
基于双通道卷积神经网络的问句意图分类研究
2019-06-03 11:14:16杨志明王来奇
中文信息学报 2019年5期
杨志明,王来奇,王 泳
(1. 中国科学院 软件研究所,北京 100190;2. 中国科学院大学,北京 100049;3. 深思考人工智能机器人科技(北京)有限公司,北京 100085)
0 引言
自然语言处理(Natural Language Processing,NLP)技术与自然语言理解(Natural Language Understanding,NLU)技术研究如何让计算机理解自然语言的语义,并运用自然语言与人进行交流,实现人机对话。因此,自然语言理解系统又叫自然语言问答系统(Question Answering System),简称问答系统(QA system)[1]。问答系统是信息检索系统中的一种高级方式,主要包含文本理解、信息检索和答案抽取三部分[2]。用户使用自然语言的表达方式向QA系统提出问题,QA系统向用户返回简洁准确的答案[3-4]。其中,问题语义理解是整个问答系统中的核心功能,对提高问答系统的整体性能具有重要作用[2,5-7]。问句理解的功能是经过对问题答案的类别进行确定,从而可以为信息检索的过程提供约束条件,缩小答案的搜索范围,提高问答系统的准确性[2]。Surdeanu[8]等学者曾经对问答系统中各部分对系统性能的影响做过相关研究,发现问句意图分类对问答系统的影响最大。因此,为了得到一个好的QA系统,需要设计一个高精度的问句意图分类器。
随着互联网技术的快速发展,随之而来的是各行业的数据量也快速增长。因此,对于大量数据集的处理分析要求也愈来愈高,促进了深度学习技术的快速发展。相较于传统机器学习算法而言,深度学习技术在处理大量数据集方面具有明显优势[9]。目前,深度学习模型在计算机视觉[10]和语音识别[11]等方面取得了显著成果。其中,最初发明应用于计算机视觉的CNN模型随后被证明对NLP任务有效,且在语义分析[12],搜索、查询、检索[13],句子建模[14]以及其他传统的NLP任务中取得了优异结果[15]。当前CNN神经网络模型在问句意图理解中的应用还是主要以单通道的形式为主,这种网络架构具有视角单一,不能很好的学习到数据更广泛的语义特征等问题。而双通道神经网络架构的思想主要源于计算机视觉方面的相关知识。一幅彩色图像是由RGB三个颜色通道构成的,这样就能够表示图像在不同状态下的特点[9]。Kim[16]研究卷积神经网络在处理英文数据集时,曾把静态的词向量与动态的词向量用于模型通道的输入,但考虑到中文自然语言问句的复杂性,本文提出了一种双通道CNN网络架构,把字向量和词向量分别作为构建的双通道CNN模型的输入,利用字的语义空间辅助词向量建模。利用多尺寸卷积核进行卷积计算,获取更充分的问句语义特征。经实验证明ICDCNN模型泛化能力强,在问句意图分类方面的准确率远高于其他算法。此外,本文还尝试使用传统的机器学习方法如KNN,LR以及集成模型如XGBoost、Adaboost等模型进行了对比实验。目前,针对基于深度学习的自然语言问句意图分类的研究方法还比较少,该领域还有很大的研究空间。因此该研究方向具有较好的研究前景,对于促进人机交互方式的发展具有重要意义,是一个值得深入探索的研究课题。
1 相关工作
自然语言问句理解是属于自然语言处理领域的问题,且一直都是其中一个热门研究方向,其主要内容是通过NLP的相关技术对自然语言问句进行意图分类。理解问句的意图,即为问句赋予一个类别标签,这个类别标签代表问句所属于的领域。自然语言问句意图理解是聊天机器人系统中的核心技术,自1999年起在一年一次的问句信息检索会议上(Text Retrieval Conference,TREC),自动问答系统主题一直是备受关注的主题之一,越来越多的研究者开始从事自然语言问句分类的相关研究。如今,国内外学者对于自然语言问句意图理解已经做了大量的研究。本文通过调研发现目前对于该问题的研究方法主要分为三大类: ①基于规则的问句意图分类解决方法; ②基于机器学习的问句意图分类解决方法; ③基于混合模式的问句意图分类方法。这三大类研究方法的特点如表1所示。
1.1 基于规则的问句意图分类研究
基于规则的问句意图分类解决方法通过分析已有的语料,提取可用的规则,进而构建一个基于规则的分类器[17]。在对自然语言问句进行分类时,使用预定义的规则获取问句的关键词,并依据关键词来理解自然语言问句的意图,从而达到分类的目的[2]。在解决相同领域的问句时,基于规则的问句意图分类方法具有较好的分类效果,但该方法具有较大的局限性。首先,为了获得较好的实验结果,往往需要人工定义大量的规则,当语料规模很大时,将需要耗费大量人力[2,18]。其次,对同一种类型的自然语言问句,可能会有多种表达方式,针对这种现象,Li[19]

表1 自然语言问句意图识别三类研究方法
等进行了相关论证,结论是这种现象会导致随着句子数量的增加,规则的数量也会急剧增加。此外,构建的大部分规则并没有泛化的能力,通过分析一个领域的语料构建的规则通常只能够用在与该领域相似的语料上。因此,很难构建出一个通用的、泛化能力强的规则架构[20]。
1.2 基于机器学习的问句意图分类研究
近年来,国内外科研工作者对机器学习方法在生活中的应用进行了大量的研究。例如,在人脸识别、无人驾驶、阅读理解、机器翻译等领域都得到了广泛应用[2]。其中,基于机器学习的自然语言问句意图分类方法使用带标签的语料训练分类模型得到分类器。不同的分类器主要在模型架构和问句特征提取方面存在不同。目前,有监督学习的分类模型主要有逻辑回归(LR)、支持向量机(SVM)、随机深林(RF)及深度神经网络(DNN)等。深度学习是机器学习的子领域,被称为人工神经网络的大脑结构和功能所启发的算法。Hinton在2006年提出了一种深度置信网络架构,该算法模型在深度学习领域具有里程碑式的作用[9,21]。2010年Mikolov[25]等提出了一种基于RNN的神经网络语言模型,该神经网络语言模型相较于统计语言模型在多个任务上取得了较大的突破。2014年Kim[16]在训练的词向量的基础上研究了卷积神经网络(CNN)模型在自然语言问句分类上的应用。2016年Komninos[22]等研究发现在自然语言问句意图分类的实验中使用基于上下文的词嵌入可以获得较好的实验效果[2]。很多基于深度学习技术的模型都获得比较好的实验结果。其中最典型的深度学习网络架构包括卷积神经网络(CNN)和循环神经网络(RNN)。
1.3 基于混合模式的问句意图分类研究
近几年来,有些学者采用把多个分类模型进行集成的方法来处理自然语言问句分类任务。2008年,Li X[23]等使用四种不相同的特征分别训练四个支持向量机分类器,然后运用模型融合技术将四个分类器集成一起,并分别使用XGBoost算法、神经网络算法及TBL算法进行了测试。Li等在2008年提出了一种SVM和CRE相结合的策略,把句子看成一个序列,首先使用CRF模型对自然语言问句中的每个词语添加标记,然后使用SVM分类器对自然语言问句进行分类[2,24]。
2 算法流程
本文通过分析聊天机器人中的对话语句和单通道卷积神经网络的特点,提出了意图分类双通道卷积神经网络(ICDCNN)模型,用于解决多意图分类的问题。该算法模型基于如下思想提出: 该模型架构包含两个通道,每个通道分别接收不同粒度的词向量;然后用卷积网络学习不同粒度的语义信息获取句子内部更深层次的抽象特征;最后把两个通道学习到的更深层次的抽象特征进行合并,达到利用细粒度的字级别的词向量辅助词级别词向量捕捉自然语言问句更深层次的语义信息的目的;最终用于决策自然语言问句想表达的意图。
整个自然语言问句意图理解分类项目的算法流程主要包含数据预处理、特征工程、模型训练、模型评估、意图输出等过程。详细的ICDCNN算法流程如下所示。
Input:X={X1,X2,…,Xn},Language={Chinese}
Output: label Y
Algorithm
(1) Preprocessing: Filling missing value; correcting mistaken word; merging data within the same category; filtering stop word; punctuation processing.
(2) Constructing dictionary
(3) If Language=Chinese
a) Data Segmentation by using Jieba
b) End if
(4) Encoding on labels: OneHotEncoder(Y)
(6) Word2vec feature extraction (output dimension=40; training iteration=5; model=CBOW; window size=5; learning rate=0.025; sample=1e-3):
(7) CNN (Convolution layer; Dropout layer; Max pooling layer; Optimization : Mini batch gradient descent: param):
c)Fword: features obtained using CNN onXword
d)Fcharacter: features obtained using CNN onXcharacter
(8) Classification: Y=Softmax([Fword;Fcharacter])
在每个过程中需要用到的技术以及要做的工作等内容在本文剩余部分详述。
2.1 数据分析
图像、问句、音频、视频等数据,大体上都是一些不完整、不一致的脏数据,无法直接用于数据挖掘或基于此的挖掘结果差强人意。为了提高数据挖掘质量,在实验之前需要对其进行相应的预处理操作。
(1) 数据预处理: 在实验过程中,对数据集进行了缺失值处理、非法字符过滤、停用词过滤、标点符号处理,以及数据词典的构建操作。对于中文数据集还进行了分词操作。通过预处理操作后,可以大大的提高数据挖掘的质量,降低数据挖掘的时间。
(2) 数据编码: 由于构建的模型是针对数值进行计算的,因此语料中的字符串类型需要转化成数值类型,本文使用One-Hot-Encoder编码技术,对没有顺序的特征值使用一组二进制数字进行表示。
(3) 数据规范化: 针对数据的规模变化较大的特征,在训练模型之前需要预先对数据集进行标准化操作,这样有利于提高实验效果,减少模型训练时间。实验中使用Standardization方法把数据特征转化成高斯分布,使得特征的均值为0,方差为1,如式(1)所示。
(1)
2.2 特征工程
聊天机器人获取的日志数据中问句类型种类繁多,需要提取自然语言问句的特征才可以理解问句所表达的意图。传统的方法使用词袋模型或向量空间模型对问句特征进行表示。这种表示方法只考虑了问句的词频信息,忽略了问句的上下文信息,故不能学习到问句的语义信息。词向量的提出,可以解决使用传统特征对问句表示产生的一些问题。本文中分别使用字级别的词向量和词级别的词向量对自然语言问句进行表示,并通过两者的结合进而获得问句更深层次的语义信息。
2.2.1 字级别词向量
字级别的特征,即把单个字看作自然语言问句的基本组成构成单元,对单个字进行词向量[26]训练。字向量作为自然语言问句处理的基本构成单位,在对自然语言问句进行深度语义处理分析过程中起着非常重要的作用。采用字向量可以减弱因分词错误造成问句语义理解不准的问题。
2.2.2 词级别词向量
词级别的特征,即使用分词器对句子进行分词处理,把单个词语看作自然语言问句的基本构成单元[26]。利用构建的神经网络训练词级别的语言模型,训练结束后问句中的每个词都会由一组n维向量进行表示。在训练的过程中,就可以捕获自然语言问句中的语义信息,这对于句子意图识别非常重要。为了进一步发挥词向量的作用,提高模型的准确率。在本文实验的过程中使用Word2Vec工具在大量的数据集上进行了无监督的学习来获得词向量用于后续自然语言问句的意图分类。
2.2.3 词向量训练
对于字级别的词向量训练是以字作为句子的基本单位,为每个字训练一个词向量。对于词级别的词向量训练时,相对于英文数据来说,需要先利用Jieba、hanlp等分词工具对中文数据集进行分词处理。把分词操作后的单个词语看作自然语言问句的基本构成单元,为每个词语训练相应的词向量。使用word2vec工具对自然语言问句训练词向量时参数设置如表2所示。
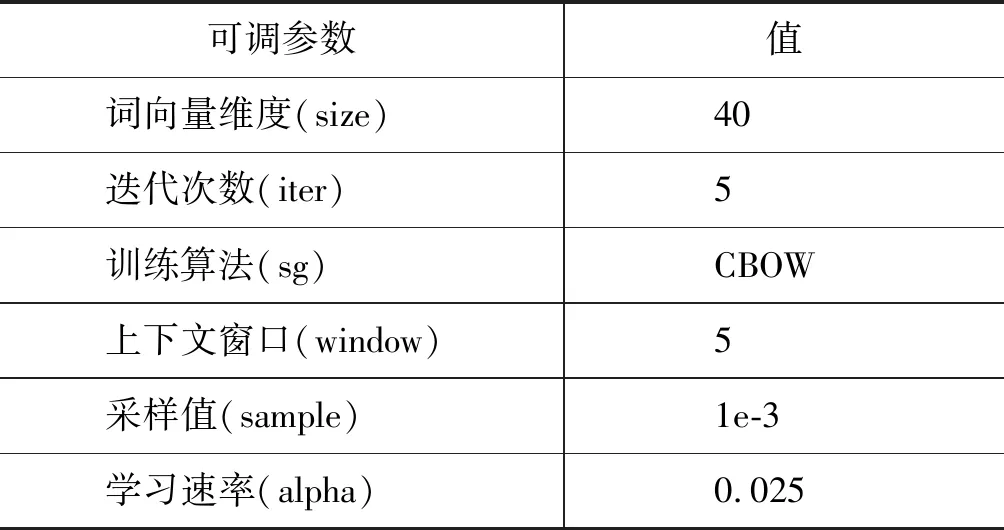
表2 word2vec工具参数设置
2.3 建模
实验的过程中,首先使用了几种传统的机器学习分类模型进行了实验,例如,LR、KNN、CART、SVM等;其次选用了集成分类方法进行了相关实验,例如,AdaBoost、XGBoost、GradientBoosting等;最后,运用Keras、tensorflow深度学习框架构建深度学习模型多层感知机(MLP)和意图分类双通道卷积神经网络模型(ICDCNN),用于训练分类模型。
2.3.1 卷积神经网络
CNN是一种比较经典的前馈神经网络,具有局部连接、权值共享、下采样等三个主要特点[27]。最初主要应用于计算机视觉领域中,并获得了很大成功,之后许多研究者把它应用于处理自然语言处理任务中[10,14,16]。CNN利用自身网络结构的特点,可以学习到自然语言问句中比较深层次的语义信息,且可以在能够接受的时间范围内完成训练。
2.3.2 双通道卷积神经网络(ICDCNN)
本文通过对CNN网络和对话语料特点进行分析,提出了双通道卷积神经网络(ICDCNN)算法模型。该算法模型能够同时接收字级别的词向量和词级别的词向量。通过设置不同大小的卷积核进行卷积计算,学习每个问句中词语和词语,字和字之间的信息。这样就可以达到对问句中的每个局部信息进行建模,可以学习到句子内部更深层次的语义信息,以获得更优质的问句语义特征。本文使用的ICDCNN网络模型架构图,如图1所示。
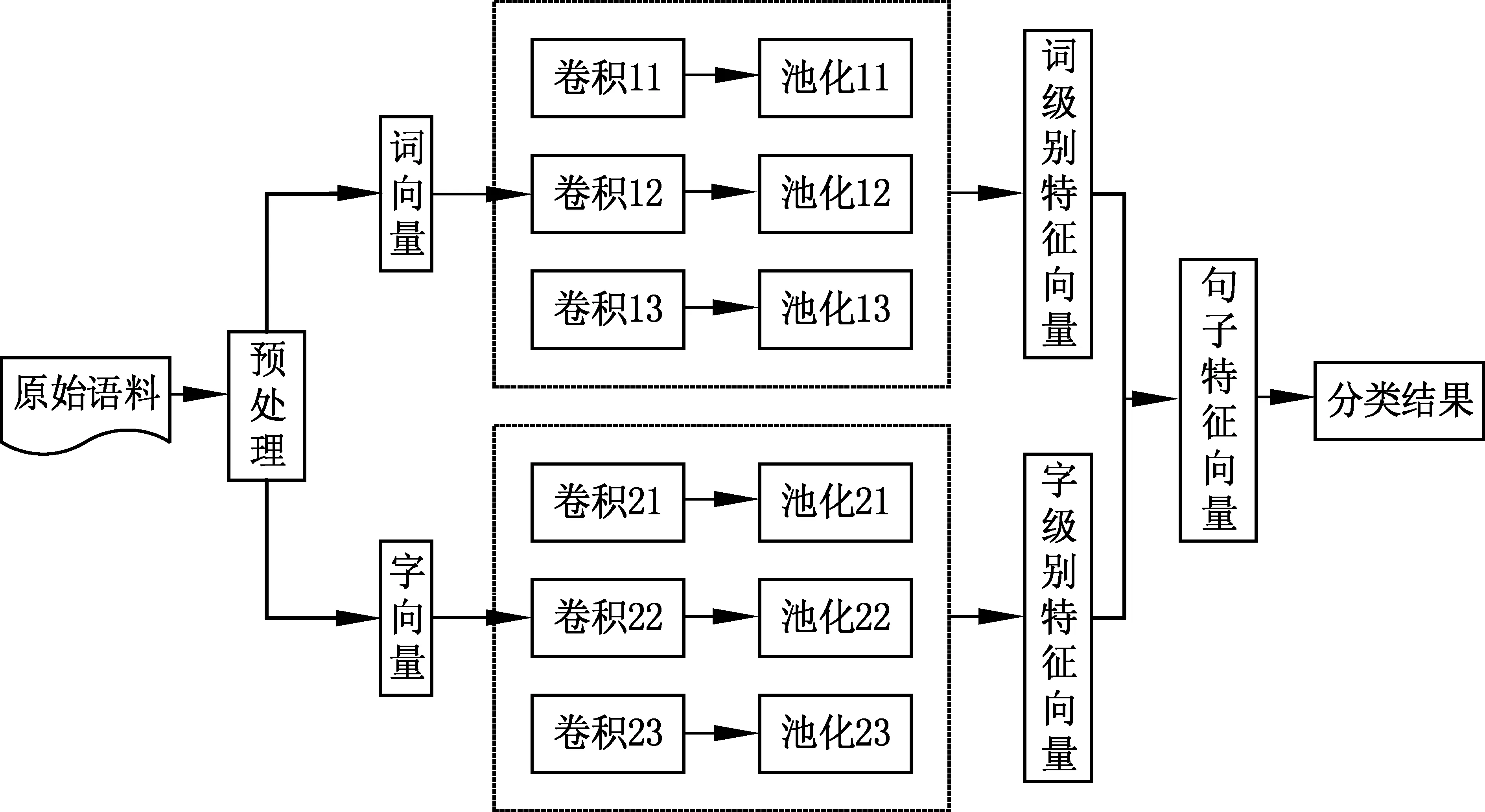
图1 双通道卷积神经网络结构图
• CDCNN模型构建
(1) Embedding层: 该层主要用于对句子进行编码,产生词或者字的分布式表示,还可以接收提前使用Word2Vec工具训练好的词向量。使用预训练好的词向量能够提高模型的准确率以及降低因为参数过大发生过拟合的概率。通过该层后就可以获得每个词或字的词向量,若每一个句子的长度为n,词向量的维度为k,Xi为第i个词,那么对于一个长度为n的句子可表示为式(2)。
X1:n=X1⊕X2⊕X3…⊕Xn
(2)
其中,符号⨁为连接运算符,Xi:i+j表示词向量Xi,Xi+1,…,Xi+j构成的特征向量矩阵。
(2) 卷积层: 该层的主要功能是通过卷积运算实现对自然语言问句的局部特征进行感知。本文选择尺寸大小不同的卷积核对输入神经网络模型中的词级别的词向量和字级别的词向量分别进行卷积操作,获取问句中更深层次的语义信息。本文采用了k=2,k=3和k=4三组尺寸大小不相同的卷积核进行卷积运算操作,使用b代表偏置项,用Wk代表不同的卷积核所对应的权值矩阵,用C1表示接收词向量的通道,用C2表示接收字向量的通道,Yk表示经过卷积后的输出结果。则通过不同尺寸的卷积核卷积运算得到的运算结果,如式(3)所示。
Yk=f(Wk·Xi:i +k -1+b)k=2,3,4
(3)
为了加快模型的收敛速度,训练过程中选用了relu作为激活函数f。使用卷积核进行卷积运算时卷积操作的步幅大小为1。当卷积核在长度为n的问句经过一次卷积操作后获得n-k+1个输出,生成特征图的计算,如式(4)所示。
Y(1)=Yk1,Yk2,…Yk,n -k +1k=2,3,4
(4)
(3) 池化层: 该层具有降低数据的维度、减少数据和参数的数量,减少过拟合等作用。本文训练模型时选用了最大池化(max-pooling)操作,且对每个通道都进行最大池化操作运算。数据通过该层运算后,模型能够捕获到具有代表性的特征。最大池化计算,如式(5)所示。
Y(2)=max(Yk,i)
(5)
假设每组卷积核的数量为m,最终池化后输出的特征集合,如式(6)所示。
Y(3)=flatten
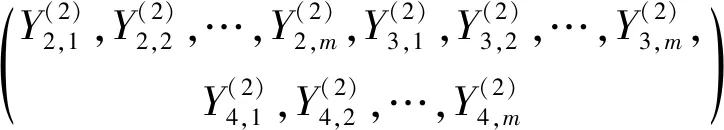
(6)
(4)合并层: 本层的主要作用是把两个通道C1和C2获取到的问句特征进行组合,获得全局特征信息,得到的最终问句特征向量,如式(7)所示。
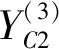
(7)
(5) 输出层: 该层的作用是接收合并层输出的特征向量,然后传入softmax分类器中,输出的值就是分类器对自然语言问句意图类别的预测值hθ(x),hθ(x)的计算,如式(8)所示。
(8)
其中,hθ(x(i))代表第i个样本的预测结果,wi代表着需要通过训练的获得权重值,bi为需要经过模型训练求得的偏置。
• ICDCNN模型训练
在模型训练的过程中本文使用多值交叉熵(categorical_crossentropy)代价函数用于衡量模型的损失,采用小批量梯度递减方法(mini-batch Gradient Descent)对模型进行优化。多值交叉熵代价函数,以及用梯度递减的方法对多值交叉熵代价函数优化的公式,如式(9)所示。
(9)
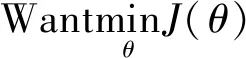

3 实验
本节将通过实验来考察本文提出的意图分类双通道卷积神经网络(ICDCNN)模型在问句意图识别任务上的性能,然后将其与其他模型的性能进行对比分析。
3.1 数据集
为了测试提出模型的有效性,本文选用了IDeepWise数据集,该数据集是对SMP2017数据集的扩充和补充。涉及到订票类、天气类、音乐类、闲聊类等13个领域。采用预处理技术对数据进行了缺失值处理、错误字符纠正、数据类别合并、停用词处理,去重等操作最终得到53 117条样本,每种类别样本数量和对应的类别标签如表3所示。
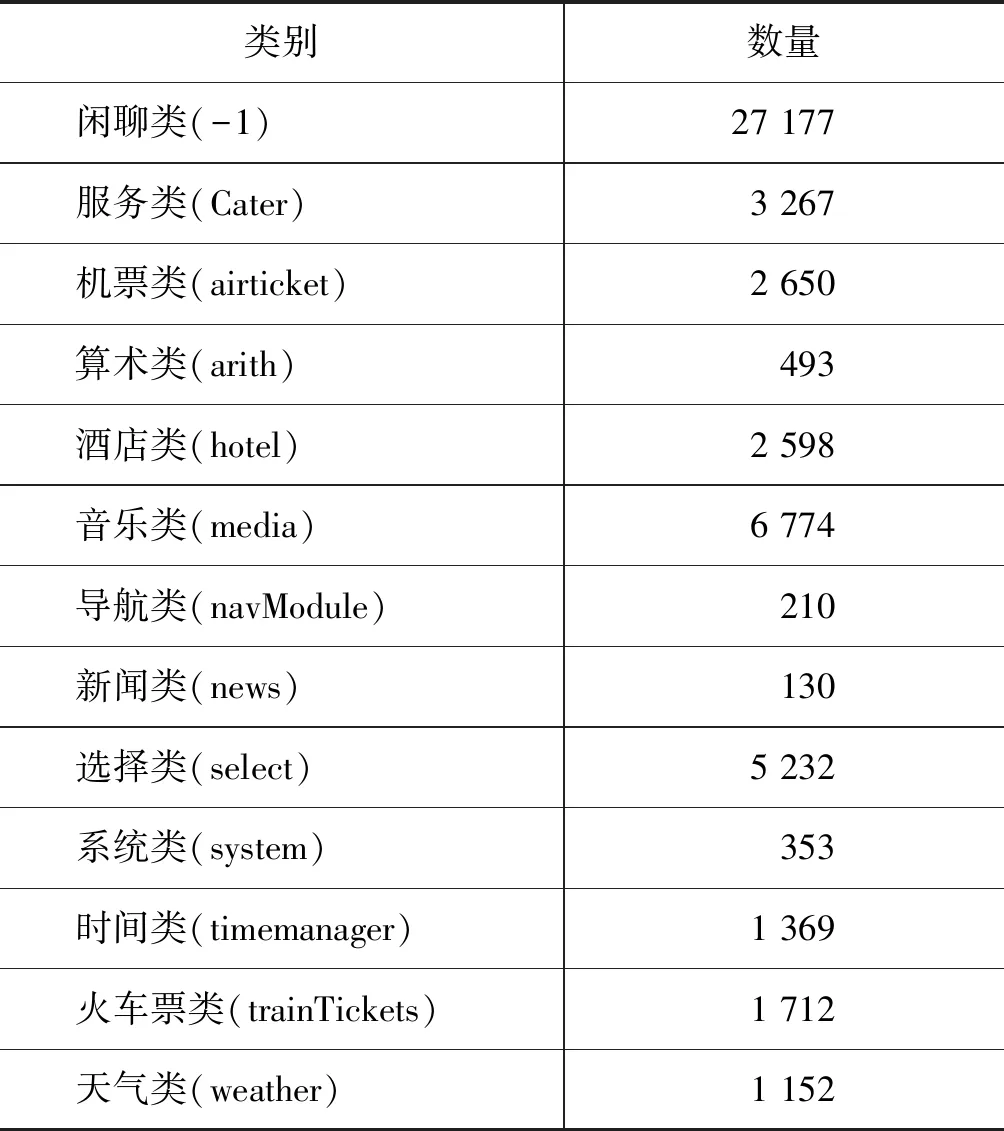
表3 样本类别和数量统计信息
3.2 环境配置
实验选用的研发环境软硬件配置详细信息如表4所示。
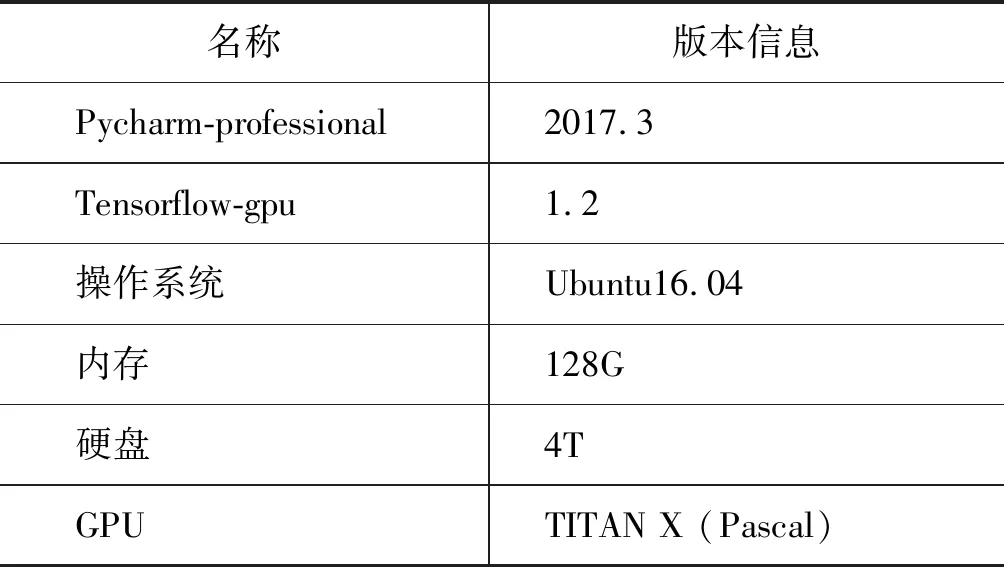
表4 实验环境软硬件配置
3.3 模型参数设置
实验过程中根据图1的ICDCNN网络架构进行构建模型, 在实验的过程中为本文所提模型设置的参数如表5所示。
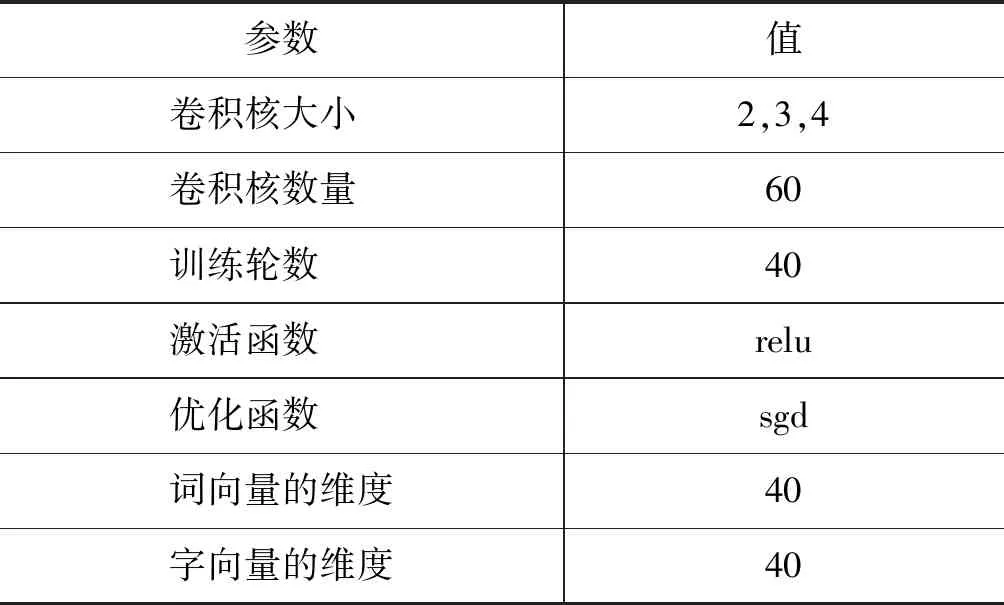
表5 ICDCNN模型参数设置
3.4 实验步骤
(1) 首先将原始问句采用结巴工具进行分词。
(2) 建立语料词典,对语料进行清洗操作。
(3) 采用Word2Vec工具训练词级别的词向量和字级别的词向量。
(4) 把词语和字分别用唯一的字符进行表示,转换成模型可接收的词序列和字序列。
(5) 根据与词语和字一一相对应的的唯一标识符到词向量表获得对应的词向量,求得词向量矩阵,然后输入构建的模型当中用于训练。
(6) 使用式(9)中定义的损失函数,开始对模型进行训练。
(7) 使用测试数据集对训练好的模型性能进行评估。
3.5 实验结果讨论
本文对多个模型进行了实验,实验过程中把本文所提ICDCNN算法与以下算法进行对比,以此来说明本文所提算法的有效性。
LR: 利用Word2Vec训练出来的词级别的词向量进行实验,用LR模型进行分类。
KNN: 利用Word2Vec训练出来的词级别的词向量进行实验,用KNN模型进行分类。
CART: 利用Word2Vec训练出来的词级别的词向量进行实验,用CART模型进行分类。
SVM: 利用Word2Vec训练出来的词级别的词向量进行实验,用SVM模型进行分类。
XGBoost: 利用Word2Vec训练出来的词级别的词向量进行实验,用XGBoost模型进行分类。
AdaBoost: 利用Word2Vec训练出来的词级别的词向量进行实验,用AdaBoost模型进行分类。
RF: 利用Word2Vec训练出来的词级别的词向量进行实验,用RF模型进行分类。
GB: 利用Word2Vec训练出来的词级别的词向量进行实验,用GB模型进行分类。
MLP: 利用Word2Vec训练出来的词级别的词向量进行实验,用MLP深度模型进行分类。
CNN: 利用Word2Vec训练出来的词级别的词向量进行实验,用CNN深度模型进行分类。
LSTM: 利用Word2Vec训练出来的词级别的词向量进行实验,用LSTM深度模型进行分类。
ICDCNN-rand: 在该模式下实验过程中获得到的词向量是通过随机初始化生成的,在训练的过程中也会对词向量进行微调,同时学习模型的其他参数。
ICDCNN-static: 该模式下是把Word2Vec工具预先训练好的词向量引入实验当中。该模式的特点是,当模型训练时只是学习模型的其他参数,词向量不会改变。
ICDCNN-non-static: 在该模式下的训练过程是使用Word2Vec工具预先训练好的词向量。在实验过程当中,学习模型其他参数的同时,预先训练好的词向量也会被微调。
ICDCNN-multichannel: ICDCNN-static和ICDCNN-non-static的混合输入,即两种类型的输入。

(10)
在实验中,采用回调函数,选取测试集准确率最高的作为模型的准确率,各个模型iDeepWise数据集上的实验效果,如表6所示。
根据表6中的实验记录,得出一些传统机器学习方法和集成机器学习方法解决多意图分类任务的实验结果直方图,如图2所示。
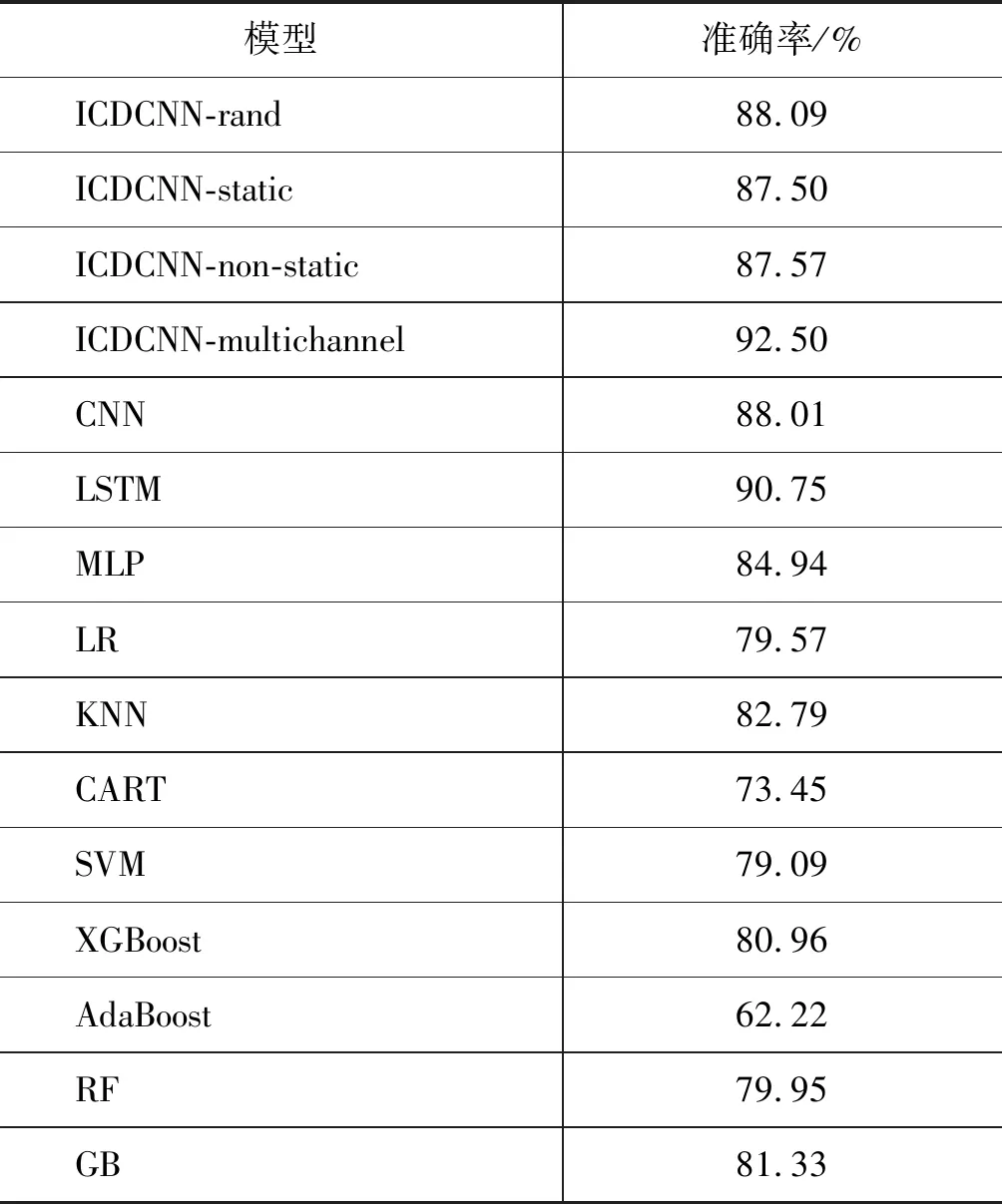
表6 不同模型的意图分类准确率

图2 机器学习方法多意图分类实验结果直方图
构建的深度学习方法解决多意图分类任务的实验结果直方图,如图3所示。
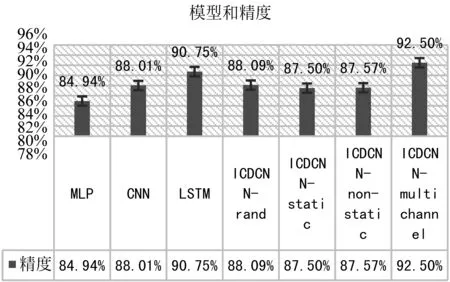
图3 深度学习方法多意图分类实验结果直方图
3.5.1 传统机器学习vs.深度学习
通过表6、图2、图3中的实验结果可知深度学习模型在数据集上表现的效果比传统机器学习模型效果要好。原因在于深度学习模型能够更好学习到数据中的语义信息,这对句子意图识别非常重要,因此,本文最终选用深度学习模型来完成问句意图识别的任务。
3.5.2 Random vs. word2vec
通过对ICDCNN-rand和ICDCNN-static模型在各个数据集上的准确率分析比价可知,在处理自然语言问句分类任务上,引入预先训练的词向量在一定程度上可以提高模型的准确率。因为训练模型的过程中引入使用Word2Vec工具预训练好的词向量中含有大量语料的上下文的语义信息,起到了数据迁移的作用。因此,在解决问句意图类别分析时能够获得比较好的实验效果。综上,在实验过程中引入在外部大量语料上训练得到的词向量是很有必要的。
3.5.3 Static vs. Non-static
通过对ICDCNN-static和ICDCNN-non-static模型在各个数据集上的实验效果对比分析可知,使用CNN网络训练过程当中对引入的预训练好的词向量进行微调,可以使得提前预训练好的词向量更好的处理特定的任务,提升模型的准确率。
通过对比各个模型在相同数据集上的实验效果可以看出本文提出的ICDCNN双通道卷积神经网络模型是有效的。通过对比分析实验结果,主要原因是因为字级别的特征粒度较小,涵盖的自然语言问句特征范围比较广,可以学习到自然语言问句中更加细粒度的语义信息,进而提高模型的性能。
4 结束语
本文通过分析聊天机器人系统中的自然语言问句的特点,以及单通道卷积神经网络模型在处理自然语言问句分类时存在的问题,提出了一种新的用于自然语言问句意图识别的方法ICDCNN模型。该模型具有两个通道,可以同时接收字级别的词向量和词级别的词向量进行卷积运算。使用细粒度的字向量协助粗粒度的词向量提取自然语言问句更深层次的语义特征信息,进而提升自然语言问句意图识别的准确率。从实验结果可以看出,本文提出的双通道卷积神经网络在自然语言问句意图识别上具有更高的准确率,在SMP 2017国内首届中文人机对话技术评测过程中获得第一名。证明了所提方法的有效与可行,并为其他研究者进行相关研究提供了重要的参考价值,也极大地推动了该技术在NLP领域的应用。
猜你喜欢
法律方法(2022年2期)2022-10-20 06:42:20
福建基础教育研究(2022年4期)2022-05-16 08:48:40
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
基层中医药(2021年8期)2021-11-02 06:25:02
法律方法(2021年3期)2021-03-16 05:56:58
电子制作(2019年11期)2019-07-04 00:34:38
家庭影院技术(2018年5期)2018-06-29 07:42:10
家庭影院技术(2018年3期)2018-05-09 07:06:12
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中学生(2017年13期)2017-06-15 12:57:48
