
基于用户关系和文本的微博用户相似性度量
2019-05-17 02:45黄建军方勇何祥
现代计算机 2019年9期
黄建军,方勇,何祥
(1.四川大学电子信息学院,成都 610065;2.四川大学网络空间安全学院,成都 610207)
0 引言
微博是一个以用户社交关系为基础的信息发布、分享、获取的在线社交平台,在微博中,用户可以随时随地发布信息,并可以对感兴趣的微博内容进行转发、点赞和评论[1]。根据新浪微博官方发布的数据,目前微博月活跃用户已经超过4亿人,构成了一个庞大的用户网络,对微博平台中用户的特征以及发布的内容和关注关系进行分析挖掘是当前的热门的研究方向,而用户相似度计算是其中的一个重要研究点。用户相似度计算相关技术可用于好友推荐、相似用户发现,可在海量用户中挖掘与目标用户在关系和兴趣爱好等特征维度相似的用户并推荐给目标用户。除此之外,用户相似度计算在用户聚类、社区发现、热门微博跟踪等方面都有着重要意义[2]。本文综合了社交关系(关注、粉丝)和微博文本两种属性,给出一种微博用户相似性度量方法。
1 相关研究
社交媒体上的用户的信息总体上可以分为三类:①用户的背景信息,包括年龄、性别、地理位置、教育、职业、标签信息等;②用户的社交关系,包括关注、粉丝、转发、点赞等;③用户发表的微博信息。已有的研究工作大多都是基于上述三类信息的一种或多种构建用户相似性度量方法。
Bhattacharyya等人[3]从用户的背景信息中提取关键词,并通过计算关键词的语义距离来表示关键词的相似性,进而度量用户间的相似度。Krishnamurthy等人[4]通过分析Twitter用户的关注和粉丝关系,并利用用户关系构成的网络结构进行用户间的相似性进行度量。Kahanda等人[5]利用用户相互之间的转发、评论、文件传输等交互行为来度量用户相似度。Xiang等人[6]融合了用户的属性(包括学校、工作单位、兴趣组和地理位置等)和用户间的交互计算用户关系强度。徐志明等人[7]在进行微博用户相似性度量时给出了用户的背景信息、微博文本、社交信息等多种属性的相似度计算方法并对各属性对相似度计算影响大小进行实验,认为社交信息对用户的相似性度量最有影响力。郑志蕴等人[8]结合微博用户自身背景信息和交互信息两种属性,并利用层次分析法确定各属性权值,最后构建综合的用户相似度计算模型。姚彬修等人[9]分别计算用户间社交信息相似度、微博内容相似度和交互关系相似度,最后融合各类相似度得出两个用户的总相似度来进行用户推荐。
本文采用用户社交关系和微博文本构建用户相似性度量方法,并分别给出基于户社交关系信息和微博文本信息的用户相似度计算方法:①用户社交关系相似度计算方面,本文在Jaccard[10-11]方法的基础上对用户间的每个共同好友根据其热度不同赋予不同的权重,使相似度计算结果更加合理。②在微博文本相似度计算方面,本文采用LDA模型[12]来表示微博文本并计算相似度,较基于TF-IDF的VSM模型[13-14]有效地降低了文本向量的维度并提高了相似度计算的效果。
2 微博用户相似度计算模型
2. 1 用户社交关系相似度计算
在微博平台中,用户之间存在着关注和被关注的关系,用户会关注感兴趣的账号,也可以吸引别的用户成为自己的粉丝,关注和被关注的关系不断扩展使构成了一个庞大的社交关系网络。微博用户的关注信息和粉丝信息可以直观的反映该用户的兴趣,两个微博用户拥有的共同粉丝或关注者越多,说明其具有更加紧密的社交联系,这也能在某种程度上反映了两个用户间的相似度。对于一个微博用户u,其社交信息可以表示为:
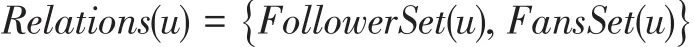
其中FollowerSet(u)表示用户u的关注用户集,FansSet(u)表示用户u的粉丝用户集。用户间的社交关系相似度可以分为关注信息和粉丝信息两种属性的相似度计算问题。
基于用户社交关系的相似度计算方法一般使用基于共同邻居的方法,如Jaccard方法[7-9]。以用户关注信息为例,基于Jaccard方法的关注信息相似度可以表示为:

如上式所示,Jaccard方法通过两个用户间的共同关注用户的比例来度量用户间的相似程度,这种方法对不同的共同关注用户并没有分情况处理,无论是热度较高(即粉丝较多)的用户,还是普通的用户,对用户相似度计算结果的影响都是相同的。但实际中并非如此,微博平台上存在着一些热门用户,这些热门用户拥有海量的粉丝数,受到广大微博用户的喜爱和关注。关注这样一个热门的用户往往并不能够反映一个用户的真正的兴趣所在。相反,微博用户对一个较为冷门的用户的关注,从某种程度上来说更能反映用户真正的兴趣所在。基于上述现象,计算用户u和用户v的关注相似度时,共同关注微博用户z的粉丝越多,在计算关注相似度时其权重越小。与之相反,粉丝数越少,在计算关注相似度时其权重越大。基于该思路,本文在Jaccard方法的基础上,对每一个共同关注根据其热度赋予不同的权重,用户关注信息相似度计算公式可以表示为:

同理用户的粉丝信息相似度计算公式可以表示为:

综合关注和粉丝两个方面,对于两个用户u,v之间的社交关系相似度定义为:

Simfollower(u,v)表示两个用户关注信息的相似度,Simfans(u,v)表示两个用户粉丝信息的相似度,α1、α2两者的权重,α1+α2=1。
2. 2 基于LDA的用户微博文本相似度计算
在微博平台上用户可以随时随地的发表自己的想法与见解,同时还能够转发、评论其感兴趣用户的微博内容。微博文本是微博用户间进行互动交流的主要媒介,微博文本直接体现了用户感兴趣的内容和话题。两用户所发布微博文本的相似度可以有效地体现两个用户间的相似度。
基于TF-IDF的向量空间模型(VSM)文本相似度计算方法被广泛地用于微博文本相似度计算[7,9]。将用户的微博文本拼接成一个文档,通过分词、提取关键词,使用TF-IDF计算关键词权重,最终将用户微博表示为一个文本向量,并通过余弦相似度计算两个用户的微博文本相似度。VSM将文档表示成一个高纬度、稀疏的文本向量导致计算效率不高,并且VSM忽略了词语之间的关联,不能完全建模自然语言的复杂性问题。
针对上述方法存在的缺陷,本文使用LDA主题模型进行文本相似度计算。LDA(Latent Dirichlet Allocation)模型是一种对文本数据的主题信息进行建模的方法,它有文档-主题-特征词三层贝叶斯网络结构。本文用LDA模型对用户微博文本进行建模,即利用文本的统计特性,挖掘文本中不同主题与词之间的潜在关系,将文档以主题分布的形式展现,通过此分布计算文本的相似度。使用LDA主题模型进行文本相似度计算相较于向量空间模型能更好地表示文本的语义并且有效地降低了文本向量的维度。
将用户所发布的微博合并成一个长文本作为LDA模型中的文档层中的一个文档,从而得到用户的主题概率多项分布。对于用户u将其发布的全部微博所拼接成一个长文本并使用LDA模型其表示为一个主题向量的过程如下:
文本预处理,对微博文本进行过滤表情符号、URL等无意义文本、分词、去停用词等处理;
词频向量表示,采用词频方法来计算微博文本中的每个特征词i的权重,将文本表示为词频向量 du=
主题生成,通过LDA模型生成用户微博文本在k个主题上的概率分布,表示成向量θu=
在将用户微博表示为主题向量θ后,用户间的相似度可以通过计算两用户对应的主题概率分布得到。有人使用KL(Kullback Leibler)散度,来衡量2个概率分布的距离[15],其计算公式为:

由于KL散度是不对称的,即Dkl(P,Q)≠Dkl(Q,P),可以将其转换为对称的,如公式(6):

在基于LDA的主题模型中,由主题的概率分布来表示。因此,用户间的相似程度可以由用户微博文本主题分布间的KL距离来表示,用户相似度计算如下所示:
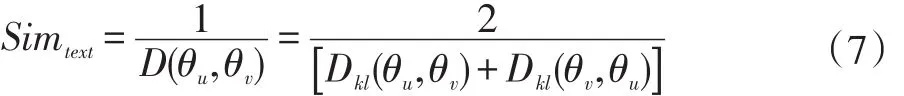
2. 3 完整的微博用户相似度计算
如图2所示,完整的微博用户相似度计算是将用户微博社交关系相似度和微博文本相似度两个部分综合起来得到,更加全面地构建微博用户间的相似性度量。
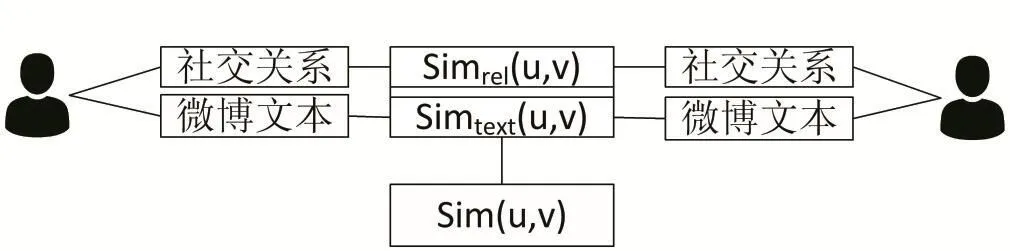
图1 微博用户相似度计算框架
结合前两节内容,将综合的微博用户相似度表示为:

其中Simrel(u,v)表示用户社交关系的相似度,Simtext(u,v)表示用户微博文本的相似度,ω1、ω2表示两者的权重,ω1+ω2=1。
3 实验及分析
3. 1 实验数据
目前,关于新浪微博用户相似度计还没有统一的公开数据集,根据需求,本文使用Scrapy框架编写爬虫程序自行从新浪微博上采集相关数据。本文在新浪微博中选取10个种子用户,并利用其社交关系链向外扩展一层,抓取用户的基本信息、微博内容、社交信息。为了实验的有效性,对采集的用户数据进行了筛选:①去除不活跃的用户,即用户关注加上粉丝数少于50或发表微博数少于30的用户;②去除部分无效的微博,即微博字数少于10个或者仅包含表情符号、URL的微博。
经过处理后,挑选出2000名用户的信息用于实验,包括用户社交关系信息230250条,微博内容968016条。
3. 2 评估指标
本文使用准确率(Precision Rate)和召回率(Recall Rate)作为衡量实验结果的评估指标。通过用户标签、简介以及用户微博内容为用户划分领域,以同一领域的用户为相似用户。对于用户集合中的用户u,通过对其进行Top-N推荐,即使用相似度算法计算各个用户之间的相似度,将计算结果排序选出相似度得分最高的N个用户作为相似用户推荐结果。
准确率是指在推荐出的N个用户中属于用户的相似用户的个数Nc与推荐结果总数N的比值,比值越大则推荐结果的准确率越高。准确率的计算公式为:

召回率是指推荐结果中属于相似用户的个数Nc与相似用户总数Ns的比值,比值越大则说明推荐结果越全面。召回率的计算公式为:

3. 3 实验结果及分析
本文选择以下四种方法进行对比实验:
(1)本文提出的方法,通过多次实验将社交关系相似度中关注相似度和粉丝相似度的权重分别设为α1=0.6,α2=0.4;微博文本相似度中LDA模型主题数k=40;社交关系相似度和微博文本相似度的权重分别设为ω1=0.8,ω2=0.2。
(2)已有的混合方法,借鉴文献[6-8]的方法,基于用户社交关系和微博文本计算用户的相似度,其中社交关系相似度采用Jaccard方法,微博文本相似度采用基于TF-IDF的VSM模型计算。
(3)本文所述的基于社交关系的相似度计算方法。
(4)本文所述的基于微博文本的相似度计算方法。
在实验中,分别取TOP-N的N={20,40,60,80,100}时的5种情况,四种算法的确率、召回率如图2-3所示。

图2 四种算法的准确率对比
从实验结果可以看出,随着推荐数N的增加,各算法的准确率逐渐降低,在四种算法的对比中本文提出的混合方法的准确率方面均明显高于其他方法;在召回率方面,随着N值的增加,召回率越来越高,并且比本文算法的召回率始终高于其他三种算法。本文算法综合了用户社交关系和微博文本两方面属性,较于单独属性构建的相似度算法有更好的表现,且与已有的混合方法相比效果上也有一定提升。
4 结语
本文主要研究微博用户间的相似性度量方法,对微博用户社交关系(关注、粉丝)和微博文本两方面信息分别进行分析并给出两种信息相似度计算方法。对于用户社交关系,本文在Jaccard方法的基础上引入用户热度的影响并用于用户社交信息相似度计算;对于用户微博文本,本文使用LDA模型进行用户微博文本相似度计算。最终通过加权的方式综合两种信息构建完整的微博用户相似性度量方法。并使用本文方法进行了Top-N推荐实验,实验结果表明,本文所提算法较其他三种算法具有更好的效果。对于微博用户相似性度量的进一步研究可以考虑利用微博用户的其他信息进行相似度计算,如使用点赞、转发、评论等交互信息来度量用户相似性。

图3 四种算法的召回率对比
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
作文大王·低年级(2022年3期)2022-03-19
现代英语(2021年18期)2021-11-22
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
小学生作文·小学低年级适用(2018年12期)2018-04-11
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
校园英语·下旬(2016年2期)2016-03-18
