
关联规则挖掘在道路交通事故分析中的应用
2019-05-17 08:12:02马庚华郑长江邓评心
西华大学学报(自然科学版) 2019年3期
马庚华, 郑长江, 邓评心, 李 锐
(1.河海大学港口海岸与近海工程学院, 江苏 南京 210098; 2.河海大学土木与交通学院, 江苏 南京 210098)
交通事故是全球所有国家面临的共同难题[1]。在我国,随着社会经济的不断发展,居民机动车保有量连年上升,城市交通面临前所未有的巨大压力。2016年,我国共接报道路交通事故864.3万起,同比增加65.9万起,上升16.5%。其中涉及人员伤亡的道路交通事故212 846起,造成63 093人死亡、226 430人受伤,直接财产损失12.1亿元[2]。利用交通大数据分析事故成因,采取针对措施减少交通事故是保障道路安全的有效手段。
关联规则挖掘是一种有效的数据挖掘方法,它可以从海量的数据中发现不同类型数据之间的关联[3]。针对数量巨大的交通事故数据,关联规则挖掘可以得出事故原因(如驾驶员、车辆、道路、环境)与事故结果(如事故类型、严重程度)之间的关系,从而给交通决策者提供参考。国内外学者对交通事故成因分析的方法有很多,如贝叶斯网络[4]、决策树[5]、FP-Growth[6]、Apriori算法[7-10]等。他们对关联规则的筛选都是使用“支持度-置信度”框架,规则评选标准单一,模式评估度量数量不足,难以找出更加合理且易于应用的关联规则。
本文在以上研究的基础上,采用改进的Apriori算法对交通事故数据进行关联规则挖掘,并结合支持度、Kulc、平衡比3个模式评估度量[11],引入相关值,进一步筛选出有价值的关联规则,得出相应结论,为交通管理部门提供参考。
1 数据预处理
1.1 数据描述
本文研究所使用的数据为某市2015年全年的交通事故数据与天气数据。交通事故数据表包括事故发生的时间、事故违法类型、性别、身份证号码、车牌号码、车身颜色、毕业驾校名称、驾照初次发放日期、车辆品牌等属性,共56 651条记录。天气表包括天气状况、气温、风力风向等属性,共365条记录。
1.2 数据清理
首先要确定关联规则挖掘所需要的不同属性。基础数据中有着大量的属性,对于关联规则挖掘中不需要的属性进行删除,如交通事故数据表中的车牌号码以及天气表中的风力风向。除了原始数据已经具有的部分属性之外,一些属性需要对原始数据进一步提取,如从身份证号码获得年龄、从驾照初次发放日期获得驾龄、从车辆品牌获得车辆类型。还有一些属性需要从其他表获得,如按照日期将天气表和事故表连接,获得事故发生时的天气状况、气温等属性。
部分基础数据存在着不正确、不完整、不一致等问题,需要采取适当的方法进行处理。车身颜色出现的乱码,删除之后按照出现最多的颜色填充。年龄的缺失值分性别按照平均值填充。驾龄的缺失值根据年龄来预测。对于大量缺失的数据另归为一类,如车辆类型未知归为一类。
1.3 数据编码
数据经过清理已经准确、完整和一致之后,为了方便存储和数据挖掘,需要对部分属性进行概念分层,并将数据的表达形式进行统一描述,因此对各个属性值编码,如表1所示。

表1 属性值编码
2 Apriori算法及改进
2.1 Apriori算法描述
Apriori算法是关联规则挖掘频繁项集的经典算法。Apriori算法采用的是逐层搜索的迭代方法,k项集用于探索(k+1)项集。首先,通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合,记为L1。然后,使用L1找出频繁2项集的集合L2,使用L2找到L3,如此下去,直到不能再找到频繁k项集。其中,使用Lk-1找出Lk的过程由连接和剪枝组成。
1)连接。
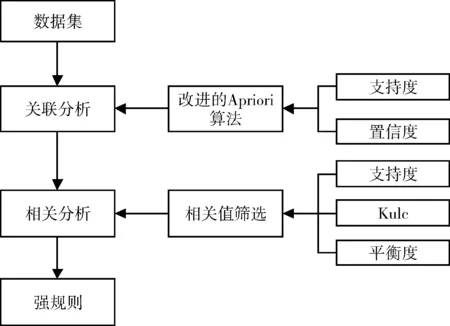
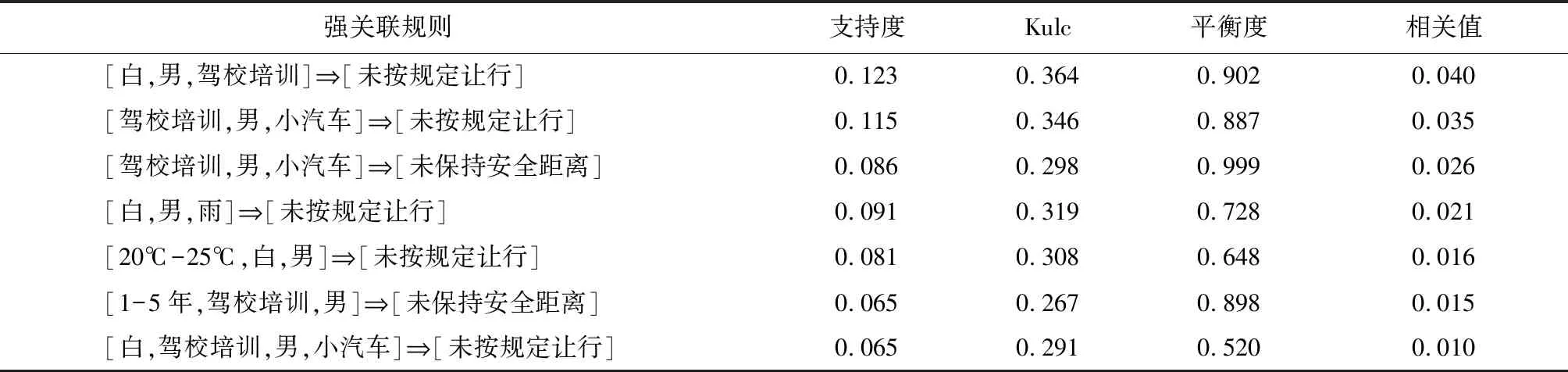
为找出Lk,通过将Lk-1与自身连接产生候选k项集的集合,记为Ck。假设l1和l2是Lk-1中的项集,记li[j]表示li的第j项。假定项集中的项按照字典序排序,即对于(k-1)项集li,其项满足li[1] 2)剪枝。 Ck是Lk的超集,其成员可以是也可以不是频繁的。扫描事务数据库,确定Ck中每个候选项集的计数,若小于最小支持度计数,则从Ck中删除;若不小于最小支持度计数,则保留,最终得出Lk。 为了提高剪枝的效率,可以采用先验性质对Ck进行压缩。任何非频繁的(k-1)项集都不是频繁k项集的子集。因此,如果一个候选k项集的(k-1)项子集不在Lk-1中,则该候选也不可能是频繁的,从而可以从Ck中删除。 Apriori算法的优点在于使用先验性质,大大提高了频繁项集逐层产生的效率,算法整体简单易理解,同时对数据集要求低。但是算法也存在缺点:如当事务数据库很大时,候选频繁k项集数量巨大;在验证候选频繁k项集的时候,需要对整个数据库进行扫描,非常耗时。 Apriori算法中从Ck到Lk要经过两次筛选:第一次是利用先验性质,通过Lk-1筛选,判断Ck中候选k项集的(k-1)项子集是否在Lk-1中,如不存在则删除,这样每产生一个候选k项集都要扫描一遍Lk-1;第二次是根据最小支持度计数筛选,项集的频数若小于最小支持度计数则删除。改进算法的思路是只需要扫描一遍Lk-1[12]。Lk-1通过与自身连接得到Ck,扫描一次Lk-1,对于Lk-1中的每一个频繁(k-1)项集,判断它是否为Ck中各候选项集的子集,如果是,那么该候选项集的计数加一。扫描完成后,对于候选项集计数为k的保留,小于k的删除。然后,再根据最小支持度计数进行第二次筛选即可得出Lk。 为了验证改进Apriori算法的效能,在支持度为0.1、置信度为0.3的条件下,分别取经典算法和改进算法在不同数据记录数下的运行时间对比,结果如表2所示。 表2 不同数据记录数下算法用时 从表2可以清晰地看出经典Apriori算法和改进Apriori算法在处理不同数据记录数时的耗时情况。实验结果表明,随着数据记录数的不断增加,改进Apriori算法的搜索时间始终低于经典Apriori算法的搜索时间,算法整体效率提高约4%。可见改进算法的搜索效率要优于经典算法,在大数据的情况下,改进算法更加适用。 假设I={I1,I2,…,Im}是项的集合。任务相关的数据D是数据库事务的集合,其中每个事务T是一个非空项集,T⊆I。A是一个项集,事务T包含A,当且仅当A⊆T。关联规则形如A⟹B,其中A⊂I,B⊂I,A≠∅,B≠∅,且A∩B=∅。规则A⟹B在事务集D中成立,具有支持度support和置信度confidence。其中,support(A⟹B)=P(A∪B),confidence(A⟹B)=P(B|A)。同时满足最小支持度阈值(min_sup)和最小置信度阈值(min_conf)的规则成为强规则,即用户所感兴趣的规则。 挖掘关联规则分两步:第一步找出所有的频繁项集,其频繁出现的次数≥min_sup;第二步由频繁项集产生强关联规则,其置信度≥min_conf。 本文在关联分析之后加入相关分析产生强规则,关联规则挖掘模型如图1所示。 图 1 关联规则挖掘模型 大部分关联规则挖掘的研究之中,都采用支持度和置信度来过滤关联规则,从而保证所得到的关联规则是用户感兴趣的。然而,仅仅使用支持度和置信度两个评判标准太少,不足以过滤掉无趣的关联规则,甚至有时会产生有误导的“强”关联规则,因此有部分研究人员加入了一个新的相关性度量:提升度lift。A和B出现之间的提升度由公式(1)计算。 lift(A,B)=P(B|A)/P(B) (1) 若提升度小于1,那么A出现与B出现是负相关的,即一个出现会导致另外一个不出现。若提升度大于1,那么A出现与B出现是正相关的,即一个出现会导致另外一个出现。若提升度等于1,那么A出现与B出现是相互独立的,即一个出现和另一个出现之间没有联系。提升度可以在一定程度上反映出A和B两者的相关性。 但是,仅加入提升度衡量相关性来进行关联规则挖掘仍然不完善。因为仅使用一个相关性度量,导致相关性判断标准单一,缺乏说服力,更为重要的是,用提升度衡量相关性存在缺陷。在事务数据库中,定义零事务为不包含任何考察项集的事务。对于一条关联规则,零事务的个数可能会大大超过包含关联规则中项集的事务的个数,而提升度这个度量从定义上看,它的值会受到零事务的影响。因此需要新的相关性度量来衡量相关性,在此引入Kulczynski(Kulc)度量和平衡比(Balance Ratio, BR)。 (2) BR(A,B)=(P(A|B))/(P(B|A)) (3) Kulc度量由公式(2)定义,可以看作两个置信度的平均值,其值可以遍取0~1,并且值越大,A和B的联系越密切。平衡比(BR)由公式(3)定义,是两个置信度的比率,它表示A和B之间相关性的平衡,越接近1则越平衡,当两个置信度中的任何一个等于零时,BR也等于零。以上两个度量仅受P(A|B)和P(B|A)的影响,不受零事务的影响,也不受事务总数的影响。 在相关性分析中,本文选用支持度(support)、Kulc、平衡比(BR)3个度量进行判断。考虑到没有前者参考来确定支持度、Kulc和平衡比的阈值应当脱离阈值确定的模式或至少能够减少阈值的数量,试图找到三者的统一表示。要做到这一点,BR首先转变为平衡度(balance),采用公式(4),使其与支持度和Kulc具有相同的正相关性。 (4) 平衡度曲线如图2所示。平衡度越大代表两个事件越平衡,当平衡度取最大值1时,表示完全平衡。 在支持度为5%,置信度为30%的条件下,采用改进的Apriori算法,共得出强关联规则141条。这些规则的支持度、Kulc和平衡度分布如图3所示。由图3可以看出,位于右上方的点具有相对较高的支持度和Kulc,并且颜色越深代表平衡度越高。这3个值呈正相关,因此使用3个值的乘积作为相关值(correlation)可以简单地用于表示相关性,如公式(5)所示: correlation=Kulc·support·balance (5) 图 2 平衡度曲线 采用上文提出的相关值(correlation)作为度量指标,对141条强关联规则进行筛选。将相关值从大到小排序,相关值越大,意味着二者之间的关系越密切,从而对应的关联规则更加有意义。筛选出的部分关联规则如表3所示。 图 3 支持度、Kulc和平衡度分布 表3 基于相关值筛选的强关联规则 通过对关联规则挖掘所得出的结果进行深入分析,可以得出一些有意义的结论以及相应的改进措施: 1)在所有的事故类型中,未按规定让行和未保持安全距离造成的事故数最多,占总数的70.0%。需要采取多种方式进行预防,如在驾驶员培训中增加此类事故的理论知识学习;在事故高发地点有针对性地设置更加合理的标志标线;加强交通管理,在高峰时段对此类事故给予重视。 2)交通事故绝大多数都是由于人为原因造成的,从驾驶员特征上看,男性驾驶员事故风险是女性驾驶员的4倍;驾龄为1~5年以及11~15年的驾驶员更容易发生事故。新驾驶员技术不娴熟、经验不足;老驾驶员自恃经验丰富,思想上麻痹。驾驶员的整体素质亟待提高,应加强对驾驶员的行为干预,严格执行惩戒制度。 3)在所有的车辆类型中,小汽车发生的事故数最多,占总数的54.5%;摩托车、电动车引发的交通事故也占有一定比例,占总数的14.2%。电动车的出现极大方便了人们的生活,然而电动车驾驶员驾照类型以自培和未知为主,没有接受过系统的交通规则学习,很容易发生事故,交管部门应加强对电动车的引导。从车辆颜色看,白色车辆发生的事故数最多,这看似与车辆颜色和事故关系的相关研究结果不符,实则是因为人们更倾向于购买白色车,造成白色车辆基数大,从而事故数多。 4)从交通环境属性上看,20~25℃和阴雨天更容易发生交通事故,且女性驾驶员在不良天气下事故率会发生较大变化。此时能见度低、路面潮湿、轮胎打滑,很容易因为制动不及时发生事故。这要求驾驶员在不良气候条件下更应该集中注意力、小心谨慎,尤其是遇到意外情况时处理能力较差的女性驾驶员,同时交管部门要积极做好引导工作。 本文以交通事故大数据为基础,采用改进的Apriori算法挖掘关联规则,提高了数据挖掘的效率。通过一个结合支持度、Kulc、平衡比三者的综合性度量——相关值对关联规则进行筛选,使筛选出的关联规则更加合理,得出的结论更有价值,从而能够为交通管理部门采取相应措施,制定相关规章制度提供参考。2.2 Apriori改进算法
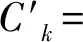
2.3 改进算法性能分析


3 关联规则
3.1 关联规则简介
3.2 相关性度量
3.3 结果及分析

4 结语
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
核科学与工程(2021年4期)2022-01-12 06:30:22
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
计算机应用(2018年5期)2018-07-25 07:41:26
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
轴承(2015年2期)2015-07-25 03:51:04
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
电讯技术(2011年11期)2011-04-02 14:00:37
