
应用于课堂场景人脸验证的卷积网络方法研究
2019-05-27 06:12吴江林刘堂友
网络安全与数据管理 2019年5期
吴江林,刘堂友,刘 钊
(东华大学 信息科学与技术学院,上海 201620)
0 引言
高校的课堂考勤严重挤压了实际上课时间,考场人员审核考生身份增加了监考人员的工作量,且容易出错,如果把人脸识别的技术应用于课堂、考场,则学生考勤、考生身份识别都可以用监控摄像头和后台计算机自动实现,因而具有巨大的优势。近几年,深度学习在不同的技术层面都取得了明显的突破,在计算机视觉中,卷积神经网络不需要人工建立特征,通过非线性模型自主学习图片特征,因而基于深度学习的人脸图像分类技术应用于课堂考勤、考生身份识别完全可行,本文正是针对这一问题进行研究。
课堂点名和考生身份识别主要侧重在人脸验证,也就是判别待核实身份与登记身份是否为同一人的过程,人脸识别是预测待判别人脸是谁的过程。然而,人脸识别与验证容易受姿势、光照、表情、遮挡等环境因素的影响,学到能够分辨不同学生的判别性特征是建立模型的目标。
在人脸视觉领域,比较典型的研究有:文献[1]建立若干层的卷积网络结构,使用3D人脸矫正等预处理方式,将图片分类输出的前一层的全连接层作为固定长度的人脸特征向量。香港大学团队[2-4]提出了一系列人脸图片分类模型——DeepID系列,DeepID1[2]是基于四层卷积网络,损失函数前一层为学习到的图片特征向量,采用多任务分块学习方法,将每个模型训练得到的人脸特征表达拼接组合成一个高维的身份特征向量,称之为DeepID向量;DeepID2[3]在原先基础上增加了验证和识别信号,使特征更具判别性;DeepID3[4]建立两个深层的网络模型。谷歌[5]用三元组损失函数替代原始损失函数,在超球面空间优化参数,人脸特征表达向量的维度简化为128维。三元组对样本有一定的要求,后续的学者都在损失函数上进行创新性改进,在目标函数上添加了一个特征类中心,使学习到的特征靠拢所属的类中心[6]。为学习到判别性特征,有文献直接对损失函数做了改进,通过人为加入一个间距来提高学习的难度[7],归一化了权重[8],对样本进行归一化处理[9]。
1 模型设计框架
应用于人脸识别或人脸验证需要三个模块。首先,人脸检测用于定位图像或者视频中的人脸;其次,使用关键点检测,基于各关键点坐标人脸对齐;最后建立图像分类模型。人脸图像分类架构如图1所示。
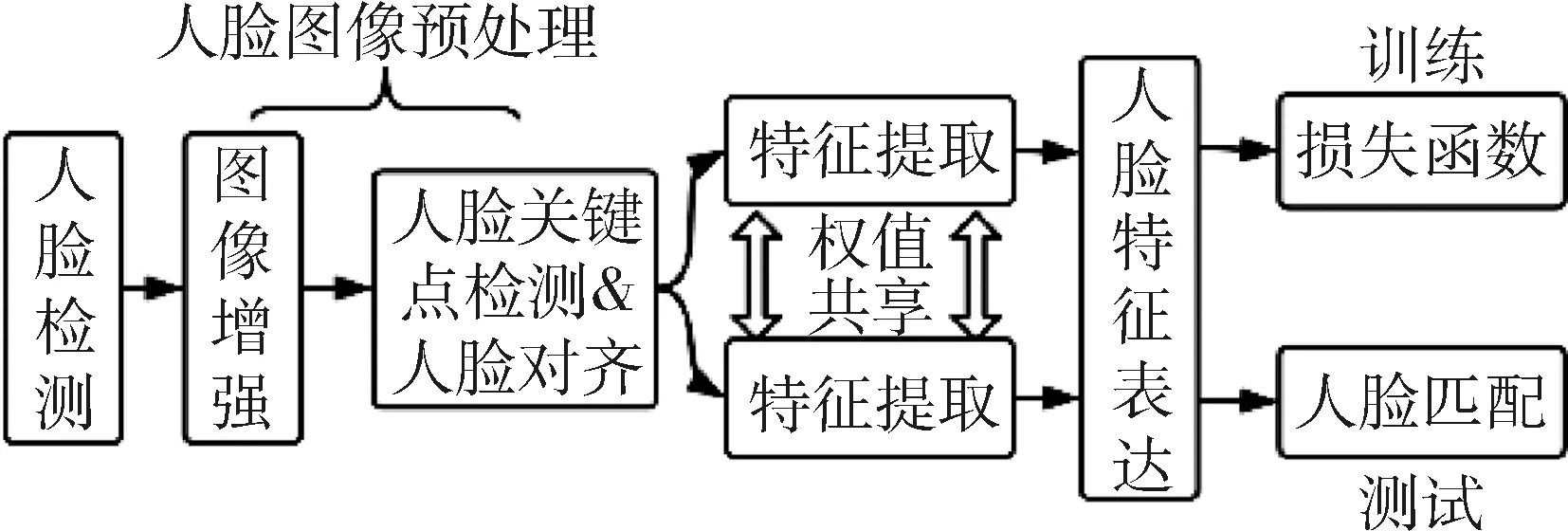
图1 人脸图像分类架构
本文采用文献[1]中的学习思想,搭建若干层卷积网络,将图片分类输出的前一层全连接层作为身份的特征向量。本文建立了两个模块:卷积模型和残差网络模型。
1.1 卷积模型的搭建
在采集到的数据样本数量条件不够充足的时候,可先设计一些轻量级的卷积模型。本文中的卷积模型含有四个卷积模块,卷积模块结构如图2所示,包含以下结构。
卷积层(Convolution Layer):用来对上一层的特征图(feature map)进行特征提取,卷积的过程为输入的特征图与卷积核在对应位置相乘并且求和,最后加上偏置项,输出新的特征图。
批量归一化(Batch Normalization,BN):随着网络的深度加深,在训练过程中,数据分布逐渐发生偏移与变动,导致网络收敛变慢,批量归一化通过一定手段把输入值分布规范到正态分布,使激活值落入非线性函数的敏感区域,提高收敛速度。
激活函数:这里采用线性整流函数(Rectified Linear Unit,ReLU)作为激活函数:f(x)=max(0,x)。激活函数的作用是激活神经元,通过函数保留并映射特征,去除数据冗余,使得到的特征图在高维空间保持一定距离的判别性,这使神经网络能够解决非线性问题。
最大池化层(Max Pooling):在卷积层之后,通过池化层来降低卷积层输出的特征向量,使特征图变小,不容易出现过拟合。

图2 卷积模块
叠加四个卷积模块,第一个卷积模块中的卷积核数量为32,第二个为64,第三个为128,第四个为128。连接1 024×1、512×1和128×1的三个全连接层。最后一层的128×1维的向量视作人脸身份特征向量表达,总体卷积模型如图3所示。

图3 总体卷积模型
1.2 残差网络模型的搭建
随着数据集增多,加深网络层数可以在高层次网络中学习更复杂的特征。但是网络的加深容易造成梯度弥散和网络退化,使得网络正确率逐渐饱和或者下降,梯度下降的过程受到阻碍,网络优化的过程变得缓慢。残差网络(ResNet)使用残差学习的方法解决梯度退化的问题,使得网络的层数得到提升。
残差网络使用了捷径(shortcut)模块,主要思想是把需要学习逼近的映射函数H(x)恒等映射,变成学习逼近F(x)=H(x)-x。捷径模块分为两种,分别为恒等模块(identity block)与填充映射的卷积模块(convolution block),恒等捷径模块为零填充,如图4(a) 所示;卷积模块填充特征映射,如图4(b)所示。
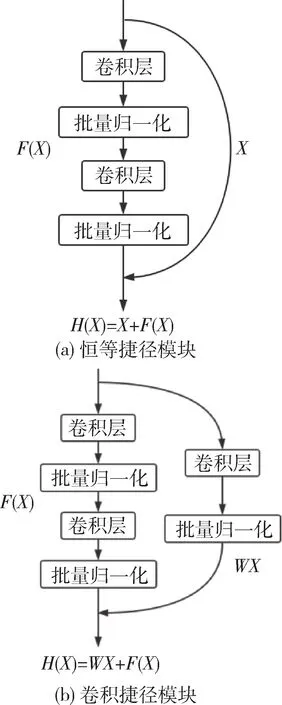
图4 捷径模块
残差网络模型由恒等捷径模块与卷积捷径模块组成,参数与卷积模型相似,残差网络模型如图5所示。

图5 残差网络模型
2 目标损失函数的选择
为了让模型学习到更具有判别性的特征,提高模型的泛化能力,还需要让模型有意识地去学习困难样本,如果采用谷歌的三元组[5]方法,可能会产生样本爆炸的问题,在随机选取三元组时不一定会遍历所有的样本,而且对于怎么选取困难样本形成三元组是一个难题,所以,在一些非海量数据集上,可以根据文献[9]的思想,通过修改目标函数约束模型的优化方向。
一般来说,第i类的损失函数为:
(1)
那么,损失函数为:
(2)
将偏置项设为0:
(3)


但是,在分类样本与训练网络参数权重时,更希望人脸表达映射到高维空间中的同时,能够让不同类别的人脸特征更具有判别性,更加紧凑。通过修改目标函数[7-9],在非海量级数据,也可以训练出紧凑的人脸特征表达。
2.1 加入余弦间距
将原本的cosθ变成cos(mθ),这里的m为整

(4)
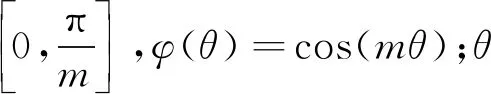
2.2 权重归一化
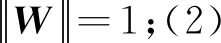
(5)
也可以写成:
(6)
其中,φ(θyi,i)=(-1)kcos(mθyi,i)-2k。
从几何意义上来说,权重W归一化,意味着将W映射到单位超球面的表面,在训练过程中,同一类会向各自球表面的类中心逐渐聚拢,m控制类的密集程度。式(4) 是对权重长度和角度都进行优化,这样损失函数在优化时没有只精准地优化角度,而式(6)明确是以只优化角度为目标,仅从角度上区分类别。
2.3 特征归一化


(7)
也可以写成:
(8)
其中,φ(θ)=cosθ-m。
特征的归一化会使网络注意那些图像质量差的人脸图片,类似于困难样本挖掘,也一定程度上避免了模型的过拟合。
3 实验与分析
3.1 图像采集与图像预处理
实验样本通过教室内的摄像头录像采集,在视频流中随机抽取大场景图片,通过OpenCV函数库中的级联检测器进行人脸检测,对检测后的图片进行分类,分类后的图片分别存至以学号命名的文件夹,一共含有60个学号的人脸图像文件夹,每个学号文件夹有500张照片,统一将图片格式规定在128×128的RGB图像。
在建立模型之前,需要对图像进行一定的处理以提高图片的质量。图像处理方法有直方图均衡、锐化、增强图像对比度等。直方图均衡可以减弱光照的影响,增强锐化可以增强图像纹理细节。针对人脸角度变化过大,通过开源函数库dlib进行人脸68个特征点检测,基于关键点进行人脸对齐。
3.2 实验参数设置
实验采用随机梯度下降(Stochastic Gradient Descent,SGD)算法进行参数优化,学习率采用随着迭代轮数增加学习率动态衰减的方法,初始学习率设置为0.05,设置单个学习批次为64。两个模型都使用式(8)作为损失函数,其中根据文献[9],设置缩放因子参数s=30,控制类内间隔参数m=0.4。
在不同数量的图像集上对模型效果进行评估,图像集A为60位学生,每人500张图片,共30 000张图片;图像集B是在图像集A中,每人随机抽取50张图片,共3 000张图片。图像集A迭代30次,大约迭代10次就可以达到收敛状态;图像集B迭代100次,大约迭代30次可以达到收敛状态。使用正确率与F1分数作为评估标准。
人脸验证采用余弦相似度计算,人脸验证阈值设置为0.5,两张图片通过模型计算得到两个人脸特征表达向量,两个向量经过余弦相似度计算,若结果大于0.5,则认为是同一人,否则认为是不同的人。人脸验证阈值是人为设定参数,在图像环境好的场所,可以提高人脸验证的阈值,人脸验证要求可以更加严格;在图像采集环境比较差的情况下,可以降低人脸阈值,放宽人脸验证要求。
3.3 实验结果与实验分析
图6(a)、(b)为在数据集A上两个模型的结果,可以看出卷积网络和残差网络都可以达到不错的效果,残差网络模型准确率为99.97%,卷积模型准确率为99.93%,在充足一点的数据集中,残差网络模型比卷积模型准确率更高一点。残差网络比卷积网络更快收敛,残差网络模型可以解决梯度弥散,让梯度得到更有效的衰减更新,收敛更加快速。

图6 残差网络和卷积网络在大图像集上结果对比
图7(a)、(b)为图像集B的实验结果,残差模型正确率为98.78%,卷积模型正确率为98.89%,在小数据集中,卷积模型比残差模型准确率略高一点。在验证集中,可以明显看出图像集B没有图像集A的精度高,提高数据量一定程度上可以提升模型的精度。在数据量较少情况下,可以明显地看出卷积模型在收敛过程中有着更激烈的震荡,残差网络模型更稳定,依然保持更快速的收敛。

图7 残差网络和卷积网络在小图像集上结果对比
图8(a)、(b)为各个模型使用原始损失函数在图像集A的结果,模型训练迭代30次,残差网络模型结果的正确率仅为2.77%,卷积模型正确率仅为1.77%,模型不收敛。这是因为采集到的图像质量不高,同一类的图像内部差异很大,方差过高,很难收敛,原始的目标函数划定的是决策边界,它的目的是尽量提高分类的正确率,尽可能去拟合高质量图片,而忽略图像质量差的样本,而修改过的损失函数对特征归一化,低质量图像会产生较大的梯度,参数可以得到有效的更新,这就意味着修改过的损失函数会特地学习低质量的图像样本,促使模型能够快速收敛。

图8 两模型使用原损失函数在数据集A上结果
4 结论
本文通过摄像头采集图片,对图片进行图像增强与人脸对齐;基于课堂场景的人脸图像数据,设计了卷积网络图像分类模型与残差网络图像分类模型;同时,结合使用前沿的损失函数[9],训练紧凑的人脸特征表达;实验分析了两个模型在不同数量的图片数据集上的表现效果,对损失函数的作用进行实验分析,通过实验证实方法的有效性。后续工作可通过余弦相似度计算实现课堂场景人脸匹配。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
