
股票市场短期趋势的离散分类预测模型研究
2019-04-17 14:41李缃珍
经济研究导刊 2019年26期
李缃珍
摘 要:股票市场短期趋势预测对政府实施有效市场监管和投资者优化资源配置具有重要意义,近年来成为学界业界的研究热点。针对股票市场短期趋势非线性和非平稳的特点,对股票历史数据进行离散化处理并基于核密度方法实现非参数的类概率估计,在此基础上运用增强学习模型实现股票市场的短期趋势预测。以国药一致和伊利股份2019年1/2季度的股票价格进行实证研究,将所提出的离散分类预测模型与三种股票市场短期趋势预测模型(线性回归模型、支持向量回归模型及BP神经网络预测模型)进行比较,结果表明,所提出的离散分类预测模型对股价短期趋势的预测效果更好且更加稳定。
关键词:股票趋势;短期预测;离散分类模型;增强学习
中图分类号:F830.91 文献标志码:A 文章编号:1673-291X(2019)26-0136-05
一、研究背景及意义
股票市场具有的融资功能、转让转化资本和给股票赋予价格等重要职能,有助于提高资金运作效率和反映社会经济及公司的发展情况,对国家经济建设具有重要作用。一方面,股票价格受多种潜在因素影响,如国家政治经济与政策、经济周期变动、货币供应量以及公司的经营状况、行业发展前景和股利分配政策等,故被称为社会经济的“晴雨表”[1];另一方面,股票价格对公司经营决策和投资者交易动机具有重要影响,可以说与社会经济发展状况与人民生活的密切相关。因此,股票短期趋势预测成为近年来称为学界业界的重点研究对象。然而,股票市场是由各种人群参与的、时变的、复杂的非线性系统,受到自然灾害、社会、政治经济以及人群心理等因素影响,使得对股票短期预测面临巨大挑战[2-3]。
现有股票短期趋势变化预测总体上可分为三类:(1)宏观经济与企业发展状况相结合分析方法[4-5]。其主要思想是认为股票是国家整体经济与企业运营状况的晴雨表,故可以通过分析宏观经济事件或分析企业的决策业绩等对未来股票的趋势进行预测。这类方法的挑战在于影响趋势的相关因素过多,例如,宏观经济事件包括国家货币政策、行业相关政策和金融突发事件等,而企业决策业绩因素包括行业前景、产品科技含量、管理及财务状况等,导致收集相关资料费时费力且很难建立股票变化趋势与这些因素之间的定量模型。(2)基于时间序列统计学模型的预测方法[6-7]。股票数据属于时间序列数据,故传统用于时间序列预测的统计学模型都可用于股票短期趋势预测,例如常见的ARMA模型[8]、ARIMA模型[9]、GARCH模型[10]和马尔科夫模型[11]等。这类预测技术假设股票成交信息反映宏观经济与企业经营状况且对未来价格具有影响,通过对股票历史数据分析,运用统计回归模型挖掘股票时序数据的内在规律,建立股票过去价格与未来价格的量化关系。(3)基于机器学习的预测方法。近年来,随着数据挖掘和深度学习等机器学习技术的快速发展,利用机器学习进修股票趋势预测受到越来越多的关注,特别是LSTM[12]和循环神经网络[13]等深度神经网络模型由于具有强大非线性和自学习能力,受到众多学者重视。与基于时间序列统计学模型的预测方法不同,基于机器学习的股票预测模型不预先设定模型或数据分布,对股票短期趋势预测具有较大实用性。但现有大部分基于机器学习的股票预测模型需要海量历史数据训练模型,且模型复杂导致所需预测时间较长。
针对上述挑战,本文提出股票短期趋势的离散分类预测模型。该模型首先对小规模的股票时间序列数据进行离散化处理以增强预测稳定性。其次利用核密度方法实现对股票价格进行非参数的类概率估计。最后以决策树作为弱预测模型并利用增强学习模型进行集成预测。通过参考来自上海/深圳证券交易所、和新浪财经的数据对国药一致(000028)和伊利股份(600887)在2019年1/2季度的股票价格数据进行有效验证,结果表明,所提出的股票短期趋势预测模型预测准确率较高且更稳定。
二、股票短期趋势的离散分类预测模型
现有股票短期趋势预测大多利用回归模型基于前k个股票价格序列数据X={x1,x2,…,xk-1}未来时刻的股票价格xk,即可表述为:xk=f(x1,x2,…,xk-1)。其中,回归模型f可选择统计学回归模型,如ARMA和ARIMA等,也可以选择支持向量回归和马尔科夫链等机器学习模型。然而,由于回归模型将少量连续值(例如前k个股票价格序列数据)作为特征输入,将导致预测模型容易过拟合且模型复杂度较高。为此,本文提出一种将连续特征离散化处理的股票短期趋势分类预测模型,其具体步骤如下。
(一)连续特征离散化
连续特征的离散化过程是将一组连续值转换为一组间隔,将这些间隔作为样本的离散类标签。将模型输入数据样本记为:{(x1,y1),(x2,y2),…,(xk-1,yk-1)},其中,xi=yi,1≤i≤k-1,离散化的目的是将的范围划分为等间距的一系列间隔:[b0,b1),[b1,b2),…,[bk,bk+1],其中b0为{x1,x2,…,xk-1}的最小值且b1为{x1,x2,…,xk-1}的最大值,划分点{b1,b2,…,bk}的选择需要满足输入数据落入每个间隔的数目相等的要求。对连续特征离散化处理后,将划分后落入[bi,bi+1)的数据样本类别记为ci。
假设股票价格数据的前k个股票價格序列数据为{1,3,6,7,8,9.5,10,11,12},将其离散化为三组间隔,可求得一组划分点为{1,6.5,9.75,12},这样每组间隔都包括三个序列数据对:{(1,1),(3,3),(6,6)},{ (7,7),(8,8),(9.5,9.5)},{(10,10),(11,11),(12,12)},这三个间隔的类别分别为c0,c1,c2。
(二)类条件概率密度估计
类概率密度估计首先使用标记数据样本学习类概率密度估计模型,实现对未知类别数据的类别估计。具体包括以下两个步骤。
1.数据样本类别权重估计
假定cy记为输入数据样本y的离散化类别,p(cy|X)记为给定股票短期价格序列数据的离散化样本为y的概率,训练数据的数据样本总数记为n,nc记为离散化样本类别为y的样本数量。通过加权训练数据的离散化类别先验概率来估计数据样本的类别权重,记为w(yi|X),其计算方法是加权所有离散化类别cyi的先验概率,计算公式如下:
数据样本的类别权重w(yi|X)表示待预测的数据样本序列数据的离散化样本为yi的可能性,其计算过程依赖于离散化训练样本的类概率。
2.条件概率密度估计
给定训练数据集中所有离散化类别的权重估计,基于单变量密度估计得到类条件概率密度估计f(y|X)。利用非参数的核密度估计方法,使用宽度为?啄k的高斯核,可得到如下的核密度估计:
高斯核宽度?啄k决定上述密度估计公式与训练样本数据的切合度,可利用数据依赖的全局标准差进行确定。
经过上述两个步骤,根据给定的股票短期序列数据X={x1,x2,…,xk-1}可以估计出未来股票价格数据xk所在的离散化所在间隔,将该间隔的中值作为xk的预测值。此外,采样基于增强学习模型(Boosting)的思想提升模型的预测性能,具体做法重点关注预测误差较大的数据样本,在具体实现上,初始化所有训练样本的权重都相等,对于第m次模型迭代训练,根据这些权重来选取样本数据,进而训练单个预测模型f1。然后,基于该预测模型的预测结果,提高被它预测误差较大的样本的权重,并降低被正确预测的数据样本权重。随后,将权重更新过的数据样本集用于训练下一个预测模型f2,不断迭代,直到预测误差小于设定阈值或者达到设定的迭代次数。
三、应用研究——以国药一致(000028)及伊利股份(600887)为例
为了评估本文所提出的方法的效果,本文实证研究从选择来自上海/深圳证券交易所的股票国药一致(000028)和伊利股份(600887)在2019年1/2季度的股票价格数据进行短期趋势进行预测。
(一)比较方法及评价指标
为说明所提出的方法的客观性与合理性,将本文提出的股票短期趋势预测模型与以下三种常用的股票短期趋势预测模型进行比较。
1.线性回归预测模型[14]。该方法假设前k个股票价格序列数据X={x1,x2,…,xk-1}与未来时刻的股票价格之间存在多元线性关系,即xk可由{x1,x2,…,xk-1}完全线性解释,不能解释项为不可观察的误差项e,回归预测模型如下式所示:
xk=?茁0+?茁1x1+?茁2x2+…+?茁k-1xk-1+e(3)
其中,{?茁1,?茁2,…,?茁k-1}为带估计的模型参数,由最小二乘法进行估计。
2.支持向量回归预测模型[15]。该方法借鉴支持向量思想和拉格朗日算子建立股票短期趋势的回归预测模型,相对于最小二乘回归,支持向量回归可用于非线性回归预测模型,可处理多重共线性问题,且对数据噪声的抗噪性更好。
3.BP神经网络预测模型[16]。该方法基于BP神经网络建立xk与{x1,x2,…,xk-1}之间的隐射关系,网络包括输入层(包括k-1个神经元,即{x1,x2,…,xk-1})、隐藏层(包括m个神经元,即{z1,z2,…,zm})和输出层(包括1个神经元,即xk)。输入层i与隐藏层j之间的链接权重为Wij,隐藏层j与输出层k之间的链接权重为Wjk。基于误差反向传播算法可利用训练数据求得连接权重Wij与Wjk。
采用均方根误差(RMSE)和平均绝对误差(MAE)来评价各个预测模型的性能,记N为测试数据样本数目,xk(i)和x■■(i)分别表示第i个待预测股票价格的真实值和模型预测值,则RMSE和MAE的计算公式如下所示:
(二)股票短期预测结果分析
利用国药一致(000028) 2019年1/2季度共118个交易日的数据进行实证研究,采样过去10日的收盘价预测未来5日的股票价格短期趋势,一共包括104个预测数据,三种对比模型与本文所提出的预测模型的预测值与真实值的拟合如图1所示。
由图1可以看出,有了这四种股票短期趋势预测模型(线性回归预测模型、支持向量回归预测模型、BP神经网络预测模型和本文所提出的预测模型)对于股票短期趋势就能进行较好的预判。但是,当股票短期趋势出现由重组和突变引起的小幅震荡情况时,三种对比预测模型(线性回归预测模型、支持向量回归预测模型、BP神经网络预测模型)的适应度都出现不同程度的下降,而本文所提出的预测模型由于对少量的历史数据进行离散化处理,提高了模型的稳定性。因此,对于由重组或突变引起的股票短期趋势反复震荡也能进行较好的预判,预测性能优于对比的其他三种预测方法。
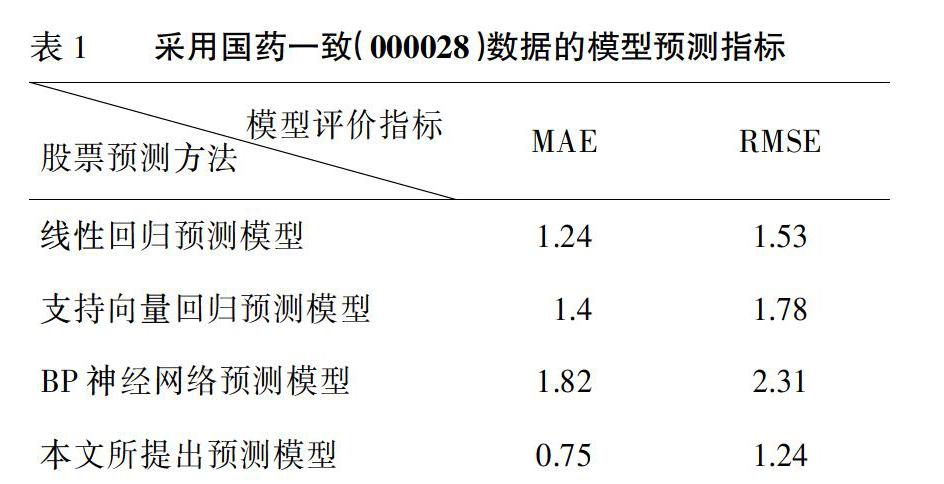
为量化比较本文所提出的股票短期趋势预测模型与其他三种对比模型的性能,还要计算出每种方法预测结果的平均绝对误差(MAE)和均方根误差(RMSE),如表1所示。从表1的结果可以看出,本文所提出的离散分类预测模型预测效果最好,预测结果的平均绝对误差和均方根误差分别为0.75和1.24,这再次说明对股票短期趋势预测的少量连续特征进行离散化处理不但能提高模型预测的稳定性,还能提高模型的预测准确度。相反,BP神经网络预测模型则取得了最差的预测性能,其平均绝对误差和均方根误差分别为1.82和2.31,相比于本文所提出的离散分类预测模型,性能分别下降了58%和46%。出现该现象的原因在于,股票短期趋势预测能用的连续特征较少,BP神经网络容易出现过拟合现象,虽然在训练數据上能取得不错的效果,但对于出现不同模式(如局部反复震荡)的测试数据则不能进行较好预测。
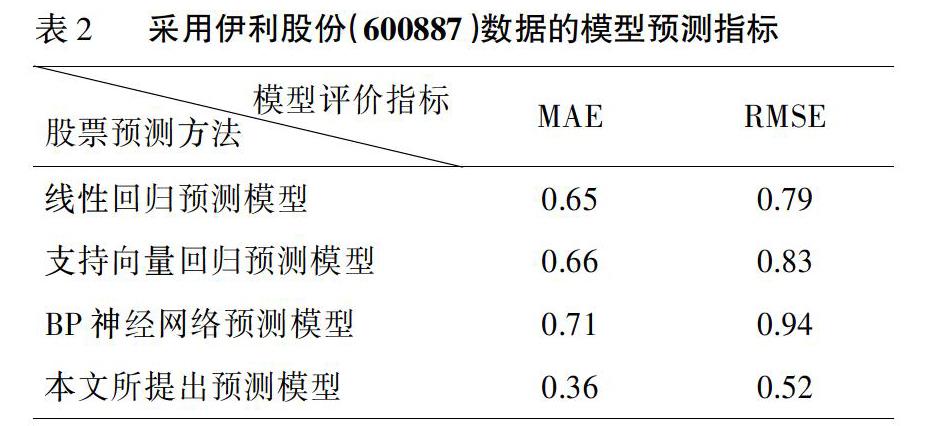
为说明本文所提出离散分类预测模型的优越性,还利用伊利股份(600887)2019年1/2季度共118个交易日的数据进行验证,同样采样过去10日的收盘价预测未来5日的股票价格短期趋势。图2为这四种预测模型的预测结果与真实值的对比情况,可以看出这几种模型的预测结果与国药一致基本类似,即对于股票整体上的趋势都能进行较好的预判。但当股票短期趋势出现局部小幅震荡时,三种对比预测模型的性能会急剧下降,而本文所提出的离散分类预测模型则能较好适应这一情况。
这四种股票短期趋势预测模型在伊利股份预测的平均绝对误差和均方根误差如表2所示。可以看出,本文所提出的离散回归预测模型仍然取得了最好的预测结果,其平均绝对误差和均方根误差分别为0.36和0.52。与国药一致数据的预测性能不同,这四种预测模型的平均绝对误差和均方根误差都存在较大幅度下降,而其他三种对比方法与本文所提出的方法的性能差距也较小。这是因为国药一致在这一时期的趋势较为复杂多变,存在先上升在下降的整體趋势,还有较多局部反复震荡的现象。而伊利股份在这一时期虽然也存在一些局部反复震荡的现象,但整体趋势是向上走多的,所以预测模型相对来说比较容易做出预测。
结语
股票市场关系到国家经济发展、企业运营和投资者未来盈亏,故对股票短期趋势预测对国家行政部门、企业决策参考和投资者利益都有重大影响。但国家宏观政策、国内外经济形势、企业运营状况和新闻舆论等因素都能影响股票的短期趋势,导致股价波动存在复杂性和非线性,因此对股票短期趋势预测存在严峻挑战。与之前大多数基于连续变量回归模型的股票预测方法不同,本文将股票预测的少量连续特征离散化,基于核密度方法实现非参数的类概率估计,随后运用增强学习技术建立股票短期趋势预测模型。通过国药一致和伊利股份2019年1/2季度的股票数据进行实证研究,本文所提出的股票短期趋势的离散分类预测模型不但能取得较好预测效果,而且预测稳定性更高。
参考文献:
[1] 郭琨,周炜星,成思危.中国股市的经济晴雨表作用[J].管理科学学报,2012,(15):1-9.
[2] 李志辉,王近,李梦雨.中国股票市场操纵对市场流动性的影响研究——基于收盘价操纵行为的识别与监测[J].金融研究,2018,(2):135-152.
[3] 黄苑,谢权斌,胡新.股票市场涨跌停影响因素及定价效应[J].财经科学,2018,(10):24-35.
[4] 徐添添.宏观经济政策对股票市场影响的实证分析[J].商业会计,2015,(18):74-76.
[5] 王磊.基于财务视角下的股票投资分析[J].现代经济信息,2017,(17):244-245.
[6] 张楠.基于时间序列的股票趋势预测研究及 R 语言应用[J].现代商业,2016,(23):112-113.
[7] 孙晓宇,李卓然.基于线性时间序列模型对金融数据分析——以云南白药股票数据为例[J].时代金融,2016,(14):264-265.
[8] 林蓝玉,陈秀芳,张德飞.ARMA 模型在股票中的应用[J].经济研究导刊,2018,(26):53,146-148.
[9] 吴玉霞,温欣.基于 ARIMA 模型的短期股票价格预测[J].统计与决策,2016,(23):83-86.
[10] 柯希均.基于 GARCH 模型的股票市场风险度量[J].当代经济,2016,(32):12-14.
[11] 陈爽,李丹,高洪韵.马尔科夫链及其在股票价格预测中的应用[J].现代经济信息,2017,(16):288.
[12] 邓凤欣,王洪良.LSTM 神经网络在股票价格趋势预测中的应用——基于美港股票市场个股数据的研究[J].金融经济,2018,(14):96-98.
[13] 黄丽明,陈维政,闫宏飞,等.基于循环神经网络和深度学习的股票预测方法[J].广西师范大学学报:自然科学版,2019,37(1):13-22.
[14] 李潇宁.多元线性回归与时间序列模型在股票预测中的应用[J].科技创业月刊,2019,32(2):153-155.
[15] 张鹏.基于 SVR 的股市预测与择时研究[J].重庆文理学院学报,2016,35(2):148-151.
[16] 刘佳祺,刘德红,林甜甜.基于 BP 神经网络模型的股票价格研究[J].中国商论,2018,(8):29-30.
Short-term Prediction in Stock Market by Discrete Classification Forecasting Model
Li Xiangzhen
(Zhejiang University City College,Hangzhou 310015,China)
Abstract:Short-term prediction of the stock market is of great significance to government effective market regulation and investor resource allocation optimization,which has become a research hotspot for both academic and industry in recent years.However,the non-linear and non-stationary characteristics of short-term trend in the stock market makes it extremely difficult to predict.To solve the non-linear and non-stationary characteristics of the short-term prediction of the stock market,the stock historical data is discretized and the non-parametric class probability estimation is implemented based on kernel density method.Then,this study utilizes a boosting-based classification model to predict short-term trend of stock market.Experiment data is from the stock price of two companies in the first half of 2019,i.e.,China National Accord Medicines Corporation Ltd and Inner Mongolia Yili Industrial Group Corporation Ltd.Using this data,we compare the proposed method with three short-term forecasting models for stock market,i.e.,linear regression model,support vector regression model and BP neural network.The results show that the proposed discrete classification prediction model achieves better prediction accuracy and is more stable.
Key words:Stock trend;Short-term forecast;Discrete classification model;Boosting model
