
采用拼音降维的中文对话模型
2019-06-03 10:53:00吴邦誉赵群飞张朋柱
中文信息学报 2019年5期
吴邦誉, 周 越, 赵群飞, 张朋柱
(1. 上海交通大学 自动化系 系统控制与信息处理教育部重点实验室,上海 200240;2. 上海交通大学 安泰经济与管理学院 管理信息系统系,上海 200240)
0 引言
对话是自然语言处理问题中的一项重要工作,它包括意图理解、知识推理和问题回答等多个方面的技术。
传统的对话模型主要可以分为以下两种方法:基于规则的方法[1]和基于统计机器学习的方法[2-4]。基于规则的方法通过人为制定多种语法规则,以匹配的方法来选择候选答案,但该方法存在规则难以制定和匹配答案固定单一的问题。基于统计机器学习的方法则是通过特定的学习算法和少量的数据对模型进行训练,该方法同样难以实现一个可扩展的对话系统。
深度神经网络近年来在自然语言处理领域取得了巨大成功。如Socher[5]将深度神经网络用于释意检测方向,Hinton[6]将深度神经网络用于语音识别方向,均取得了很好的效果。编码—解码模型首先由Sutskever[7]提出,应用于神经机器翻译领域。该模型由一个编码器网络和一个解码器网络构成。编码器网络接收输入序列并将其编码为固定长度的中间语义向量,解码器网络对固定长度的中间语义向量进行解码得到输出序列。这种编码—解码结构很好地解决了模型的输入和输出都为不定长序列的问题。由于编码—解码模型在神经机器翻译上的成功,Vinyals[8]在2015年将该模型用于自然语言对话领域。同年,Shang等[9]将编码—解码模型应用于单轮短文本对话,Sordoni[10]采用编码—解码模型结合上下文信息提出一种上下文敏感的对话生成模型。在此基础上,Bahdanau[11]提出了注意力机制,使得输出序列可以更好地与输入序列对应起来,提升了编码—解码模型结构的效果。
编码—解码模型虽然取得了不错的对话效果,但仍存在字词表规模受限的问题。为了控制模型的时空开销,模型在编码器网络的输入端和解码器网络的输出端都要限制词语表的规模。对于词语表之外的词语,如果用特殊字符UNK代替,将导致句子信息的缺失。这一问题对词语规模较大的语言(如汉语、德语等)将产生较大影响。Jean[12]提出一种基于重要性采样的方法,以保证在使用大规模词语表示时模型训练复杂度不显著增加。Ling[13]以字符作为编码器网络的输入,以此减少字词表规模。
本文利用汉字可用汉语拼音表述这一特点,将汉字输入转换为拼音输入,并将拼音分解为声母、韵母和声调三个部分作为编码器的输入,以此减少输入的字词规模。然后通过全卷积神经网络和双向LSTM网络提取拼音特征,通过该方法提取的拼音特征可以被精确地还原为输入汉字。最后采用4层GRU网络对拼音特征进行解码,得到输出序列。同时在解码阶段加入了注意力机制,使模型的输出可以更好的与输入对应起来,提升对话效果。
1 拼音特征提取
目前汉字总数已经超过了8万,如果将汉字作为对话模型的输入,模型的时空开销将会很大。本文针对汉字可用汉语拼音表述这一特点,将汉字输入转换为拼音输入,并将拼音拆分为声母、韵母和声调三个部分输入对话模型。在保证拥有完整信息的情况下减少了模型的输入维数,降低模型的时空开销,如图1所示。

图1 汉字拼音输入对比
1.1 拼音图构建
1.1.1 多音字处理
为了降低模型的输入维数,先将汉字输入转换为拼音输入。汉字转化为拼音时存在大量多音字干扰,故将汉字输入转化为拼音输入时并不是对逐个汉字进行转化,而是对整个句子进行转化。这样多音字在转化为拼音时不仅结合了自身信息,同时也结合了前后文的信息,可以被有效地转化为正确的拼音。例如,“他的头部受到重创”,对于多音字“重”,其拼音表示可以有“zhong4”和“chong2”两种选择,通过结合前后文信息可以得知“zhong4”是此处多音字“重”的正确拼音转换。多音字处理示例如图2所示。
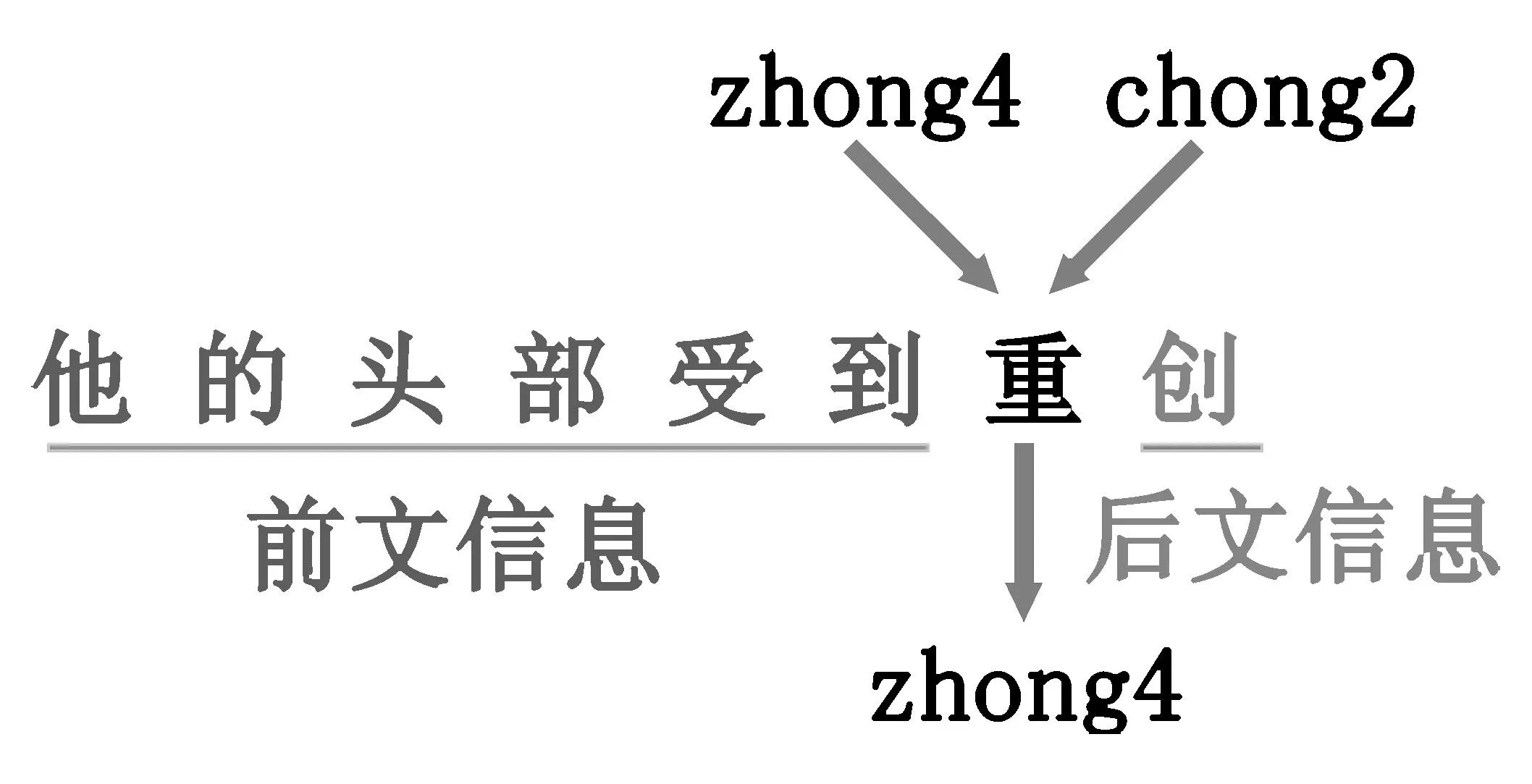
图2 多音字处理示例
汉字输入转换为拼音输入之后,将拼音拆分为声母、韵母和声调三个部分。这样,模型的输入维数将由原来的汉字个数降低到63,包括24个声母部分、34个韵母部分和5个声调部分。拼音表如表1所示。
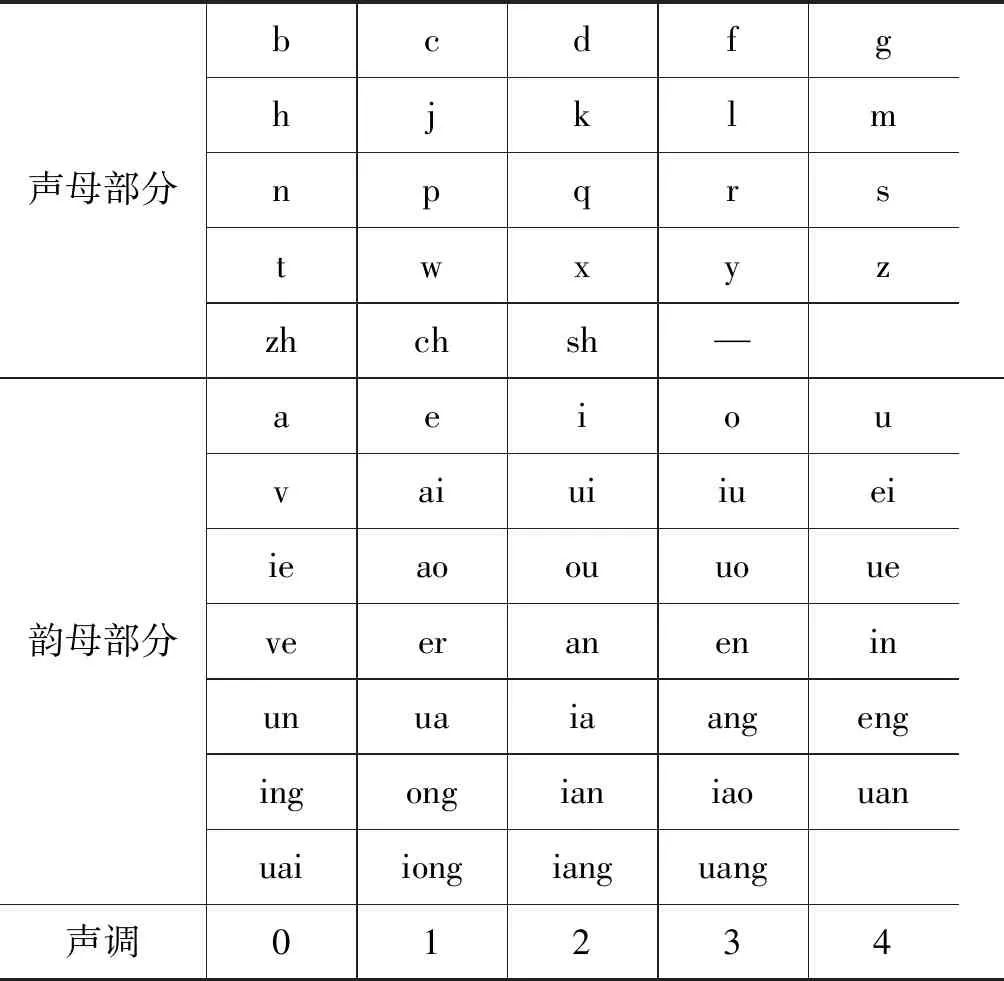
表1 拼音表
注: “—”表示声母部分为空(如“啊”、“哦”)的情况。
1.1.2 拼音向量生成
为了将拼音信息作为网络模型的输入,需要用数值表示拼音的各个部分(声母、韵母和声调),并将输入的拼音信息映射为一张拼音图。最简单的方法就是对拼音表中的每一个声母、韵母和声调都赋予一个值进行表征,即one-hot编码方式。但该编码方式使声母、韵母和声调之间相互独立,无法体现各部分拼音之间的联系。于是本文将拼音表中的每一个声母、韵母和声调都表示为一个随机生成的可训练的64维稠密向量,即embedding编码方式。这样对于长度为n的中文词汇 c=[c1,c2,…,cn] 可以采用拼音向量进行表示,如式(1)所示。
(1)
其中,c_pinyin∈3×64为中文词汇的拼音向量表示,ci∈3×64表示第i个字的拼音表示, xi∈64为声母部分向量, yi∈64为韵母部分向量, zi∈64为声调部分向量。
拼音向量在经过训练之后,相近中文词汇的拼音向量表示在空间上的距离较小,而无关中文词汇的拼音向量表示在空间上的距离很大,可以表现出词汇之间的联系。
通过上述步骤,可以构建出一个高度为3,宽度为输入序列长度,深度为64的拼音图。拼音图的构建流程如图3所示。
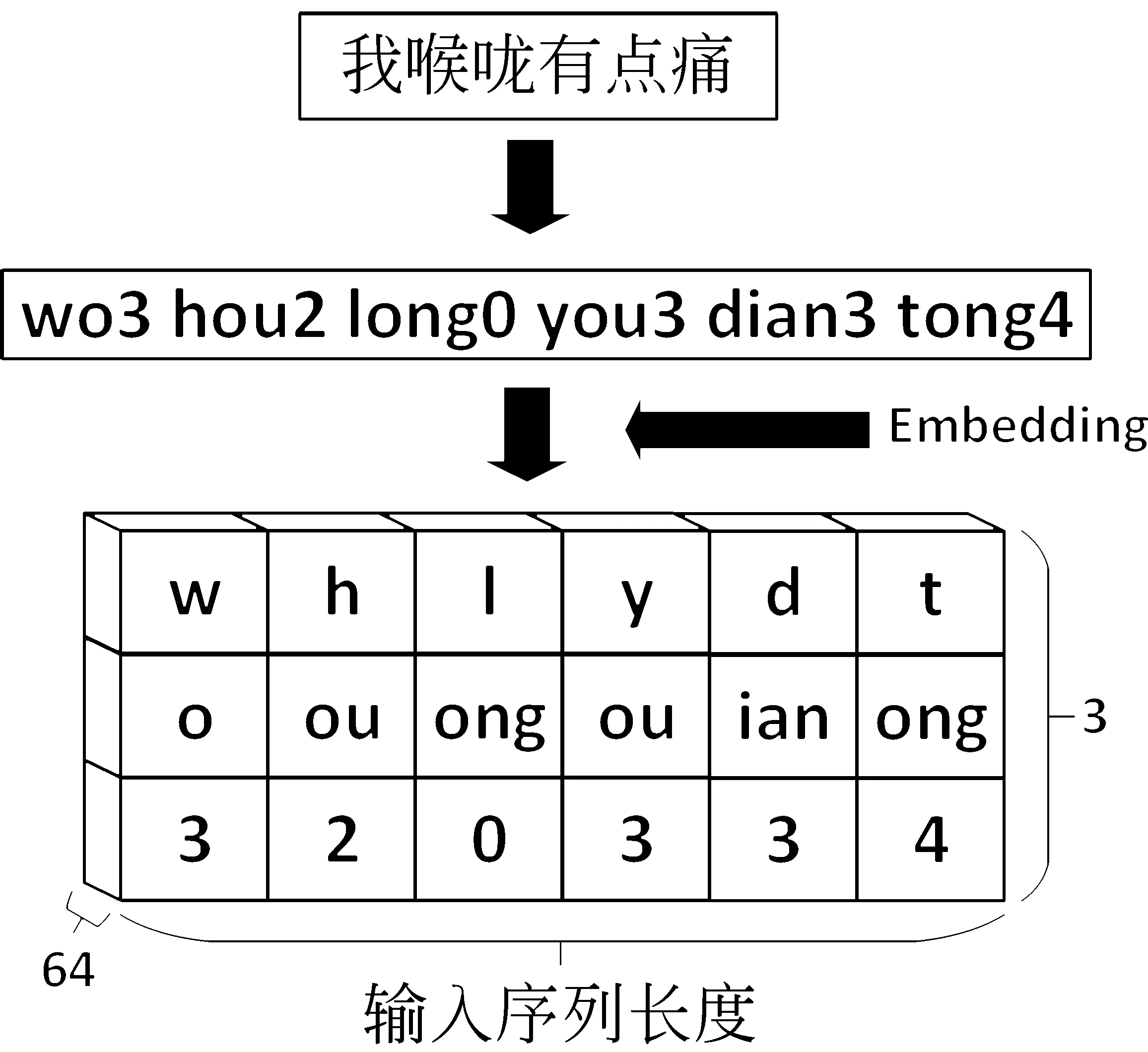
图3 拼音图构建流程
1.2 特征提取
1.2.1 FCN提取拼音特征
构建了拼音图之后,将拼音图作为模型输入,通过全卷积神经网络将声母、韵母和声调向量进行融合,从而提取单个字的拼音特征。全卷积神经网络共设计了3个卷积层,将拼音特征的维度由原来的64维转换到256维,最终得到长度为输入序列长度,维数为256的拼音特征序列。全卷积神经网络提取拼音特征的流程,如图4所示。
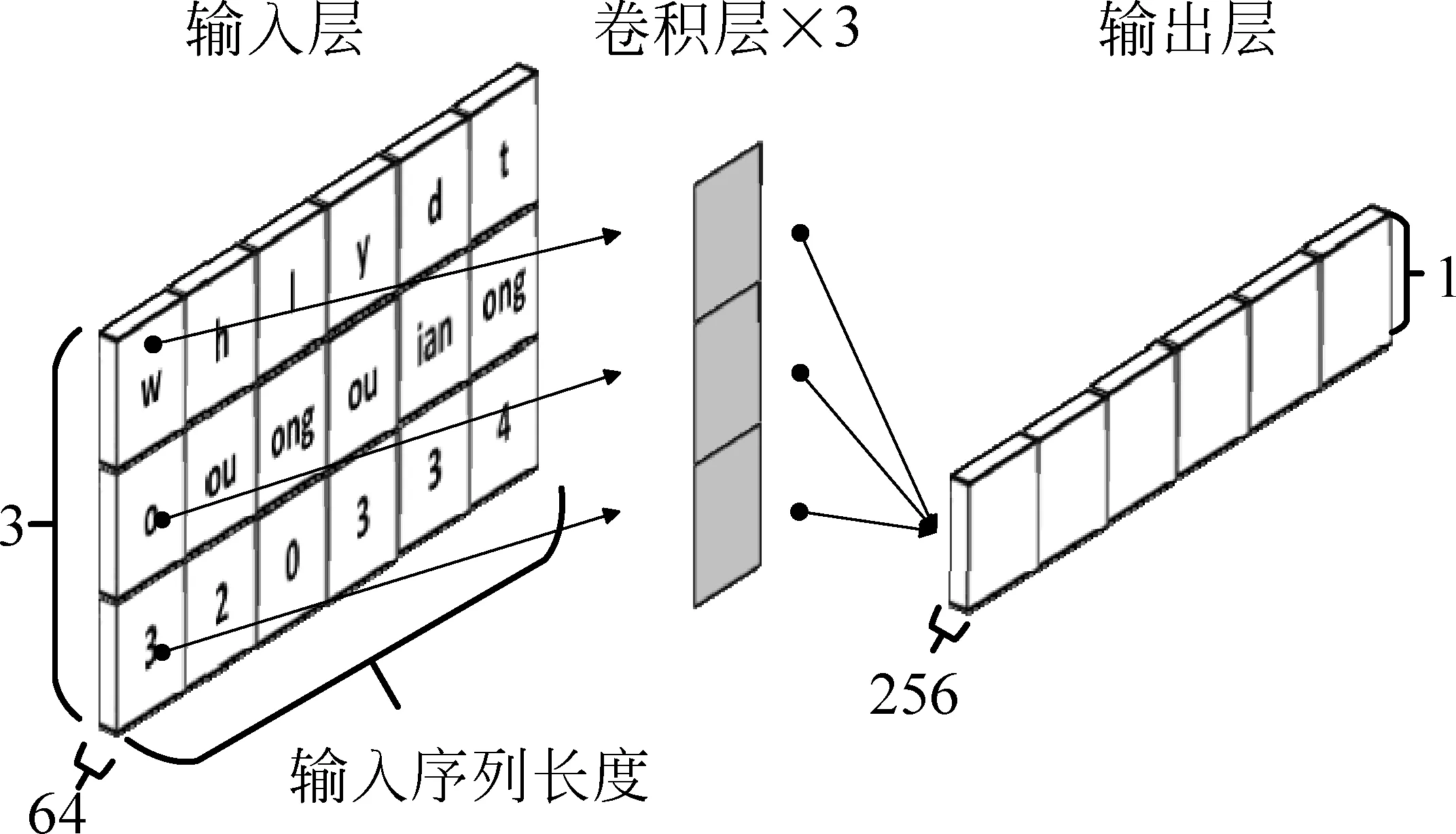
图4 卷积网络特征提取
令I∈3×time_step×64表示输入的拼音图,其中time_step为输入序列的长度。W∈3×k×64×256表示卷积窗口,k为卷积窗口的宽度。则全卷积网络的输出,如式(2)所示。
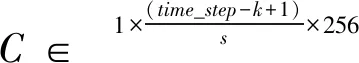
1.2.2 双向LSTM处理同音字
通过全卷积神经网络提取的是单个字的拼音特征,该网络无法对同音字的拼音特征进行区分。由于汉字中存在大量同音字,若只考虑单独的拼音信息而不结合前后文信息则会导致语义分析错误。例如,“生病需要休养”和“生病需要修养”这两句话在拼音表示上都是一样的。对于“xiu1”的两个同音字“休”和“修”,通过结合前后文信息可以知道“休”才是此处的正确表示。同音字处理示例如图5所示。

图5 同音字处理示例
因此,采用双向LSTM网络进一步提取拼音特征,该网络不仅提取当前拼音自身的信息,还提取当前拼音前后文的信息,得到结合了前后文信息的拼音特征。通过提取结合前后文信息的拼音特征可以有效地解决同音字带来的语义分析错误问题。双向LSTM提取拼音特征的流程如图6所示。
令 xt表示t时刻输入序列的值,At表示t时刻前向传播隐藏层节点的值,Bt表示t时刻后向传播隐藏层节点的值。则At、Bt的计算如式(3)、式(4)所示。
其中,t时刻网络的输出值yt取决于At和Bt,其计算过程,如式(5)所示。
最终的输出Y=[y1,y2,…,ytime_step] 是长度为输入序列长度,维数为256的拼音特征序列。
2 中文对话模型
2.1 模型框架
中文对话模型采用编码器—解码器网络框架。编码器网络接受拼音信息输入并将输入序列转化成一个固定长度的中间语义向量。解码器网络对生成的中间语义向量进行分析和解码并最终得到模型的输出序列。中文对话模型框架如图7所示。
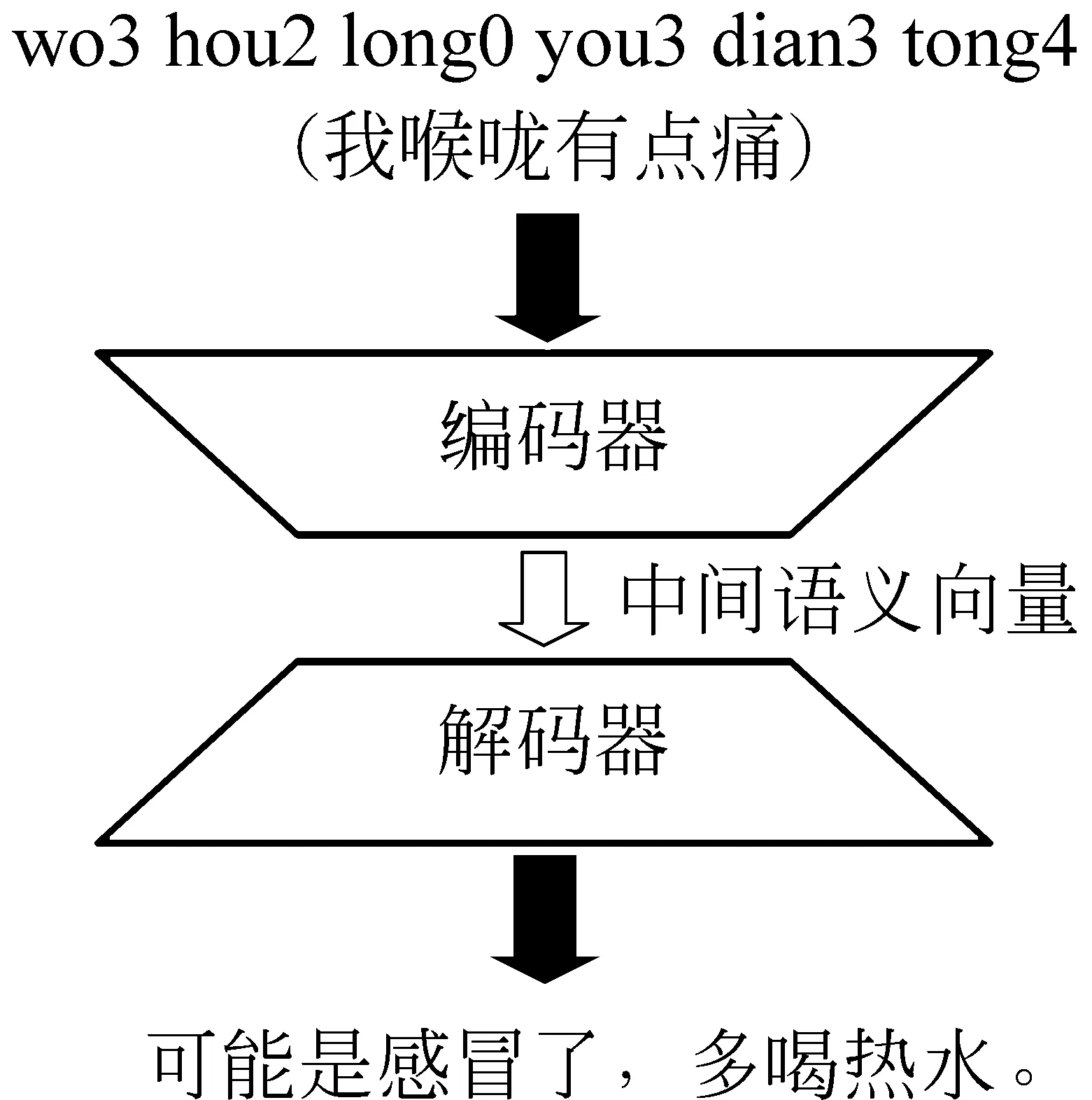
图7 中文对话模型框架
图7中编码器部分即第1节中全卷积神经网络和双向LSTM网络的组合。该部分以拼音图作为网络的输入,提取结合了前后文信息的拼音特征作为中间语义向量。解码器部分由一个4层的GRU网络构成,该网络由一个重置门和一个更新门构成。重置门决定是否要忘记之前的信息,而更新门负责对输出的信息进行更改,GRU网络能够记住很长时间内的信息,对长时间序列处理有较好的表现。解码器部分对拼音特征进行解码,最终得到中文对话模型的输出。
2.2 注意力机制
编码器—解码器模型虽然非常经典,但也存在其局限性,即中间语义是一个固定长度的向量。这将导致输入序列或输出序列的长度较大时,中间语义向量无法包含足够多的信息。为了解决这一问题,模型在解码阶段加入了注意力机制。这样,编码器不再需要将所有的输入信息都编码进一个固定长度的向量之中,而是得到一个中间语义向量序列V=[v1,v2,…,vn]。 在解码时,t时刻解码器的输出 st将与当前时刻计算得出的中间语义向量 vt有关。注意力机制如图8所示。
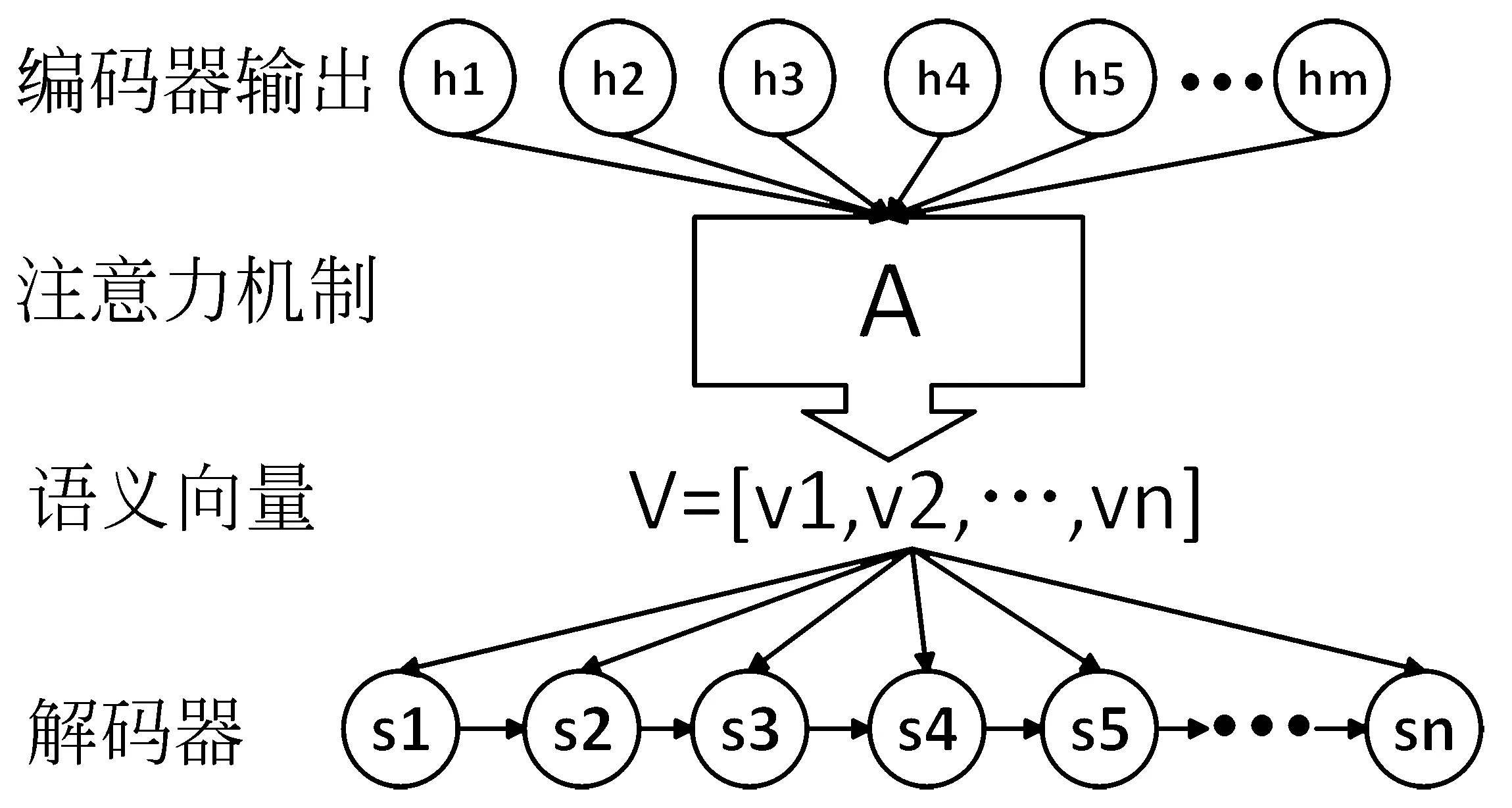
图8 注意力机制
图8中 hj表示编码器输出序列中的第j个值,A=[a1,a2,…,an] 表示注意力机制的权值网络,V为中间语义向量序列, st表示t时刻解码器输出的值,则 st的计算如式(6)、式(7)所示。
其中,atj为由网络训练出的权值矩阵,表示t时刻解码器的输出st对第j个编码器输出hj注意力程度,该值越高则st对hj越重视。可以看到,st由上一时刻解码器的输出st-1和当前时刻的中间语义向量 vt得出。
通过以上步骤,得到了使用拼音输入的中文对话模型,该模型的总体实现流程如图9所示。

图9 对话模型总体流程
3 数据库
目前公开的中文对话数据库数量较少,无法满足深度神经网络的训练要求。为了对中文对话模型进行训练与测试,本文建立了应用于医疗领域的中文对话数据库。该数据库由325万多条问答对组成,其中问题为患者对疾病提出的疑问,回答为医生根据患者描述做出的解答。在建立该数据库的过程中,先在寻医问药网站上提取了大量的问答对话。再对得到的数据进行清洗和预处理,包括:
(1) 去除重复出现的问答对话。
(2) 去除过于简短和过于繁杂的问答对话,将对话句子的长度控制在一定范围之内。
(3) 去除表情符号等干扰因素。
(4) 将网址用特殊符号LINK_ID代替。
(5) 将数字用特殊符号NUM_ID代替。
将建立的数据库以1 000∶1的比例分为训练集和测试集两部分,其中训练集用于训练对话模型,测试集用于验证对话模型的效果。为了作进一步分析,对建立的中文对话数据库进行了统计,统计结果如表2所示。
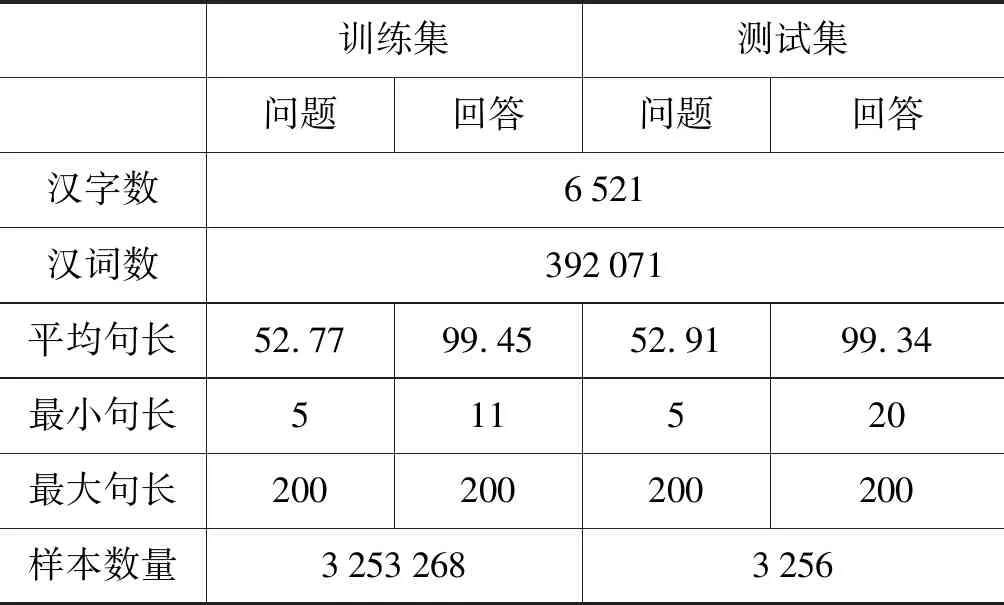
表2 数据库统计信息
由表2可以看到,训练集和测试集中问题与回答的最大句长都为200,这是因为在数据预处理时去除了过于繁杂的问答对话,将问题和回答的最大句长控制在了200。而数据库中回答的平均句长要远大于问题的平均句长,表示医生的回答比患者的提问要更加详尽,包含的内容更多。中文对话数据库部分示例如表3所示。
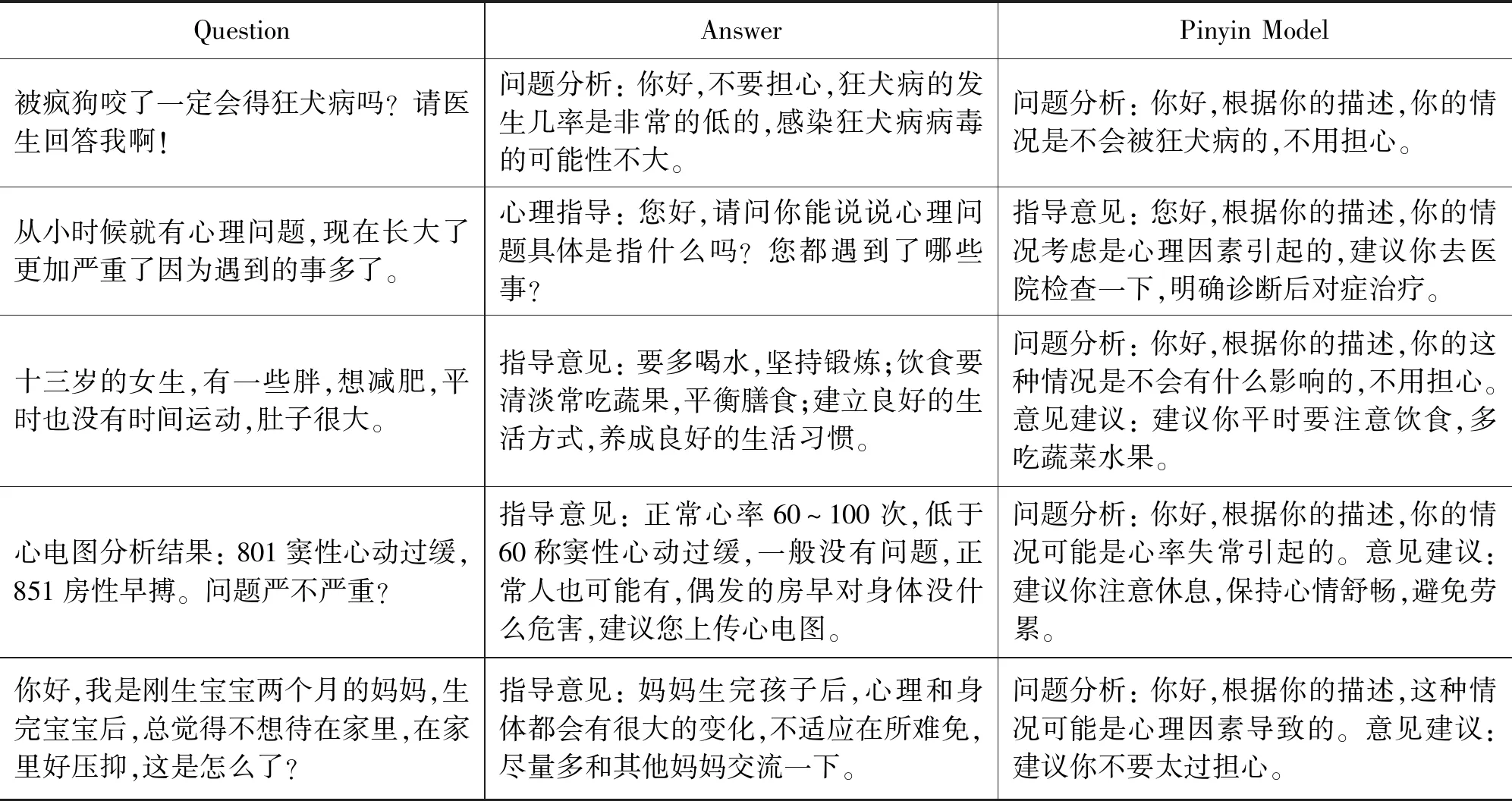
表3 对话模型示例
4 实验与结果分析
4.1 模型训练参数
为了使训练出的中文对话模型有更好的表现,对模型的训练参数进行了如下设置:
(1) 初始学习率设置为0.01,并且每遍历一次训练集就将学习率降为原来的一半,整个训练过程共遍历训练集10次(epoch)。
(2) 批处理数(batch_size)设置为256,即每批训练投入256个训练数据。
(3) 因为递归神经网络存在梯度爆炸的问题,所以对梯度g进行了限制。计算s=‖g‖2,若s>5,则令g=5g/s。
4.2 模型性能分析
本文在空间复杂度和时间复杂度上对模型进行了分析。首先在空间复杂度上分析模型性能。分别以拼音、汉字和汉词作为对话模型的输入,计算模型在输入层的参数数量。声母、韵母和声调共63个,而在建立的中文对话数据库中共6 521个汉字,392 071个汉词,统一以64维的向量对每个输入进行表示,即embedding_size=64。则以拼音为输入的模型在输入层共有63×64个权值参数(weights),64个偏执参数(bias)。同理可得到以汉字和汉词为输入的模型参数数量,如表4所示。

表4 不同输入下输入层参数数量
通过表4可以看到以拼音为输入的模型在输入层的参数数量远低于以汉字和汉词为输入的模型,说明以拼音为输入减小了模型的空间复杂度,在空间上优化了模型。
其次,在时间复杂度上分析模型性能。取批处理数batch_size=16,在不同输入下分别记录训练每批数据所需要的时间,如表5所示(硬件条件为E5-2630 CPU和单张GTX Titan XP显卡)。

表5 不同输入下的批训练时间
由表5可以看到,以拼音为输入的模型训练每批数据的时间要短于以汉字和汉词为输入的模型。这是因为拼音输入具有更小的规模,所需的计算数量较少的缘故。
4.3 拼音特征分析
为了验证模型提取的拼音特征的有效性,在全卷积神经网络和双向LSTM网络组成的编码器后面加入了一层全连接层(注: 该全连接层在最后端到端的对话模型中将被去除,以降低模型的时空开销),该全连接层以分类的方式将拼音特征还原为汉字。即网络的输入为汉语拼音组成的句子,输出为汉字组成的句子。如果网络可以精确地将拼音还原为汉字,则说明拼音特征包含了完整的汉字输入信息。拼音还原汉字流程,如图10所示。

图10 拼音还原汉字流程
在拼音还原汉字实验中,将对话数据库训练集3 253 268条问答对中问题的拼音表示和汉字表示作为模型的训练数据,测试集3 256条问答对中问题的拼音表示和汉字表示作为模型的测试数据。实验中输入为句子的拼音表示,输出为句子的汉字表示。模型在训练集上的初始学习率为0.01,取batch_size=256,epoch=10对模型进行训练。在测试集上将训练出的模型和其他开源的拼音转汉字算法进行了比较,如表6所示。
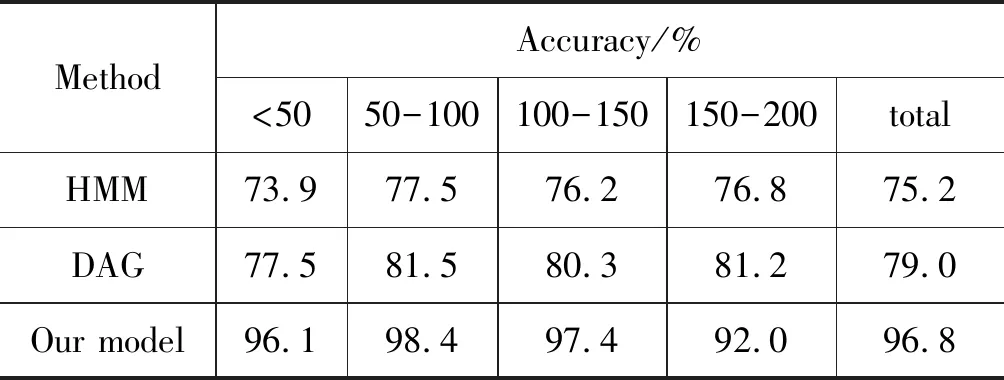
表6 拼音转汉字实验结果
表6中HMM为基于隐马尔科夫模型的转换算法,使用viterbi算法计算拼音输入对应的汉字输出。DAG为基于有向无环图的转换算法,使用的是词库和动态规划的原理。可以看到,相比于HMM和DAG算法,本文的模型算法在各个句长分段上都有较好表现,在测试数据集上拼音转汉字的准确率达到了96.8%。
同时,采用主成分分析(PCA)方法将对话模型提取到的拼音特征降到2维,实现拼音特征的可视化,在空间上分析各个句子拼音特征的关系。可视化的拼音特征,如图11所示。

图11 拼音特征可视化
由图11可以看到,拥有相近病症的句子的拼音特征在空间上较为接近,而拥有不同病症的句子的拼音特征在空间上距离较远。说明拼音特征可以有效区分句子中包含的病症信息,这样对话网络利用拼音特征生成的输出回答将准确地与输入问题中的病症信息对应起来,有利于提高对话模型输出回答的质量。
4.4 对话模型测试
对话问答是具有发散性的,相同的问题可能有完全不同的答案。回答的适当性、流畅性和相关性都会影响到对话模型的效果。如今基于深度学习的对话系统常用的评价指标包括词重叠指标、词向量指标和困惑度指标。本文采用BLEU和ROUGE_L评价指标作为评价中文对话模型回答好坏的标准。BLEU评价指标由IBM[14]在2002年提出,最初用于神经机器翻译(NMT)领域,近年来也被广泛应用于对话系统的性能评估。ROUGE_L在2004年由Chin-Yew提出,是一种利用最长公共子序列求得回答好坏的方法,其计算如式(8)~式(10)所示。
其中,X为参考输出,长度为m。Y为模型生成输出,长度为n。R为召回率,表示为公共序列长度与参考输出长度的比值。P为准确率,表示为公共序列长度与生成输出长度的比值。实验中考虑到要对话模型要综合考虑召回率和准确率,故计算ROULE_L时取β=1。对话模型测试结果如表7所示。
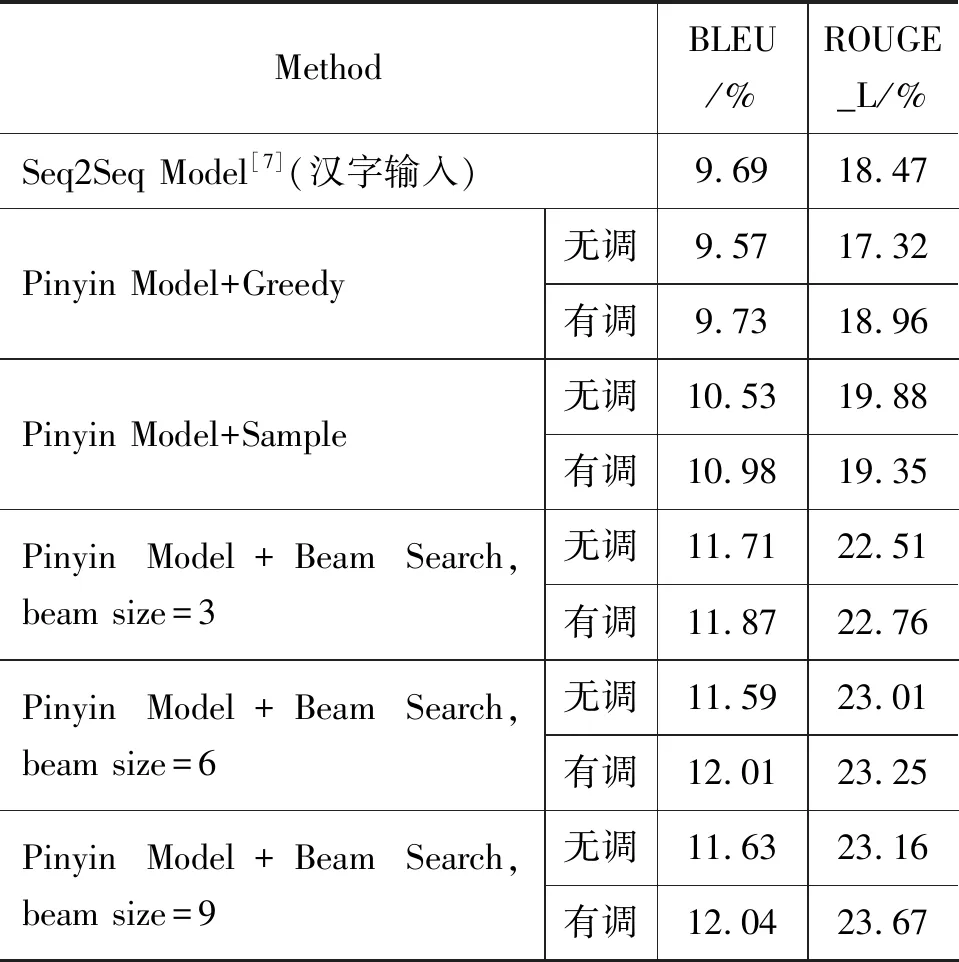
表7 对话模型评价
表7中Seq2Seq Model为基于汉字输入的对话模型,Pinyin Model为本文提出的基于拼音输入的对话模型。以拼音为输入的模型分为了无调拼音模型和有调拼音模型两种,无调拼音模型即输入的拼音不包含声调信息,有调拼音模型即输入的拼音包含了声调信息。Pinyin Model使用贪婪搜索(Greedy)、采样搜索(Sample)和集束搜索(Beam Search)三种搜索策略在测试集上进行了对比。在采用有调拼音输入,Beam Search搜索策略,词表大小(beam size)为9时,取得了最好的效果。
图12是以BLEU为指标在不同句长下对中文对话模型的测试结果。可以看到,采样搜索策略和集束搜索策略整体都优于贪婪搜索策略。这是因为贪婪搜索策略只选择当前时刻的最优匹配而没有考虑一段时间内的最佳答案,所以导致BLEU得分较低。而采样搜索对于句长大于150的句子表现较好,总体上集束搜索表现最优。对话模型的具体示例如表3所示。
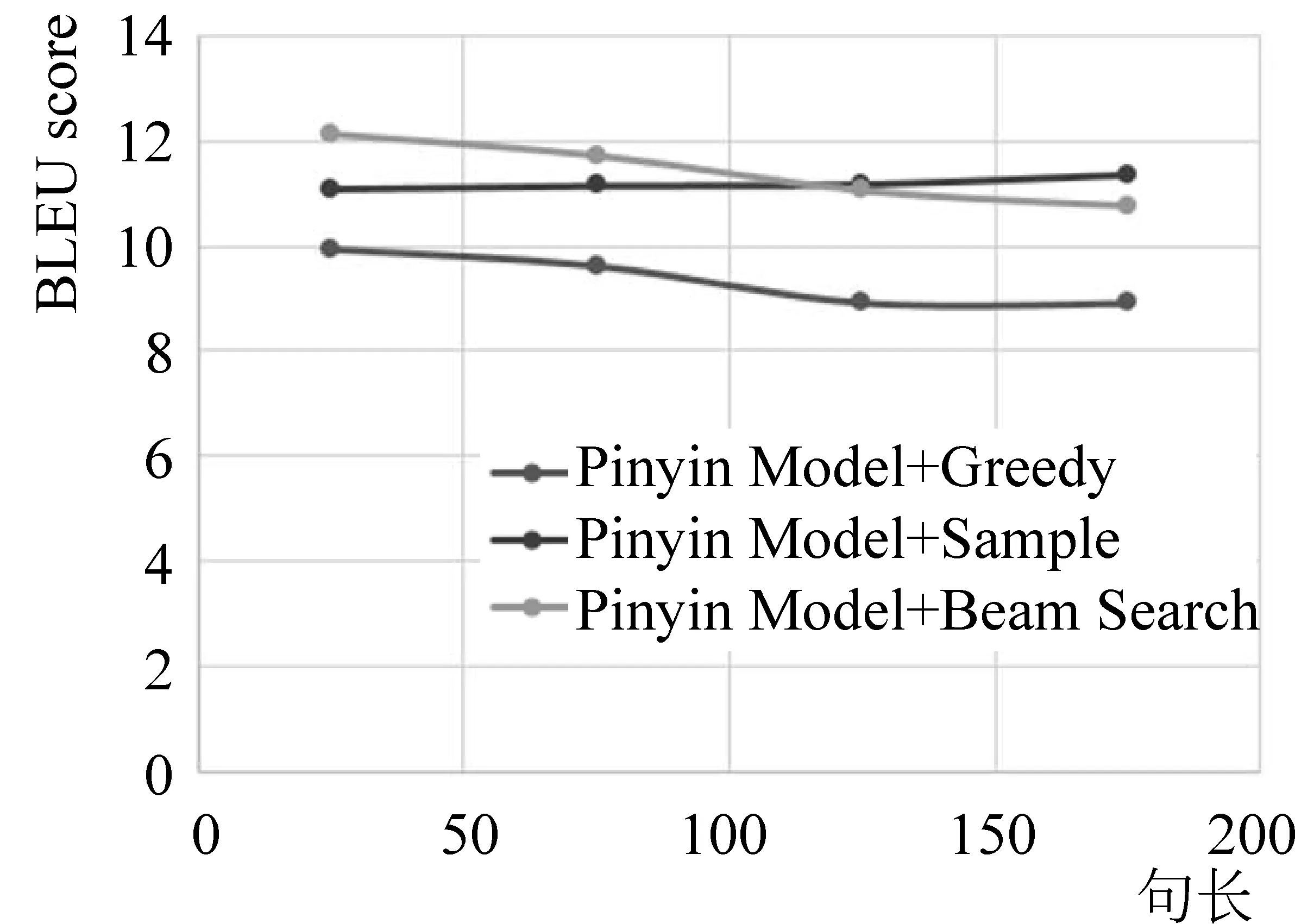
图12 对话模型在不同句长下的测试结果
5 结论
本文利用汉字可用汉语拼音表述这一特点,提出了一种利用全卷积神经网络和双向LSTM网络提取中文对话模型拼音特征的方法,该方法减少了对话模型的输入维数,降低了模型的时空开销。在此基础上,采用4层GRU网络结合注意力机制对拼音特征进行解码以解决普通RNN网络无法记忆长时间信息的问题,得到中文对话系统的输出。最后,建立了用于医疗领域的对话数据库并在该数据库上采用BLEU和ROUGE_L作为评价指标进行了实验与对比,取得了很好的效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
小学阅读指南·低年级版(2017年4期)2017-04-24 16:36:13
小学阅读指南·低年级版(2017年1期)2017-03-13 19:56:28
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
小天使·一年级语数英综合(2015年8期)2015-07-06 06:16:26
小天使·一年级语数英综合(2015年3期)2015-04-20 05:57:18
小天使·一年级语数英综合(2015年2期)2015-01-14 06:07:04
小溪流(画刊)(2014年4期)2014-06-28 19:27:00
