
基于两步分解法和SARIMA的非饱和机场能耗预测
2019-04-15 06:54陈静杰
计算机应用与软件 2019年4期
陈静杰 孟 琦
(中国民航大学电子信息与自动化学院 天津 300300)
0 引 言
民航节能减排“十三五”规划对民航业温室气体排放的要求以及国际上即将实行的碳排放交易体系,使我国机场节能减排压力日益增加[1]。因此,准确预测机场能耗意义重大。而机场非饱和状态与饱和状态相互转换的生命周期特点导致非饱和机场能耗数据有效样本量较少且具有非线性和非平稳特性,预测难度较大。
能耗预测方法的研究大致分为单一模型法和组合模型法。常见单一模型有时间序列法[2]、支持向量回归法[3-4]和神经网络法[5]等,但以上单一模型在处理非线性且非平稳的时间序列时均存在一定的局限性。因此,能够结合单一模型优点的组合模型研究开始受到越来越多关注。组合模型主要有:1) 并联式组合法,该方法利用组合权系数将单一模型预测结果进行加权相加,组合模型是单一模型的线性叠加[6-7]。该方式忽略了模型间的非线性关系且组合权重的确定决定了模型精度的高低。2) 串联式组合法,该方法利用前一模型的输出作为后一模型的输入,后一模型的输出为最终结果,该方式的组合模型精度受前一模型输出影响且易导致误差叠加[8]。3) 基于序列分解的组合预测法,该方法将原始序列分解为一系列子序列,对子序列分别建模预测并叠加得组合预测值。如小波变换法[9]、经验模态分解EMD(Empirical Mode Decomposition)方法[10-11]、聚类经验模式分解EEMD(Ensemble Empirical Mode Decomposition)方法[12]和自适应噪声完整集成经验模态分解CEEMDAN(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise)方法[13]等。以上研究通过分解技术降低了原始序列的非线性与非平稳特征。但由于各种分解算法的固有缺陷,使得受外界随机因素影响的时间序列经分解所得的高频分量的非线性和非平稳性依然较高[14]。
综上可知,对高频分量进一步弱线性化和平稳化是基于序列分解的组合预测方法精度提高的关键,因此,提出一种基于两步分解法和季节差分自回归滑动平均模型SARIMA相结合的组合预测方法。首先,利用CEEMDAN算法将原始序列分解为一系列从高频到低频的分量,依据各分量的样本熵SE(Sample Entropy)识别其复杂度进行模式重组。然后,利用变分模态分解VMD(Variational Mode Decomposition)算法把重组分量中的高频复杂分量再次分解,得到一系列呈现弱非线性且相对平稳的子序列。最后,采用SARIMA对子序列分别进行建模,将各子序列预测值叠加得机场能耗预测值。以某非饱和机场能耗数据作为样本进行实验,验证所提方法具有较高的预测精度。
1 两步分解方法
两步分解法的分解过程见图1。第一步分解,利用CEEMDAN算法将原始序列分解为一系列本征模函数IMF和一个剩余趋势分量RES。利用SE值识别各分量的复杂度进行模式重组,降低预测模型的运算量。第二步分解,利用VMD算法对高频复杂分量再次分解,得到一系列子序列VM。经过以上两步分解,原始时间序列被分解为一系列呈现弱非线性且相对平稳的子序列。
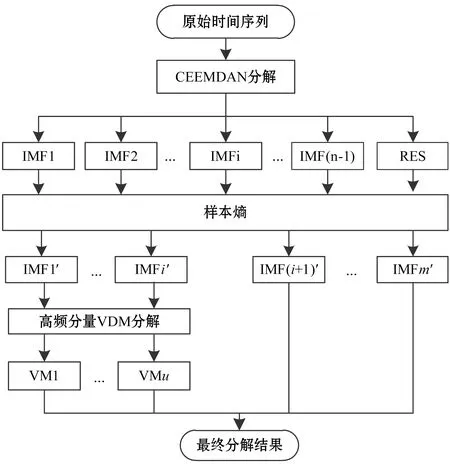
图1 两步分解流程图
其中,IMF1,IMF2,…,IMF(n-1)和RES为CEEMDAN分解所得子序列,IMF1′,IMF2′,…,IMFm′为经样本熵识别重组后的子序列,VM1,…,VMu为VMD分解所得子序列。
1.1 CEEMDAN-SE一步分解
定义EMD算法分解所得分量为Ek(·),CEEMDAN算法分解所得分量为FIM,k(t),k为分解阶段。CEEMDAN-SE分解具体步骤如下:
(1) 向原始时间序列加入N次白噪声构造新序列:
xi(t)=x(t)+ε0wi(t)
(1)
式中:x(t)为实际时间序列,wi(t)为服从N(0,1)分布的白噪声,i=1,2,…,N,ε0为自适应系数。
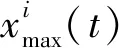
(2)
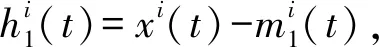
(3) CEEMDAN的第1个分量FIM,1(t)和第1阶段(k=1)的余量信号r1(t)为:
(3)
r1(t)=x(t)-FIM,1(t)
(4)
(4) 对信号r1(t)+ε1E1(wi(t))进行EMD分解,则FIM,2(t)为:
(5)
(5) 对其余阶段,即k=2,3,…,K,与步骤(3)相同,计算第k个余量信号为:
rk(t)=rk-1(t)-FIM,k(t)
(6)
计算第k+1个模态分量为:
(7)
(6) 重复步骤(5),直至所获余量信号不能再分解为止,即余量信号极值点数不超过两个。最终序列分解为K个IMF分量和一个余量R(t):
(8)
(7) 计算各FIM,k(t)和R(t)的SE值,将SE值相差较小的FIM,k(t)合并为新分量。SE的具体算法见文献[15],设时间序列为{u(t),t=1,2,…,N},u(t)为FIM,k(t)或R(t),m为嵌入维数,r为相似容限,定义X(i)=[u(1),u(2),…,u(i+m-1)],i=1,2,…,N-m+1,矢量X(i)与X(j)之间的距离为:
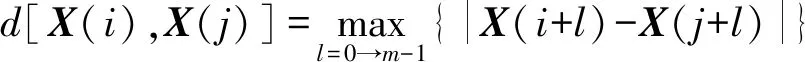
(9)
式中:j=1,2,…,N-m+1且i≠j,则SE表示为:
(10)
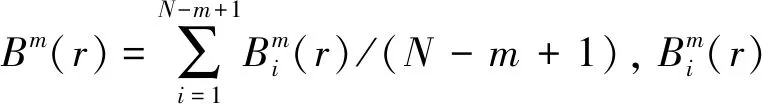
经以上步骤,原始时间序列分解为一系列具有复杂度差异的子序列,设各子序列的SE均值γ为门限值,对SE大于γ的子序列进行第二步分解。
1.2 VMD二步分解
VMD算法实现过程如下:
(2) 根据下式更新参数yk和wk。
(11)
(12)
(3) 更新参数λ:
(13)
式中:τ为噪声容限,为达良好去噪效果可设为0。
(4) 迭代停止判断条件如下式,若不满足,则m加1,返回步骤(2),否则停止迭代,得k个模态分量。
(14)
经过以上两步分解,原始时间序列被分解为一系列呈现弱非线性且相对平稳的子序列。
2 预测模型
2.1 SARIMA预测模型
季节ARIMA模型记作SARIMA(p,d,q)(P,D,Q)S,公式如下:
(15)
2.2 基于两步分解法和SARIMA的组合预测法
CEEMDAN-SE-VMD-SARIMA组合预测方法具体过程如下:
(1) 将原始时间序列进行两步分解,得到一系列子序列。
(16)
(17)
式中:yi(t)为残差修正后各子序列预测结果;y(t)为子序列预测结果相加所得的最终预测结果。
3 实例分析
3.1 数据选取及误差指标
实验程序在Windows 7 64位系统Intel-I7 CPU、32 GB内存的计算机上进行,在MATLAB 2009a软件平台上进行仿真。实验数据为某非饱和机场2013年-2016年的机场综合能耗数据,数据采样周期为1个月。利用2013年-2015年月度能耗数据对2016年机场月度能耗进行预测,用2016年的能耗实际数据对预测方法的预测精度进行评价。采用平均相对误差(RME)、均方根误差(RMSE)和判定系数(R2)对模型预测效果进行比较。
(18)
(19)
(20)
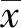
3.2 预测过程
3.2.1 两步分解
首先利用CEEMDAN算法分解原始能耗时间序列,分解结果如图2所示。
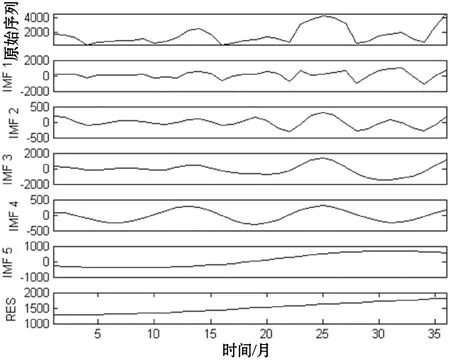
图2 能耗原始序列和CEEMDAN分解所得子序列
由图2可以看出,原始时间序列被分解为5个IMF分量和1个剩余趋势分量RES。由于分解后的分量较多,若对每一个分量都进行SARIMA建模并进行残差修正,计算规模较大,且会造成误差叠加。为降低上述影响,利用SE识别各子序列的复杂度进行模式重组。由式(10)可知,SampEn值与m和r有关,由于SE具有较好的一致性,其值的变化趋势不受m和r影响,一般情况下取m=1或2,r=0.1~0.25SD,SD为时间序列标准差,本文选取m=2,r=0.2SD。各子序列的SE值结果如图3所示。
图3 各IMF及RES的样本熵
由图3可知,IMF3和IMF4的样本熵值差异较小,可将其合并为一个子序列。经过重组后子序列变为5个。结合图2和图3可知,IMF1和IMF2的复杂度较高依然具有较高的非线性和非平稳性特征。
计算得IMF1和IMF2的SE值均大于γ,采用VDM算法再次分解IMF1和IMF2,结果如图4所示。

(a) IMF1经VMD分解所得子序列

(b) IMF2的VMD分解所得子序列图4 VDM分解
由图4可以看出,IMF1和IMF2经再次分解后分别得到4个充分降低了非线性和非平稳性的子序列。至此,经两步分解得到11个子序列。
3.2.2 模型比较分析
在经过两步分解的基础上,对分解所得子序列建立不同的SARIMA模型,并对拟合残差建模,修正预测结果,将各子序列的预测值相加得机场能耗预测值。为验证CEEMDAN-SE-VMD-SARIMA组合预测方法对提高机场能耗预测精度的有效性,分别利用SARIMA模型、CEEMDAN-SE-ARIMA法和VMD-SARIMA法对相同的能耗时间序列进行预测,对比分析各个方法得到的预测值。机场能耗预测结果对比如图5所示,各模型的预测误差指标对比见表1。

图5 能耗实际值和各模型预测值
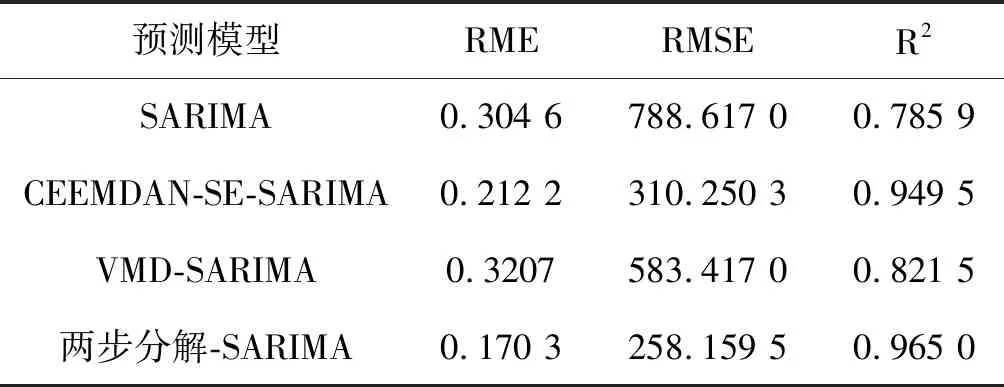
表1 四种方法误差指标比较
根据图5和表1可知,CEEMDAN-SE-VMD-SARIMA组合预测方法的拟合效果最好,其RME和RMSE均低于其他方法,其拟合优度R2高于其他方法,说明本文提出的CEEMDAN-SE-VMD-SARIMA组合预测方法的预测精度最高。CEEMDAN-SE-SARIMA方法和VMD-SARIMA方法的误差小于SARIMA模型,拟合优度R2高于SARIMA模型,说明通过分解技术可以提高模型的预测能力。而相比于单步分解的组合预测法,CEEMDAN-SE-VMD-SARIMA组合预测方法的误差更小,拟合优度R2更高。这说明在处理非线性非平稳的机场能耗时间序列时,对序列进行弱非线性化和平稳化预处理对提高预测精度有很大的帮助,而一步分解得到的子序列中的高频分量依然存在着较高的非线性和非平稳性,直接将其舍弃或将其预测结果加入最终结果均会导致预测精度的下降。相比于单步分解法,两步分解法能够更好地降低各个子序列的非线性和非平稳性,从而有效地提高模型的预测精度。
4 结 语
针对非饱和机场能耗时间序列具有的非线性和非平稳性特点,提出一种基于两步分解法和SARIMA的组合预测方法。
(1) CEEMDAN-SE方法优于一般的序列分解方法,能够有效地对原始时间序列信号进行分解并减少建模运算量。
(2) 采用CEEMDAN-SE-VMD两步分解法来处理原始能耗时间序列的非线性和非平稳性,分解效果明显优于一步分解法。
(3) 对子序列建立SARIMA预测模型,有效提取了序列的周期特征,并且利用拟合残差预测值修正最初的预测值,提高了预测准确性。
(4) 通过对几种方法预测结果的对比分析,可以得出,本文方法大大提升了机场能耗预测的精度,也适用于其他非饱和型机场,可为相关机场制定能耗有关决策、能耗综合管理和节能绩效评价提供一定的参考。
猜你喜欢
特种结构(2022年2期)2022-05-06
力学与实践(2022年1期)2022-03-12
今日农业(2021年19期)2022-01-12
高教学刊(2021年34期)2021-12-03
黑龙江科技大学学报(2021年3期)2021-06-04
电子产品世界(2021年6期)2021-02-10
读者·校园版(2020年19期)2020-09-16
中国现代医生(2020年2期)2020-04-09
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
