[2]中对该语料库做了详细叙述。该语料有选取了多个领域的中文语句,标记有525篇、共计六个大分类的篇章句间关系。
基于该语料库,本文提出了一种基于双向长短时记忆(Bi-LSTM)网络的多任务学习架构,并采用融合词向量的方法解决隐式篇章句间关系识别任务。本文方案中的多任务学习架构能够充分使用到隐式句间关系和显式句间关系的语料,间接地扩充训练集样本数量。不仅如此,多任务学习的底层权重共享机制可以充分挖掘隐式句间关系分类和显式句间关系分类之间的关联,增强底层网络的特征提取能力。同时,方案中的融合词嵌入的方法能够充分挖掘文本自身的信息。经过验证,本文方法取得较好的识别性能,对比张牧宇等[1]中的最好方法有着非常明显的性能提升,平均F1值提升约13%,个别类别的F1值提升近一倍,平均召回率(Recall)提升9%。
1 隐式句间关系识别的研究现状
隐式句间关系识别的难点在于该任务的语料不存在类似于显式的篇章句间关系中的连接词,缺乏较好的特征。同时,数据集的稀少和样本的分布不均衡也是隐式句间关系识别无法得到很好解决的原因之一。解决该问题可以从多种角度出发。首先,根据语句中词汇之间的依赖关系、句法关系以及浅层语义等关系进行分析判断。徐凡等[3]将句子的句法特征、浅层语义特征、情感分析特征和词汇特征整合到一起,使用树核的方法进行分类,取得较好效果。再者,基于机器学习的判断方法也在该问题上有着广泛的实践。王智强等[4]使用篇章框架的方法来解决该问题。机器学习的方法例如SVM(support vector machine)[5]、最大熵[1]等方法被应用到该问题的解决中,SVM由于其对边界实例的敏感性,效果较最大熵要更好[1]。聚类的方法也被用到该问题的解决中[6]。目前,基于深度学习的方法被广泛地应用到自然语言处理问题的解决中。该类方法相较于传统的方法能够大幅度减少特征工程的工作量,在节省人工的同时,也能取得较好的效果。Liu Y等[7]使用了CNN(convolution neural network)对句子进行特征提取,然后通过多任务学习网络联合显式句间关系语料和隐式句间关系语料解决该问题。同时,循环神经网络(recurrent neutral network,RNN)以及注意力模型(attention model)也被应用到该任务的解决中[8],该方法在训练模型时,同时将整个句子以及句子的前后两个子句加入到模型的训练之中,取得较好的泛化能力。当然,针对语料特征的解决方法也被应用到解决该问题中,由于样本的不均衡,隐式句间关系识别的样本较少的类别很难得到较好的结果。朱珊珊等[9]根据隐式篇章关系数据这一特点设计了基于框架语义向量的训练样本拓展的方法,该方法比主流的欠采样方法得到更好的结果。
2 方法
2.1 总体识别方案
本文将双向长短时记忆神经网络、融合词嵌入和多任务模型结构进行融合,设计了基于多任务学习循环神经网络的隐式句间关系识别模型,模型网络结构如图1所示。
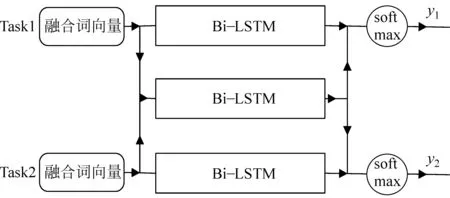
图1 整体网络结构图
其中,task1为主任务,识别隐式句间关系;task2为辅助任务,识别显式句间关系。模型共有三个Bi-LSTM,上方Bi-LSTM和下方Bi-LSTM网络分别是task1和task2独享的网络,用于提取各自任务独有的特征。中间的Bi-LSTM用于提取任务task1和task2通用的特征。最后将结果输出到softmax层中,计算最终的损失值。
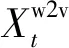
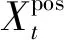
(1)
按照该顺序将task1和task2的输入词向量输入到任务独享的Bi-LSTM中提取任务独有的特征,同时输入到共享的Bi-LSTM中提取任务通用的特征,如式(2)~(4)所示。
最后,将每个Bi-LSTM的最后一个时间步的隐藏层单元状态作为输出。task1和task2分别将任务独享的Bi-LSTM输出和共享的Bi-LSTM的输出连接到一起,输出到softmax层中,得到最终的预测值,如式(5)、式(6)所示。
task1和task2均使用交叉熵(cross entropy)作为损失函数,设置task1和task2的损失权重为α1和α2,如式(7)所示,其中ytrue和ypred分别表示真实值和预测值。
(7)
该网络结构设计旨在使用共享结构进行训练,学习到两种任务所共同具有的特征,针对具体任务的网络训练学习到具体的任务的特征。
2.2 双向长短时记忆神经网络
循环神经网络(recurrent neutral network,RNN)[10]是一种具有循环结构的网络,能够针对时间序列进行建模,有效地捕捉时间序列上的信息传递特征。它与自然语言文本中词汇的前后顺序关系非常地契合。因此,在很多自然语言处理任务中,循环神经网络都能取得不错的效果。但是,循环神经网络中的梯度消失和梯度爆炸问题是影响其效果的因素之一。
长短时记忆网络[10](long short term memory,LSTM)引入记忆块的概念,通过门(gate)控制信息的输入、遗忘以及输出,用以保持和更新细胞状态,从而有效地减轻梯度消失和梯度爆炸问题。LSTM的结构如图2所示。
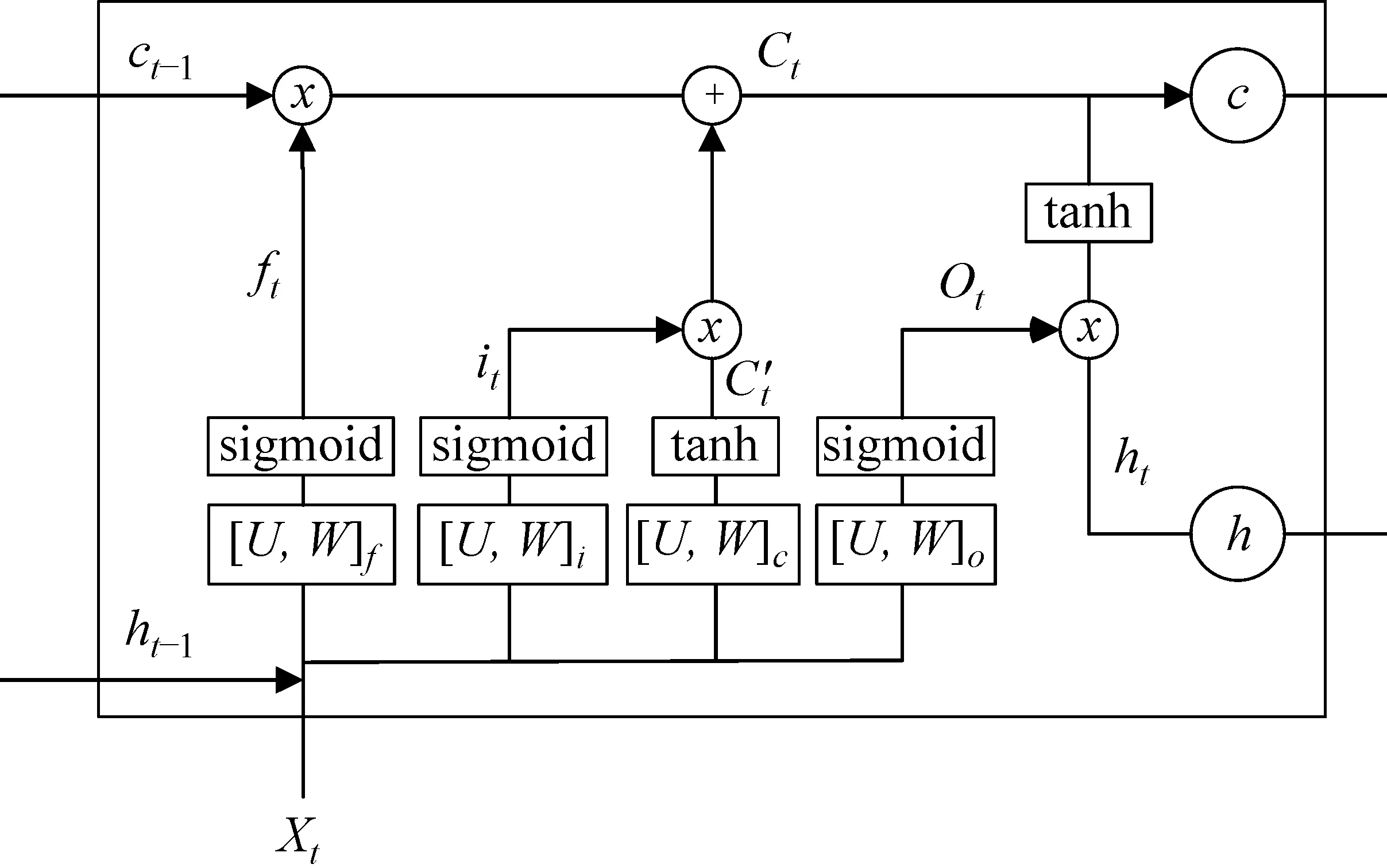
图2 LSTM结构图
LSTM中门的概念实际上是一个全连接层,它的输入是上一时刻的隐藏层单元状态,输出是对应到细胞状态(cell state)的每一个单元的信息乘数因子。该乘数因子的大小控制着信息的输入、遗忘和输出百分比。门的结构如式(8)所示。
gate(x)=σ(Wx+b)
(8)
其中,σ为sigmoid函数,输出0到1之间的实数向量;W和b分别为门的权重与偏置。
LSTM设计了三个门函数: 输入门(input gate)、遗忘门(forget gate)和输出门(output gate)。这三个门的计算公式均可由式(8)给出。
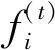
(9)
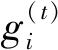
(10)
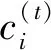
(11)
(12)
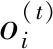
(13)
(14)
LSTM网络由于其出色的性能被广泛地应用到自然语言处理任务中,其细胞状态结构能够根据上一时刻的细胞状态和当前时刻的输入更新细胞状态,学习到文本序列中较长的短时记忆。
双向循环神经网络(Bi-RNN)[12]是Schuster等在RNN的基础上做的改进,它的思想是不仅考虑顺序的时间步骤的信息传递过程,同时考虑逆序时间步骤上的信息传递。通过这种方式捕捉到更多的时间顺序上的特征。其结构如图3所示。
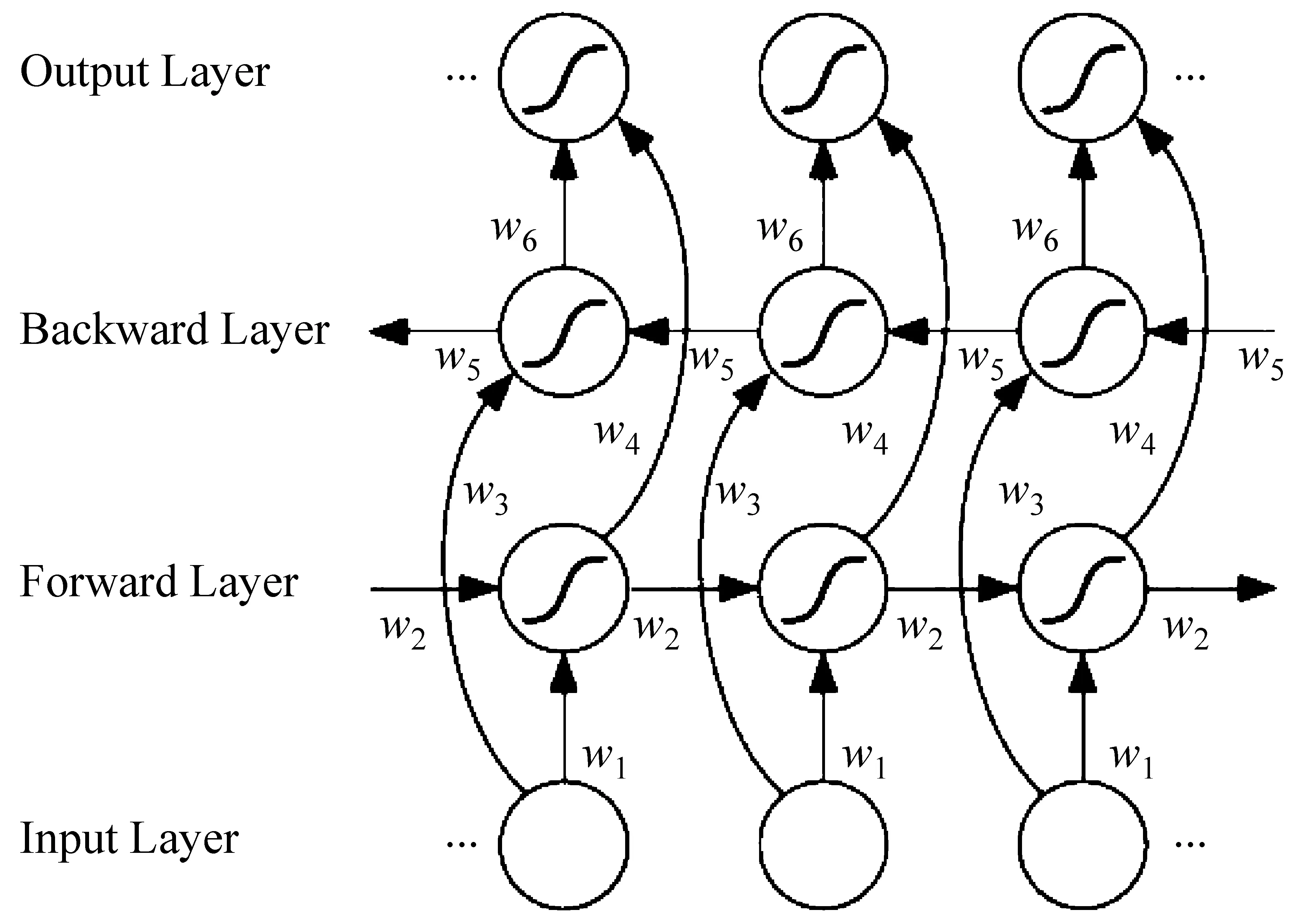
图3 Bi-RNN结构图[10]
双向长短时记忆网络[10](bidirectional long short term memory,Bi-LSTM)是Bi-RNN和LSTM的结合,专门用来处理长期依赖缺失的问题。前向网络按照顺序读取每一时刻的输入,计算权重;后向网络按照逆序读取输入并计算权重。然后,将前向和后向的输出融合到一起作为Bi-LSTM的输出。该模型不但考虑了顺序的特征,而且考虑了逆序的特征,在很多自然语言处理任务中,Bi-LSTM比LSTM的效果更好。
2.3 融合词嵌入
词嵌入(word embedding)是一种词的表示方法,它使用一组低维、稠密、实值的向量表示文本中的每一个词。在深度学习处理过程中,通常将这组词嵌入方法所表示的词向量作为模型的输入。当然,词嵌入所训练的方式不同,它能够表示出不同的意义。NNLM(neural network language model)[13]是Bengio等在2003提出的训练方法,该方法训练出的词向量表示的是该句子从语言模型角度出发的整体出现概率。Word2Vec[14]是Mikolov等在2013年提出的无监督词嵌入训练方法。该方法训练出的词向量可以表示词汇在浅层语义上的距离(king-queen=man-woman)。神经网络词向量Word2Vec的训练思想有两种[15],分别代表两种训练方式: 第一种是通过中间的词预测周围的词,也就是skip-gram方法;第二种是通过周围的词去预测中间的词,也就是CBOW模型。当然,该模型也用到负采样(Negative Sampling)、Hierarchical softmax等方法加速训练。
为了充分利用文本的信息,扩充词向量的表示能力,本文选择的方法是使用skip-gram的Word2Vec训练出的100维词向量和词性向量,将其进行拼接,作为模型的输入。这种方法相当于从特征工程的角度丰富词向量所表示内容,让词向量不仅从Word2Vec这一部分中表达词的语义关系,也能通过拼接词性向量表示其他相关信息。句子的词性序列在一定程度上反映了句子的句法上的信息。融合词向量的过程为: 首先,将41种词性生成词嵌入表示形式;再通过观察词汇在具体语句中的词性,将词性对应的词向量与Word2Vec词向量拼接到一起。综上,本文所使用的模型输入包括两个部分: Word2Vec词向量部分和词性向量部分;最后,将这两部分拼接在一起,作为表示具体词汇的融合词向量。
2.4 多任务学习
多任务学习是针对传统的单任务学习提出的一种学习概念。单任务学习是一次只学习一个任务,生成的模型只针对单个学习任务。张牧宇等[1]使用的SVM或最大熵模型均是针对隐式句间关系或显式句间关系的单任务学习方法。多任务学习是多个任务同时进行学习,旨在利用任务之间的关联性,通过共同训练的方式提升模型的性能。多任务学习深度神经网络在进行训练时,多个任务的网络同时进行损失函数的误差反向传播。这些任务通过共享底层的特征表示层来相互促进学习,从而提升模型的性能和泛化能力。同时,多任务学习可以间接地扩大训练的语料,对语料较少的任务提供一种可行的解决方案。
多任务学习在文本分类任务上有着深入的研究。Liu P等[16]设计了多种基于循环神经网络的多任务学习结构,并将该结构应用到文本分类之中。该结构中共享部分Bi-LSTM的隐藏层,能够向用于具体任务的Bi-LSTM传递信息,起到底层网络共享特征的作用。Liu P等[17]将对抗网络的思想加入到多任务学习文本分类的训练之中,使得共享层的网络能够更加纯粹地学习到共享的特征,有效地提升了分类的性能;Liu Y等[7]使用了CNN(convolution neural network)作为底层的共享表示层,并使用动态池化层(dynamic pooling)选取重要特征。本文所使用的多任务学习结构深受这些新方法的启发。
自然语言处理中很多问题的子问题是具有相关性的。例如中文分词和命名实体识别,Qi Y等[18]使用多任务学习方法提升命名实体识别的准确率。Liu Y等[7]使用多任务学习来处理隐式句间关系,他们使用卷积神经网络作为底层的共享层,上层的网络使用不同的分支结构计算不同任务的损失。之所以可以使用多任务学习进行隐式句间关系分类,是因为隐式句间关系和显式句间关系也存在这种任务之间的关联。从前文中提到的例1和例2可以看出这两个任务之间的联系。如果例1去掉连接词后在内容上和例2一致,可以判断出句子间存在因果关系。反过来例2加上合适的连接词“因为”“所以”,在内容上和例1一致。因此,某些隐式句间关系的句子可添加上合适的连接词,转化为相应的显式句间关系的实例;反过来,可将部分显式句间关系的句子转化为隐式句间关系的实例。可以看出,两种任务的语料除连接词外,文本内容存在着相似性,利用这种联系可以将这两个任务放在多任务学习框架下共同训练。本文将隐式句间关系识别设置为主任务,显式句间关系识别设置为辅助任务。多任务学习过程中,两种任务同时对底层的共享表示层网络进行梯度下降,学习通用特征;而较为上层的网络学习特定任务的特征。该方法能够有效地提高模型性能及泛化能力,在一定程度上扩充了数据集规模。
3 实验
3.1 实验环境及数据介绍
本文所使用硬件环境为: 处理器AMD Ryzen 1700k CPU;显示接口卡Nvidia GeForce GTX 1060 6 GB;内存8 GB。软件环境为: Python 3.5,jieba3k 0.35.1,Tensorflow-gpu 1.4.0,Keras 2.1.5,Gensim 2.3.0。
实验使用的数据是张牧宇等[1]在2013年提出的HIT-CDTB语料。该语料标记了525篇语料,将这些语料中的句子按照句间关系类型分为两类: 显式句间关系和隐式句间关系。按照句子的类型分为三个类别: 分句句间关系、复句句间关系和句群句间关系。按照句子的篇章句间关系分为六个大类: 时序关系、因果关系、条件关系、比较关系、拓展关系和并列关系。同时,这六个大类又细分为55个小的分类。具体的语料细节可以参见文献[2]。由于这六个类比中的时序关系和条件关系的语料过少,因此舍弃这两种,只选用剩下的四个类别的语料进行分类的训练和测试。
本实验选取的是分句句间关系和复句句间关系中只包含因果关系、对比关系、拓展关系和并列关系的语料,隐式和显示关系总数分别为14 987条和13 130条。具体语料数量如表1所示。
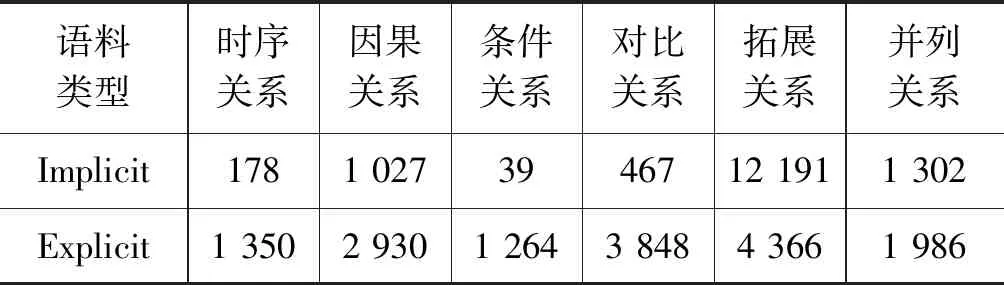
表1 语料统计表
在隐式句间关系的性能评估中,本文采用的是常用的R(召回率)、P(准确率)和F1(召回率和精确率的调和平均值),以F1值作为评测的主要参考指标。
3.2 实验设计
本文设计了三个实验。
实验一为了验证多任务学习相比传统机器学习的优越性,在实验数据相同的情况下,设计了包括文献[1]中性能较好的SVM方法及文献[5]中SVM方法的对比实验,得到了测试数据中的P、R、F1值,如表2所示。
实验二为了验证多任务学习在数据集较少的情况下优于现有的深度学习方法,在实验数据相同的情况下,设计了包括文献[8]文中在CDTB数据集上性能较好的A Recurrent Neural Model with Attention(RNN-Att)方法的对比实验,得到了测试数据中的P、R、F1值,如表3所示。
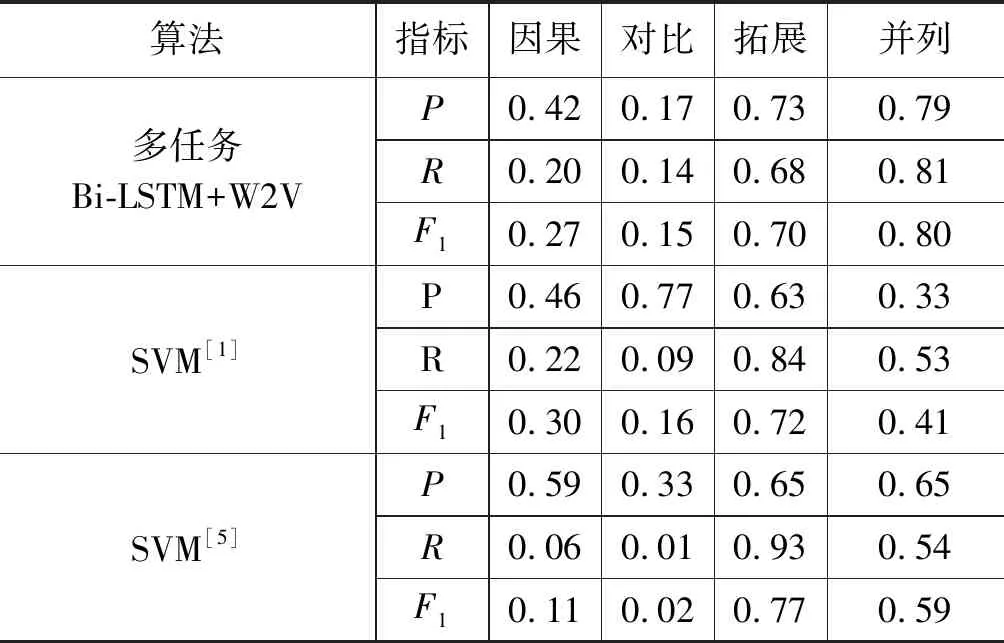
表2 隐式句间关系识别结果
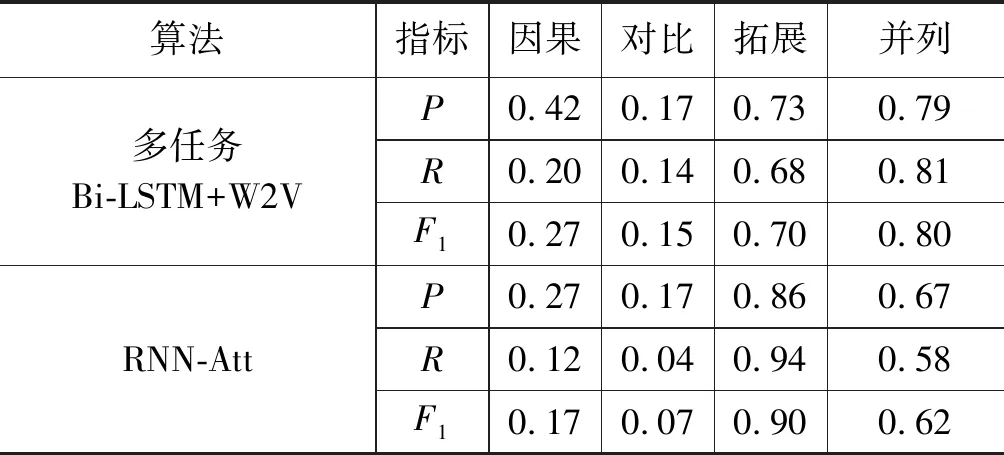
表3 与RNN-Att模型对比实验
实验三为了验证词性向量的有效性,设计了添加词性向量与不添加词性向量的对比实验。在保证实验其他参数相同的条件下,得到了在测试数据集中的P、R、F1值,如表4所示。
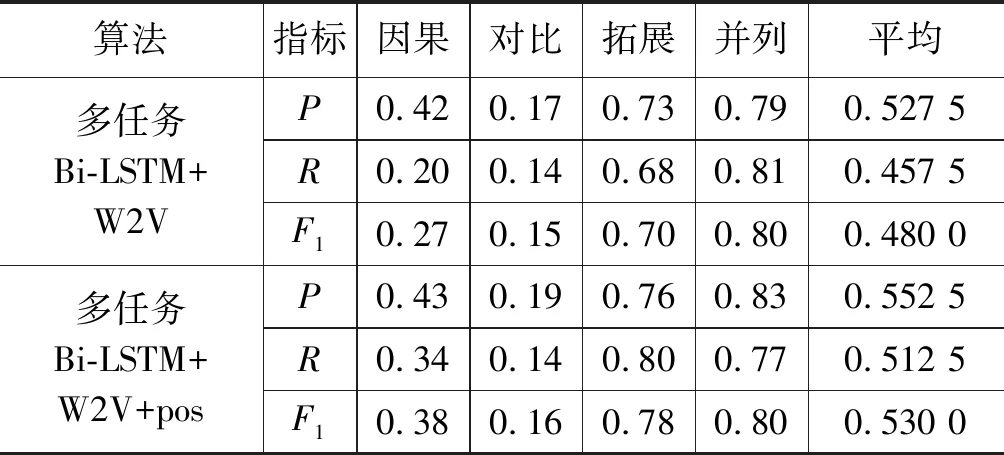
表4 词性向量对比实验
3.3 实验参数设置
实验使用3.1节中提到的约28 117万条语料作为实验数据。随机选取80%的数据作为训练集,余下作为测试集。
首先,使用jieba分词工具对数据进行分词和词性标注;其次,使用Gensim工具包下的Word2Vec模块将样本集中所有的句子训练生成100维词向量,同时也对词性做embedding处理,生成32维向量,两者进行拼接,生成132维向量作为模型输入;然后,使用Keras完成多任务学习Bi-LSTM代码的编写;最后,由于数据存在类别不均衡的问题,测试每个类别的二分类时,均调整提升较少类别的采样权重,使用过采样的方式减轻数据不均衡造成的影响。同时,两个任务均使用交叉熵作为损失函数,经过多次测试,得到最优超参数设置: 学习率设置为0.000 5;隐式句间关系任务损失权重设置为0.65;显式句间关系任务损失权重设置为0.35。
3.4 实验结果与分析
实验结果表明,使用融合词向量作为输入的多任务循环神经网络模型的实验结果在准确率、召回率以及F1值指标上均取得很好结果,其中大部分指标取得目前该语料测试上的最好结果。与张牧宇等[1]的论文中的最好结果对比: 平均F1值提升约0.13,召回率(Recall)平均提升0.09,准确率(Precision)在拓展、并列关系上平均提升0.28,其余两类虽有所下降,是由于这两个类别的样本较少。同时,并列关系的F1值提升近一倍,模型很好地学习到并列关系的相关特征。与姬建辉等[5]的方法对比:F1值有明显提升。文本所使用的方法能够有效地学习到隐式句间关系的相关特征,达到较好的性能。但是,从表中仍然可以看出因果关系、对比关系的训练结果较差,这种情况的出现是因为这两个类别的样本较少,分别是1 027条和467条。在样本较少的任务上,深度学习方法很难获取很好的效果,而基于概率或者规则的方法往往能取得更好的结果。与Samuel Rönnqvist等[8]文中方法对比:P、R、F1在因果、对比、并列三类关系上有明显提升,在扩展关系上有所下降。这说明多任务学习在数据集不够充足的情况下表现较好,因为可以通过辅助任务来弥补数据集不足的缺点,但是在数据集足够的情况下不一定可以取得最好的效果。
3.5 模型简化测试
本文进行模型简化测试,以定量评估本文模型词性特征的贡献度。本文将引入融合词向量与仅使用单一的Word2Vec词向量此两种方案进行实验对比。实验表明: 使用融合词向量后,效果有一定提升,多任务Bi-LSTM+W2V+pos方法的F1平均值为0.53,而多任务Bi-LSTM+W2V方法的F1平均值为0.48;因此,前者比后者F1平均值提升0.05;同理可计算出召回率R平均提升0.055,准确率P平均提升0.025。
4 总结与展望
本文提出了基于多任务学习的循环神经网络和融合词向量进行隐式句间关系识别的方法。由于隐式句间关系识别和显式句间关系识别在一定程度上有内在的联系,因此,使用多任务学习的方法,用显式句间关系的语料和隐式句间关系的语料共同训练,学习两种任务之间共同的特征,从而提升模型的泛化能力。同时,使用了融合词向量的方法,在Word2Vec的基础上加入词性的先验知识,也在一定程度上提升模型的性能。本文使用的方法比目前已有结果有一定的提升。在今后的研究中,可以尝试针对隐式句间关系语句的前后两个分句的结构设计更精细的模型来获取语句的特征,从而提升模型的识别效果。同时,吸收传统的特征工程的一些可用的经验,包括将先验知识应用到深度学习的模型中等方法,该类处理方式不但能够提升模型的性能,也能提高深度模型的可解释性。
猜你喜欢
应用心理学(2022年5期)2022-11-05
新高考·高一数学(2022年3期)2022-04-28
北京大学学报(自然科学版)(2022年1期)2022-02-21
通信技术(2021年12期)2022-01-25
现代信息科技(2021年21期)2021-05-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机应用与软件(2018年9期)2018-09-26
中国新技术新产品(2016年23期)2016-12-26
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
