
基于Faster RCNN的手势识别
2019-05-25 02:42何劼恺
桂林电子科技大学学报 2019年6期
郭 庆, 何劼恺, 金 焰, 许 金
(桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004)
在目标检测应用中,相比传统算法,深度学习目标检测不仅可以省去手动提取特征的过程,还具有效率高、精度高的特点[1],近年来在理论与应用研究方面得到了广泛重视[2]。
许多学者在RCNN(region CNN)算法的基础上不断优化精度及检测效率,推动了深度学习目标检测研究的不断深入。深度学习目标检测的发展如图1所示。从RCNN[3]发展到Mask RCNN[4],目标检测从选择性搜索发展到区域回归网络(region proposal network,简称RPN),通过RPN网络得到目标区域在特征图上的位置,使得算法可以集中处理有用部分[5]。Faster RCNN中增加了ROI Pooling,代替了传统的Max Pooling,使得算法可以输入不同的图片,同时也解决了RCNN中需要拉伸或压缩图片尺寸的问题[6]。Faster RCNN中的RPN不仅解决了选择性搜索所导致的低效率问题,还省去了手动提取特征的过程。Mask RCNN将ROI Pooling优化为ROI Align,解决了Faster RCNN不能按照整数块做池化的缺陷,同时增加了用于对图像作分割的掩码输出,提升了深度学习算法的精度[7]。

图1 深度学习目标检测的发展
Mask RCNN是以ResNet50/101、RPN、ROI Align为主干的网络结构[8],需要在6 GiB及以上显存的GPU上运行,而Faster RCNN采用的是以ZF Net或VGG-16、RPN、ROI Pooling为主干的网络结构[9],相对需要的参数较少,且在目标识别精度上无较大差异。由于硬件条件的限制,本研究采用Faster RCNN为手势目标检测的主要框架。
1 算法原理
1.1 Faster RCNN
Faster RCNN主要由深度全卷积网络和Fast RCNN检测器两部分组成。第一部分提供需要目标定位的区域,用于挖掘图像的深层特征信息;第二部分学习由第一部分提供的候选区域[10],分割图像,取出特征图中目标的信息,使得后续分类器在分类时可以充分学习目标的特征信息,解决了目标与背景造成的样本不平衡问题。Faster RCNN的网络结构如图2所示。

图2 Faster RCNN网络结构
ROI池化的具体操作:根据输入的图像将ROI映射到特征图上的对应位置;将映射后的区域划分为相同大小的部分,对每个部分进行最大池化的操作。由于ROI池化不限制输入的特征图的大小,保证了网络可以输入不同大小的图片,大大提升了网络训练的效率。
RPN由一个全卷积网络构成,其主要作用是图像分割。全卷层输出的特征图输入到RPN中,得到一群建议框的信息,为ROI池化做准备[11],如图3所示。RPN的主要目的是将网络的注意力调整到目标区域上,使得网络向目标所在的区域学习,从而提升整体网络在学习时的效率及识别准确率。RPN的输出即为分割后的特征图,用于输入下一层的ROI池化层。在每个滑窗位置,同时使用多个候选区域进行预测。因此,在进行目标查询之前,需要提前设置滑窗的大小,这里的滑窗大小即为候选区域的大小,与图像的尺寸有关,同时与需要定位的目标大小有关,设置的滑窗过大,可能导致损失值很难降下来,这种情况会导致欠拟合。
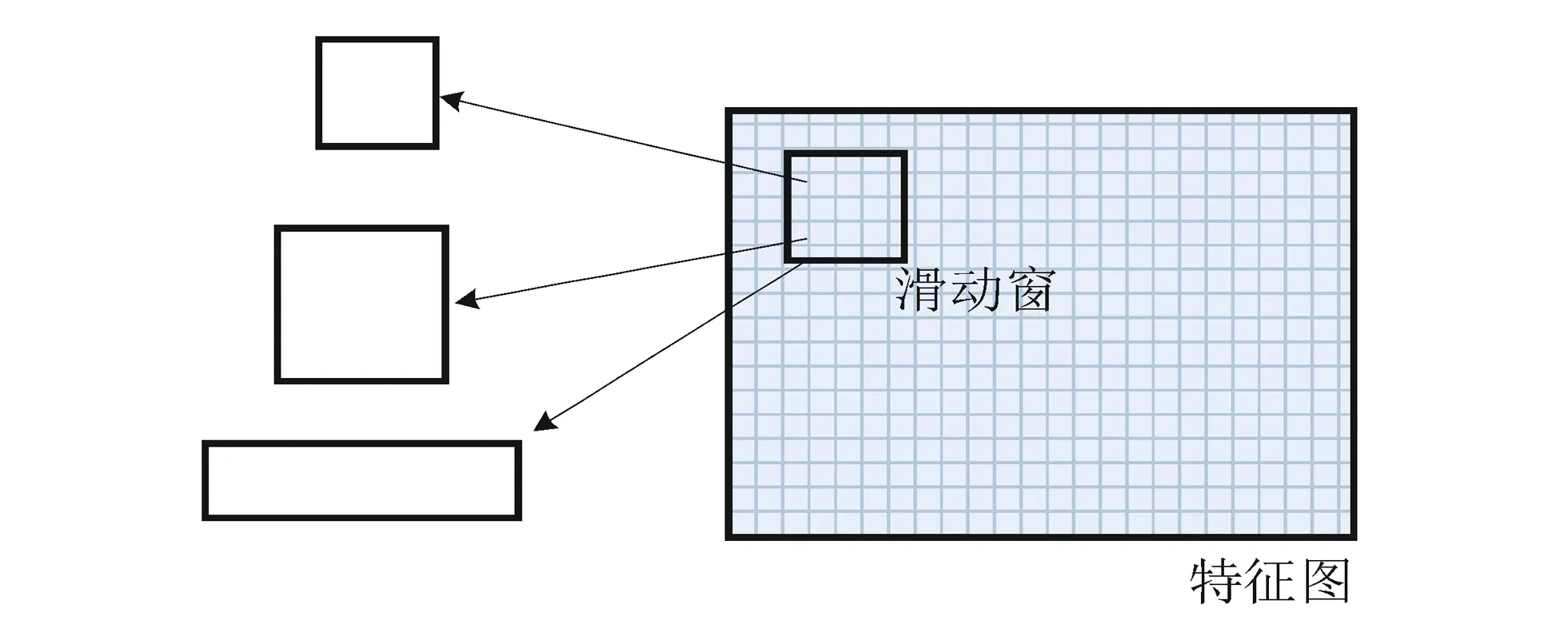
图3 RPN结构
RPN中采用的损失函数为
(1)

(2)
(3)
其中R为Smooth L1损失函数[12]。
RPN通过反向传播和SGD的方式端对端训练,对目标区域进行学习优化,从而降低无关背景对网络学习的影响。RPN中采用零均值偏差为0.1的高斯分布值作为初始值,其他卷积层采用预训练模型的参数值作为初始值,并通过微调的方式在手势数据集上做出调整。本研究在输入RPN之前的主干网络采用ZF Net。
1.2 非极大值抑制
深度学习在目标检测后会产生多余的候选框,需对多余的候选框进行消除处理,因此需要加入非极大值抑制(NMS)算法。非极大值抑制算法的加入可以找到最佳候选框,这些候选框的选择由置信度决定,通过置信度以及候选框之间的重叠面积筛选最后需要的候选框,如图4所示。

图4 NMS处理
2 基于FRCNN的手势识别
将Faster RCNN应用于手势识别中,流程如图5所示。

图5 手势识别流程
数据准备阶段包括:1)制作图片数据,将HandNet数据集划分为所需的训练集、测试集和验证集;2)制作标签,即手势在图中的位置。
采用的深度学习框架为Caffe,并在Caffe的基础上完成Faster RCNN编写。由于使用CPU运行深度学习较慢,在编写完成C语言程序的基础上完成Cuda加速,使得Faster RCNN能够更快地检测目标。Faster RCNN参数设置如表1所示。

表1 算法实施PC机主要性能参数
表1中,Anchor ratio为预设滑窗的长宽比,Scale size为实验图像中最短的边长,Max size为实验图像中最长的边长,Batch size为Faster RCNN在学习时批量学习的图片数量。设置Batch size可提高识别稳定性。
通过将图片输入到Faster RCNN,先经RPN给出目标候选框,再采用NMS除去多余的候选框,得到最优目标框,算法对最优框内的内容进行学习,摒除了无关信息的干扰。
3 实验和分析
在PC机及C++编程语言和CUDA环境下实现上述算法,算法实施平台性能主要参数见表2。

表2 算法实施PC机主要性能参数
测试的数据集为HandNet数据集[13],包含10名参与者的手在RealSense RGB-D相机前非刚性变形的深度图像。其中还包含了6D数据,用于描述手的中心及指尖的位置方向信息。数据均保存为.mat文件。HandNet数据集信息如表3所示。

表3 HandNet数据集信息
随机从HandNet中选取10 000张图片作为训练集,1 000张图片作为验证集,5 000张图片作为最后的测试集。将数据集分为5类(1-单指型手势,2-双指型手势,3-三指型手势,4-四指型手势,5-五指型手势)。根据图5,在深度学习Caffe的框架下测试基于Faster RCNN的手势识别系统。测试中只生成置信度在90%以上的候选框。部分测试结果如图6所示。

图6 深度学习检测结果
经过5 000张图片的测试,得到的测试准确率为99.14%,而SVM等传统手势识别算法识别准确率为96%左右[14],平均每张图片测试时间为44.19 ms。传统算法中平均每张图片的测试时间一般不低于1 s。因此,本算法较传统方法具有手势识别检测准确率高、检测效率高的优势。
4 结束语
通过采用Faster RCNN对手势目标进行定位,能够准确并迅速定位手势在图中的位置。通过对Faster RCNN网络参数的调整,提升了识别准确率。相较于传统算法,省去了手动提取特征的过程,提升了手势识别的泛化能力。相比传统算法,该算法对手势识别更快、更准确。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
计算机工程与应用(2022年1期)2022-01-22
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
计算机技术与发展(2020年2期)2020-04-15
红领巾·萌芽(2019年9期)2019-10-09
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
小学科学(学生版)(2018年12期)2018-12-19
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
火力与指挥控制(2018年3期)2018-04-19
