
基于自然语言处理的多源情报分析系统的研究与设计
2019-05-27 06:11刘旭东苏马婧朱广宇
网络安全与数据管理 2019年5期
刘旭东,苏马婧,朱广宇
(华北计算机系统工程研究所,北京 100083)
0 引言
如今世界各国都在大力发展自身的综合实力,尤以信息技术为最。随着人工智能时代的到来,许多国家都把情报工作的地位提高到了前所未有的高度,身处大数据环境下,无所不在的信息每分每秒都在产生数据,世界各国的用户无时无刻不在产生海量信息的交互,数据量已经呈现一种爆炸的状态。这些体积大、类型多的数据中有许多高价值的信息,关键在于能否及时发现并做出相应的决策,因此谁掌握了数据谁就掌握了先机。
同样,正因为这些非结构化数据中包含了大量的情报,例如某些社交软件与论坛中难免出现一些危及社会安定、公共安全的信息。而这些信息并没有想象中那么容易分辨,其中常常有一些“行话”,比如“猪肉”常被暗指毒品。传统文本分析很难对具有该性质的文本进行准确的分析。因此,收集和分析来自网络的大量评论需要使用文本相似度和情感倾向分析技术,掌握这些信息对于有关部门在提前预警、降低风险、提高应变能力、打击违法犯罪、维持社会安稳等方面有着很大的辅助作用。
不可否认的是,情报分析在大数据时代也面临着非常严峻的挑战。第一是如何准确稳定地获取情报信息,第二是情报信息的分析与可视化,在数据量激增时如何维持信息的利用程度,是目前情报分析面临的一大难题。
1 研究现状
情报分析研究分为科技文献研究、专业研究、综合研究三个主要阶段。情报分析方法包括逻辑学方法、数学法、系统分析方法、社会学方法、情报学方法和经济学方法等[1]。本文针对海量文本中关键情报的提取分析,主要使用了文本相似度分析及情感倾向分析。
目前,文本相似度计算的方法越来越丰富,情感倾向分析的效果取得了一定进步。Zhang Shunxiang等[2]实现了一种基于情感字典的方法来更好地支持网络监管工作。王春柳[3]等人从表面文本相似度计算方法、语义相似度计算方法两方面进行研究分析,对最新成果进行了归纳总结。GOVINOARAJAN M[4]提出了一种混合遗传算法与朴素贝叶斯的方法来进行情感分析,也取得了不错的效果。李青松[5]认为基于传统机器学习进行情感分析也是目前主流的方法,此类方法可以对多种特征建模并进行分类。通过在大量的语料库上进行训练,最终输出的模型不仅能够提取出特征词之间的关系,而且能够考虑到文本中随机词和词共现的影响。
但如今面向多源非结构化的海量文本,仅仅依靠一种方法来对其进行分析难以精确提取出更为深层次情报。为了更好地解决这一问题,本文从数据的获取、聚类、分析以及展示层面,提出并设计了一套流程化的多源情报分析系统,为当今情报分析提供一定的支撑。
2 系统分层模型
情报分析是情报工作的核心环节,而内容分析作为最为直观的表现形式,具有直观的说服力。本系统建立在充足数据的基础上,运用前沿的深度学习方法,通过管理筛选、综合分析、推理对比等逻辑设定,使文本信息内容的分析系统化、综合化、准确化,并形成多种类型的情报成果,为有关部门提前预警、有效打击违法乱纪行为提供有力支撑。
完整的情报分析系统的体系结构模型采用分层设计,由下到上依次是数据层、业务逻辑层、界面展示层,如图1所示。

图1 情报分析系统体系结构模型
(1)在数据层,确定研究对象,包括分析目标、情报搜集与采集样本。
(2)在业务逻辑层,一是制定标准,构建语料库、停用词典等;二是编码,将采集到的文本数据转化成文本向量;三是数据分析,使用自然语言处理相关的技术对文本向量进行处理,实现相似文本的推送、文本情感倾向的分析。
(3)结果分析,将上一步得到的分析结果在界面展示层进行相应的可视化。
接下来对各模块用到的核心技术进行详细阐述。
3 主要技术
自然语言处理的基础是各类自然语言处理数据集,如tc-corpus-train(语料库训练集)、面向文本分类研究的中英文新闻分类语料、以IG卡方等特征词选择方法生成的多维度ARFF格式中文VSM模型、用于非监督中文分词算法的中文分词词库、UCI评价排序数据、情感分析数据集等。
本文通过运用深度学习与其结合的方法对数据源的文本进行了较为透彻的分析。
3.1 文本相似度分析
目前比较常用的相似度分析方法是TF-IDF(Term Frequency-Inverse Document Frequency)和BM25(Best Matching 25)算法,用TF-IDF模型计算普通的文本相似度分析效果已经比较可信,但是在实际的中文文本里,用TF-IDF表示的向量维数可能是几百、几千数量级,不易分析计算。GUAN W提出一种基于VSM的改进文本相似度算法[6],JIAO Y提出基于树结构的文本内容相似度计算[7]。此外一些文本的主题或者说中心思想并不可能完全地通过文本中的词来表示。Bm25算法通常用来作搜索相关性评分,通过使用不同的语素分析方法及相关性判定方法来衍生出不同的相关性得分计算方法。而LDA(Latent Dirichlet Allocation)模型有效地解决了文本挖掘中的特征稀疏和分类性能受损问题,文本相似度分析基于LDA模型获得了比较好的效果。
LDA主题模型是由BLEI等人提出的,其中“文本—主题—词”LDA基于贝叶斯模型,模型图如图2所示。
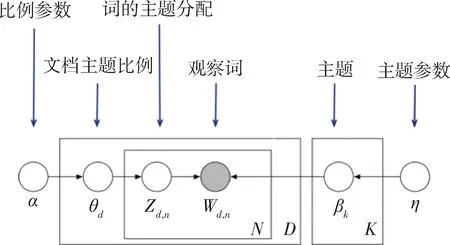
图2 LDA模型
假设有M篇文本,对应第d个文本中有Nd个词,即输入如图3所示。

图3 输入
为了找到每一篇文本的主题分布和每一个主题中词的分布,LDA假设文本主题的先验分布是Dirichlet(狄利克雷)分布,即对于任一文本d,其主题分布θd为:
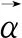
LDA假设主题中词的先验分布是Dirichlet分布,即对于任一主题k,其词分布βk为:

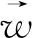
核心算法如图4和表1所示。

图4 核心算法伪代码

LDA算法算法输入:分词后的文本内容集(一般一篇文本一行)话题数K,超参数α和β算法输出:1.每个文本的各个词被指定的话题编号:topic.txt2. 每个文本的话题概率分布θ:theta.txt3. 每个话题下的词概率分布Φ:varphi.txt4. 程序里词语WORD的映射表:map.txt5.每个话题下Φ概率排序的TOPN特征词:topn.txt
3.2 情感倾向分析
目前常见的情感倾向分析方法主要有两种:基于情感词典的方法和基于机器学习的方法。前者存在着非常明显的缺点与局限性,比如段落的得分是其所有句子得分的平均值,这一方法并不符合实际情况;其次,有一类文本使用贬义词来表示正向意义,尤其是在含有重要情报信息的文本中,如果使用情感词典来判断会出现与实际不相符的结果。ALSAQER A F等人提出了一种使用RapidMiner运算符的方法进行情感分析,一定程度提高了准确率[8]。使用深度学习的方法能更为有效地解决这类问题。
3.2.1 数据预处理
对数据库中所有的评论进行分词并去除停用词。因为模型的输入需要的是数据元组,所以需要将每条评论的词语组合转化为一个数值向量。目前常见的转化算法有Bag of Words、TF-IDF、Word2Vec。Word2vec能快速构建词语的词向量形式,词向量的每一维的值代表一定的语义和语法上解释的特征,其核心框架包括CBOW和Skip-gram两种训练模式,CBOW依据上下文决定当前词出现的概率,但短文本上下文信息缺失,此模式不适用。Skip-gram采用跳跃组合的方式学习词项规则,更能适应短文本特征稀疏的需要[9]。
核心代码如下:
def Word2Vecs(content):
vecs = []
for ct in content:
ct = ct.replace(' ','')
try:
vecs.append(model[ct])
except KeyError:
continue
return np.array(vecs,dtype='float')
3.2.2 构建模型
本系统使用的是Naïve Bayes SVM(Support Vector Machine)+PCA(Principal Component Analysis)来构建模型,SVM分类表现更为宽松,且使用PCA降维后模型表现有明显提升。
等式左边代表的是一条评论的极性类型,P(cj)指该极性类型出现的概率,ΠP(wi|cj)指在当前极性条件下文本中各个词出现的概率的乘积。
其中V就是当前训练文本的词汇量。
系统该模块的流程图如图5所示:

图5 流程图
将语料进行分词后转化为向量并对结果进行标准化和PCA降维后,经SVM模型训练,得到P(positive)、N(negative)、C(confidence)三元组信息。
4 实验结果
在微博、推特上各筛选了2 000条评论,Tor上则选取了6 000条具有“行话”性质的评论文本用来测试,如表2所示。

表2 评测样本数据集
常用模型的文本相似度计算的准确率对比结果如图6所示。

图6 常用模型文本相似度对比图
从测试结果可以看出,Naive Bayes在文本相似度计算中取得的效果并不令人满意;而TF-IDF则是中规中矩,但对于这些具有特定主题的文本的中心思想不能非常准确地反映;LDA模型很好地弥补了这方面的缺点,能更加精确地返回与话题最为相似的文本,取得了比较好的效果。
情感倾向分析结果如图7所示。

图7 分析结果

表3 特征选择对比
从表3不难发现,在Naïve Bayes+SVM模型中,特征选择的三种技术对于微博、推特、Tor的数据集来说,Binary TF和TF-IDF在情感倾向分析特征选择上的效果有所不足,而Word2Vec因其神经网络的性质对于最终训练出来的权重矩阵有着更好的效果,对于准确把握文本情感倾向起到了关键的作用。
实验证明该系统的设计方法对情报信息的获取、分析有较好的效果。
5 结论
文本相似度和情感倾向分析是自然语言处理中的一些基础性研究,有着比较悠久的历史,近年来随着深度学习神经网络的发展,各个模型的性能都得到了一定程度的提高。
目前的研发成果可以表明,运用自然语言处理的方法计算文本相似度及情感倾向分析在一定程度上可以辅助情报分析人员进行数据的存储、清洗、处理、分析和结果展示。对于情感分析来说只是仅仅完成情感极性的一个分类、语法分析的任务,本文构建的专用于行话信息的语料库在正负面情感分析上取得了较为满意的效果。但是如何做到让机器对人类情感进行深入细腻的把握和分析,甚至是让机器模仿、创造出人类的情感并与人类进行情感交互是情感分析领域需要更加深入研究的问题。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
小学生学习指导(低年级)(2021年12期)2021-12-31
中国生殖健康(2020年5期)2021-01-18
甘肃教育(2020年8期)2020-06-11
艺术评论(2020年3期)2020-02-06
小太阳画报(2019年10期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
中华诗词(2018年9期)2019-01-19
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
