
一种KD树集成偏标记学习算法
2019-05-25 11:26:10卢勇全刘振丙颜振翔方旭升
桂林电子科技大学学报 2019年6期
卢勇全, 刘振丙,2, 颜振翔, 方旭升
(1.桂林电子科技大学 电子工程与自动化学院,广西 桂林 541004;2.桂林电子科技大学 计算机与信息安全学院,广西 桂林 541004)
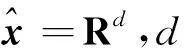
偏标记学习从本质上看是属于多类分类问题的特例。多类分类问题可以转换为构建多个二分类问题来解决。然而现有的一对多或一对一方式构建二类基分类器的算法中,很少考虑各个类别样本数目之间的极度不平衡问题,偏标记学习在处理标签问题上已经是个难题,加上类不平衡问题,则更加难以解决,且偏标记样本真实标签不可知,故该方法不能直接在偏标记学习中使用。做交叉验证时,有可能将类别少的数据集作为测试使用,从而导致此类别训练样本缺失,若运用标签划分数据集,则可能存在某类样本数为0的情况,忽略此极有可能导致算法崩溃。如Lost[4]数据集中存在一类仅有4个样本的数据,在算法中若不对此情况进行处理,会导致实验失败。鉴于此,提出一种KD树集成偏标记学习算法(ensemble K-dimension tree for partial label learning,简称PL-EKT),将样本候选标签所携带的信息和样本特征综合利用,构建多个二分类样本集,采用集成学习中Stacking的方法处理偏标记学习问题。
1 相关工作
偏标记学习的难度主要是由偏标记数据集的伪标签造成的[7],为此,学者们提出了一系列算法。最为直观的方法是对偏标记的伪标签进行操作,将样本的伪标签去掉,也称为消岐操作,即辨识消岐和平均消岐[8]。辨识消岐是将偏标记的真实标记作为隐变量,采用迭代的方式优化内嵌隐变量的目标函数实现消岐[8]。平均消岐是赋予偏标记对象的各个候选标记相同的权重,通过综合学习模型在各候选标记上的输出实现消岐[8]。在辨识消岐中,通过基于极大似然准则的方法优化参数,解决偏标记学习问题。文献[9]提出一种基于最大间隔偏标记学习算法(PL-SVM),通过模型在Si和非Si上的最大输出差异进行优化。文献[10]提出了一种新的基于最大间隔的偏标记学习算法(M3PL),直接优化真实标记与其他标记的差异。在平均消岐中,文献[11]提出一种代表性的惰性学习算法PL-KNN,类似KNN算法,通过距离度量的方式,根据示例的K个近邻样本进行投票预测。文献[12]提出了基于凸优化的偏标记学习算法CLPL,算法将问题转化为多个二分类问题,通过在二类训练集上优化特定的凸损失函数求解偏标记学习问题。
在解决偏标记学习问题上,也有非消岐策略的方法。如文献[13]提出的编码解码策略的输出纠错编码算法PL-ECOC,通过特定编码和解码方式实现二分类过程。在编码阶段,通过随机生成的列编码来划分样本正负集,从而构建二分类器;在解码阶段,让未见示例在二分类器上输出特定长度的码字,将最接近的类别作为测试样本的预测输出。PALOC算法[14]、CORD算法[15]通过集成多个分类器,运用模型投票的方法来解决偏标记学习问题。
KD树(K-dimension tree)是平衡二叉树,通过利用已有数据对K维空间进行切分[16-17]。KD树在进行检索时,以目标点为圆心,以目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部。然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否与超球体相交,若相交,就寻找是否有与该子节点更近的近邻,有的话就更新最近邻节点;若不相交,直接返回父节点,在另一个子树继续搜索最近邻节点。当回溯到根节点时,保存的最近邻节点就是最终的最近邻节点。
集成学习通过联合几个模型来提高机器学习效果[18]。与单一模型相比,这种方法可以很好地提升模型的预测性能。其中Stacking是一种通过元分类器或元回归器来综合几个分类模型和回归模型的集成学习技术。基模型基于整个数据集进行训练,元模型再将基模型的输出作为特征进行训练。
2 KD树集成偏标记学习
在训练阶段,通过充分利用样本的候选标签和样本特征所隐藏的信息,将样本分成正负类。其中,1表示正类,0表示负类。划分正负类数据集后,由于偏标记样本属多分类,一般情况下属于某一类样本的数量并不多,大部分是其他类别的样本。在初级模型训练阶段,为了使样本数量均衡,以小的样本数量为标准,允许在2倍内波动,当出现某一类样本极少时,利用KD树搜索找出特征相似的样本进行补充,保证正负两类样本趋于均衡。完成数据集的划分后,先训练出初级分类模型,再利用初级分类模型对样本进行预测并投票,将初级分类器的预测值加入到原样本中形成新样本。运用集成学习的Stacking方法,再次进行分类模型的训练,最终完成模型的训练。PL-EKT算法实现过程如下。
输入:D偏标记样本集
输出:根据式(8),返回x*的预测标签y*
1K:检索KD的最近K个样本
2x*:未见示例
3 输出y*:样本x*的预测标签
5 训练初级分类器Hab←β(D)
6 根据式(6)预测标签,根据式(7)形成新特征并加入
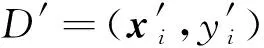
在预测阶段,利用初级分类模型对未见样本进行投票,将投票结果作为新特征加入未见示例中,最后将加入了新特征的未见示例进行最终预测。
按照标签1、0,根据
(1)
(2)
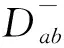
(3)
Dab={T(x1)∪T(x2)…∪T(xk)}
(4)
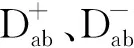
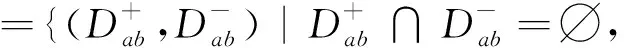
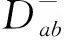
(5)
其中lmax和lmax为设置的样本数目阈值范围。
数据集均衡化过程如下:
1)根据式(1)划分样本;
2)根据式(2)处理划分样本集公共部分,构建KD树;
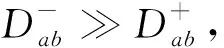

5)样本为空检测;
6)若划分结果不满足式(5),则返回第2)步。
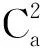
(6)
实现消岐操作。利用Hab构建样本新特征,
(7)
(8)
其中γ为平衡因子。
3 实验
3.1 实验设置
本次实验分别在UCI人工数据集和真实数据集2类不同数据集上进行实验。表2为2组人工UCI偏标记数据集的特性,表3为4组真实偏标记数据集的特性。
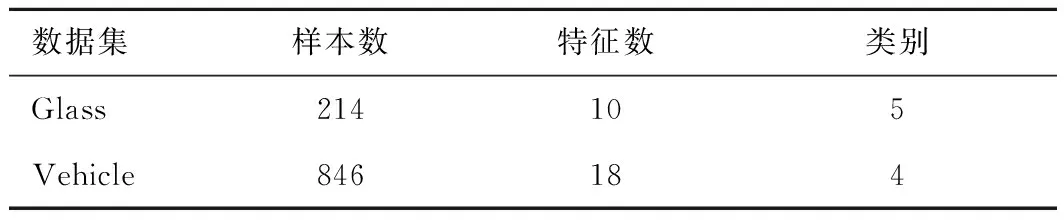
表2 UCI数据集特性
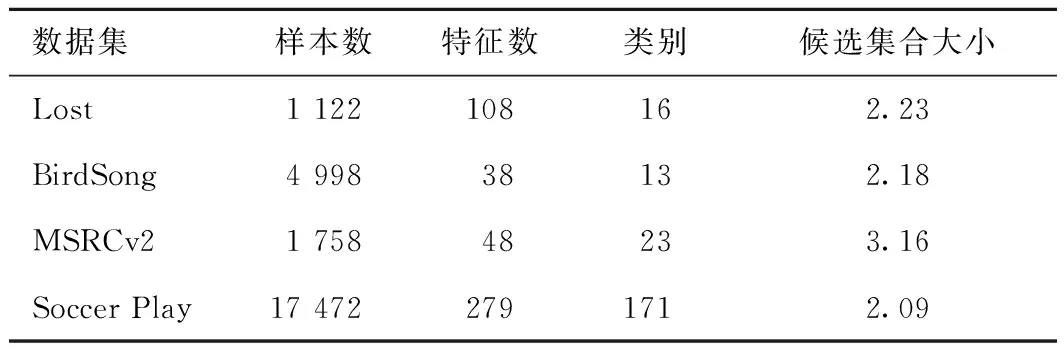
表3 真实数据集特性
3.2 实验结果
在UCI数据集中,研究提出的算法与各类算法分别在r=1,2,3,步长p从0.1~0.7变化时的分类准确率。采用10倍交叉验证结果做显著程度为0.05的成对t检验,实验结果如图1~3所示。

图1 r=1时p取0.1~0.7的分类精度

图2 r=2时p取0.1~0.7的分类精度
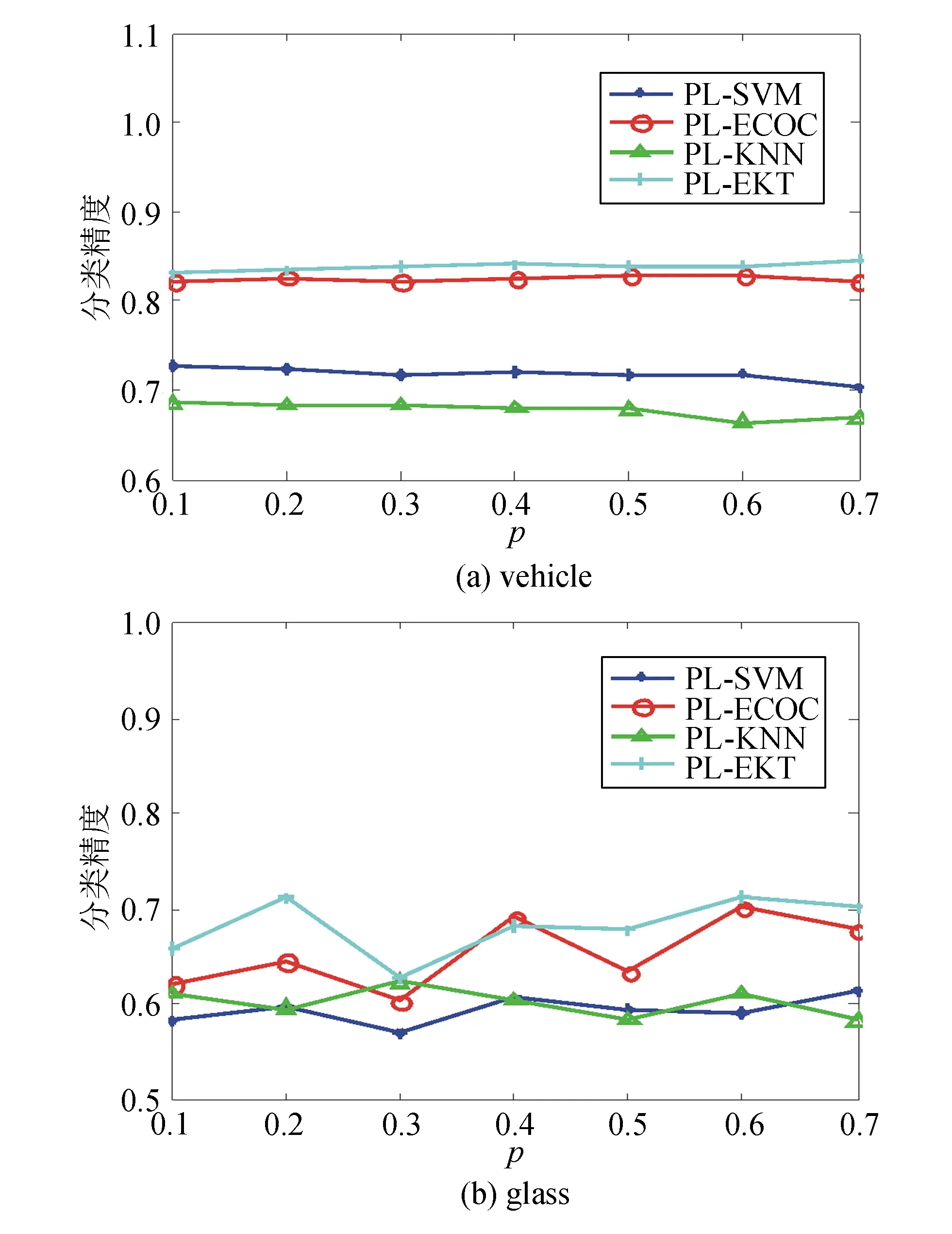
图3 r=3时p取0.1~0.7的分类精度
通过观察实验结果,可得出如下结论:
1)在vehicle数据集上各算法鲁棒性均较好,但在glasss数据集上,在不同参数下,各算法分类结果波动较大,鲁棒性不足。
2)在vehicle数据集上,除了在个别步长时劣于PL-ECOC算法,PL-EKT算法性能优于其他算法。
在真实数据集上,采用10倍交叉验证结果做显著程度为0.05的成对t检验。表4给出了各算法在真实数据集上分类精度。
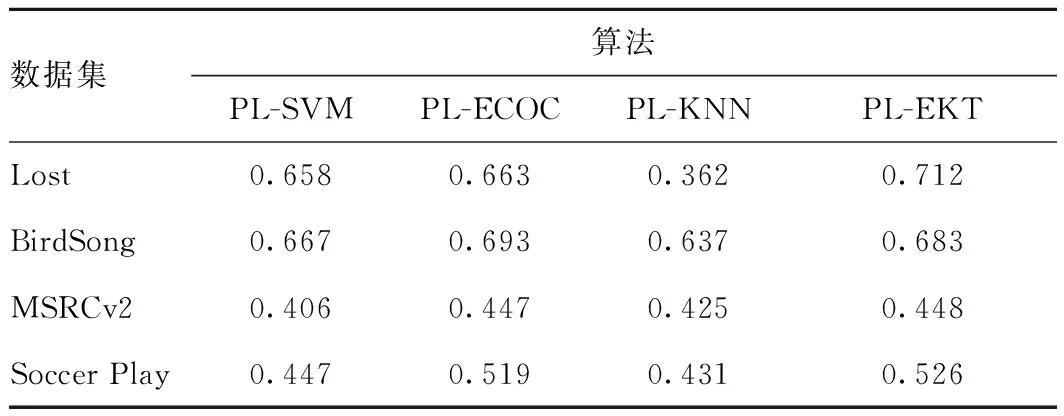
表4 各算法在真实数据集上分类精度
从表4可看出:
1)在Lost数据集上,PL-EKT算法性能比其他3种算法表现好。
2)在MSRCv2数据集上,PL-EKT算法与PL-ECOC算法基本持平,但优于其他算法。
3)在BirdSong和Soccer Play数据集上,PL-EKT算法劣于PL-ECOC算法,优于其他算法。
PL-EKT偏标记学习算法在2组UCI人工数据集和4组真实数据集上都具有较好的表现力。从整体上看,PL-EKT算法在UCI数据集中比其他算法分类精度高,且鲁棒性相对较好;在真实数据集上,PL-EKT算法相比于其他算法也拥有较好的效果,仅在Birdsong数据集上劣于PL-ECOC算法。
4 结束语
为了充分利用候选标记来划分样本,提出了KD树集成偏标记学习算法,通过KD树均衡训练集,使得偏标记学习算法有较好的泛化性能。实验结果表明,该算法在真实数据集上有较好的表现。但同时也存在一些不足的地方,在UCI数据集Glass上算法的鲁棒性不够,划分子数据集仍会存在样本均衡的问题等,有待进一步改进。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
电子测试(2018年1期)2018-04-18 11:52:35
数学物理学报(2017年5期)2017-11-23 07:51:31
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
