
一种考虑交叉学科特点的智慧图书推荐方法
2019-05-08 03:29王茜喻继军
新世纪图书馆 2019年3期
王茜?喻继军


摘 要 论文根据专业课程信息及图书馆中的图书信息,采用主题词分析方法计算专业之间的交叉系数,在关联规则算法的基础上,综合考虑读者的专业背景及借阅记录中图书之间的关联关系,提出一种既满足读者对交叉学科知识的需要、又满足对图书多样性需求的参数化智慧图书推荐方法。
关键词 交叉学科 图书推荐 智慧图书馆
分类号 G256
DOI 10.16810/j.cnki.1672-514X.2019.03.015
0 引言
随着云计算、大数据、物联网等技术的迅猛发展,基于互联网的各种应用层出不穷,引发数据规模的爆炸式增长,大数据给社会带来变革性发展的同时,也带来巨大的“信息过载”问题[1-3]。推荐系统作为解决大数据时代信息过载的有效方法,已广泛应用于电子商务、社交网络、信息检索、图书推荐等各个领域。在图书馆管理领域,高校图书馆系统也面临着海量信息资源的新挑战,随着书目数量的与日俱增以及图书内容的日新月异,读者越来越难以从图书资源中快速获取所需的信息。如何引导读者从海量的信息中找到满足知识需求的信息,为读者提供个性化的主动服务已成为高校图书馆发展过程中需要解决的重要课题。目前,在图书馆图书的个性化推荐领域,常用的推荐方法主要可分为四类:基于关联规则的推荐方法;基于内容的推荐方法;基于协同过滤的推荐方法;融合其它领域知识的推荐方法。在图书馆借阅服务中,读者往往不会对借阅图书进行评分,读者与图书馆之间的互动反馈较为匮乏,其他领域中的推荐方法难以在图书推荐中加以应用。因此,現有推荐方法多以读者的借阅记录作为数据集,关联规则成为图书个性化推荐模型的主要方法。但是,在交叉学科发展的背景下,现有基于关联规则的推荐方法存在以下问题。
一是推荐方法中没有考虑交叉学科的特点。学科是对人类知识体系的划分。由于自然界、人类社会和个体本身具有整体性,许多问题的解决都需要综合运用多种学科知识来实现,例如高铁、飞机制造、环境治理等问题都涉及多个学科知识领域。近代科学中的重大发现和重要问题的解决,常常依赖于多个学科的知识交流和相互渗透。因此,近年来,交叉科学的研究与发展越来越成为研究的热点。在新时代背景下,《国家中长期科学和技术发展规划纲要(2006—2020年)》 也指出:“加强基础科学和前沿技术研究,特别是交叉学科的研究”[4]。高校各交叉学科的发展,离不开在校学生对交叉专业知识的学习和掌握。图书馆作为学生自我学习和掌握新知识的主要服务场所,在培养学生掌握融合知识能力的过程中起着至关重要的作用[5-6]。因此,根据学生的专业背景,为学生准确地进行基于交叉学科的图书推荐,对于新时代背景下提高图书馆个性化服务水平有着重要的意义。
二是推荐方法中没有考虑图书推荐的多样性。多样性的推荐方法最早在检索领域被提出[7],其目的是为了避免推荐结果的同质化问题,即推荐结果种类过于相似或向不同用户推荐同一种类项目[8]。在图书推荐领域,为满足读者广泛的兴趣爱好,同样需要提供多样性的图书推荐。高校在培养学生专业知识的同时,提高学生阅读的广泛性,既是培养学生兴趣的需要,也是促进交叉学科知识融合的需要。因此,提高图书推荐结果的准确率和多样性是交叉学科发展背景下提高图书馆个性化服务需要实现的重要功能。
基于此,本研究以图书信息和学生的专业背景为基础,对学生所选专业的课程信息采用主题词分析方法计算专业之间的交叉系数,同时根据图书信息建立分类模型,提出一种考虑交叉学科特点的智慧图书推荐方法,以满足学生对交叉专业知识的需要,同时满足对图书多样性的需要,从而为图书馆个性化服务提供参考。
1 相关研究评述
近年来,随着高校图书馆不断进行数字资源的信息化建设,积累了大量的图书信息和读者借阅记录,其中蕴含的大数据已成为一种重要的信息资源,引起了国内外学者的关注。现有图书馆个性化服务的研究即是基于大数据分析而来,其主要集中在三个方面:个性化推荐方法的研究;读者需求及行为研究;图书馆管理相关研究。
推荐系统作为大数据时代解决信息过载的有效工具,其技术核心是推荐方法。现有的个性化推荐技术主要包括:基于协同过滤的推荐、基于社交网络的推荐、基于矩阵分析的推荐、基于情境感知的推荐、基于深度学习的推荐及融合各种数据源的混合推荐等。其中,在个性化推荐方法领域,孙彦超等学者运用协同过滤算法解决图书推荐问题[9-10];国外学者Wei等人采用模糊数学算法降低图书索引维度,通过对矩阵采取降维的方法以提高推荐结果的准确率[11];柳益君等学者分析了高校图书馆大数据发展的状况,提出大规模网络分析方法在图书馆中的应用模式[12];王顺箐学者提出一种基于用户画像的个性化推荐框架[13];杨利军等研究了图书馆个性化服务中的大数据可视化问题,帮助读者更好地理解数据[14];马仲兵教授通过加权方式改善关联规则的推荐模式,为读者提供更加人性化的图书推荐[15];袁虎声等学者根据热量传播理论提出基于加权网络的图书推荐[16];彭博教授通过挖掘读者属性进行关联规则的推荐[17];唐晓波等学者运用基因组原理对图书进行推荐研究[18];蓝冬梅等学者通过收集当当网电子商务用户的评分数据,将评分信息与高校图书馆信息进行结合,根据二部图原理进行网络图书推荐[19]等。
近年来,随着社会进入“交叉学科时代”,高校的自主创新能力及学科间的交叉融合已成为高校新的增长点及提升核心竞争力的重要体现[20]。交叉学科知识创新的过程,往往伴随着多个相关学科的知识融合,而在图书馆的图书中就存在着大量的知识组合关系。作为学生获取融合知识的主要场所,个性化图书馆服务在交叉学科发展中也扮演着越来越重要的角色。Kaemmerer等人研究了医学康复领域基于交叉医学知识的推荐[21];郑文涛等人研究了双一流背景下交叉学科发展的重要性[22-23],商宪丽教授针对图书馆知识的交叉主题进行了研究[24],邵瑞华等学者采用文献计量学方法研究了学科交叉程度与文献学术影响力的关系[25],张洪磊等学者从复杂网络的角度,采用社会网络分析方法和UCINET工具对近年来发表的文献进行交叉学科知识发现的研究[26],魏建香等学者研究了交叉学科的知识可视化问题[27]。
综上所述,现有基于图书的个性化推荐服务主要以提高推荐结果的准确率为目标,而交叉学科的研究多集中于学科建设和人才培养模式或者交叉学科之间的知识发现等问题,基于交叉学科的图书推荐研究相对较少。本文基于专业课程的主题词分析,并结合学生的历史借阅记录,提出一种考虑交叉学科特点的图书推荐方法。
2 智慧图书推荐方法
2.1 总体构想
首先,对专业课程信息进行主题词分析,基于主题词建立交叉学科的主题词矩阵,并计算专业之间的交叉系数。然后,根据图书信息构建图书分层模型。接着,根据读者历史借阅记录、读者所在专业的交叉系数以及图书在分层模型中的距离,采用参数化方法综合计算图书之间的关联度。最后,采用关联规则算法根据关联度大小进行排序,选取符合条件的图书对读者进行推荐,其实施框架如图1所示。
其中Q(SWi)表示种子词SWi的权重,p(wij)表示种子词SWi的第j个元素的概率分布。
按照上述方法,即可获得给定文本中最重要且相互独立的用种子词表示的词类,这些种子词称为该文本的主题因子,将这些主题因子按权重降序排列输出,就得到文本的主题。在获得各专业主题之后,即可建立主题类别矩阵,并按公式(1) 计算主题词的共现频率和余弦测度,从而计算出各专业之间的交叉系数。
2.2.2 根据图书信息构建分类层次模型
关联规则反映一个事物与其他事物之间的相互依存性和关联性,如果两个或者多个事物之间存在一定的关联关系,那么,其中一个事物就能够通过其他事物进行预测。传统的关联规则随着图书种类数量的增加,获取的难度也随之增加。本研究通过分层模型将具体图书按其所属的类别进行抽象,即可构造出一颗分类树,树中的叶子节点为具体的图书名称,父节点是下一级图书所属的大类。在挖掘的过程中,可运用中间节点进行多层关联规则挖掘。
获取整体关联度之后,即可根据读者的历史借阅记录采用关联规则算法进行挖掘,选择符合条件的频繁项并按关联度大小排序,选取前若干个结果向读者推荐。目前,关联规则算法主要有:Apriori,DHP,Tree Projection,FP-tree等。由于FP-Tree算法比其他算法具有更高效的时间复杂度优势[41],本文采用 FP-Tree算法进行挖掘,算法如下。
输入:读者历史借阅记录数据库D,设置最小支持度阈值。
输出:频繁模式的完全集;按以下步骤构造 FP-Tree。
步骤1:扫描借阅记录数据库D,计算支持度并建立频繁项集合。
步骤2:继续扫描数据,删除支持度低于阈值的项,并按照支持度降序排列,建立频繁项集L。
步骤3:构建 FP树。对D中的每个事务 T执行以下操作:选择 T中的频繁项,并按 L中次序排序。设排序后频繁项集为[x,L-x],其中x是第一个元素,L-x是剩余元素的表。按以下方式生成FP树,记为Insert-Tree([x,L-x],T)。该过程执行如下: 如果T事务中有子节点N,使得N节点的项目为X项目,则 N计数增加1;否则创建一个新节点N链接到它的父节点T, 并通过节点链式结构将其链接到具有相同书目名称的节点;如果L-x非空,递归地调用Insert-Tree([x,L-x],T)。直到所有的数据都插入到FP树后,FP树的建立完成。
步骤4:从FP树查找条件模式基。从条件模式基递归挖掘频繁项集,并计算置信度。
步骤5:设置最小置信度,采用交叉验证方法获取α,β,γ,选择符合置信度阈值的频繁项,并根据支持度和置信度按公式(8) 计算整体关联度,按关联度大小按降序排序选择前N个关联规则,针对读者按该关联规则推荐。
3 实验分析
3.1 樣本选取和预处理
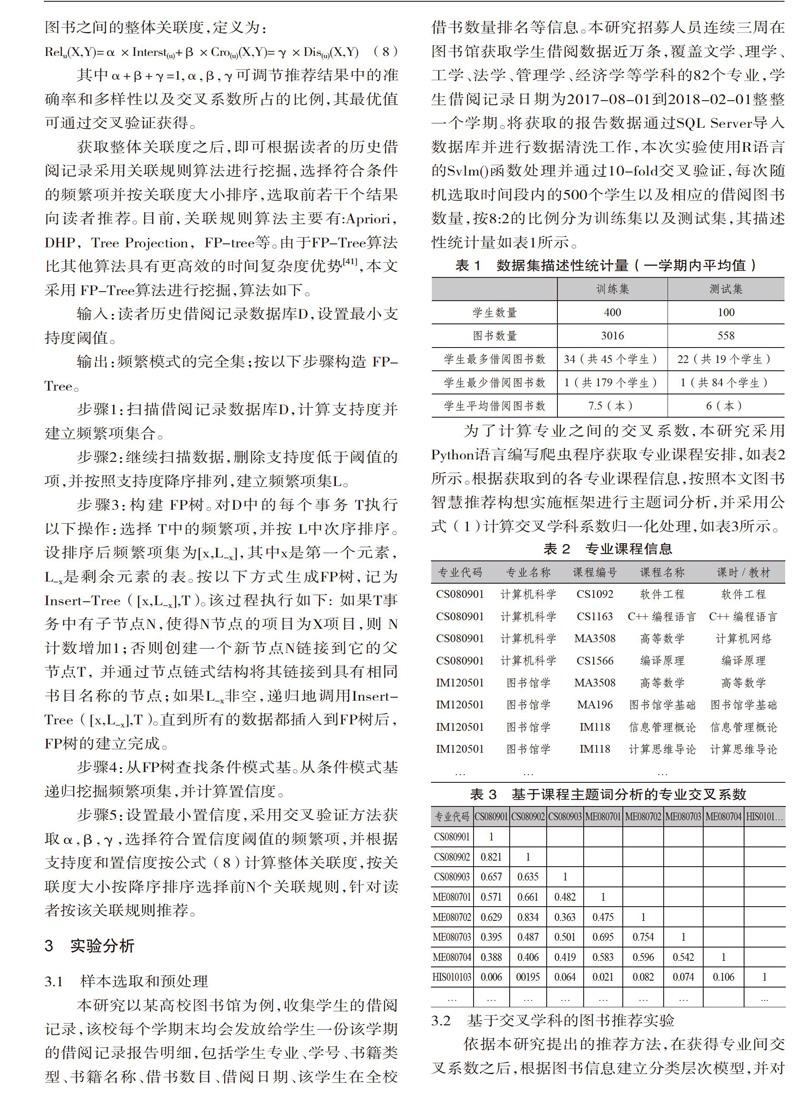
本研究以某高校图书馆为例,收集学生的借阅记录,该校每个学期末均会发放给学生一份该学期的借阅记录报告明细,包括学生专业、学号、书籍类型、书籍名称、借书数目、借阅日期、该学生在全校借书数量排名等信息。本研究招募人员连续三周在图书馆获取学生借阅数据近万条,覆盖文学、理学、工学、法学、管理学、经济学等学科的82个专业,学生借阅记录日期为2017-08-01到2018-02-01整整一个学期。将获取的报告数据通过SQL Server导入数据库并进行数据清洗工作,本次实验使用R语言的Svlm()函数处理并通过10-fold交叉验证,每次随机选取时间段内的500个学生以及相应的借阅图书数量,按8:2的比例分为训练集以及测试集,其描述性统计量如表1所示。
为了计算专业之间的交叉系数,本研究采用Python语言编写爬虫程序获取专业课程安排,如表2所示。根据获取到的各专业课程信息,按照本文图书智慧推荐构想实施框架进行主题词分析,并采用公式(1) 计算交叉学科系数归一化处理,如表3所示。
3.2 基于交叉学科的图书推荐实验
依据本研究提出的推荐方法,在获得专业间交叉系数之后,根据图书信息建立分类层次模型,并对学生的借阅记录采用公式(5)(6) 计算图书之间基于分类模型的支持度和置信度,如表4所示。然后根据支持度、置信度、交叉系数以及图书在分类模型中的距离,采用交叉验证的方法获取α,β,γ,按公式(8) 计算整体关联度,之后再按照本文2.2小节中的算法选择满足阈值的频繁项对学生进行相应图书类别的推荐。
考虑交叉学科特点的图书推荐方法与其他三种方法相比,在各指标上都有明显的提高。协同过滤推荐算法没有考虑专业知识的因素,纯粹根据学生的历史记录进行推荐,随着学生和图书数量的增加,其准确率、覆盖率和多样性均有明显下降。在与二部图的多样性推荐算法的比较中,二部图的多样性推荐方法采用基于网络的模式进行推荐,基于网络的推荐依赖于读者共同借阅图书的数量,随着推荐列表的增加,推荐结果在准确率方面和本文研究的方法越来越接近,但由于共同借阅书籍的数量较少,导致覆盖率和多样性方面仍然不如本研究的方法,如图4、图5所示。传统基于关联规则的推荐在各指标方面的比较也比本研究的方法低近4%,具体数值如表5所示。
4 结论
本文采用主题词分析方法研究读者所学专业的交叉系数,结合图书信息的分层模型,提出并验证了一种考虑交叉学科特点的智慧图书推荐方法。实验结果表明,该方法与其它推荐方法相比,在各性能指标方面,均可获得更理想的结果。本研究提出的新方法具有以下特点:(1)根据读者的专业背景和借阅记录,能够更好地为读者提供符合专业需求和知识融合的图书推荐,提高了推荐结果的准确性,从而更好地改善读者的个性化体验;(2)在传统关联规则算法的基础上,建立图书信息的分层模型,从而更好地挖掘图书之间的关联关系并提高了推荐结果的多样性,更好地满足了读者广泛的兴趣需求;(3)本研究采用参数化方法将交叉系数,图书之间在分类树中的距离融入到推荐模型中,从而使得推荐方法可通过调节参数灵活配置推荐结果中图书的相关性和多样性,为图书馆在大数据环境下实施推荐系统提供灵活的框架,有助于提升图书馆的个性化服务水平。另外,新方法对于高等院校制定图书采购计划也具有一定的参考意义。
本文主要探讨考虑交叉学科特点的图书推荐,还有些问题有待进一步研究。本研究基于各专业开展的课程信息进行交叉学科之间的交叉测度计算,但学科交叉不仅体现在课程上,也体现在各个学科的学术文献中。由于目前对交叉学科的概念在学术界还没有形成统一的定义,如何采用更准确更合理的交叉学科测度方法,以获得更好的实验结果是本研究进一步的研究方向。另外,如果从心理学的角度对读者做更全面的综合分析,推荐结果将会更为理想。
参考文献:
OESTREICHERSINGER G, SUNDARARAJAN A.
Recommendation networks and the long tail of electronic commerce[J]. Management Information Systems Quarterly, 2012,36(1):65-83.
MARZ N, WARREN J. Big data: principles and best practices of scalable realtime data systems[J]. Pearson Schweiz Ag, 2013.
朝乐门,邢春晓,张勇.数据科学研究的现状与趋势[J].计算机科学,2018,45(1):1-13.
国家中长期科学和技术发展规划纲要(2006—2020)[EB/OL].[2018-04-02].http://www.fmprc.gov.cn/ce/cekor/chn/kjjl/kjzc/t802179.htm.
郑晓瑛.交叉学科的重要性及其发展[J].北京大学学报(哲学社会科学版), 2007, 44(3):141-147.
陆康.数字人文环境下图书馆读者需求与行为统计分析实践[J].新世纪图书馆, 2018(3):31-35.
HURLEY N, NEIL J, ZHANG M. Novelty and diversity in top-N recommendation: analysis and evaluation[J]. ACM Transactions on Internet Technology,2011,10(4):243-254.
LIU J G, SHI K, GUO Q. Solving the accuracy-diversity dilemma via directed random walks[J]. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2012, 85(2):016118.
孙彦超,韩凤霞.基于协同过滤算法的个性化图书推荐系统的研究[J].图书馆理论与实践,2015(4):99-102.
陈金菊.基于数据挖掘的读者个性化服务研究[J].图书馆学研究,2016(23):84-91.
WEI Y, LI H. Thelibrary evaluation based on the pca and fuzzy-c means[C]// International Conference on Artificial Intelligence and Computational Intelligence. IEEE, 2009:167-171.
柳益君,何胜,冯新翎,等.大数据挖掘在高校图书馆个性化服务中应用研究[J].图书馆工作与研究,2017, 1(5):23-29.
王顺箐.以用户画像构建智慧阅读推荐系统[J].图书馆学研究,2018(4):92-96.
杨利军,高军.图书馆个性化服务中的大数据可视化分析与应用研究[J].现代情报,2015,35(7):68-72.
马仲兵.基于关联规则的高校图书馆个性化推荐模型[J].新世纪图书馆,2013(7):42-44.
袁虎声,赵洗尘.基于加权借阅网络的个性化推荐算法与实现[J].图书情报工作, 2016(10):130-134.
彭博.面向用户属性的个性化图书推荐方法探究[J]. 图书馆工作与研究,2017(10):118-123.
唐晓波,周咏.基于图书基因组的个性化图书推荐研究[J].图书馆学研究,2017(2):76-85.
蓝冬梅.大数据量图书下多数据集的二部图多样化推荐[J]. 情报理论与实践,2016,39(2):69-72.
张宇峰.学科交叉融合的趋势与现代图书馆工作的方向[J].图书情报工作,2009(S2):13-14.
KAEMMERER H, BAUER U, DE H F, et al. Recommendations for improving the quality of the interdisciplinary medical care of grown-ups with congenital heart disease(GUCH)[J]. International Journal of Cardiology,2011,150(1):59-64.
郑文涛. “双一流”背景下的高校交叉学科建设研究[J].首都师范大学学报(社会科学版),2018(1):160-166.
郑茹,袁曦临,宋歌.跨学科战略规划对大学人文社会科学国际化发展的影响:基于文献计量学分析视角[J].新世纪图书馆,2017(3):14-21.
商宪丽.基于多模主题网络的交叉学科知识组合模式研究:以数字图书馆为例[J].情报科学,2018,36(3):130-137.
邵瑞华,李亮,刘勐.学科交叉程度与文献学术影响力的关系研究:以图书情报学为例[J].情报杂志, 2018(3):146-151.
张洪磊,魏建香,杜振东,等.基于社会复杂网络的学科交叉研究[J]. 情报杂志,2011,30(10):25-29.
魏建香.学科交叉知识发现及其可视化研究[D].南京:南京大学, 2010.
许海云,尹春晓,郭婷,等.学科交叉研究综述[J].图书情报工作,2015, 59(5):119-127.
PORTER A L, COHEN A S, ROESSNER J D, et al. Measuring researcher interdisciplinarity[J]. Scientometrics,2007,72(1):117-147.
王建明,袁偉.基于节点表的FP-Growth算法改进[J].计算机工程与设计,2018(1):140-145.
SHANI G, GUNAWARDANA A. Evaluating recommendation systems[J]. Recommender Systems Handbook, 2010:257-297.
猜你喜欢
科学导报(2018年25期)2018-05-14
大学生(2017年3期)2017-03-21
东方教育(2016年20期)2017-01-17
新世纪图书馆(2016年11期)2017-01-13
中学教学参考·文综版(2016年10期)2016-12-13
数字技术与应用(2016年9期)2016-11-09
企业导报(2016年8期)2016-05-31
商(2016年4期)2016-03-24
科技视界(2016年3期)2016-02-26
中国石油大学学报(社会科学版)(2015年1期)2015-03-10
