
基于TensorFlow的K-means算法的研究
2019-05-27 06:12李昱锋李建宏文永明
网络安全与数据管理 2019年5期
李昱锋,李建宏,文永明
(1.华北计算机系统工程研究所,北京 100083;2.中国人民解放军第5718工厂,广西 桂林 541003)
0 引言
聚类[1]分析是一个数据对象划分成子集的过程,每个子集是一个簇,使得簇中的对象彼此相似,但与其他簇中的对象不相似。聚类分析已经广泛地用于许多应用领域,包括商务智能、图像模式识别、Web搜索、生物学和安全。在商务智能应用中,可以将大量客户分组,其中组内的客户具有非常类似的特征,这有利于开发加强客户关系管理的商务策略。K-means算法是聚类分析中的一个经典算法,是基于距离的聚类分析。在当今信息时代,数据爆炸式增长,数据处理的计算量也随之增大,为了缩短运算时长采用GPU进行计算,通过计算并行化从而提高算法性能。CUDA是NVIDIA推出的基于GPU的通用并行计算平台和编程模型。TensorFlow支持GPU加速,通过使用CUDA和驱动实现GPU计算。
1 基于TensorFlow的K-means算法
1.1 CUDA平台
CPU由专为顺序串行处理而优化的几个核心组成,而GPU则拥有由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。这使得CPU更擅长处理具有复杂计算步骤和复杂数据依赖的计算任务,GPU更擅长处理并行计算[2],CPU优化复杂逻辑任务的运行时间,GPU则优化吞吐量。图1为CPU和CPU的结构图。
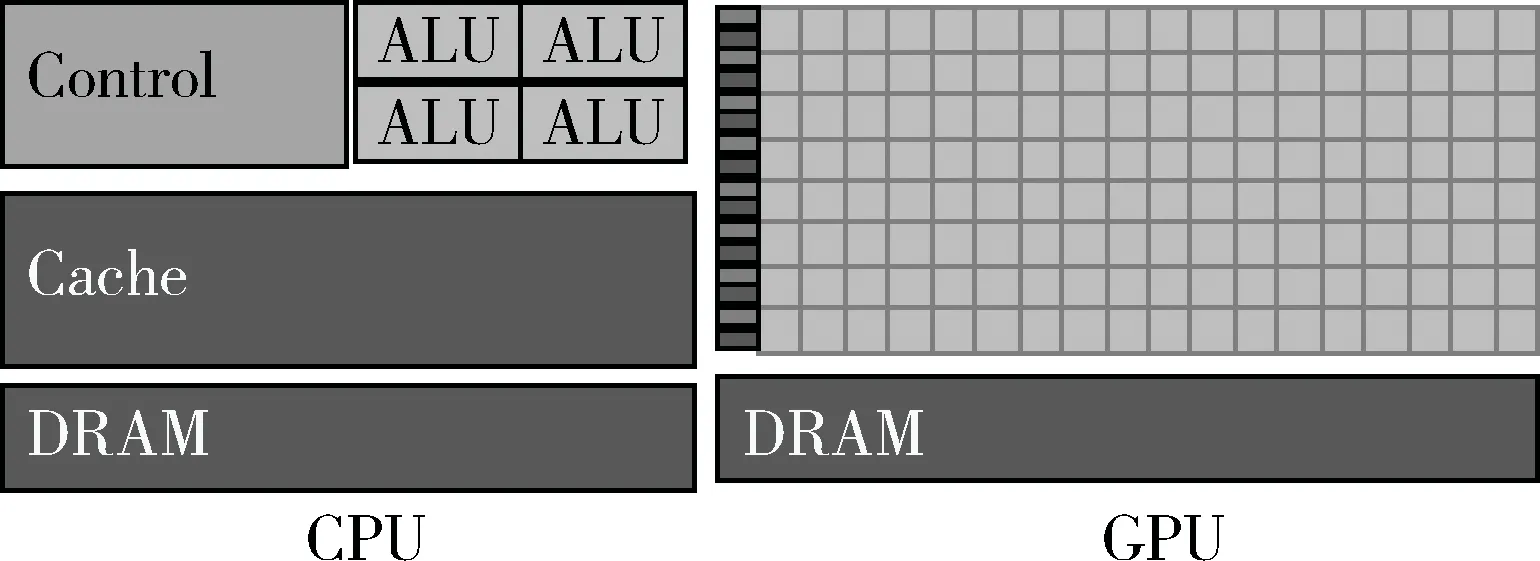
图1 CPU和GPU结构图
CUDA[3]是利用NVIDIA GPU的并行计算引擎以比CPU更高效的方式解决很多复杂的计算问题的通用并行计算平台和编程模型。
CUDA是可扩展的编程模型[4],这种模型允许GPU架构通过简单扩展多处理器和内存分区的数量包含价格不同的设备,如图2所示。

图2 CUDA平台扩展图
GPU是围绕一系列流式多处理器(SM)构建的。多线程程序被划分为彼此独立执行的线程块,因此具有更多多处理器的GPU比具有更少多处理器的GPU能在更短的时间内执行完程序。
1.2 CUDA编程模型
CUDA的C语言编程接口继承了C语言中定义函数的方式来定义kernel,它不像C语言的函数只执行一次,而是由N个不同CUDA线程并行执行N次。一个kernel的定义由_global_声明符号和CUDA线程数组成,线程数由特定的kernel调用通过使用<<<…>>>中的执行参数配置。每一个执行kernel的线程拥有唯一特定的thread ID,它在kernel内部可通过访问内置的threadIdx变量得到。
threadIdx是一个三分量的向量,因此线程可以被一维、二维或者三维的线程索引所识别,形成一维、二维或者三维的线程块。这提供了一种自然的方式调用向量、矩阵或者张量中域的元素进行计算。线程的索引和线程ID对应关系:对一维而言,它们相同;对大小为(Dx,Dy)的二维块,线程索引为(x,y)的线程ID为(x+yDx);对于大小为(Dx,Dy,Dz)的三维块,线程索引为(x,y,z)的线程ID是(x+yDx+zDxDy)。块中线程数目是有限制的,因为块中每个线程需要驻留在同一处理器核上并且共享有限的内存资源,在目前的GPU上线程块最多包含1 024个线程。然而,每个kernel能够执行多个同形状的线程块,所以总线程数目是块数乘每块的线程数。
线程块需要独立执行:能够以任何顺序、并行或串行执行它们。这种独立性要求允许线程块以任意顺序在任意数目的核上进行调度,使程序的代码能够具有在核数目上的扩展性。同一个块内的线程通过共享内存、数据和同步它们执行协调内存访问实现合作。在kernel中同步的位置需要指定_syncthreads(),_syncthreads()作为一个块内所有线程允许继续执行前等待的阻塞点。为了协作的高效,共享内存应该是靠近每个处理器核的低延迟存储器(类似L1 cache),_syncthreads()应该是轻量级的。
1.3 TensorFlow介绍
TensorFlow是一个用于研究和生产开发的开源机器学习库。TensorFlow运行时是一个跨平台的库,架构如图3所示。

图3 TensorFlow架构图
Client:定义计算的数据流图,使用session构建图的执行。Distributed master:从图中修剪由Session.run()中的参数定义特定的子图,将子图拆分成多个部分,它们运行在不同的处理器和设备上;分发图的各部分给work services,通过work services启动图各部分的执行。Worker Services:使用合适可用的硬件(CPUs、GPUs等)的内核实现调度图运算的执行;发送和接收运算结果给其它work services。Kernel implementation:执行单个图操作的计算。
TensorFlow中的op由kernel实现,GPU的内核由两部分组成:OpKernel和CUDA内核以及启动代码。
TensorFlow这一框架定义和运行涉及张量的计算。张量是矢量和矩阵向可能更高维的泛化。TensorFlow在内部将张量表示为基本数据类型的n维数组。TensorFlow程序主要的操作和传递的对象是张量,一个张量对象表示部分定义为会最终产生值的计算。TensorFlow程序工作时首先要构造一个图的张量对象,每个张量的计算细节基于其他可用的张量和运行该图的部分以获得所需的结果。张量具有两个属性:数据类型和形状。张量中的每个元素都具有相同的数据类型,且该数据类型是已知的,形状,张量的维数和每个维度的大小。
TensorFlow中的变量是程序操作共享和持久状态的最好方式。通过tf.Variable类对变量进行操作。tf.Variable相当于一个张量的值,可以通过在其上运行ops进行改变。不同于张量对象,变量存在单个session.run调用的上下文之外。一个tf.Variable可以存储一个持久的张量,特定的ops可以去读取和修改张量的值。这些修改在多个tf.Session间是可见的。
TensorFlow使用数据流图表示计算中独立运算间的依赖。在低级别的编程模型中首先定义数据流图,然后创建TensorFlow中的session在一组本地和远程设备上运行图的各部分。数据流图是一种用于并行计算的常见编程模型。在数据流图中,节点代表着计算单元,边代表着计算消耗或产生的数据。数据流带来的优势:并行处理,通过使用明确的边代表运算间的依赖,这样便于系统去识别能够并行执行的运算;分布式执行,通过明确的边代表运算间流动的值,TensorFlow能够将程序划分到不同机器的不同设备上,它在设备间添加必要的通信和协调;编译生成高效代码,TensorFlow的编译器使用数据流图生成还行更快的代码,例如将相邻的运算融合在一起;可移植性,数据流图描述的模型不依赖于语言。
tf.Graph包含两类相关信息:图结构和图集合。图结构信息主要包含图的节点和边,表示各个运算如何组合在一起,但不指定它们该如何被使用。图集合信息,TensorFlow提供一种用于存储tf.Graph中的元数据集合的通用机制。
1.4 K-means算法
K-means算法[5-9]把簇的形心定义为簇内点的均值。算法的处理流程如下。首先,在数据集D中随机地选择k个对象,每个对象代表一个簇的初始均值或中心。对剩下的每个对象,根据其与各个簇的中心的欧式距离,将它分配到最相似的簇。然后,k-means算法迭代地改善聚类结果。对于每个簇,它使用上次迭代分配到该簇的对象,计算新的均值。然后,使用更新后的均值作为新的簇中心,重新分配所有对象。迭代继续,直到分配稳定,即本轮形成的簇与前一轮形成的簇相同。
用于划分的k-means算法,其中每个簇的中心都用簇中所有对象的均值来表示。
输入:
k:簇的数目;
D:包含n个对象的数据集;
输出:k个簇的集合;
方法:
(1)从D中任意选择k个对象作为初始簇的中心;
(2)repeat;
(3)根据对象到簇中心的距离,将每个对象分配到最相似的簇;
(4)更新簇的中心,即重新计算每个簇中对象的均值;
(5)until不再发送变化。
1.5 基于TensorFlow的K-means算法优化
K-means算法计算量主要体现在计算数据集中对象到簇中心的距离和更新簇中心两步,通过提高这两步的并行化进而优化算法[10-12]。
由于硬件结构的不同,GPU比CPU更擅长并行计算,在GPU设备上执行并行计算,算法性能会更好。英伟达厂商提供了CUDA计算平台,它是一种通用并行计算框架,方便开发人员使用GPU解决复杂计算问题。英伟达为了深度学习框架提出了cuDNN,是用于深度神经网络的GPU加速原语库。TensorFlow通过cuDNN和CUDA实现GPU计算,TensorFlow平台提供的编程模型和编程接口比CUDA平台更容易理解和使用。TensorFlow的编程接口表达能力强,使GPU计算更简单且无需关注CUDA编程多线程并行的细节。TensorFlow描述的模型与语言无关,具有更好的移植性,架构灵活,支持分布式。
在传统的串行的K-means算法中,每个对象要计算k(簇数目)次,才能得到各簇的中心距离。在TensorFlow中,通过将数据集转化为张量,然后重构张量用于计算距离,在新的张量中,数据集中的每个对象出现k次,相应的各簇中心的重构张量中,簇中心的每个对象出现n(数据集中记录数目)次。求数据集中记录到簇中心的距离,转化为对两个张量的计算,便于算法并行执行,提高性能。
根据划分的结果重新计算各簇的中心,簇的划分结果由距离张量分组返回最小的索引,根据划分结果计算簇各属性的和,统计各簇中元素的数目,从而求得簇中对象的均值。
基于TensorFlow的K-means算法的主要步骤:
输入:
k:簇的数目;
D:包含n个对象的数据集。
输出:k个簇的集合。
方法:
(1)从D中任意选择k个对象作为初始簇的中心;
(2)将数据集和簇中心转为张量;
(3)调整数据集张量(记录数,属性数)和簇中心张量(簇数目,属性数)形状,得到它们的重构张量,形状为(记录数,簇数目,属性数);
(4)repeat;
(5)通过数据集和簇中心的重构张量计算距离,分配对象到距离最小的簇;
(6)根据分配簇的结果张量和数据集张量,更新簇中心,重新计算簇中对象的均值;
(7)until不再发送变化。
算法的整体流程图如图4所示。

图4 K-means优化算法流程图
2 实验与分析
本文实验所使用的数据集是美国人口普查数据集,该数据集包含大量人口普查数据,数据中的元素维度为69,每个对象拥有68种属性,每个维度的数据类型是整型。
2.1 实验环境
本实验平台为Intel(R) Core(TM) i7-8750H CPU,系统内存为16 GB,GeForce GTX 1050 Ti,显存4 GB,显卡计算能力6.1,CUDA 9.0,cuDNN 9.0,TensorFlow 1.12.0。
2.2 实验结果
实验设置聚类中簇的数目k为8,由于簇中心的对象初始是随机的,导致聚类收敛即算法的迭代次数不确定。为了避免迭代次数不同对实验产生影响,选取算法执行迭代时间的平均单次时间为实验对象。实验分别在Python环境中使用CPU计算运行普通的K-means算法,在TensorFlow环境中使用CPU计算运行优化的算法,在TensorFlow环境中使用GPU计算运行优化的算法。实验结果如表1所示,其中数据集记录数目分别为:1万条、5万条、10万条、50万条。每项数据是通过运行10次算法求均值得到的结果。
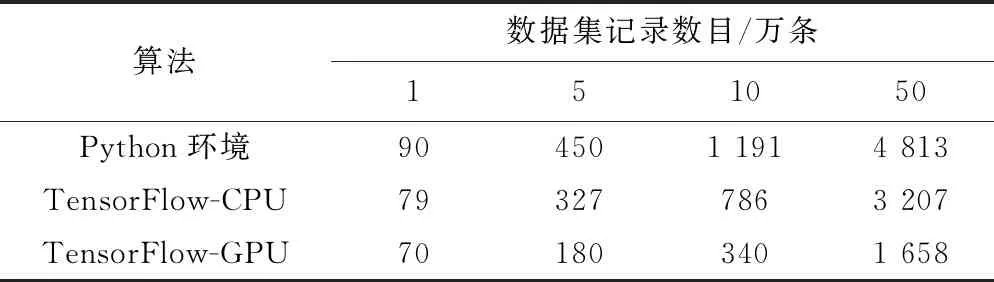
表1 算法运行时间比较(ms)
由实验结果分析,GPU的架构比CPU更适合处理并行任务,本实验环境中的CPU是多核的,因此具有一定并行计算能力,单次计算速度CPU也比GPU快。当数据集不大的情况下,GPU计算速度并未有明显优势,随着数据量增大GPU的优势也开始明显增大。使用相同的计算设备,TensorFlow编程模型更利于程序执行的并行化。
3 结论
本文在经典的K-means算法的基础上,利用GPU擅长并行计算的特性,研究基于TensorFlow的K-means算法。该算法能有效地处理大规模数据集的聚类问题,利用张量运算的思想加速了距离和簇中对象均值的计算,进一步提高算法的并行化。TensorFlow简化基于GPU编程,有良好的移植性,能够在不同平台上运行和使用不同的计算设备。TensorFlow架构支持分布式,分割描述算法的计算图得到的子图能够在不同设备上执行。通过实验证明该方法可以充分利用GPU的特性,有效加速K-means算法,缩短算法的运行时间。
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
现代电子技术(2022年8期)2022-04-13
科技信息·学术版(2022年8期)2022-02-25
体育科技文献通报(2022年1期)2022-01-15
昆明医科大学学报(2021年10期)2021-12-02
小猕猴智力画刊(2021年6期)2021-08-05
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
北华大学学报(自然科学版)(2020年6期)2021-01-05
作文大王·低年级(2016年3期)2016-03-11
中学理科·综合版(2008年3期)2008-03-07
