
基于连续语音识别技术的猪连续咳嗽声识别
2019-05-11 06:13刘望宏雷明刚谭鹤群
农业工程学报 2019年6期
黎 煊,赵 建,高 云,刘望宏,雷明刚,谭鹤群
基于连续语音识别技术的猪连续咳嗽声识别
黎 煊1,2,赵 建1,2,高 云1,2,刘望宏2,3,雷明刚2,3,谭鹤群1,2
(1. 华中农业大学工学院,武汉 430070;2. 生猪健康养殖协同创新中心,武汉 430070; 3. 华中农业大学动物科技学院动物医学院,武汉 430070)
针对现有基于孤立词识别技术的猪咳嗽声识别存在识别声音种类有限,无法反映实际患病猪连续咳嗽的问题,该文提出了基于双向长短时记忆网络-连接时序分类模型(birectional long short-term memory-connectionist temporal classification, BLSTM-CTC)构建猪声音声学模型,进行猪场环境猪连续咳嗽声识别的方法,以此进行猪早期呼吸道疾病的预警和判断。研究了体质量为75 kg左右长白猪单个咳嗽声样本的持续时间长度和能量大小的时域特征,构建了声音样本持续时间在0.24~0.74 s和能量大于40.15V2∙s的阈值范围。在此阈值范围内,利用单参数双门限端点检测算法对基于多窗谱的心理声学语音增强算法处理后的30 h猪场声音进行检测,得到222段试验语料。将猪场环境下的声音分为猪咳嗽声和非猪咳嗽声,并以此作为声学模型建模单元,进行语料的标注。提取26维梅尔频率倒谱系数(Mel frequency cepstral coefficients,MFCC)作为试验语段特征参数。通过BLSTM网络学习猪连续声音的变化规律,并利用CTC实现了端到端的猪连续声音识别系统。5折交叉验证试验平均猪咳嗽声识别率达到92.40%,误识别率为3.55%,总识别率达到93.77%。同时,以数据集外1 h语料进行了算法应用测试,得到猪咳嗽声识别率为94.23%,误识别率为9.09%,总识别率为93.24%。表明基于连续语音识别技术的BLSTM-CTC猪咳嗽声识别模型是稳定可靠的。该研究可为生猪健康养殖过程中猪连续咳嗽声的识别和疾病判断提参考。
信号处理;声音信号;识别;生猪产业;连续咳嗽声;双向长短时记忆网络-连接时序分类模型;声学模型
0 引 言
目前,市场对猪肉的需求量在所有动物肉类中比重最大[1]。然而,随着生猪产业规模化的发展,猪呼吸道疾病严重威胁了猪肉的质量和产量,通过猪咳嗽声的监测可以及时发现猪呼吸道疾病[2-4]。目前猪场监测猪咳嗽声的方法是人为蹲点监测,不仅人力成本高,而且无法保证较理想的识别率。本文基于语音识别技术开展猪场环境下猪咳嗽声的自动识别研究,以促进生猪健康养殖的发展[5]。
在猪咳嗽声时域特征的研究过程中,Mitchell等[3]研究了比利时长白和杜洛克杂交猪的咳嗽声,发现病猪、健康猪咳嗽声持续时间分别为0.3和0.21 s;Sara等[4]通过对长白和大白杂交猪咳嗽声的研究,发现病猪、健康猪咳嗽声持续时间分别为0.67和0.43 s。由此可见猪的咳嗽声持续时间长度与猪的健康状况以及品种都有关系。另外,Cordeiro等[1]采用不同的冷热环境对猪进行刺激,发现处于紧张状态下的猪所发声音持续时间长于1.02 s,并以此阈值作为决策树算法(decision tree algorithm)的判断标准,对猪是否处于紧张状态进行判断。
在猪咳嗽声识别的研究过程中,Exadaktylos等[6]采用模糊C均值聚类算法识别猪咳嗽,总识别率达到85%。同样基于模糊C均值聚类算法进行猪咳嗽声识别的工作有Hirtum等[7],识别率达到92%,错误率达到21%;徐亚妮等[8]识别率达到83.4%;Guarino等[9]则采用动态时间规整(dynamic time warping,DTW)算法识别猪咳嗽,识别率达到85.5%;刘振宇等[10]采用隐马尔科夫模型(hidden markov model,HMM)对猪咳嗽声进行识别,识别率达到80.0%;黎煊等[11]基于深度信念网络(deep belief nets,DBN)实现了猪咳嗽声识别,猪咳嗽声识别率达到95.80%,误识别率为6.83%,总识别率达到94.29%。
前人的工作均是基于孤立词的猪咳嗽声识别和研究,所考虑的非猪咳嗽声种类有限,故所得模型对于没有学习的猪场其他声音样本无法做出识别判断,模型实用性受到限制;另外,患病猪每次咳嗽时,会进行多次连续性的咳嗽[12-13],故通过猪的连续咳嗽声识别更能反映猪的患病情况。
目前,国内外关于猪连续声音识别的研究工作未曾报道,但是越来越多的学者已经通过构建声学模型,将连续语音识别技术运用于其他动物的声音识别研究上。声学模型是连续语音识别系统的重要组成部分,通过选择合适的声学建模单元可以很方便地描述语音信号的物理变换规律。Milone等[14]构建了牛吃食声的声学模型,实现了牛连续吃食声的识别。类似的研究工作还有Reby等[15]实现了鹿连续声音的识别,Milone等[16]实现了羊连续吃食声的识别,Trifa等[17]实现了蚁鸟连续声音的识别。
为此,本文开展了猪连续咳嗽声识别的研究。通过双向长短时记忆(birectional long short-term memory,BLSTM)网络[18-20]对猪连续声音进行特征学习,进一步借助连接时序分类(connectionist temporal classification,CTC)[21]直接对输入猪连续声音序列和其标注的对齐分布进行建模,实现端到端[22-23]的猪连续咳嗽声识别系统,以期为生猪健康养殖过程中猪连续咳嗽声的识别和疾病的判断提供方法参考。
1 猪声音采集与特征参数提取
1.1 猪声音采集
猪声音采集地点为华中农业大学校属精品猪场。用美博M66录音笔(采样频率为48 kHz)进行采集。采集时间为2016年3‒4月气温变换明显的猪病多发期进行。声音采集对象为10头体质量75 kg左右的长白猪,各5头分开饲养于相邻两栏。经兽医诊断10头猪中5头感染呼吸道疾病,咳嗽明显。将录音笔固定于两栏中间靠近猪舍墙壁上离地1.5 m处,进行每天24 h连续猪场环境声音的采集。对录音笔采集的声音进行选取,保留猪咳嗽频繁时间段的语音信号共30 h进行试验。
1.2 猪声音去噪
猪场环境噪声复杂,过多的噪声对后续端点检测和猪声音的识别都有不利的影响。本文选择基于多窗谱的心理声学语音增强算法[11]实现猪连续声音的去噪。图1所示为语音增强算法处理前后时长为8.50 s猪连续咳嗽声波形对比图,由图1b可知猪连续声音信号噪声得到明显削减,并且通过人耳试听感知,发现猪声音样本几乎没有失真。
1.3 猪咳嗽声时域特征研究
猪场采集的连续声音中声音种类繁杂,猪声音主要包括咳嗽、打喷嚏、吃食、尖叫、哼哼、甩耳朵等,环境噪声主要包括狗叫声、金属碰撞声、抽风机噪声等其他声音,这些声音与猪咳嗽声在持续时间和能量大小等时域特征上存在明显的差异。本文从前人[3-4]通过对猪声音持续时间、能量大小等特征的研究工作中得到启示,研究了本试验中单个猪咳嗽声样本的持续时间长度和能量大小。
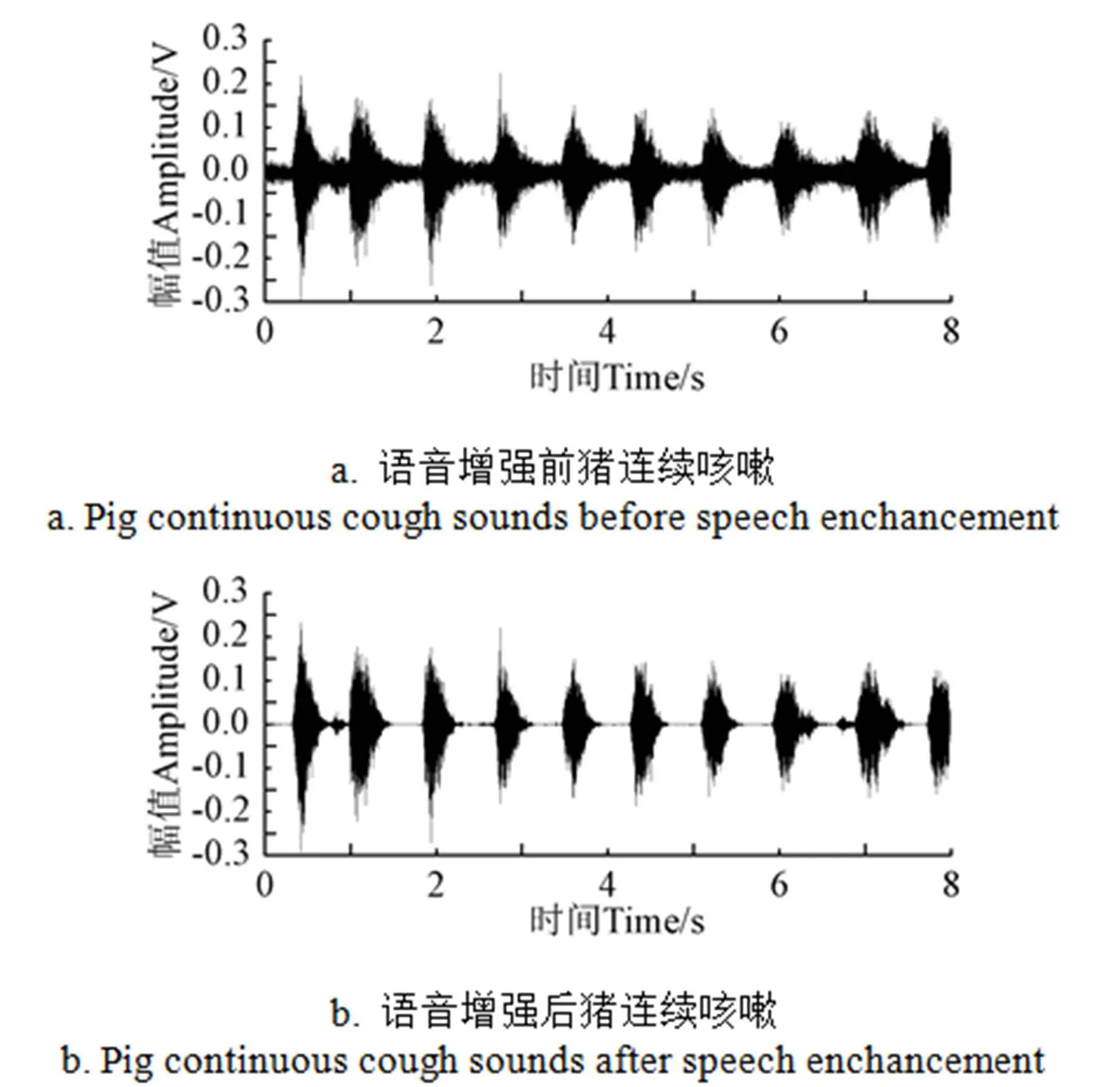
图1 语音增强前后猪连续咳嗽声波形图
经过分帧处理后的猪咳嗽声样本()的持续时间长度dur计算公式为
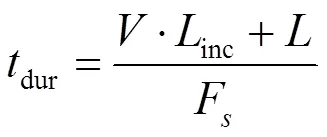
式中是经过分帧后猪咳嗽样本总帧数,是帧长,根据声音信号的短时平稳特性取为25 ms,inc是帧移,取为帧长的40%,F是采样频率,Hz。
令猪咳嗽声样本()经过分帧后第帧表示为y(),则猪咳嗽声样本()的能量计算公式为
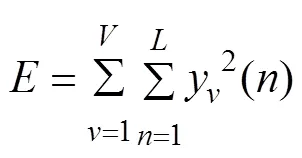
式中是采样点序号。
利用Direct Splitter语音信号处理软件从录音笔采集声音中随机截取了597个猪咳嗽声样本,按照公式(1)和(2)分别计算每个样本的持续时间长度和能量大小,进一步得到最大最小值,结果如表1所示。
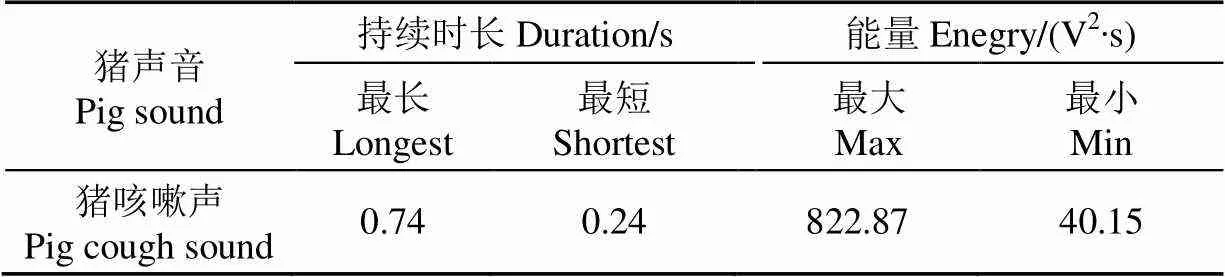
表1 单个猪咳嗽声样本时域特征分析结果
由表1分析结果可知,本试验对象长白猪咳嗽声持续时间从0.24~0.74 s不等,研究结果与前人的研究结果[3-4]类似。由于猪咳嗽的强度和猪距离录音笔的距离都会对咳嗽声样本的能量造成影响。相对而言,能量越高的样本表示猪咳嗽越剧烈且猪距离录音笔越近,故能量阈值只考虑其下限值。
猪声音信号端点检测是指从包含猪声音的连续信号中找出所有声音样本的起止点,把起止点之间的信号定义为有效信号。利用文献[11]中基于短时能量的单参数双门限端点检测算法检测录音笔采集的30 h连续猪场声音的有效信号,并对检测出的每一个声音样本按照表1中持续时长上下限和能量下限值设定的阈值范围进行判断,剔除不在此范围内的声音样本。最终得到222段试验语料,其中最长9.14 s,最短3.91 s。所有222段语料共包含声音样本1 145个,其中猪咳嗽样本一共751个,非猪咳嗽样本一共394个。
在兽医帮助下,采用人工标记法对222段语料进行标注得到对应的序列标记,将声学建模单元中猪咳嗽声和非猪咳嗽声分别用符号‘k’和‘n’表示。
1.4 特征参数提取
梅尔频率倒谱系数(Mel frequency cepstral coefficients,MFCC)[24-25]的分析是基于人耳的听觉机理进行的。将线性频谱映射到非线性的Mel频谱中,依据人的听觉试验结果来分析声音的频谱特性。将猪连续声音语段经过分帧加窗后,采用快速傅里叶变换计算其频谱能量,然后将其通过梅尔滤波器组,对滤波器输出取对数得到梅尔滤波能量,再计算其离散余弦变换得到可以反映猪声音静态特性的13维梅尔频率倒谱系数,最后加入反映猪声音动态特性的一阶差分系数,得到26维梅尔频率倒谱系数。梅尔频率倒谱系数特征参数提取过程具体步骤如图2所示。
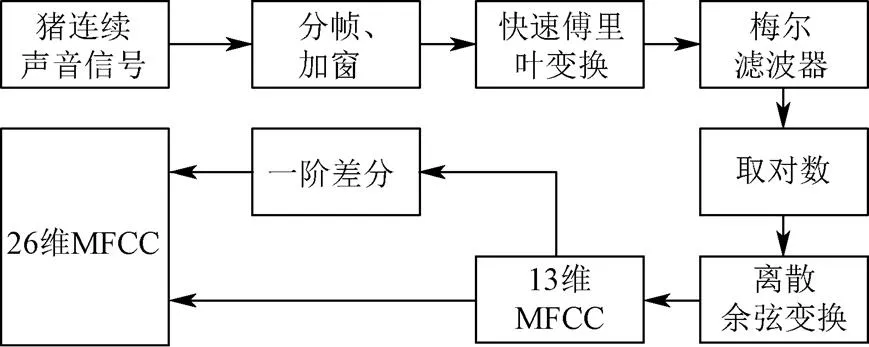
图2 MFCC特征参数提取步骤
2 猪连续咳嗽声识别
2.1 BLSTM网络模型
相对于前馈神经网络[26-27]隐层神经元之间无连接的特点,RNN(recurrent neural network)是一种允许隐层神经元存在自反馈通路的神经网络结构。RNN隐层输入不仅包括输入层输入的猪声音特征,也包括上一时刻隐层神经元的输出,这种网络结构有利于模型对前面的信息进行记忆,并应用于处理当前输出的计算中。虽然RNN理论上很适合处理类似语音序列的建模问题,但是随着语音序列长度的增加存在着梯度爆炸和消失的问题[20,28]。LSTM是一种特殊的RNN,其通过引入记忆单元和门限机制可以学习历史信息,并控制信息的累积速度,在一定程度上缓解了存在于RNN模型中的问题,LSTM模块单元如图3所示。
由图3可知LSTM单元主要由4个部分组成:记忆单元(memory cell)、输入门(input gate)、输出门(output gate)和遗忘门(forget gate)。在LSTM网络中记忆单元彼此互相连接,3个非线性门控单元可以调节输入和输出记忆单元的信息(如图3中虚线连接所示)。其中输入门控制哪些信息会被输入到记忆单元,通过读取上一时刻记忆单元输出h-1和此时刻输入x,输出一个在0和1之间的数值,i表示要输入信息的百分比,0表示全部舍弃,1表示完全输入。i计算公式为
i=(W[h-1, x]+ b) (3)
式中是sigmoid函数,W是输入门权值,b是输入门阈值。
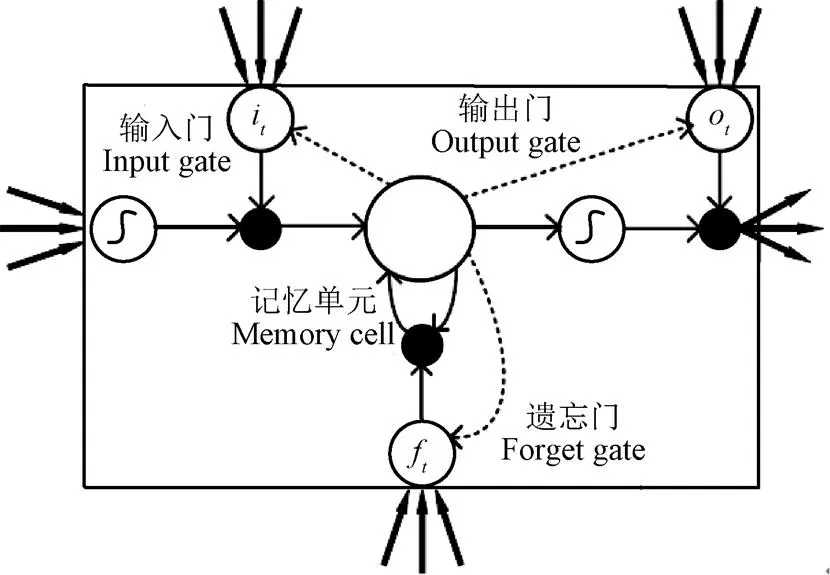
注:it表示输入信息的百分比,ft表示遗忘信息的百分比,ot输出门状态值大小,黑色实心圆表示进行乘积运算。Note: it is the percentage of the input information of input gate; ft is the percentage of the forgotten information of forget gate; ot is the state value of output gate, and the black circle indicates the multiplication operation.
类似的,遗忘门控制需要忘记上一时刻记忆单元状态c-1的哪些信息,f表示要遗忘信息的百分比,计算公式为
f=(W[h-1, x]+ b) (4)
式中W是遗忘门权值,b是遗忘门阈值。
于是可得到此时刻记忆单元的状态c计算公式如下
c= f c-1+ itanh(W[h-1, x]+ b) (5)
式中tanh是双曲正切函数,W是记忆单元权值,b是记忆单元阈值。
输出门值o控制记忆单元此时刻输出了多少信息,于是有如下计算公式
o=(W[h-1, x]+ b) (6)
h=otanh c(7)
式中W是输出门权值,b是输出门阈值,h是此时刻记忆单元输出。
传统LSTM是单向展开的,只能利用历史信息,而猪连续咳嗽声识别是对整个语音序列的识别。当前帧的特征不仅与前面各帧有联系,也与后面各帧有关联。因此通过2个独立的LSTM来分别处理前向和后向[29-30]猪连续声音序列(图4),然后将输出组合进入网络下一层进行处理,充分挖掘上下文时序信息进行猪连续声音的声学建模。
2.2 连接时序分类CTC
在连续语音识别系统中,CTC(connectionist temporal classification)层利用BLSTM学习序列信号的强大能力直接对输入语音特征和输出标签进行建模[21,31],而不必依赖语音特征序列与序列标记之间的对齐,从而实现了端到端的声学模型训练。
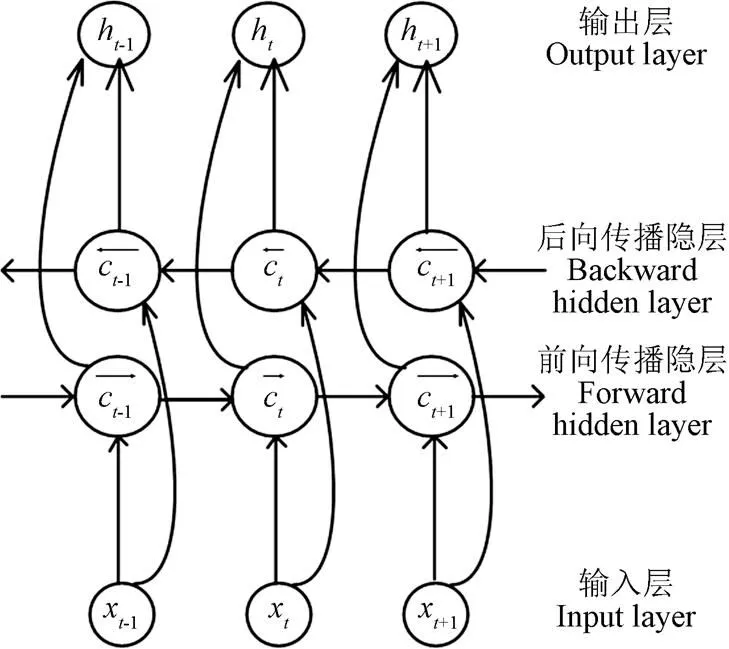
注:xt-1、xt和xt+1分别表示t-1、t和t+1时刻输入层输入, ct-1、ct和ct+1分别表示隐层记忆单元t-1、t和t+1时刻的状态值,ht-1、ht和ht+1分别表示t-1、t和t+1时刻记忆单元输出,上标→、←分别表示前向传播和后向传播。
BLSTM模型输出作为CTC层输入,输出神经元个数即所有可能的标签个数,即声学建模单元个数,额外加入一个空白标签用于估计输出的静音,在本系统中标签个数为3,即‘k’、‘n’和‘_’,其中‘_’为空白标签,表示静音模型。于是BLSTM模型的输出可以描述输入连续语音对应的标签概率分布。给定长度为的连续输入语料,在时刻BLSTM模型输出标签索引(∈{1,2,3})的概率表示为
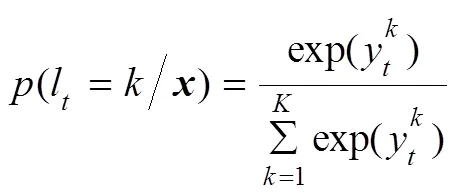
式中y是BLSTM网络时刻输出标签的值,即输出层神经元的输出值,l是BLSTM模型时刻输出的标签索引,为标签个数。
令CTC输出序列为π,则π是由个标签组成的长度为的序列,将个时刻的概率值相乘即得到π的概率为
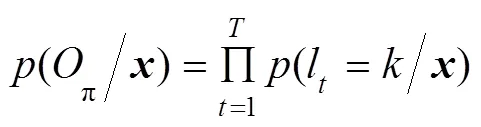
实际上,每个真实序列标记有多个CTC输出序列π与之对应,定义从π到的映射=(π),通过将可能序列中的重复标签和空白标签去掉[23]就可以将π转化为。例如,对于一个为8的猪连续声音信号,若其真实序列标记为(n, k, n, k),相应的CTC输出序列可以为(n, _, k, k, k, n, k, k)或(n, n, _, k, n, k, _, _)等。于是可得到
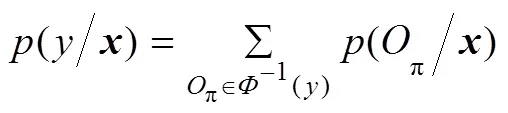
上式可利用前向后向算法[18]通过动态规划的思想计算并求导。若*为对应连续输入语料的序列标记,CTC训练目的就是让BLSTM网络输出*的概率最大化,也即概率的负导数最小化,设定损失函数为
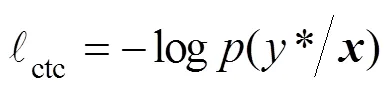
2.3 猪连续咳嗽声识别系统
图5所示为基于BLSTM-CTC声学模型的猪连续咳嗽声识别系统。首先将猪连续声音特征参数作为BLSTM输入,利用BLSTM的强大声学建模能力学习处理输入语音的特征,接着网络输出猪连续声音语料特征对应的标签概率分布,以此概率分布作为CTC层输入,同时借助原始语料序列标记计算模型损失,进一步实现整个声学模型的训练。
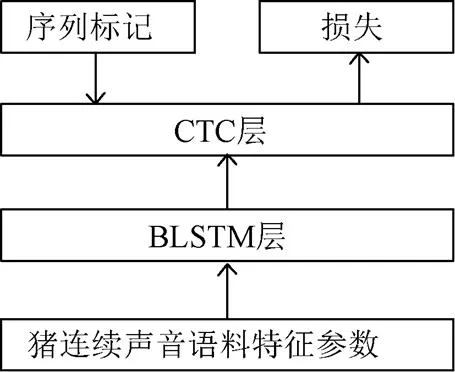
图5 猪连续咳嗽声识别系统框图
训练好的猪连续咳嗽声识别系统可以应用于猪连续声音语料的识别,测试过程会输出一个行列的概率矩阵,表示在所有时刻输入帧经过系统输出后对应标签的概率分布,通过集束收索算法[32]可解码得到最大概率输出序列,即为识别结果。
3 试验与结果分析
3.1 试验设计
对BLSTM-CTC猪连续咳嗽声识别模型进行性能评估。试验采用5折交叉验证方法进行,将222段试验数据集划分为5个大小近似相等的互斥子集,然后每次用4个子集的并集作为训练集,第5个子集作为测试集,这样就得到5组训练、测试集,从而可以进行5次训练和测试。
3.2 评价指标
在以识别基元为声学模型建模单元的连续语音识别系统中一般以词错误率[33](word error rate,WER)作为系统评价指标,将识别结果与测试语料的序列标记进行对比,计算替代误差个数(substitution)、插入误差个数(insertion)和删除误差个数(deletion)三者之和,再除以测试语料中总样本个数,得到WER,即
关于3种误差的解释如下例:序列标记为(n, , k, k, n, n),识别结果为(n,k,n, _),由识别结果与序列标记对比可知,识别结果中第一个猪咳嗽声为插入误差,第二个非猪咳嗽声为替代误差,序列标记中的最后一个非猪咳嗽声没有被识别出来,为删除误差。由于本文主要进行猪连续咳嗽声的识别,所以在识别过程中,仅考虑非猪咳嗽声的替代误差,同时忽略了非猪咳嗽声的插入和删除误差。为此,本文利用改建的WER来对猪连续咳嗽声识别系统进行性能评估,评估指标猪咳嗽声识别率R、误识别率R和总识别率total计算公式分别如下所示。
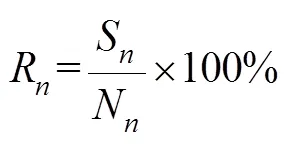
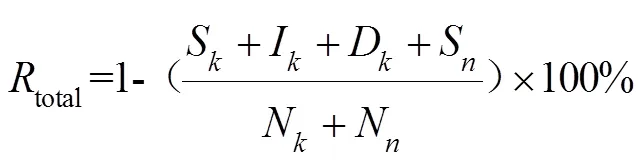
式中S、I、D、N、S、N分别表示猪咳嗽声识别为非猪咳嗽声个数、插入猪咳嗽声个数、删除猪咳嗽声个数、测试集中猪咳嗽声个数、非猪咳嗽声识别为猪咳嗽声个数、测试集中非猪咳嗽声个数。
3.3 试验参数设置与结果分析
通过多次试验对比,最终将BLSTM前向传播过程和后向传播过程隐层神经元、全连接层神经元个数均设置为300,学习率设置为0.001,训练过程最大迭代次数为200。5折交叉验证试验结果如表2所示。
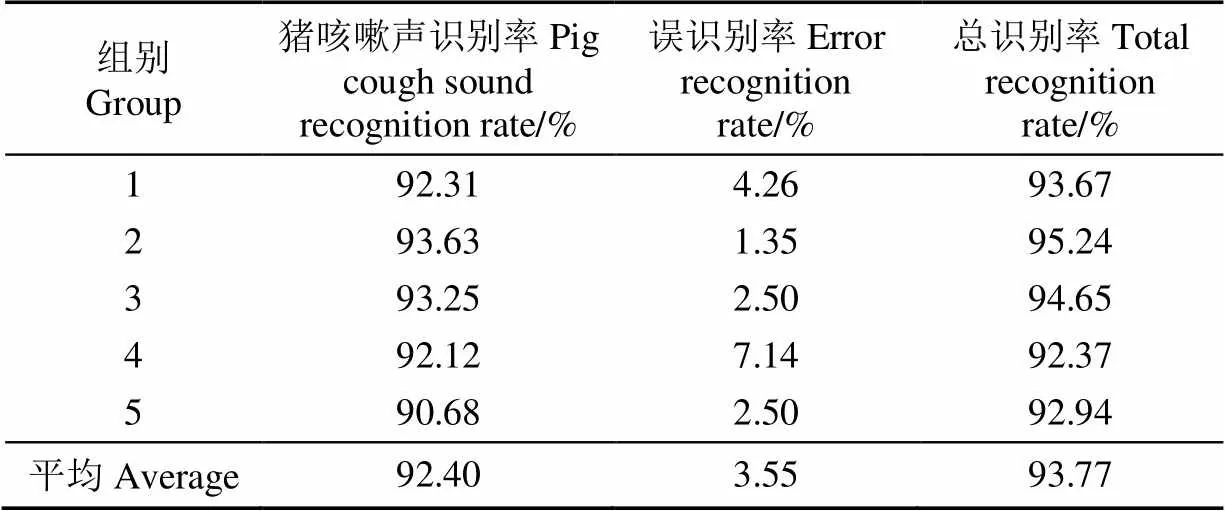
表2 猪连续咳嗽声识别5折交叉验证结果
通过表2的交叉验证试验对应的5组试验识别结果可知,各组猪咳嗽声识别率和总识别率均达到90.00%,误识别率控制在8.00%以内。并且5折交叉验证结果平均猪咳嗽声识别率达到92.40%,误识别率达到3.55%,总识别率达到93.77%,本文采用的基于BLSTM-CTC声学模型的猪连续咳嗽声识别系统是稳定有效的。
3.4 算法应用测试
为了对基于连续语音识别技术的猪连续咳嗽声识别模型进行算法应用测试,另取一段长度为1 h猪场环境语料为试验对象。先进行语音增强,然后利用基于阈值的端点检测算法获得测试数据集14段,其中最长8.51 s,最短3.56 s。此14段语料共包含声音样本74个,其中猪咳嗽样本52个,非猪咳嗽样本22个。接着对此14段测试语料进行人工句级标记,特征参数提取,最后利用表2第2组数据所得模型进行算法应用测试。测试结果猪咳嗽声发生替代误差1次、插入误差1次、删除误差1次,非猪咳嗽声发生替代误差2次。分别计算得到猪咳嗽声识别率为94.23%,误识别率为9.09%,总识别率为93.24%。算法应用测试结果表明基于连续语音识别技术的猪连续咳嗽声识别模型对于训练测试数据集外的样本同样可得到较理想的识别效果,模型稳定可靠。
4 结 论
本文提出了一种进行猪场环境猪连续咳嗽声识别的方法。该方法相对孤立词识别技术而言,可以识别更多种类的猪场环境声音,更能反映猪的患病状况,语料处理、特征提取、识别等过程比孤立词识别技术更简单。
1)提出了猪声音的声学模型,并且引入具有强大时序信号处理能力的双向长短时记忆网络结构和连接时序分类层来构建猪声音声学模型。以猪咳嗽声与非猪咳嗽声为声学建模单元,对连续语料进行了标注,实现了端到端的猪连续咳嗽声识别系统。
2)通过5折交叉验证试验,将BLSTM前向传播过程和后向传播过程隐层神经元、全连接层神经元个数均设置为300,学习率设置为0.001,5折交叉验证试验平均猪咳嗽声识别率达到92.40%,误识别率为3.55%,总识别率达到93.77%。同时,以数据集外1 h语料进行了算法应用测试。得到猪咳嗽声识别率为94.23%,误识别率为9.09%,总识别率为93.24%,表明基于连续语音识别技术的BLSTM-CTC猪连续咳嗽声识别模型是稳定可靠的。
[1] Cordeiro A, Nääs I, Leitão F, et al. Use of vocalisation to identify sex, age, and distress in pig production[J]. Biosystems Engineering, 2018, 173:57-63.
[2] Silva M, Ferrari S, Costa A, et al. Cough localization for the detection of respiratory diseases in pig houses[J]. Computers and Electronics in Agriculture, 2008, 64(2): 286-292.
[3] Mitchell S, Vasileios E, Sara F, et al. The influence of respiratory disease on the energy envelope dynamics of pig cough sounds[J]. Computers and Electronics in Agriculture, 2009, 69(1): 80-85.
[4] Sara F, Mitchell S, Marcella G, et al. Cough sound analysis to identify respiratory infection in pigs[J]. Computers and Electronics in Agriculture, 2009, 64(2): 318-325.
[5] 何东健,刘冬,赵凯旋. 精准畜牧业中动物信息智能感知与行为检测研究进展[J]. 农业机械学报,2016,47(5):231-244. He Dongjian, Liu Dong, Zhao Kaixuan. Review of perceiving animal information and behavior in precision livestock farming[J]. Transactions of the Chinese Society for Agricultural Machinery, 2016, 47(5): 231-244. (in Chinese with English abstract)
[6] Exadaktylos V, Silva M, Aerts J M, et al. Real-time recognition of sick pig cough sounds[J]. Computers and Electronics in Agriculture, 2008, 63(2): 207-214.
[7] Hirtum A V, Berckmans D. Fuzzy approach for improved recognition of citric acid induced piglet coughing from continuous registration[J]. Journal of Sound and Vibration, 2003, 266(3): 677-686.
[8] 徐亚妮,沈明霞,闫丽,等. 待产梅山母猪咳嗽声识别算法的研究[J]. 南京农业大学学报,2016,39(4):681-687. Xu Yani, Shen Mingxia, Yan Li, et al. Research of predelivery meishan sow cough recognition algorithm[J]. Journal of Nanjing Agricultural University, 2016, 39(4): 681-687. (in Chinese with English abstract)
[9] Guarino M, Jans P, Costa A, et al. Field test of algorithm for automatic cough detection in pig house[J]. Computers and Electronics in Agriculture, 2008, 62(1): 22-28.
[10] 刘振宇,赫晓燕,桑静,等. 基于隐马尔可夫模型的猪咳嗽声音识别的研究[C]//中国畜牧兽医学会信息技术分会第十届学术研讨会论文集,2015:99-104.
[11] 黎煊,赵建,高云,等. 基于深度信念网络的猪咳嗽声识别[J]. 农业机械学报,2018,49(3):179-186. Li Xuan, Zhao Jian, Gao Yun, et al. Recognitional of pig cough sound based on deep belief nets[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(3): 179-186. (in Chinese with English abstract)
[12] 陈升科. 从中兽医学角度分析猪咳嗽气喘及治疗方案[J]. 中国动物保健,2015,17(3):22-23.
[13] 陈润生. 猪咳嗽疾病的鉴别诊断[J]. 现代农业科技,2016(14):269-270.
[14] Milone D H, Galli J R, Cangianoc C A, et al. Automatic recognition of ingestive sounds of cattle based on hidden markov models[J]. Computers and Electronics in Agriculture, 2012, 87(3): 51-55.
[15] Reby D, Andreobrecht R, Galinier A, et al. Cepstral coefficients and hidden markov models reveal idiosyncratic voice characteristics in red deer (cervus elaphus) stags[J]. Journal of the Acoustical Society of America, 2006, 120(6): 4080-4089.
[16] Milone D H, Rufiner H L, Galli J R, et al. Computational method for segmentation and classification of ingestive sounds in sheep[J]. Computers and Electronics in Agriculture, 2009, 65(2): 228-237.
[17] Trifa V M, Kirschel A N, Taylor C E, et al. Automated species recognition of antbirds in a mexican rainforest using hidden markov models[J]. Journal of the Acoustical Society of America, 2008, 123(4): 2424-2431.
[18] Sepp H, Jurgen S. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[19] 陈英义,程倩倩,方晓敏,等. 主成分分析和长短时记忆神经网络预测水产养殖水体溶解氧[J]. 农业工程学报,2018,34(17):183-191. Chen Yingyi, Cheng Qianqian, Fang Xiaomin, et al. Principal component analysis and long short-term memory neural network for predicting dissolved oxygen in water for aquaculture[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE),2018, 34(17): 183-191. (in Chinese with English abstract)
[20] Bengio Y, Frasconi P, Simard P. The problem of learning long-term dependencies in recurrent networks[C]// IEEE International Conference on Neural Networks. IEEE, 1993: 1183-1188.
[21] 王智超,张鹏远,潘接林,等. 连接时序分类准则声学建模方法优化[J]. 声学学报,2018,43(6): 984-990.
Wang Zhichao, Zhang Pengyuan, Pan Jielin, et al. Optimization of acoustic modeling method with connectionist temporal classification criterion[J]. Acta Acustica, 2018,43(6): 984-990. (in Chinese with English abstract)
[22] Bahdanau D, Chorowski J, Serdyuk D, et al. End-to-end attention-based large vocabulary speech recognition[C]// IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2016: 4945-4949.
[23] Graves A, JaitlyA N. Towards end-to-end speech recognition with recurrent neural networks[C]// International Conference on Machine Learning, 2014: 1764-1772.
[24] Chia A O, Hariharan M, Yaacob S, et al. Classification of speech dysfluencies with mfcc and lpcc features[J]. Expert Systems with Applications, 2012, 39(2): 2157-2165.
[25] 李志忠,腾光辉. 基于改进MFCC的家禽发声特征提取方法[J]. 农业工程学报,2008,24(11):202-205.
Li Zhizhong, Teng Guanghui. Feature extraction for poultry vocalization recognition based on improved MFCC[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2008, 24(11): 202-205. (in Chinese with English abstract)
[26] Hinton G E. Learning multiple layers of representation[J]. Trends in Cognitive Sciences, 2007, 11(10): 428-434.
[27] Lecun Y, Bengio Y, Hinton G E. Deep learning[J]. Nature, 2015, 512: 436-444.
[28] 赵明,杜回芳,董翠翠,等. 基于word2vec和LSTM的饮食健康文本分类研究[J]. 农业机械学报,2017,48(10):202-208. Zhao Ming, Du Huifang, Dong Cuicui, et al. Diet health text classification based on word2vec and LSTM[J]. Transactions of the Chinese Society for Agricultural Machinery, 2017, 48(10): 202-208. (in Chinese with English abstract)
[29] Schuster M, Paliwal K K. Bidirectional recurrent neural networks[J]. IEEE Transactions on Signal Processing, 2002, 45(11): 2673-2681.
[30] Chen K, Huo Q . Training deep bidirectional LSTM acoustic model for LVCSR by a Context-Sensitive-Chunk BPTT approach[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2016, 24(7): 1185-1193.
[31] Woellmer M , Eyben F , Schuller B , et al. Spoken term detection with connectionist temporal classification: A novel hybrid CTC-DBN decoder[C]//International Conference on Acoustics Speech and Signal Processing (ICASSP). IEEE, 2010: 5274-5277.
[32] Graves A, Gomez F. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks[C]// International Conference on Machine Learning. ACM, 2006: 369-376.
[33] Abu-Khzam F N, Fernau H, Langston M A, et al. A fixed-parameter algorithm for string-to-string correction[C]// Sixteenth Symposium on Computing: the Australasian Theory(CATS 2010). Australian Computer Society, 2010: 31-37.
Pig continuous cough sound recognition based on continuous speech recognition technology
Li Xuan1,2, Zhao Jian1,2, Gao Yun1,2, Liu Wanghong2,3, Lei Minggang2,3, Tan Hequn1,2
(1.,,430070,; 2.,430070,; 3.,,,430070,)
Cough is one of the most frequent symptoms in the early stage of pig respiratory diseases. So it is possible to monitor and diagnose the diseases of pigs by detecting their coughs. The existing methods for pig cough recognition are based on key word recognition technology, which cannot recognize the samples that have not been trained or learned by itself, another drawback is that the methods are for isolated coughs while the coughs of sick pigs are usually continuous. This paper intends to realize the recognition of pig continuous cough sound based on continuous speech recognition technology. Ten Landrace pigs, with a body weight of about 75 kg, were used as sound collection objects, and pig sounds were collected in pig farms during late winter and early spring when the respiratory diseases of pigs were prevalent. The sound collection devices were working continuously all day. By selecting the frequent coughing phases in the collected signal, a total of 30 h pig farm sound signals were obtained as the experimental corpus. Firstly, the sound signals were denoised by the speech enhancement algorithm based on a psychoacoustical model. Then the time-domain characteristics, including duration and energy of individual cough, were studied, and it was found that the duration of pig cough ranged from 0.24 to 0.74 s and the energy ranged from 40.15 to 822.87V2·s. So threshold of the sound samples was set with the duration and the lower energy value of individual coughs. Based on the threshold range, the speech endpoint detection algorithm based on short-time energy was used to detect the 30 h pig field sound signals which had been preprocessed by the speech enhancement algorithm, and 222 experimental sentences were obtained. The longest was 9.14 s and the shortest was 3.91 s. All 222 corpus contained a total of 1 145 sound samples, including 751 pig coughs and 394 non-pig coughs. Sounds in the pig farm environment, including cough, sneeze, eating, scream, hum, shaking ears sounds of pigs and sounds of dogs, metal clanging and some other background noise, were divided into pig cough and non-pig cough, which were chosen as the acoustic modeling units. The labels of the experimental sentences were obtained with the help of experts. Then the 13-dimensional Mel frequency cepstrum coefficients (MFCC) reflecting the static characteristics of pig sound were extracted, and the first-order differential coefficients reflecting the dynamic characteristics of pig sound were added to obtain the 26-dimensional MFCC, which were used as the characteristic parameter of the experimental sentence. Finally, the bidirectional Long Short-term Memory-Connectionist temporal classification(BLSTM-CTC) model was selected to recognize the pig continuous sounds, specifically, the BLSTM network had excellent feature learning ability of continuous pig sounds, and the CTC could directly model the alignment of the input continuous pig sound sequence and its labels. Through the 5-fold cross-validation experiment and analysis, the number of hidden layer neurons in the BLSTM forward propagation process, the backward propagation process, and the fully connected layer, were all set to 300, and the learning rate was set to 0.001. The average recognition rate, error recognition rate and total recognition rate of the results of 5 groups were 92.40%, 3.55% and 93.77%, respectively. Furthermore, the algorithm application test was carried out with another 1 h data, and the recognition rate reached to 94.23%, the error recognition rate was 9.09% with the total recognition rate of 93.24%. It is indicated that the pig cough sound recognition model based on continuous speech recognition technology is stable and reliable. This paper provides a reference for the recognition and disease judgment of pig continuous cough sound during the healthy breeding of pigs.
signal processing; acoustic signal; recognition; pig industry; continuous cough; birectional long short-term memory-connectionist temporal classification; acoustic model
2018-11-09
2019-01-13
国家重点研发计划项目(2018YFD0500700);华中农业大学自主科技创新基金;华中农业大学大北农青年学者提升专项项目(2017DBN005);现代农业产业技术体系项目(CARS-36);国家级大学生创新创业训练计划(201810504074)
黎煊,副教授,博士,主要从事生猪信息智能感知与行为识别研究。Email:lx@mail.hzau.edu.cn
10.11975/j.issn.1002-6819.2019.06.021
TN912.34
A
1002-6819(2019)-06-0174-07
黎 煊,赵 建,高 云,刘望宏,雷明刚,谭鹤群. 基于连续语音识别技术的猪连续咳嗽声识别[J]. 农业工程学报,2019,35(6):174-180. doi:10.11975/j.issn.1002-6819.2019.06.021 http://www.tcsae.org
Li Xuan, Zhao Jian, Gao Yun, Liu Wanghong, Lei Minggang, Tan Hequn. Pig continuous cough sound recognition based on continuous speech recognition technology[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(6): 174-180. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2019.06.021 http://www.tcsae.org
猜你喜欢
小主人报(2022年17期)2022-11-21
作文成功之路·小学版(2021年3期)2022-01-01
作文成功之路·教育教学研究(2021年3期)2021-06-06
家庭影院技术(2020年6期)2020-07-27
中国听力语言康复科学杂志(2019年3期)2019-06-24
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
中国高新技术企业(2017年5期)2017-05-05
物联网技术(2016年11期)2017-01-12
