
基于多图流形排序的图像显著性检测
2019-04-11 12:14于明李博昭于洋刘依
自动化学报 2019年3期
于明 李博昭 于洋 刘依
图像显著性检测是计算机视觉领域的关键技术之一,有着广泛的应用领域,包括目标识别、图像分类[1]、图像检索[2]、基于内容感知的图像压缩等[3].人类视觉注意机制可以从自然图像中提取出感兴趣的区域供给大脑进行后续分析,如何使计算机能够更好地模拟人类的视觉注意机制,准确、快速地提取图像中的感兴趣区域,是图像显著性检测研究的主要内容.
图像显著性检测方法从驱动方式上可以分为两大类:自底向上的基于数据驱动的方法和自顶向下的基于任务驱动的方法[4].自底向上的方法主要利用图像的底层特征,如对比度、颜色、亮度、纹理和边缘等,提取图像中的显著目标.自顶向下方法是根据具体任务对自底向上的检测结果进行调整或者根据任务样本自动建立显著性模型,这类方法需要大量的带有类别标记的示例数据集进行训练,且需人为控制,并依赖于所需的任务.由于自底向上的显著性检测方法多从图像特征入手,不依赖于特定的任务,因此目前大多数研究都是基于自底向上的方式进行视觉显著性检测.
对比度是引起人类视觉注意的最大因素,Goferman将自底向上的基于对比度的图像显著性检测算法分成以下三类[5]:考虑局部特征,考虑整体特征,以及融合整体特征和局部特征的方法.基于局部对比度的算法通常通过计算图像的子区域或者像素与其周围一个小的局部邻域的对比度来衡量该图像子区域或者像素的显著性,代表算法有Achanta等[6]于2008年提出的AC(Salient region detection and segmentation)算法和Yan等[7]于2013年提出的HS(Hierarchical saliency)算法.AC算法通过计算像素块在不同邻域上的局部对比度实现多尺度显著性计算.HS算法对图像进行多级分割,在每个层级上利用局部对比度计算显著图,并引入等级机制对每个层级上的显著图进行融合得到最终的显著图.基于全局对比度的算法特点是对于每个子区域或像素,将整个图像作为对比区域计算其显著值,代表算法有Cheng等[8]于2015年提出的HC(Histogram based constrast)算法和RC(Region based contrast)算法.HC算法将一个像素的显著性定义为该像素与其他像素的颜色对比度之和,并使用直方图进行高效处理.针对HC算法仅考虑了像素的颜色特征,RC算法在此基础上加入了位置信息.融合局部和全局对比度的方法在计算图像显著性时分别考虑局部对比度和全局对比度,并将二者通过一定的方式结合起来.Borji等[9]提出的LGPR(Local and global patch rarities)算法利用LAB空间的三个通道分别计算图像块之间的欧氏距离和图像块直方图的概率分布,作为局部和全局对比度,并进行融合得到最后的显著图.
通常,在空域中计算像素(或像素块)的显著性时间复杂度高,而在频域中计算显著性可以提高算法的速度.如Achanta等于2009年提出的FT(Frequency-tuned)算法[10]和2010年提出的MSS(Maximum symmetric surround)算法[11],还有Hou等[12]提出的SR(Spectral residual)算法都是基于频域的显著性检测方法.
Wang等[13]于2015年提出了BFSS(Background and foreground seed selection)算法,通过对原始图像进行超像素分割并选择背景超像素生成背景模板,计算每个超像素与背景模板中超像素块的对比度之和,生成初始显著图;在二值化的初始显著图中选择前景超像素生成前景模板,计算每个超像素与前景模板中超像素块的对比度之和,生成最终的显著图.该算法中生成背景模板的机制耗时多,算法的时间复杂度较高.除了上述基于对比度的算法,基于阈值分割的方法也被用于进行图像显著性检测.Kim等[14]于2014年提出了HDCT(High-dimensional color transform)算法,首先利用基于Otsu的多级自适应阈值算法,计算两个阈值,对现有算法生成的初始显著图进行阈值分割,得到三值图像,提取三值图像中非中间值区域像素的颜色特征,这些像素将被用作显著区域和背景区域的初始颜色样本,然后将低维颜色空间映射到高维颜色空间并以颜色样本为约束,根据颜色样本的约束估计颜色通道的最优线性组合,最后结合高维颜色空间中的颜色值获得显著性图.Zhang等[15]于2016年提出的BMA(Boolean map approach)算法将输入图像利用多个阈值进行分割得到多幅二值图像,通过二值图像间的拓扑分析计算显著图.基于阈值分割的显著性检测方法对阈值的依赖性强,阈值选择不好往往会使算法失效.
基于图模型的显著性检测算法利用图的不同连接方式直观地刻画数据节点之间多样的结构特征,通过构造不同的关联矩阵(Affinity matrix)反映图像区域之间的相似程度,由于其检测准确率高且算法复杂度低而引起更多的关注.在IT模型[16]的基础上,Harel等[17]于2006年提出GBVS(Graph based visual saliency)算法,利用马尔科夫随机场构建二维图像的马尔科夫链,通过求其稳定状态得到显著图.Wei等[18]于2012年提出了GS(Geodesic saliency)算法,以超像素为节点构造图模型,并将节点的显著性值定义为该节点与所有背景节点之间的测地距离之和,该方法原理简单,能够较完整地检测出显著目标.Li等[19]于2013年提出了CHM(Contextual hypergraph modeling)算法将超图模型引入到图像显著性检测中,通过对原始图像进行多级分割,在每一级上建立超图模型并结合边缘特征计算显著图.Li等[20]于2015年提出RW(Random walk)算法,该算法融合显式视觉线索和潜在视觉相关性,同时考虑图像区域本身的信息性及不同图像区域之间潜在的相关性,构建有向图模型,在该图模型上利用随机游走计算各区域的显著性值.Yuan等[21]于2018年提出的RR(Regularized random)算法中引入了正则化的随机游走排序模型RRWR(Regularized random walk ranking)和反转修正模型RC(Reversion correction),该算法同时利用区域和像素特征,将先验显著性估计引入图像中的每个像素,从而生成基于像素细节特征和超像素区域特征的显著图.
基于图模型的显著性检测算法普遍需要解决以下问题:如何构建图模型的节点集、边集以及边的权值选择;如何利用图模型计算节点的显著性值.Yang等[22]提出的MR(Manifold ranking)算法利用图模型刻画图像区域之间内在的关系,并把流形排序的概念引入到显著性检测中,将图像的显著性检测视为对超像素节点的二分类问题.通过基于图模型的流形排序算法将局部分组融入到节点的分类问题中,与直接利用图模型上节点之间的测地距离计算显著图的GS算法相比,MR算法得到的显著目标内部更加均匀光滑[23].然而MR算法在构造图模型时仅将位置相邻的节点进行连接,没有考虑颜色相似的节点之间的连接性,这样检测到的显著目标存在不完整的问题,有时也会错误地突出非显著区域.
针对以上显著性检测算法中存在的问题,例如显著目标不完整,目标内部不能一致均匀突出,本文提出了一个基于多图流形排序的显著性检测算法.与仅利用单一图模型的显著性检测算法不同,本文引入多个图模型,分别以超像素为节点构造基于超像素颜色特征的KNN图模型和基于空间位置特征的K正则图模型.在KNN图模型中将颜色相近的节点进行连接,在K正则图模型中将位置近邻的节点进行连接.本文算法的主要贡献是:1)在两种图模型中分别利用流形排序算法计算节点的显著性值,并且在利用流形排序算法计算节点的显著性值时使用全局前景假设,一定程度上解决了显著目标位于边界时MR算法失效的问题;2)将两种图模型下得到的节点显著性值在节点级上进行加权融合,得到节点最终的显著性值,在一定程度上弥补了单一图模型下生成的显著图中噪声较多和显著目标不完整的问题.
其余章节组织如下:在第1节中介绍提出的基于多图流形排序的图像显著检测算法,在第2节中将本文算法与经典的显著性检测算法进行对比实验,第3节中给出总结和展望.
1 基于多图流形排序的图像显著性检测算法
本文提出的算法是在超像素基础上进行的,超像素是利用像素之间特征的相似性将颜色相近的像素分组,这样就可以用少量的超像素代替大量的像素表示图像,从而为后续的图像处理降低复杂度.本文利用SLIC算法[24]对图像进行超像素分割,对得到的超像素块提取颜色特征和空间位置特征,以超像素为节点分别构造基于颜色特征和空间位置特征的两类图模型G1和G2.在这两类图模型上分别利用流形排序算法计算所有节点的显著性值和,其中f1,i表示超像素节点i在G1模型下计算得到的显著性值,f2,i表示节点i在G2模型下计算得到的显著性值.将两个图模型上得到的节点的显著性值进行加权融合,利用融合后节点的显著性值生成初始显著图,并根据中心先验和边界抑制对初始显著图进行优化得到最终的显著图.在此基础上将两种图模型下生成的显著图进行融合,能够使得检测到的显著目标更加完整均匀,并且能够在一定程度上抑制单一图模型下由于节点连接错误,在显著图中产生的噪声.本文算法的流程伪码如算法1所示:
算法1.基于多图流形排序的图像显著性检测算法
输入:图像In;
1)利用SLIC算法对图像In进行超像素分割;
2)以超像素为节点构造图模型G1,计算图模型G1的关联矩阵W1和度矩阵D1;
3)计算图模型G1下节点的显著性值;
4)以超像素为节点构造图模型G2,计算图模型G2的关联矩阵W2和度矩阵D2;
5)计算图模型G2下节点的显著性值;
7)对初始显著图进行优化,得到最终的显著图S.
输出:显著图S.
1.1 基于图模型流形排序的显著性计算
本文涉及的流形排序问题又称为半监督回归问题[25],是基于半监督学习分类领域的一个分支.流形排序可以简单描述为:给定正样本(或负样本),通过排序值的大小,判定某个样本与正样本(或负样本)的相似性,依此对该样本进行分类.基于图模型的流形排序算法引进图模型刻画数据之间的关系,使得数据的表达更加直观.
基于图模型流形排序的图像显著性计算以超像素为节点构造图模型,在图模型的基础上通过求目标函数的最小值计算每个节点相对于查询节点的排序值,并将这个排序值定义为节点的显著性值.这里定义查询节点为已标记好的超像素节点,例如将某个超像素节点标记为前景(或背景)节点.
设图像中超像素个数为n,构造数据集,其中m表示超像素节点特征的维数,n表示超像素节点个数,其中一些节点被标记为查询节点.定义指示向量, 若xi为查询节点,则yi=1,否则yi=0.定义排序函数F:,排序函数F将m×n的数据集矩阵X映射到n维向量f,其中fi表示节点i相对于查询节点的排序值,即节点的显著值.在数据集X上构建一个图模型G=(X,E),其中数据集X是节点集,边集E是连接节点的边构成的集合,边的权值由关联矩阵表示.定义为图模型G对应的度矩阵(Degree matrix),其中,j=1,···,n.根据流形排序的思想,排序值f的最优解通过以下的最优化问题得到[22]:

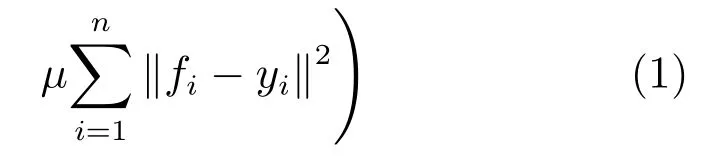
其中参数µ用来平衡平滑项(第一项)和拟合项(第二项).根据式(1)求得f的最优解为:
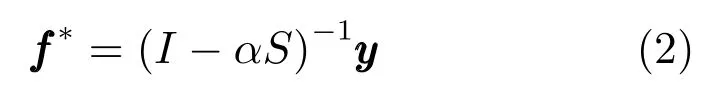
其中I为单位矩阵,参数α=1/(1+µ),S是归一化的拉普拉斯矩阵S=D−1/2WD−1/2.利用非归一化的拉普拉斯矩阵,得到f∗的另一种形式:
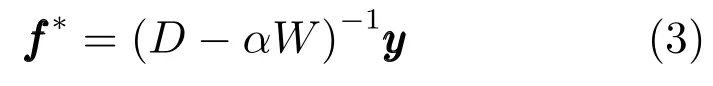
文献[22]中通过实验验证,式(3)比式(2)得到的显著图更准确.本文利用式(3)计算每个节点的排序值即显著性值fi.令A=(D−αW)−1,则,当计算f∗时,需要将A的对角线元素置为0,否则得到的f∗中将包含节点到自身的排序值,这是一个无意义的值并且会影响最终的排序结果.
基于图模型流形排序的显著性检测算法中,查询节点的选择是一个关键的问题.MR算法利用背景先验,假设图像边界为背景区域,将图像边界节点设置为查询节点,利用式(3)计算每个节点i相对于背景节点的排序值,则节点的显著性值为.目前基于背景先验的显著性检测算法大多利用边界假设,即假设图像边界为背景区域,生成背景模板,并根据背景模板计算图像的显著图,这些算法大都会遇到背景鉴别这个具有挑战性的问题.其中一些算法通过不同的方法优化背景模板,RBD(Robust background detection)算法[26]通过定义节点的边界连接性判定边界节点属于背景的可能性大小,边界连接性越大的节点,其属于背景的可能性越大.BFSS算法[13]则是通过定义节点的边界概率选择背景节点,节点的边界概率越大,越有可能属于背景.UILSG(Updating initial labels from spectral graph)算法[27]通过一个边界节点分类机制筛选真正的背景节点.这些算法在一定程度上解决了背景鉴别的问题,但是仍然是基于边界假设的思想,当显著目标位于图像边界时,算法会失效.为了解决这个问题,本文采用全局前景假设的思想,将所有的节点作为查询节点,即在利用式(3)计算节点的显著性值时,假设所有的节点为前景节点,设置节点指示向量,将y代入式(3)计算节点的显著性值.将所有的节点设置为查询节点,避免了背景鉴别的问题,检测到的显著目标更加完整.图1显示了MR算法和本文算法分别利用边界假设和全局前景假设生成的显著图,其中图1(a)为原图,图1(b)是人工标注图Ground-truth,简称GT,图1(c)为MR算法中利用边界假设生成的显著图,图1(d)为MR算法中利用全局前景假设生成的显著图,图1(e)为本文算法中利用边界假设生成的显著图,图1(f)为本文算法中利用全局前景假设生成的显著图.从图中可以看出利用全局前景假设得到的显著目标更加完整.
1.2 多图模型构造
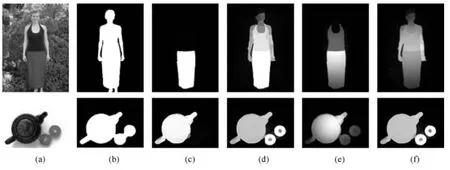
图1 全局前景假设和边界先验的比较Fig.1 Comparison of global foreground prior and background prior
在基于图模型的显著性检测算法中,图模型的构造对显著图的计算至关重要.现有的基于图模型的显著性检测算法大多利用单一的图模型描述图像中不同区域之间的关系,例如GS和MR算法都是以超像素为节点,将空间相邻的节点进行连接构造图模型.然而在自然图像中,不同区域之间往往具有复杂的关系,仅使用单一的图模型并不能够准确地描述图像区域之间的关系.Li等[28]提出的MGL(Multi-graph learning)算法利用优化的多图模型学习进行显著目标检测,该算法融合多个图模型刻画数据节点之间的关系,但是这些图模型中节点之间的连接关系并没有变化,只是边的权值不同,仅改变图模型中边的权值并不能反映数据本身的特性,在不同的特征下,节点之间的连接性也是不同的.Zhang等[29]提出的GBOF(Graph-based optimization framework)算法通过构造两个图模型并计算不同图模型下的权值矩阵,从不同的角度刻画节点之间的连接性.GBOF的图模型分别是利用阈值法查找邻接点的颜色特征图模型和基于K正则图模型的位置特征图模型,颜色特征图模型利用设定的阈值寻找每个节点的邻接节点,当阈值设置不合适时,会产生孤立节点,影响显著目标的检测结果.位置图模型与MR算法一致,两类图模型融合时利用图模型的权值矩阵,通过最小化能量函数得到节点相对于查询节点的排序值,进而生成显著图.
在基于图模型的显著性检测算法中,图模型需要能够体现数据节点之间的连接性.常用的构图方法有K 正则图、KNN图、全连接图和ε-图.K 正则图构造方式简单,且具有对称性,可以用于描述超像素节点的空间位置特性.KNN图与ε-图都可以用于刻画节点之间基于颜色特征的连接性,KNN图模型是根据节点之间的颜色差异寻找每个节点的K个邻接节点,ε-图是根据阈值寻找每个节点的近邻节点,但是如果阈值设置不准确,ε-图构造的图模型中会产生孤立点,影响算法的性能,所以本文使用KNN图模型刻画节点之间基于颜色特性的连接性.全连接图指的是将图模型中所有的节点两两相连,不能准确地体现不同节点之间的连接关系.
1.2.1 KNN图模型
颜色是自然图像中的重要信息,颜色相似的区域很可能属于同一个物体,本文基于颜色特征构造KNN图模型作为图模型G1=(V1,E1).在KNN图中每个节点只与它在某个距离测度下的K个近邻节点相连.KNN图模型能够自适应地反映节点在特征空间中的分布特性,在高密度区域,KNN图的半径变小;在低密度区域,KNN图的半径变大[30],这种能够自动适应节点分布特性的优点,使得KNN图能够很好地拟合节点在颜色特征下的分布特性,因而可以刻画节点在颜色特征下的连接性.
本文提取CIELAB颜色空间中超像素块所包含的像素点的颜色特征均值作为节点的颜色特征c=(l,a,b)T,提取超像素块所包含的像素点的空间位置特征均值作为节点的空间位置特征z=(x,y)T.定义dist(ci,cj)为超像素i和j之间的颜色距离,其中ci和cj表示超像素i和j的颜色特征;定义dist(zi,zj)为超像素i和j之间的空间位置距离,其中zi和zj表示超像素i和j的空间位置特征.KNN图模型中,如果仅使用颜色距离寻找每个节点的近邻节点,而不考虑相邻节点之间的连接性,这样构造出的G1图模型生成的显著图中显著目标内部不均匀;如果仅使用空间位置距离寻找每个节点的近邻节点,构造出的G1图模型生成的显著图中背景与显著目标边界不明确,并且会错误地突出背景区域,所以本文在寻找近邻节点时利用式(4)的距离度量方式:
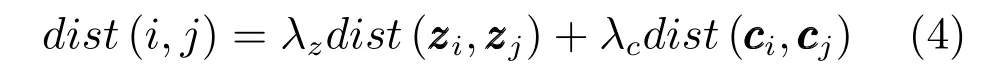

计算超像素i与其他超像素之间的距离dist(i,j),j=1,2,···,n,,根据dist值寻找超像素i的K个近邻超像素.利用式(4)搜索得到近邻节点,既考虑了节点之间颜色特征的相似性又考虑了节点之间空间位置的连接性,不仅能够限制颜色相近但位置相距较远的节点之间的连接性,又能够提高颜色差异较大但是位置相距较近的节点之间的连接性.
这里考虑节点位于图像的内部和位于图像边界区域两种情况,当节点位于图像内部时,在节点i与它的K个近邻节点j之间构造一条有向边eij∈E1,Inner,E1,Inner为有向边集合,有向边的权值定义为:

其中σ是一个常数,用来控制权值的强度.
由于图像的边界区域大多属于背景区域,在KNN图模型的基础上,本文将边界节点两两连接.边界节点指的是当超像素中包含图像边界像素时,则该超像素节点被定义为边界节点.将图像的任意两个边界节点i和j之间构造两条有向边,分别为从节点i指向节点j的有向边eij和从节点j指向节点i的有向边eji,其中eij,eji∈E1,Boundary,E1,Boundary为有向边集合,集合E1,Boundary中的有向边上的权值定义为:
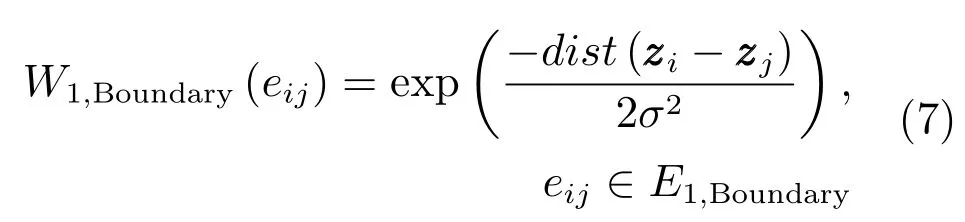

图2 不同图模型生成的显著图比较Fig.2 Comparison of saliency maps obtained by different graphs

综上所述,G1图模型中边的权值为:
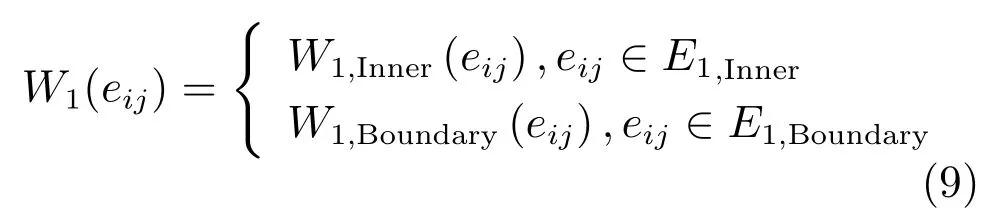
1.2.2 K正则图模型
在自然图像中位置相近的图像区域属于同一类区域(前景或背景区域)的概率很大.与文献[22]中构造图模型的方法相同,这里将空间位置相近的节点进行连接,利用K正则图(K regular graph)构造G2=(V2,E2)图模型.在G2图模型中每个节点不仅与它的相邻节点连接,并且和与它相邻节点有共同边界的节点进行连接.根据中心偏置原理,显著目标大多位于图像中心,图像的边界区域很可能属于同一区域(背景区域),故与G1图模型的构造方式类似,在G2中本文也将图像的边界节点两两连接,加强边界节点之间的连接性.G2图模型中边的权值为:
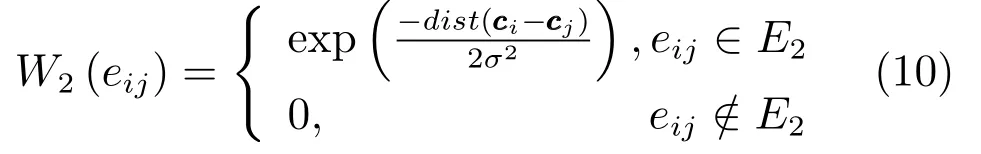
1.3 显著性融合
图模型G1将颜色相近的节点连接起来,得到的显著图能够比较完整地突出显著目标,但是存在显著目标内部不均匀或者显著目标不能一致高亮的问题;G2模型中将位置相近的节点连接起来,得到的显著图能够使显著目标的内部一致高亮,但是显著图中存在突出背景区域,显著目标与背景区域边界不清晰的问题.如图2所示,图2(a)为原图,图2(b)为GT,图2(c)为超像素分割图像,图2(d)为仅利用G1图模型生成的显著图,图2(e)为仅使用G2图模型生成的显著图,图2(f)为G1和G2融合生成的显著图.从图2(d)中可以看出检测到的显著目标虽然比较完整且边界清晰,但其内部没有均匀一致高亮;图2(e)中尽管显著目标内部均匀一致高亮但是背景噪声明显.故本文提出了一种融合方式,将这两种图模型得到的节点的显著性值在节点级上进行融合,即在两种图模型中,分别利用第1.1节中的式(3)计算节点的显著性值,记为,将和进行加权融合,得到超像素最终的显著性值:
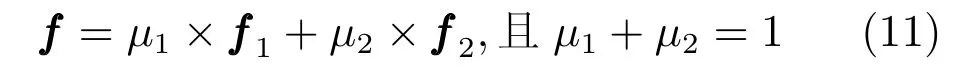
其中f=(f1,f2,···,fn)T,fi表示超像素i的显著性值,i=1,2,···,n.从图2(f)中可以看出检测到的显著目标内部不仅一致均匀突出,并且滤除了部分背景噪声.
1.4 显著图优化
利用第1.3节中式(11)计算超像素的显著性值f=(f1,f2,···,fn)T,其中fi表示第i个超像素的显著性值,i=1,2,···,n,将显著性值赋给超像素i所包含的所有像素作为每个像素的显著性值,这样得到一个全分辨率的与原图像大小相等的初始显著图Sco.
由于显著目标大多处于图像的中央,并且位于图像中央的区域更能引起人们的关注,故本文引进中心先验图加强初始显著图Sco中显著目标的亮度.由于初始显著图Sco的边界中存在一些噪声,为了进一步滤除背景噪声,本文引入边界抑制操作对初始显著图Sco进行优化.首先,根据中心先验思想对图像中心进行加强,利用关于图像中心的各向同性的对称高斯模型模拟图像的中心先验图[31]:
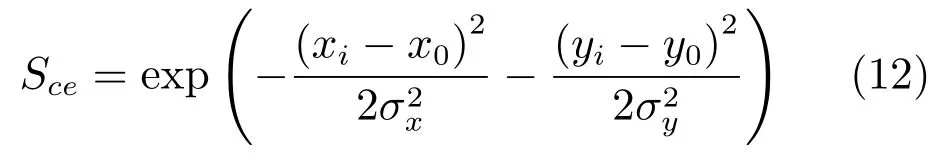
其中xi和yi是像素的水平和垂直坐标,x0和y0是图像中心像素的水平和垂直坐标,σx和σy分别代表水平方向和垂直方向上的方差,σx和σy取值相同.将中心先验图Sce与初始显著图Sco进行融合得到优化后的显著图:

式(13)中“·”表示点乘,即将Sco与Sce两幅显著图中对应像素点的显著值逐个相乘,得到显著图S中对应像素的显著值.
其次,在显著图S的基础上,通过MATLAB中的imclearborder函数的边界抑制操作抑制S中与边界相连的高亮区域的亮度,即将与边界相连的且面积较小的高亮区域的亮度降低,以进一步去除背景噪声,得到优化的显著图.
2 实验结果与分析
2.1 数据库及评价指标
为了验证本文方法的有效性,将本文提出的方法在MSRA-10K[32]、SED2[33]和 ECSSD[34]这三个公开的数据集上进行测试.MSRA-10K数据库是目前该领域最常用的一个数据库,该库中共包含10000张图像.数据库中的图像显著目标的种类繁多,但是大多数只包含一个显著目标,并且图像的背景相对简单.SED2数据库包含100张图像,每张图像中包含两个显著目标.ECSSD数据库包含1000幅内容丰富且背景复杂的图像.这三个数据库都提供了人工标记的二值图像作为GT,以便于评价显著图的性能.
对于本文方法所涉及的参数,由于数据库中的图像多为400×300左右,为了保证算法时间效率的同时又不影响检测结果,本文将初始超像素个数设置为200.在构造KNN图模型时,如果每个节点的邻接节点的个数K的取值太小会影响目标内部的完整性,K取值太大会检测到较多的噪声,实验中选取了多种K值进行对比实验,结果显示当K=5时,实验结果最好.在式(4)中,λz和λc分别用来控制位置特征与颜色特征在距离公式中所占的权重,当λz过大时,检测到的显著目标边界不明确,当λz过小时,显著目标内部不完整,实验中设置多组λz与λc的值,当λz=0.5,λc=1实验结果最好,故本文中设置λz=0.5,λc=1.式(6)、(7)和(10)中的σ2均设置为经验值0.05.式(11)中的µ1和µ2分别用来控制不同图模型下超像素块的显著性值融合时的权重,实验中选取了多组µ1和µ2的值,当µ1=µ2=0.5时实验结果最好.式(12)中,实验中选择多组参数值进行对比实验,当实验结果最好.
图像显著性检测方法很多,本文选取14种常用的显著性检测算法进行对比,这14种算法分别是基于全局对比度的HC和RC算法,基于局部对比度的AC算法,基于分层显著性融合的HS算法,基于频域的SR算法、FT算法和MSS算法,基于背景先验的GS算法,MR算法和BFSS算法,基于随机游走的RW算法,基于高维颜色转化的HDCT算法,基于二值图拓扑分析的BMA算法和基于正则随机游走排序的RR算法.所用对比算法源码链接1https://github.com/libozhao/saliency-detection-methods/blob/master/README.md和本文算法源码2https://github.com/libozhao/saliency可见相关网页.MR和GS算法都是基于图模型的显著性检测算法,MR是利用基于图模型的流形排序算法进行显著性检测,GS是基于图模型上的测地距离计算显著性.本文引入四种常用的评价指标评测提出的算法,这四种指标分别是P-R(Precision-recall)曲线、ROC曲线、F-measure和AUC值[34].
1)P-R曲线
P-R曲线是最常用的评价显著性检测算法优劣的指标.对于一幅显著图S,将S中像素值归一化到[0,1],然后从0到1依次选取阈值对S进行二值化,得到二值图像M,GT表示Ground-truth.根据式(14)计算查准率(Precision)和查全率(Recall):
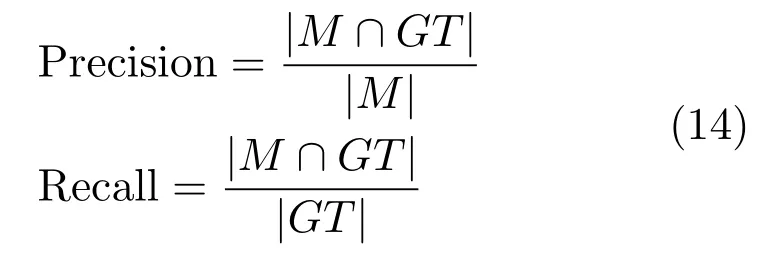
2)ROC曲线
ROC曲线的绘制方式与P-R曲线类似,对于显著图S,将S调整到[0,1],然后从0到1依次选取阈值对S进行二值化,得到二值图像M,GT表示Ground-truth,表示GT取反.根据式(15)计算真阳性率(TPR)和假阳性率(FPR):
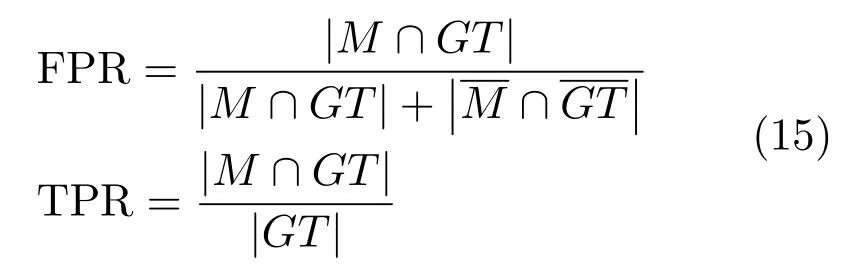
相同真阳性率下,假阳性率越小,显著性检测算法越好.
3)F-measure
F-measure用来综合衡量查全率和查准率:
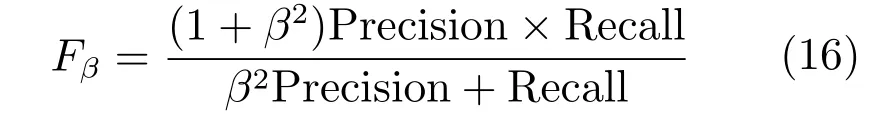
式(16)中,β用来决定查全率和查准率的影响程度,为了强调准确率的重要性,通常β2设置为0.3.F值越大表明显著性检测算法的性能越好.
4)AUC值
AUC值被定义为ROC曲线下面积,即ROC曲线与X轴包围的面积.ROC曲线有较小的假阳性率和较大的真阳性率是最优的,所以AUC值越大则表示显著性算法性能越好.
本文首先使用一系列的固定阈值对数据库中所有图像在某个算法下的显著图进行二值化,利用得到的二值图像与GT进行比较,计算每幅显著图在不同阈值下的Precision和Recall,然后在每个阈值下分别计算所有图像的Precision和Recall的平均值,作为该阈值下的Precision和Recall绘制P-R曲线.ROC曲线的绘制方式与P-R曲线类似,也是利用一系列的固定阈值.与Precision和Recall的计算方式不同,F值的计算方式是利用自适应阈值对每幅显著图进行二值化,然后与GT进行比较,计算每幅图像的F,然后计算所有图像F的平均值,作为该方法在该数据库上的F.
2.2 多图模型有效性实验比较
为了验证多图模型的有效性,本文分别在数据库MSRA-10K、SED2和ECSSD上进行了三组实验.这三组实验分别是仅利用K正则图模型生成显著图,仅利用KNN图模型生成显著图,以及融合两种模型计算得到的显著图,并计算这三组实验的P、R和F值.表1是在数据库MSRA-10K、SED2和ECSSD上的对比实验结果.表1中K正则表示仅利用K正则图模型生成显著图,KNN表示仅利用KNN图模型生成显著图,K正则+KNN表示将K正则图模型下生成的显著图与KNN模型下生成的显著图进行融合.
从表1的第2~4列和第8~10列可以看出在MSRA-10K和ECSSD数据库上,与仅利用K正则图和KNN图模型的实验结果相比,将K正则图和KNN图模型进行融合的实验结果优于仅利用单一图模型的实验结果.在SED2数据库中,由于存在前景与背景颜色非常相似的图片,在构造KNN图模型时,会错误地将背景节点与前景节点连接起来,故KNN图模型下生成的显著图准确率低于K正则图模型下生成的显著图.但是将K正则图模型与KNN图模型下生成的显著图进行融合,结果优于仅利用KNN图模型生成的显著图,如表1第5~7列所示.故将两个图模型下生成的显著图进行融合能够改善实验结果.
2.3 全局前景假设有效性实验比较
为了验证本文中全局前景假设的有效性,本文在数据库MSRA-10K、SED2和ECSSD上分别进行对比实验,在这三个数据库上分别利用边界假设生成显著图,利用全局前景假设生成显著图,并计算这两类显著图的P、R和F值记录在表2中.表2中“边界”表示利用边界假设生成的显著图.“全局”表示利用全局前景假设生成的显著图.
从表2可以看出,利用全局前景假设生成的显著图在三个数据库上的R值平均提升31.0%,F值平均提升8.6%,优于利用边界假设生成的显著图.
2.4 优化策略有效性实验比较
为了验证本文所用优化策略的有效性,分别在数据库MSRA-10K、SED2和ECSSD上计算初始显著图与优化显著图,并计算相应的P、R和F值将结果记录在表3中.表3中的“初始图”表示初始显著图,“优化图”表示优化后的显著图.
从表3第2~4列和第8~10列可以看出,在MSRA-10K和ECSSD数据库上,与初始显著图相比,优化后的显著图在P值和F值上均有提升.数据库SED2中,图片数量小并且存在大量显著目标靠近边界的图片,在该数据库上优化后的显著图比初始显著图在F值上有所下降.但是在MSRA-10K和ECSSD上,加入中心先验和边界抑制进行优化后,实验结果中F值和P值均有所提升.由于大多数图像的显著目标处于图像的中央,并且位于图像中央的区域更能引起人们的关注,故本文引入优化策略对初始显著图进行优化.

表1 K正则图模型、KNN图模型和K正则图模型+KNN图模型比较Table 1 The comparison of K regular graph,KNN graph,and K regular graph+KNN graph

表2 边界假设和全局前景假设比较Table 2 The comparison of boundary assumption and global foreground assumption

表3 初始显著图和优化后显著图的比较Table 3 The comparison of original saliency maps and re fined saliency maps
2.5 MSRA-10K数据库上的实验结果

图3 MSRA-10K数据库上实验结果Fig.3 Experimental results on the MSRA-10K database
本文算法与其他的14种算法在MSRA-10K数据库上的部分实验结果的对比图见图3.从图3中可以看出,基于对比度的HC和AC算法,在背景与前景颜色相似时,会错误地突出背景区域.FT和MSS算法,虽然保留了比较完整的图像信息,但是没有一致高亮显著目标.SR算法没有保留足够的高频信息,导致显著目标的边界不清晰.当显著目标之间存在较大的差异时,MR算法会出现漏检的现象,如图3中MR算法的(a)、(b)所示;当显著目标与边界相连或者与边界颜色相似时,该算法会错误地突出背景区域,如图3中MR算法的(c)、(d)图像所示.RC和HS的检测结果相似,基本能够准确地定位显著目标,但是从图3中的(d)、(e)可以看出RC和HS算法都存在错误突出背景区域的问题.当显著目标与背景颜色相似时,HDCT算法生成的显著图中不能正确地检测出显著目标,如图3中HDCT算法的(c)、(e)所示.BFSS算法也是基于边界假设的一种算法,当显著目标与边界颜色相似时会错误地突出背景区域,例如BFSS算法中的(d)、(e)所示.RW 和BMA算法生成的显著图中显著目标的边界不清晰.RR算法生成的显著图中存在较多的背景噪声,如图3中的RR算法(d)和(e)所示,当显著目标之间存在较大颜色差异时,RR算法存在漏检的现象,如图3中RR算法(a)和(b)所示.本文算法不仅能够准确地定位显著目标,并且显著目标内部更加光滑,边界更加清晰,并且有效减少背景噪声.
为了更加客观地进行比较,本文中利用P-R曲线、ROC曲线和F值进行定量对比.图4是MSRA-10K数据库上各种算法的P-R曲线、ROC曲线和F值,其中图4(a)和图4(b)为P-R曲线,图4(c)和图4(d)为ROC曲线,图4(e)和图4(f)为F值.图4中第一列表示本文算法与FT、GS、AC、MSS、HS、MR、RC、HC 和 SR算法的对比,图4中第二列表示本文所提算法与BFSS、RW、HDCT、BMA和RR算法的对比.在后文中图6和图8中的排列方式同图4.从图4(a)和(b)中可以看出本文算法的P-R曲线与MR、RC、HS和RR算法基本持平且优于其他算法.图4(c)和(d)中显示本文算法的ROC曲线优于其他算法.图4(e)中显示本文算法的查全率(Recall)高于MR算法低于GS算法,查准率(Precision)略低于MR算法但高于GS算法.说明本文算法在保持较高查准率的同时,能够比较完整地检测到图像的显著目标.
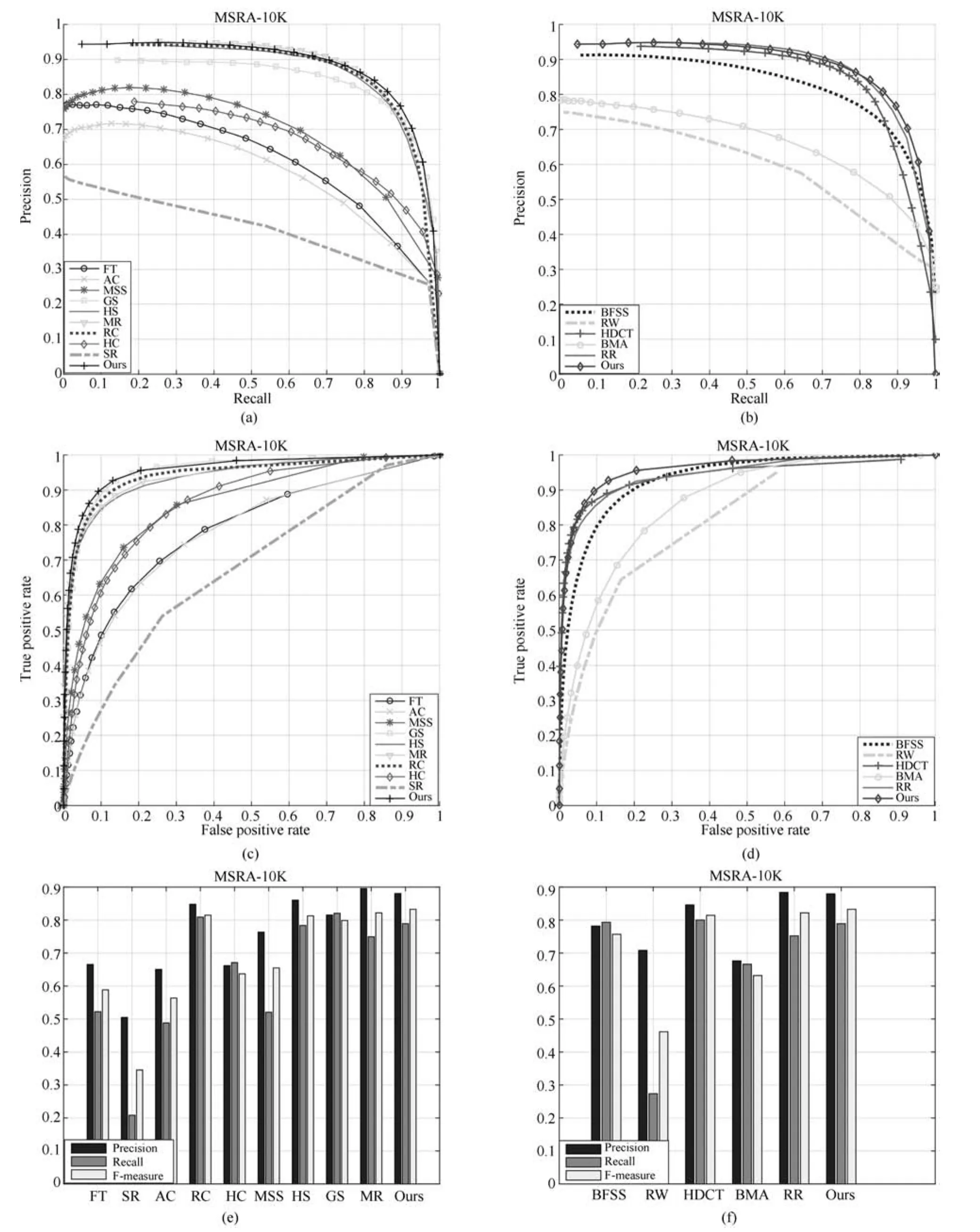
图4 MSRA-10K数据库上的P-R曲线、ROC曲线和F值Fig.4 P-R curves,ROC curves,and F values on the MSRA-10K database

图5 SED2数据库上实验结果Fig.5 Experimental results on the SED2 database
2.6 SED2数据库上的实验结果
SED2数据库中的图像大多含有两个显著目标,并且有的显著目标靠近图像边界,相比MSRA-10K数据库中只包含单个显著目标,SED2更具挑战性,但是该数据库中的图片背景比较简单.图5是SED2数据库上的部分实验结果对比图.从图5中可以看出,HC和RC算法生成的显著图背景噪声较多,显著目标的边界不明确.AC、SR、FT和MSS算法没有突出显著目标.基于背景先验的MR算法,当显著目标靠近边界时,会将显著目标错误的检测为背景,并且存在漏检的现象.GS算法也存在与MR相似的问题,并且生成的显著图中背景噪声较多.HDCT算法基本能够准确地定位显著目标,但是当显著目标比较大时,算法会失效,如图5中HDCT算法的(d)所示.当显著目标与边界相连或者靠近边界时,BFSS算法会错误地突出背景区域.BMA算法生成的显著图没有突出显著目标,如图5中BMA算法所示.RR算法检测到的显著目标不完整,如图5中的RR算法(c)和(d)所示.本文算法得到的显著目标不仅一致均匀,并且显著图中背景噪声相对较少.
图6是SED2数据库上的P-R、ROC曲线和F值.图6(a)中显示,在该数据库上,除了SR的P-R曲线比较低以外,其他9种算法的P-R曲线比较接近,HS的P-R曲线最高,本文算法略低于HS.图6(b)中显示,本文算法的P-R曲线与BFSS、RW、HDCT算法基本持平.图6(c)显示,除了SR的ROC曲线比较低以外,其他的曲线比较接近.图6(d)显示本文算法的ROC曲线于其他5个算法基本持平.图6(e)显示本文算法的查准略低于最高的MSS算法;图6(f)显示本文算法的查准率略低于HDCT算法.由于该数据库中存在显著目标非常小的图片,本文算法计算该种图片的显著图时,在利用SLIC算法对原始图像进行超像素分割时可能会将显著目标与背景区域分割到同一超像素块中,故本文算法在该数据库中的查全率低于基于像素点对比度的HC算法,但是由于引进了基于颜色特征的KNN图模型,本文算法的查全率高于MR算法.通过比较发现本文算法在该数据库上保持高查准率的同时能够较完整地突出显著目标.
2.7 ECSSD数据库上的实验结果
ECSSD数据库中的图片不仅背景复杂,并且显著目标的纹理也很复杂.比MSRA-10K和SED2更具挑战性.图7是ECSSD数据库上实验结果的对比图.图7中第(a)行的原始图像中显著目标与背景中的深色草地部分颜色相似,除了GS和本文算法外,其他的算法都突出了部分背景区域或者没有完整突出显著目标.与GS相比,本文算法的显著目标内部更加均匀;图7第(b)行中,MR算法只突出了部分显著目标;图7第(c)行中显著目标纹理比较复杂,只有MR、GS和本文算法能够比较均匀地突出显著目标,但是本文算法的显著目标内部更加光滑完整;图7第(d)行中显著目标颜色与背景相近,只有RC、MR和本文算法能够比较好地突出显著目标;图7第(e)行的原始图像中显著目标各部分颜色差异较大,本文算法相对完整地突出了显著目标.
图8是该数据库上不同算法的P-R曲线、ROC曲线和F值.从图8(a)、(b)和(c)、(d)可以看出本文算法的P-R曲线和ROC曲线都是该数据库上最高的.无论从P-R曲线还是ROC曲线都可以看出,本文算法优于当前流行的14种算法.图8(e)和(f)可以看出本文算法的F值是该数据库上最高的,表明本文算法能够比较准确地检测显著目标,并且显著目标更加完整.
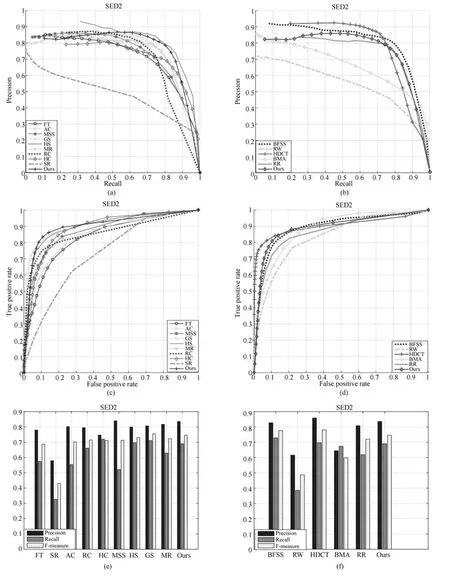
图6 SED2数据库上的P-R曲线、ROC曲线和F值Fig.6 P-R curves,ROC curves,and F values on the SED2 database
表4是各种算法在不同数据库上的AUC值和F值,从表4第2列和第5列可以看出本文算法在MSRA-10K数据库上的AUC值为0.9532,F值为0.8327,这两个指标都是该数据库上最优的.从表4第3列和第6列可以看出本文算法在SED2数据库上的AUC值达到0.8937,F值达到0.7456.从表4第4列和第7列可以看出本文算法在ECSSD数据库上的AUC值达到0.9114,F值达到0.7034,这两个指标都是该数据库上最优的.通过以上的比较发现,本文算法能够准确地检测出显著目标,并且能够一致均匀地突出显著目标.
本文算法采用MATLAB R2014b编程实现,系统环境为Windows10,CPU频率为3.6GHZ,8GB内存.表5为不同算法在该实验环境下运行数据库ECSSD、SED2上所有图片和MSRA-10K上前1000张图片所用时间的平均值.从表5中可以看出本文算法的平均运行时间为1.30秒,结合本文算法的检测效果,本文提出的算法具有优越性.

图7 ECSSD数据库上实验结果Fig.7 Experimental results on the ECSSD database

表4 各种方法在不同数据库上的AUC值和F值Table 4 The AUC and F values of the various methods on different databases

表5 各种方法平均运行时间Table 5 The average runtimes of different methods
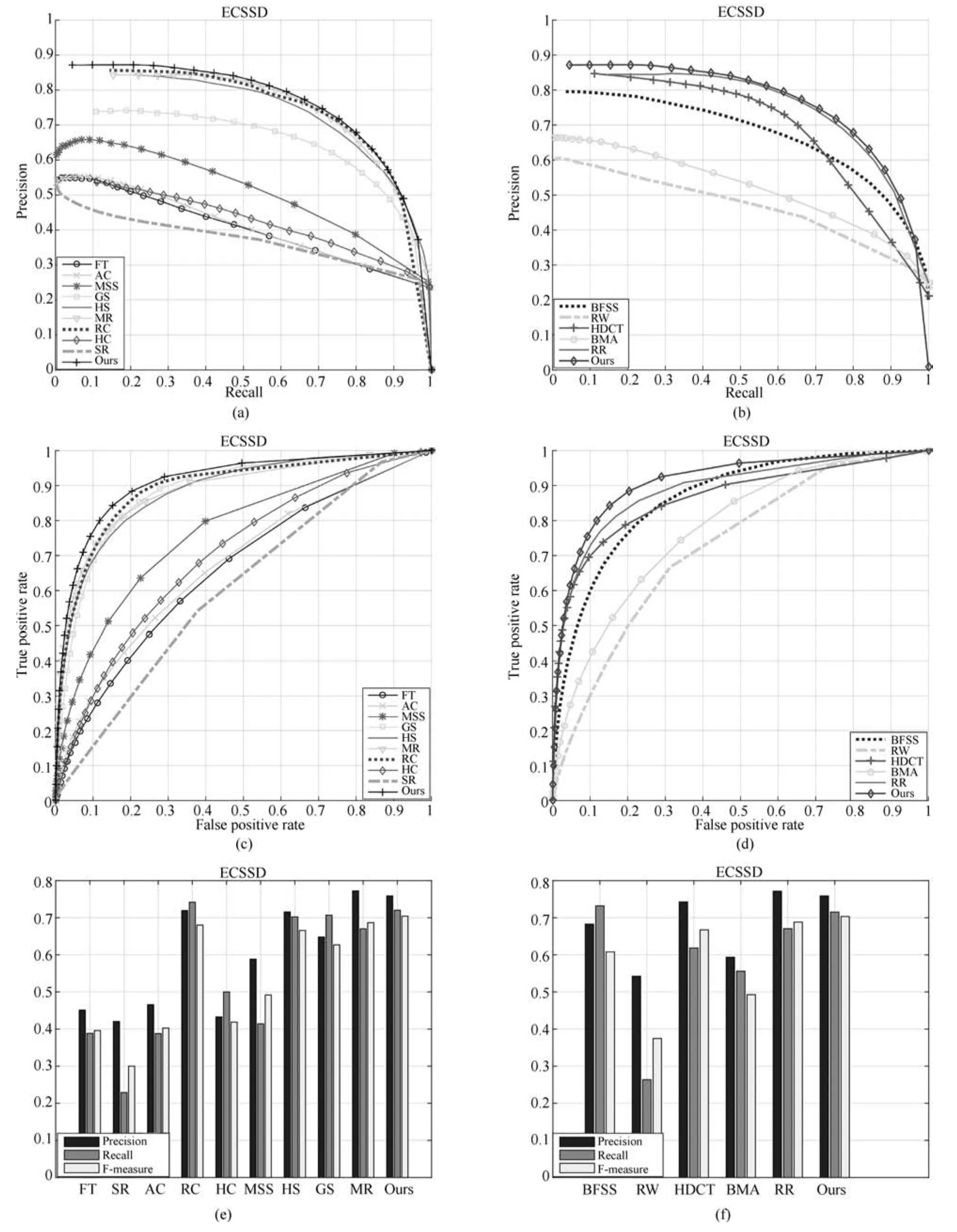
图8 ECSSD数据库上的P-R曲线、ROC曲线和F值Fig.8 P-R curves,ROC curves,and F values on the ECSSD database
3 结论
本文提出了一个基于多图流形排序的图像显著性检测算法.该算法分别利用超像素的位置特征和颜色特征,基于K正则图和KNN图构造两类图模型,分别在两种图模型上利用流形排序算法计算超像素的显著性值,并将每个图模型下得到的超像素的显著性值进行加权融合得到超像素最终的显著性值.本文将提出的算法与当前流行的14种算法在MSRA-10K、SED2和ECSSD数据库上进行了对比,无论是在视觉效果上还是在定量指标上,本文算法都具有明显优势.针对背景与前景颜色相似的图片,本文算法的检测效果需要进一步提高,未来考虑提取更多的特征比如超像素的形状特征,并结合流形排序算法提取更加准确的显著目标.
猜你喜欢
山东第一医科大学(山东省医学科学院)学报(2022年7期)2023-01-05
小哥白尼(军事科学)(2022年2期)2022-05-25
故事作文·高年级(2022年2期)2022-02-24
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
中国人兽共患病学报(2020年11期)2020-12-08
现代装饰(2020年4期)2020-05-20
红领巾·萌芽(2019年8期)2019-08-27
小型微型计算机系统(2019年4期)2019-05-05
电子制作(2019年24期)2019-02-23
