
机器学习算法在糖尿病预测中的应用
2019-04-30 07:40菊云霞周薏岚
贵州大学学报(自然科学版) 2019年2期
贺 其,赵 岗,菊云霞,周薏岚,李 敏,董 琪,赵 凯
(1.齐鲁师范学院 数学学院,山东 济南 250200; 2.山东师范大学 信息科学与工程学院,山东 济南 250014; 3.齐鲁工业大学(山东省科学院) 电气工程与自动化学院,山东 济南 250353)
科技不断进步与发展,大数据时代已经到来,面对各种纷繁复杂,基数巨大的数据,如何在其中提取挖掘出最有价值的信息,为企业、团体或个人决策提供科学的依据显得尤为重要。最近几年,机器学习受到了企业、学校、学术研究机构的广泛关注。机器学习[1-3](Machine Learning, ML)是一门跨越多个领域的交叉学科,涉及统计学、概率论等多门学科,机器学习算法是从已有数据中分析挖掘获得规律,并利用这些规律对未知数据做出预测。利用机器学习的算法对数据做处理、分析、预测可以应用到很多领域。文献[4]中阐述了机器学习方法在金融领域的应用。文献[5]介绍机器学习这一智能化探索型数据分析手段为处理地理学中普遍存在的高维非线性噪声数据提供了方法支撑。文献[6]研究了支持向量机算法在翻译风格研究中的应用。文献[7]介绍了机器学习方法在水文地质中的研究。
在医学领域应用机器学习算法,可以有效节约各种人力、物力、财力,提高医生的看病效率,缓解就医难的问题。糖尿病作为多发病和严重的慢性病,患病率呈现逐步上升的趋势。并且一直以来是受到医学界、研究机构的广泛关注。世界卫生组织发布的《全球糖尿病报告》[8],指出全球糖尿病患者人数已达到4.22亿人,这些患病的人主要集中在中低收入国家。糖尿病分为1型糖尿病和2型糖尿病,患者罹患2型糖尿病的占大多数。利用机器学习算法对2型糖尿进行预测的研究比较多[9-13]。糖尿病可能导致多种并发症包括视力减退、中风、心脏病发作,这将会给患者的身心健康造成严重伤害。糖尿病也会给患者及其家庭带来较重的经济负担。
我们选用了神经网络、逻辑回归、决策树、贝叶斯、支持向量机五种机器学习算法进行了预测,如图1是机器学习算法预测糖尿病的过程。五种方法比较,实验结果显示决策树预测的更好,所以我们重点选用了决策树进行预测,并根据数据特性选用合理的方法标准化数值特征。

图1 机器学习算法预测糖尿病的过程Fig.1 The process of machine learning algorithm to predict diabetes
1 决策树
在机器学习算法中,决策树是非常重要的算法之一,决策树也被叫做判定树。根据不同的特征点信息对给出的数据集进行划分,最终结果得到的是一棵树。每个划分集存放在相应的子树里。决策树的决策过程是从决策树的根节点开始的,待测数据与决策树中的特征节点进行比较,依照比较结果选择相应的分支。决策树的学习过程如下:首先是特征选择,从给定的训练数据的特征点中选择其中一个作为节点的分裂选择标准。其次是决策树的生成,要依据所选标准,从上到下递归地生成对应的子节点,一直到数据集不可再分则停止生成。最后是对树剪枝,决策树很容易产生过拟合,针对这种情况需要通过剪枝来解决这一问题。
1.1 决策树的基本算法
决策树的基本算法如下[14]:
(1)输入:训练集Z={ (x1,y1,z1),(x2,y2,z2),…,(xm,ym,zm)};属性集B={b1,b2,…,bn}。
(2)过程:函数TG(Z,B)
①生成结点n;
②ifZ样本全属于同一类别A, then
③将n标记为A类叶结点;return
④end if
⑤IfB是空集orZ中样本在B上取值相同
⑥then
⑦将n标为叶节点,类别则标为Z样本数最多的类;return
⑧end if
⑨从B中选择最优划分属性b*;
⑩forb*的每一个值b*vdo
(3)输出:以n为根节点的一颗决策树。
从以上决策树算法中可以得出,生成决策树是一个递归的过程。
1.2 划分选择
从决策树的算法中,希望决策树分支节点所包含的样本应尽可能地属于同一个类别,即节点纯度越来越高。信息熵是用来评价样本集合纯度的最常用指标。
假定集合A中第n类样本所占的比例为pn(n=1,2,…,|x|),则A的信息熵定义公式为
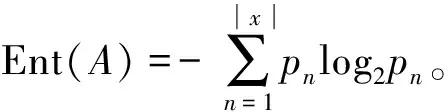
(1)
Ent(A)的值越小,则A的纯度越高。
进行决策树的划分属性选择,用到信息增益。b有V个可能取值,要使用b对样本A进行划分,将会产生V个分支叶节点。要对样本集A进行划分属性b所获得的“信息增益”如公式(2),信息增益越大,则属性b划分所获得的“纯度提升”越大。
(2)
1.3 剪枝处理
在决策树学习过程中,由于节点划分过程不断地重复,会造成决策树分支过多,这时会导致训练样本学的过于好,产生过拟合。采取的措施是通过主动去掉一些分支,来降低过拟合的风险。
决策树剪枝分为预剪枝与后剪枝两种。决策树学习中,对每个节点在划分前首先进行估计,如果当前节点的划分不会使决策树泛化性能得到提升,则要停止划分,把当前节点标记为叶子节点。后剪枝是先从给定的训练集中生成一棵完整的决策树,随后自底向上对非叶节点进行检查,如果这个结点对应的子树替换为叶子结点能带来泛化性能的提升,则使用叶子结点替换它。后剪枝决策树通常比预剪枝决策树保留了更多的分支,后剪枝决策树欠拟合风险小,泛化性能上表现更优秀。
2 实验及结论
我们的样本选用了15000条记录的数据集,共有11个特征点,分别是
(1)PatientID(病人编号);
(2)Pregnancies(怀孕次数);
(3)Plasma Glucose(血糖);
(4)Diastolic Blood Pressure(舒张压);
(5)Triceps Thickness(三头肌皮褶厚度);

表1 机器学习算法预测糖尿病模型评估
(6)Serum Insulin(血清胰岛素);
(7)BMI(体质指数);
(8)Diabetes Pedigree(糖尿病谱系);
(9)Age(年龄);
(10)Diabetic(是否患糖尿病);
(11)Physician(患者的医生)。
其中10500个(70%)用作训练集,4500个(30%)用作测试集。所选用的机器学习工具为微软的Azure Machine Learning[15]。
预测正确率(Accuracy)=真阳性+真阴性/真阳性+真阴性+假阳性+假阴性,正确率是接近真值的程度。越接近1越好。预测精度(Precision)=真阳性/真阳性+假阳性,分散程度越接近1越好。召回率(Recall)=真阳性/真阳性+假阴性,越接近1越好。曲线下面积(AUC)能够体现模型性能的优劣。如表1是对预测结果的评估。如图2是ROC曲线显示了真阳性率与假阳性率之间的曲线变化率。曲线越是靠近左上方,表明算法的预测效果越好。在5种机器学习方法种预测效果表现好的依次排名分别是决策树,神经网络,逻辑回归,支持向量机,贝叶斯。在所有5种方法预测的基础上,我们根据要预测的目标,剔除了病人编号和医生两个特征点。对于一些特征近似正态分布我们采用了均值方差作标准化,而对远离正常值的则采用MinMax标准化。
预测结果(表1和图2)表明我们改进的方法,准确率达到0.954,预测精度达到0.934,召回率0.928,AUC为0.991。
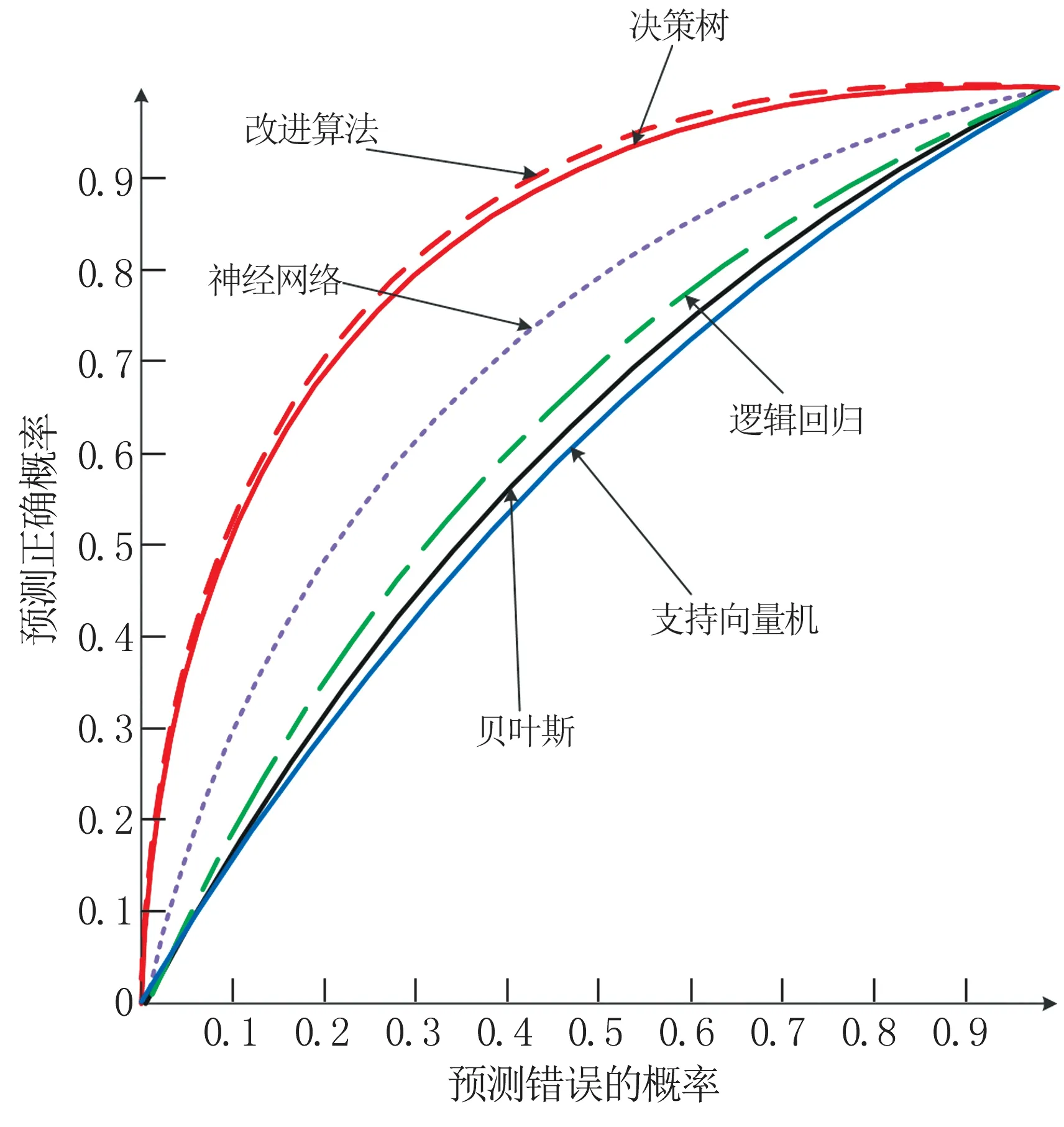
图2 六种方法预测糖尿病的ROC图Fig.2 ROC diagrams of six methods for predicting diabetes mellitus
3 总结
人工智能和大数据分析领域日益引起广泛的关注,而机器学习是其中重要的理论依据和工具之一。在论文中分别采用了神经网络、逻辑回归、决策树、贝叶斯、支持向量机等机器学习算法预测糖尿病,几种方法比较结果表明决策树预测的准确度和精度更加准确,更加有效,下一步我们将采用更加多样的糖尿病方面的数据集,对我们的方法进行印证。我们坚信机器学习方法将会更广泛地应用于医疗领域,对于人们治疗各种疾病起到积极的作用。
猜你喜欢
环球时报(2022-07-13)2022-07-13
保健医苑(2022年5期)2022-06-10
环球时报(2022-03-14)2022-03-14
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电影(2018年8期)2018-09-21
天津诗人(2017年2期)2017-03-16
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
