
基于图拓扑特征的恶意软件同源性分析技术研究
2019-05-17 02:45:04黎奇刘嘉勇贾鹏刘露平
现代计算机 2019年9期
黎奇,刘嘉勇,贾鹏,刘露平
(四川大学电子信息学院,成都 610065)
0 引言
随着计算机技术的发展,恶意软件越来越危害着网络安全。Symantec 2017年发布的威胁报告显示,恶意软件不仅数量快速增长,而且呈现出变种越来越多、结构越来越复杂的特点[1]。由于变种和多态技术的普及、自动混淆工具的出现,恶意软件的指令通过重排序及等效序列替换,改变了样本原有的特征,从而达到规避杀毒软件查杀的目的。恶意样本的多样变种为分析恶意软件带来了很大的挑战[2]。
恶意软件同源性分析根据样本的家族属性可以对未知样本进行分类识别。在过去的研究工作中,恶意样本同源性分析通常是将样本视为字节序列提取样本的家族特征[3,6],基于字节序列进行分类的方法忽视了程序的控制流程图和函数调用图的结构信息对分类结果的影响,有着天然的缺陷[6]。大多数恶意软件都是由高级编程语言编写而成,源代码的微小变化会引起二进制代码的显著改变,并且字节序列的改变并不能反映出样本功能或结构的改变。
传统基于图分析恶意样本同源性的核心思想是比较不同样本函数调用图之间图形的相似性[7]。早期方法是计算图之间的编辑距离,Kinable J和Kostakis O[5][5]等人通过此方法测量图形间相似性。通过计算图编辑距离比较图形相似性的优点在于可以定义自己的成本函数,但该方法的时间复杂度随图节点数量的增加呈指数增长。为此,Hu X、Chiueh T C和Kang G S[6]使用匈牙利(Hungarian)算法对传统基于图编辑距离测量图相似度的思路做了改进,从而在立方阶O(n3)的时间复杂度中计算出两个图的相似度。此外,Xu M、Wu L和Qi S[7]等人通过对图所拥有边的数量进行标准化来度量图的相似性。Shohei H和Hisashi K[8]用图中每个顶点的邻域哈希值替换节点的初始标签后,通过计算两个图顶点标签集的交集比率,比较两个函数调用图的相似度。
与以往仅通过比较恶意样本函数调用图的结构进行样本同源性研究不同,Jang J W和Woo J[10]等人在2015年提出基于网络分析的恶意软件分类方法中,验证了函数调用图的特征(如度中心性、网络密度)可有效区分正常软件和恶意软件,其分类准确率达到96%,但该研究没有用网络分析方法对恶意样本进行家族间的分类。
1 基于图拓扑特征的同源性分类方法
恶意软件在执行过程中会调用很多函数[4],同一个家族软件的函数调用图有相似的结构信息,本文假设函数调用图的拓扑特征可以进行恶意软件家族分类,基于此,提出基于图拓扑特征的恶意软件同源性分析的方法,并进行分类实验。
本文首先生成软件的函数调用图,根据函数调用图提取出图的拓扑特征及外部函数名,最后使用机器学习分类算法根据函数调用图提取出的相关特征进行同源性分类,并进行分类评估。恶意软件同源性分类框架如图1所示。
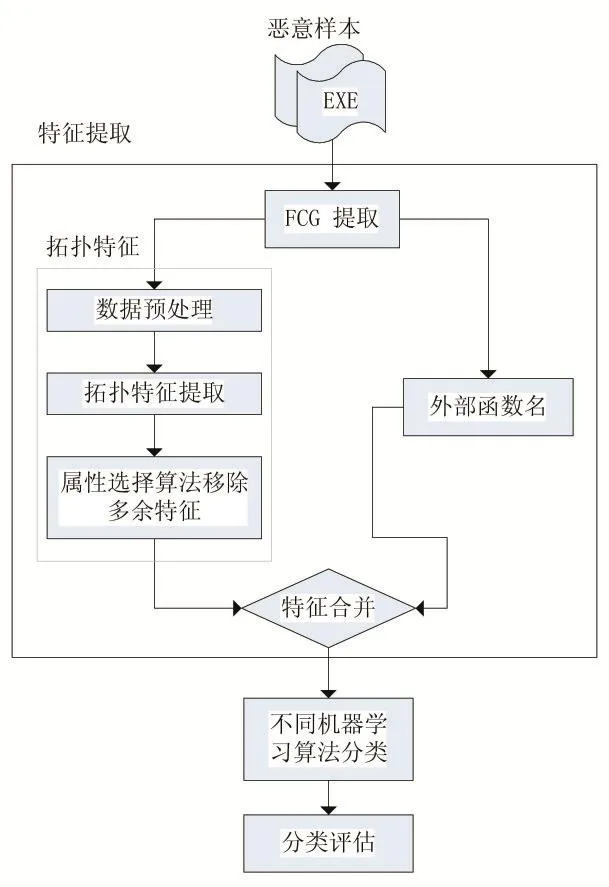
图1 恶意软件同源性分类框架
1. 1 拓扑特征提取及过滤
在提取出恶意软件的函数调用图后,通过把函数视为节点,函数间的调用关系视为有向边后,抽象函数调用图为一个网络。本文生成的网络数据文本格式如下所示:

其中,directed项为true表示生成的是有向图;nodes项中以数字0~n标记并表示函数调用图中函数的名称;links项中每对{source:n,target:k},k∈[0,n]表示一对函数调用关系,其中source表示调用函数,target表示被调用函数。
1. 2 函数调用图提取
函数调用图G是一个由函数集合V和函数间关系集合E组成的有向图,如图2所示。函数调用图的数学表达式为:G=(V,E)。

图2 函数调用图
函数调用图中顶点有两类函数构成:
(1)本地函数,程序设计者定义的函数;
(2)外部函数,系统函数或库函数。
由于在不同的二进制文件中,即使两个本地函数功能相同,在静态分析过程中,也很难识别出来。静态分析工具一般以sub_开头的随机符号命名本地函数[11],因此,本文没有把本地函数名作为同源性恶意样本的分类依据。
对于外部函数,本文通过解析样本PE头中的导入地址(IAT)表找到外部函数名称,对于外部函数中的静态链接库函数,使用了Fast Library Identification and Recognition Technology(FLITERT)识别出它们的原始名称[12]。同一家族的恶意样本很大概率会调用相同的外部函数。因此,本文把样本函数调用图的外部函数名如:ExitProcess、MessageBoxA作为恶意软件同源性分类一个单独的特征向量。
当所有函数被识别出来后,根据提取出来的函数调用关系添加顶点之间的有向边,生成最终的函数调用图。
(1)拓扑特征提取
网络分析离不开对网络拓扑特征的计算,本文用NetworkX[13]杂网络分析工具中已有的算法对每个恶意软件对应的网络进行特征提取。在网络分析工具中,计算网络结构的拓扑特征包括近似性、拟合性、中心性等42大类,每类拓扑特征都有一些子特征用于研究者分析网络结构。
网络的单一特征并不能很好地分类恶意软件家族,不同家族的同一网络特征值可能相同,同一家族的同一网络特征值并不完全相同[10]。在这里,本文提取出了网络48个子特征供后面筛选,表1中列出了选取的部分特征。
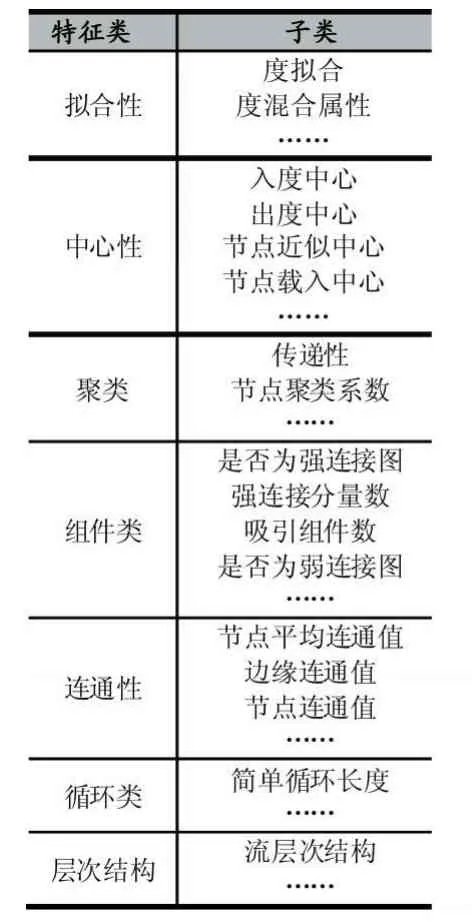
表1 部分复杂网络特征
(2)拓扑特征选择
网络分析依赖的是与研究相关拓扑特征的计算,不是越多特征,越有利于目标的分类,反之,多余的特征会影响分类的正确性[4]。在初次选择的48个特征中只有部分特征与恶意样本家族分类相关。为了精简特征集,需要对这些特征进行选择。由于每个子特征对家族预测能力不同,特征间也存在相互关联的现象[15]。为了选取出家族预测能力强且组成的特征集关联性低的单个特征,本文选择了过滤器模式的基于关联的特征选择(CFS)方法进行特征筛选[14],其评估方法为:

其中:Ms为对一个包含有k个特征项的特征子集s的评价;rˉcf为特征与类之间的平均相关度;rˉff为特征与特征之间的平均相关度。
本文使用CFS方法对48个特征过滤后,选出了如下所示的8个拓扑特征集合,作为恶意样本同源性的分类依据:
(1)传递性
传递性表示网络中连接同一个节点的两个节点相互连接的可能性,即网络中可能组成三角形的比例,属于聚类特征。计算方式如公式(2)所示。

triangles指网络中三角形的数量,triads指有两条边有相同顶点的数量,结果为浮点数。
(2)强连通分量数
有向网络强连通分量:在有向网络中,如果一对顶点 Vi,Vj,Vi≠ Vj间存在 Vi到 Vj及 Vj到 Vi的路径,则称两个顶点强连通。有向网络的极大强连通子图,称为强连通分量,属于组件类特征。
(3)强连通点
强连通点:为强连通分量中的节点,该特征属于组件类,把强连通点的标号作为一个特征。
(4)吸引分量的数量
吸引分量属于强连通分量,吸引分量具有一旦进入,则一直在这个分量中循环的属性,属于组件类特征。
(5)平均连通度
网络的平均连通度是反应网络可靠性的参数之一,是经典连通度的推广,属于连通性特征类,计算方式如公式(3)所示。

u,v指的是网络中的节点。
(6)简单循环长度
简单循环是指网络中一个封闭的路径,此路径中节点不会重复出现,把FCG生成的网络的简单循环节点的长度作为一个特征,属于循环类特征。
(7)流层次结构
度量流层次结构是为了理解网络的结构机制和演化模式出现的,这里为有向网络中不参与循环的边的比例,该特征属于距离相关特征度量类。
(8)密度
网络密度,该特征用于测量网络属性,计算方式如公式(4)所示。

其中n为网络节点的数量,m为网络边的数量。
综上所述,本文使用CFS特征选择算法,从初始48个拓扑特征集中选出1个聚类、3个组件类、1个连通性类、1个循环类、1个层结构类和1个网络属性类特征作为家族同源性分析的依据。
2 实验评估
测试环境为装有Weka3.8软件的Windows 64位系统计算机,详细配置为:CPU型号Intel Core i7 4790@3.60GHz,内存 8GB。
2. 1 实验样本
本文中实验数据均来源于VxHeavens数据集,该数据集中的样本均按卡巴斯基命名规则命名。为了确保实验数据的准确性,本文使用了VirusTotal网站抽样验证样本的家族命名。本次实验使用Windows平台上的10个恶意样本家族数据进行同源性分析,10个样本家族分别是:

实验中使用到每个家族的样本数量如表2所示。
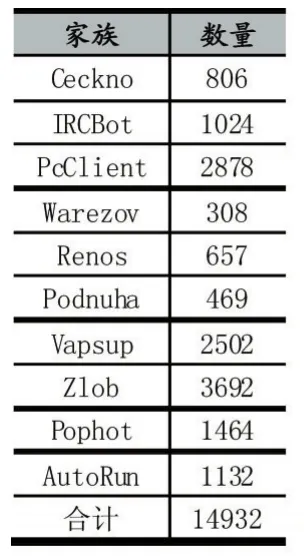
表2 恶意家族样本
2. 2 测量指标
通过判断预测值是否很好地与实际标记值相匹配可以评估分类算法的性能。本文用以下通用标准来度量分类方法的有效性:
精确率(Pr):被预测为某个家族的恶意样本中实际为该家族的样本所占比例,计算公式:

其中TP表示正确分类到某个家族的数量,FP表示错误分类到这个家族的数量。
召回率(Rc):正确预测为某个家族数量和实际为该家族样本数量的比值,计算公式:

其中TP表示正确分类到某个家族的数量,FN表示该家族实例被错误分配到其他家族的数量。
2. 3 实验结果与分析
本次实验使用10折交叉验证法,即将实验样本分成10分,轮流将其中9分作为训练集,剩余1份作为测试集来评估分类。本次实验选择LibSVM、Instance Based 1、RandomForest、BayesNet四种分类算法对样本进行了同源性分析。实验结果表明,四种分类算法的参数设定改变并没有有效地提高分类的效果,因此本实验中的四种分类算法均采用Weka中默认的参数值。各种算法分类结果如表3所示,表中包含每个分类算法对家族分类的Pr、Rc值。
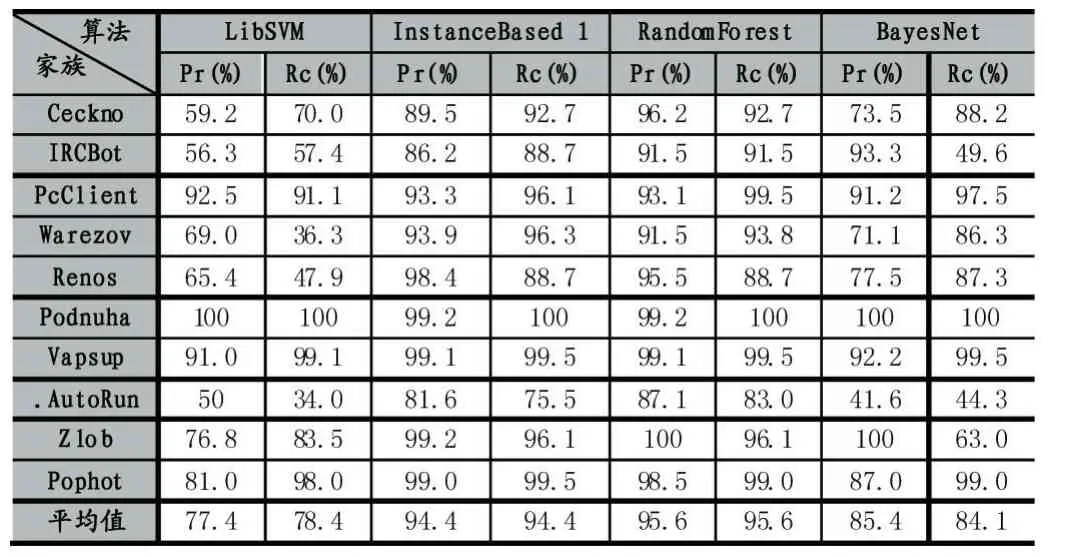
表3 实验结果
通过表3中Pr、Rc两类指标的比较,可以看出RandomForest分类效果最好,精确率平均值和召回率平均值均为95.6%;Instance Based 1分类算法次之,精确率平均值和召回率平均值均为94.4%;BayesNet分类算法精确率平均值为85.4%,召回率平均值84.1%;LibSVM分类算法精确率平均值仅为77.4%,召回率平均值仅为78.4%。
耗时方面,因为Instance Based 1分类算法不需要建立模型,速度更快。使用RandomForest分类算法,构建模型所需的时间为6.96秒;BayesNet构建模型所需的时间为7.05秒;LibSVM构建模型所需的时间为1.71秒。
综合上所述,结合分类算法精确率、召回率和分类样本所需建模时间,RandomForest适用于本次实验,达到较准确的分类效果。
3 结语
本文在函数调用图基础上,结合网络理论体系中的网络分析方法,提出基于图拓扑特征的恶意软件同源性分析技术。通过实验,RandomForest分类算法取得了精确率95.6%的分类效果,验证了本文提出思路的有效性和可行性。本文的贡献有以下几点:
(1)提出了一种基于函数调用图拓扑特征和机器学习相结合的恶意软件同源性分类方法;
(2)设计实验,验证了本文提出方法的有效性,在本文所使用的样本集上,恶意软件同源性分类精确率上达到了95.6%。
本文的缺陷在于特征提取方法不够完善,实验结果中出现了某个家族分类效果明显低于其他家族的现象。在下一步工作中,将优化拓扑特征选择方法,加大样本规模,以得到更好的实验结果。
猜你喜欢
电脑知识与技术(2021年33期)2021-12-17 00:50:31
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
小哥白尼(军事科学)(2019年9期)2019-12-21 02:09:34
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
电影(2019年3期)2019-04-04 11:57:18
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
湘潭大学自然科学学报(2018年2期)2018-05-28 09:04:38
阅读(低年级)(2018年11期)2018-05-14 09:37:53
电脑知识与技术(2017年32期)2017-12-15 10:22:23
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
