
姿态特征与深度特征在图像动作识别中的混合应用
2019-04-11 12:15:16钱银中沈一帆
自动化学报 2019年3期
钱银中 沈一帆
动作识别是计算机视觉中的研究热点.一个特定动作通常由一连串人体的肢体运动组成,因此长期以来研究者从视频研究动作识别[1−5].生活经验告诉我们,人类具有从图像中识别动作的能力.例如,图6中的每幅图像都有一个人在执行一个动作,我们一眼就能看出这个人在干什么.随着图像分类和物体检测技术的进步,近十年来出现了很多从静止图像识别动作的研究工作[6].
从静止图像中识别动作具有广阔的应用前景.首先,可以促进视频识别动作的研究.视频由一组按照时间顺序排列的帧图像组成,如果能够设计新的算法,从少量图像中识别动作,就可以减少冗余帧,提高计算效率.这种算法还可以与视频中的时间维度结合,提出新的算法,进一步提高动作识别性能.其次,有助于图像自动标注.由于Internet的兴起,人们能够从网络上获得海量图像数据.如果计算机能够识别图像中的动作,就可以把像素信息作为输入,自动标注这些图像的动作类别.另外,还有助于动作图像的检索和管理.目前搜索引擎检索图像主要还是依赖图像周围的文字,如果能够从图像中提取动作信息,无疑将更准确、更方便地检索和收集动作图像.
1 相关研究
仔细分析一下可以发现,人类通过图像中的线索识别动作,这些线索包括:人体的姿态、与人交互的物体、以及背景等.研究静止图像中的动作识别有两种思路.一种思路与人类识别动作类似,先从图像中检测人体姿态或与人交互的物体等高层语义信息,然后根据机器学习算法判定动作类别[7−9].另一种思路是提取图像的整体特征,把动作识别当作图像分类问题[10]处理.
人体姿态是动作识别中最重要的语义线索.人体很容易被检测到,检测结果通常用一个矩形窗口表示人体的位置.Ikizler-Cinbis等[11]使用NMF(Non-negative matrix factorization)方法对训练集中的人体窗口进行姿态聚类,有相似姿态的图像被划分到同一个聚类中,然后对每个动作类别训练分类器.除了矩形窗口外,还有的方法使用人体轮廓表示人体.Wang等[12]用Canny边缘检测模板得到的一组边界点作为人体的轮廓,然后对轮廓特征聚类,把图像标注到不同的动作类别.
肢体整体难以反映姿态特征的细节,而人体的各部件,例如胳膊、腿、躯干等无法变形的原子部件的组合结构有丰富的动作线索.如果能够识别这些部件以及它们的相对位置,就能够更准确地识别动作类别.通过原子部件的组合配置描述人体姿态的经典算法是基于部件的Pictorial模型[13−14].遗憾的是,这方面的研究还很不成熟,通过这些原子部件检测人体姿态只能在一些特定的数据集上做实验,检测结果无法用于识别动作.为了避免原子部件在检测中显著性不足的缺点,研究者提出了Poselet[15−16].Poselet是由训练集中同一肢体部件具有相同关键点配置的图像窗口实例训练而来的检测模板.一个动作通常由一连串变化的姿态组成,而一幅图像只能抓住其中一个快照.即使是同一个姿态,从不同角度拍摄,得到的图像也会千差万别.除此以外,还要处理人的高矮胖瘦以及不同服饰引起的的外貌特征差异.因此,研究者需要定义一组Poselet描述同一部件的不同姿态.由于Poselet的粒度可以从最小的原子部件到整个人体,研究者可以根据检测中的显著性大小、是否包含姿态和动作语义信息等要求定义不同粒度和种类的Poselet.Yang等[17]对左胳膊、右胳膊、肢体上部和腿四个部件分别训练一组反映其姿态变化的Poselet,通过一个星形的基于部件的模型把这些部件连接起来.在此基础上,Wang等[18]提出了分层的基于部件的模型,该模型是由20个部件节点组成的有环网状结构.
本文用Poselet向量空间中的坐标表示肢体部件的姿态,然后根据这一中间层特征识别动作.与这一特征类似的有视频动作识别研究中的局部运动部件[19],这一中间层特征是由稠密轨迹[20]在局部时空域上聚集而成,描述诸如胳膊或腿等语义区域内的运动特征.该方法先从训练集中提取稠密轨迹,然后在每一视频中根据时间重叠、空间距离以及速度定义的距离对稠密轨迹聚集分组.如果把单个稠密轨迹看作一个可视化单词,局部运动部件就是由一组稠密轨迹组成的可视化语句.与这一方法不同的是,本文可视化单词是Poselet,Poselet是由二维图像窗口训练来的检测模板,由同一部件的Poselet描述该肢体部件的姿态变化,而稠密轨迹是从三维时空域中提取的运动特征,局部运动部件由一组相似的稠密轨迹组成,描述部件的运动特征.
随着大规模训练数据集的出现,CNN模型逐渐引起研究者的关注.在ILSVRC2012图像分类挑战赛中,Krizhevsky等[21]提出的深度网络的性能超过了所有的已有分类算法.深度特征是从整体图像中依次经过多层架构抽象而来.尽管深度特征有很强的判别能力,却无法区分哪些特征各自反映了姿态、交互的物体、属性以及背景等与动作有关的语义线索.
在动作识别领域,利用两个通道的互补线索提高识别能力有很多研究.文献[17−18]从图像局部区域中提取姿态特征,从图像全局中提取整体特征,目标函数由局部特征构成的基于部件的模型加上整体特征组成,通过模型与图像的匹配判别动作类别.在视频处理领域,Simonyan和Zisserman[22]根据人类视觉识别的两通道假说[23]训练两个通道的CNN网络,一个CNN从帧图像中提取静态特征,另一个CNN从光流中提取运动特征,然后合并这两者的深度特征实现动作识别.这种从两个通道提取互补深度特征的方法在后续研究中有很多变体[24−28].例如,Glkioxari和Malik[24]利用这两个通道的深度特征在帧图像中检测动作,并把每个帧中的检测结果连接为三位时空域中的动作管道.Cheron等[25]对帧图像中不同肢体部件提取静态和运动深度特征,经过合并形成视频的姿态特征,然后识别动作类别.受这些研究的启发,本文通过探索深度特征与手工设计的姿态特征的互补关系.本文从图像局部区域中提取姿态特征,从整体图像提取深度特征,利用这两个通道的互补线索识别静止图像中的动作.
2 提取姿态特征
本文的姿态特征是一组Poselet检测结果组成的向量.本节介绍如何用Poselet表示肢体部件的姿态,以及如何利用上下文检测Poselet.
2.1 姿态特征的表示方法
控制理论用状态空间表示系统可能出现的状态集合.状态空间是以状态变量为坐标轴形成的向量空间,系统的任何一个状态可以用状态空间中的一个坐标表示.向量空间这种表示可变状态的方法也在计算机视觉中得到了应用.例如,在底层信息处理中,彩色图像中的每个像素由RGB三维向量空间中的坐标表示.这种表示法还被用来估计人脸和躯体的姿态.Mikolajczyk等[29]训练了两个人脸检测模板,一个是侧面的,一个是正面的,测试图像中的人脸朝向由这两个模板的检测结果表示.Maji等[7]对训练集中的人脸和肢体朝向做了标注,对每个朝向训练Poselet,在测试图像中检测每个Poselet的触发得分组成向量,脸部或肢体的朝向特征由这个向量表示.
本文把文献[7]表示人脸和肢体朝向的方法推广到每个选定的肢体部件.为了利用训练实例窗口中的交互物体和背景线索提高动作识别能力,同一Poselet的训练实例来自同一动作的训练集.数据集中人体都标注了关键点,对于每个肢体部件,先对同一动作训练集中该部件的图像窗口按照关键点的坐标聚类.同一聚类组成一个Poselet的正实例,负实例从其他动作的训练集中随机截取.图1显示了部分打高尔夫球动作中胳膊(包括左胳膊和右胳膊)Poselet的训练实例.
训练好Poselet以后,就可以从测试图像中检测每个Poselet的触发得分.部件的姿态特征由这组Poselet检测得分组成的向量表示.
人体整体具有所有的姿态信息,但是由于粒度太粗,难以从中提取姿态线索,尤其是胳膊和腿包含的与动作有关的姿态语义信息.另一方面,胳膊或腿等部件具有含部分姿态.因此,本文使用图2所示层次部件树中10个肢体部件的姿态特征表示人体姿态.图2中,从根节点开始,依次根据包含关系产生子节点,第二层节点包括胳膊、躯干+头、腿,第三层节点有左胳膊、右胳膊、头、躯干、左腿、右腿.从根到叶,肢体粒度由粗变细,可以充分利用这些部件各自在检测中的显著性大小、是否包含姿态和动作语义线索等方面的优点.更重要的是,后面将分析,图2的层次部件树结构为检测每个Poselet提供了一个精巧的上下文,可以用来抑制检测错误,提高动作识别性能.
2.2 Poselet上下文模型
给定Poselet模板,可以在图像中检测这个Poselet,但这样的检测结果模棱两可,难以辨别真假.首先,尽管物体检测水平不断提高,但仍然是一个未解决的开放问题.即使有足够的训练实例,经过充分训练的Poselet模板,也可能在没有人的图像中检测到Poselet,而在有这个Poselet的图像中却无法检测到.其次,Poselet是在训练实例数量少,质量差的情况训练出来的.训练Poselet需要标注人体的关键点,这需要耗费大量时间,因此,无法为训练Poselet提供海量的实例.同一Poselet的训练实例是通过对关键点坐标聚类确定的,同一聚类中的实例在姿态和外貌上有很大差别,这种实例集合难以训练出完美的检测模板.

图1 打高尔夫球动作中部分胳膊Poselet训练实例Fig.1 Instances for some arm poselets in playing golf
在物体识别领域,物体所在的上下文被用来提高检测能力.检测Poselet与检测物体本质上是一致的,Poselet的检测也可以利用上下文提高检测能力.例如,一个圆形的轮廓可能是人脸,如果在它的下部检测到躯体,则人脸的可能性就更大.Bourdev等[16]把Poselet作为相互检测的上下文,为每个Poselet训练一个星型的上下文模型.这种上下文模型类似一个两层的前向网络,输入层是每个Poselet的检测结果,在输出层,每个Poselet利用上下文改善检测结果,获得上下文环境中的检测得分.这个过程中,Poselet数量不变,但每个Poselet都利用了与其他Poselet的同时出现关系组成的上下文优化了检测结果.
本文的上下文模型也利用每个Poselet的检测结果,不同的是,本文利用了肢体部件之间相对位置和同时出现的制约关系构成的Pictorial结构,为检测其中每个Poselet构建了一个共有的上下文,见图2.
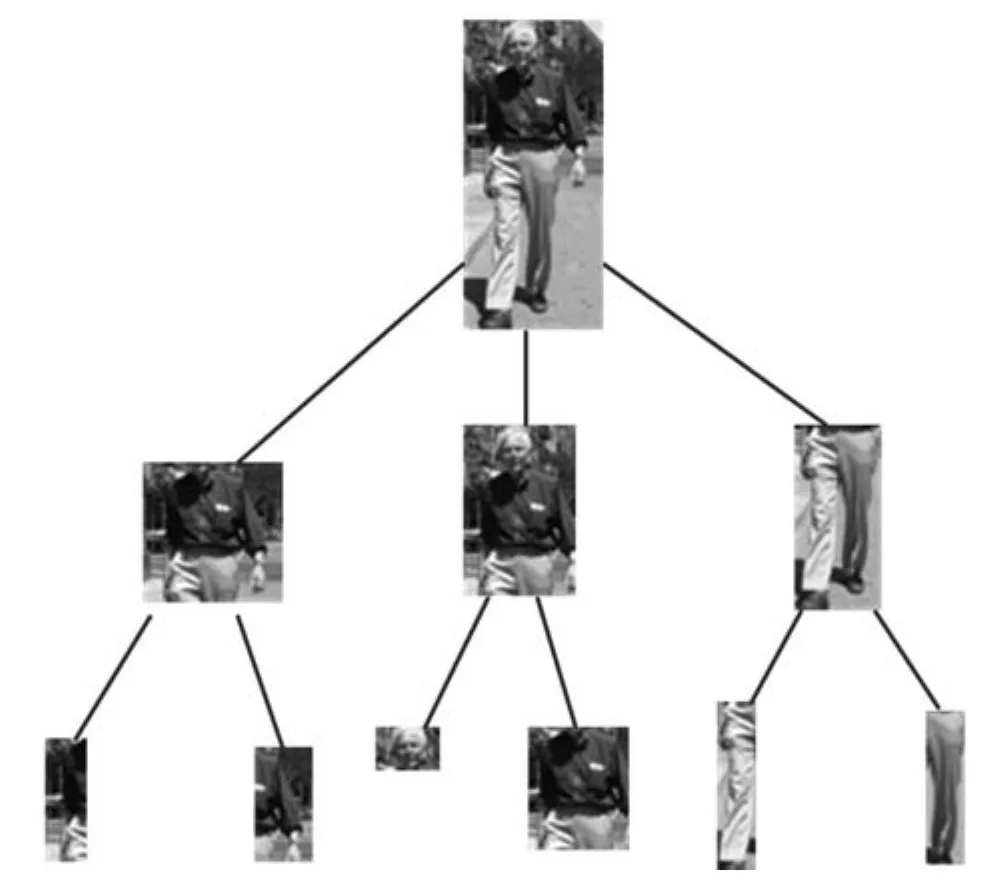
图2 层次部件树Fig.2 Hierarchical part tree
图2中的每个部件由一组Poselet表示.对于图像I,a∈{a1,a2,···,am}= Λ 为动作类别,m是类别数量.L=(l1,l2,···,l10)是层次部件树上10个肢体部件的位置,li=(pi,ti),其中pi=(xi,yi)是部件i在图像中的坐标,ti∈Ti是该图像中部件i的Poselet类别代号.用G=(V,E)表示层次部件树,i∈V表示部件i,(i,j)∈E表示连接i和j的边,层次部件树构成了一个Pictorial可变形模型[13]:

其中,Φa(I,li)是部件i的外貌潜在函数,描述动作a中部件i的Poselet模板αti,a在图像坐标pi处的匹配得分,按下式计算:
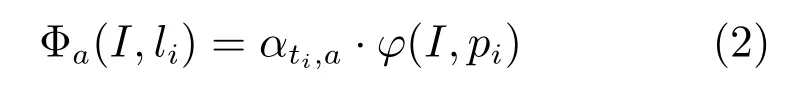
αti,a是Poseletti的模板,ϕ(I,pi)是图像pi处的HOG特征.Ψa(li,lj)是部件i和j的对偶潜在函数,表示给定动作a时,两者的变形代价和同时出现代价,按下式计算:
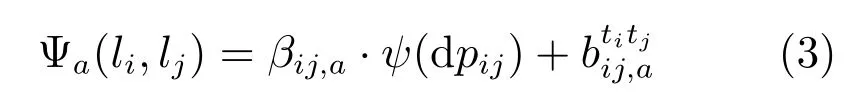
ψ(dpij)=[dxij,(dxij)2,dyij,(dyij)2]T,dxij=xi−xj−x0,dyij=yi−yj−y0,(x0,y0)是部件i相对于它的父节点j的锚接位置,即训练数据集中i相对于j的平均坐标差.与文献[17−18]的可变形模型相比,式(1)中的对偶潜在函数(3)中除了类似弹簧的变形代价,还增加了同时出现代价,描述Poseletti与tj彼此相容还是互斥及其程度.不同的动作图像中,有不同的同时出现关系.例如,在行走图像中,胳膊Poselet以及腿Poselet或者都是背面的,或者都是侧面的,不会出现背面的胳膊Poselet与侧面的腿Poselet在同一图像中.而在舞蹈图像中,这种同时出现关系就经常发生.Ψa(li,lj)中引入同时出现代价能够进一步利用Poselet外貌之间的关系,更准确地描述Poselet之间的约束关系.在本文两个数据集上的对比实验结果表明,引入同时出现代价后,动作识别性能分别提高了2.7%和2.1%.
图3是上下文模型的示意图,每个部件节点由一组Poselet表示,这些部件节点的Poselet之间形成了紧密的制约关系.图中第二层的第一个节点列举了三个姿态各异的Poselet,每个Poselet由四个训练实例表示,从身体朝向可以看出,第一个向前,第二个向后,第三个偏向右.如果在检测第一个Poselet时,它的上层节点以及下层节点的锚节点附近出现了很强的相容Poselet信号,上下文环境就支持这个Poselet,因此要提高它的检测得分.沿着树的边直到根节点以及其他节点,可以从树中每个节点获得检测这个Poselet的支持或扣分.可见,这一模型为检测Poselet提供了一个结构严密的上下文.

图3 Poselet上下文模型Fig.3 Poselet context
一种简单而幼稚的做法是为每个Poselet训练一个上下文模型.这样,把待检测Poselet所在的节点作为根节点,利用Pictorial结构[13]的推理,置信度传播到根节点时,就可以得到这个Poselet在上下文空间L中的最优得分.但这样做,需要训练大量的模型.本文使用同一个模型,为层次部件树上每个Poselet提供一个共有的上下文环境.
图4是该上下文模型的示意图.模型参数训练好以后,利用这个模型作为上下文环境,在图像中逐一检测其中的每个Poselet.图中显示了检测到第二层节点的第三个Poselet时的情况.此时,该节点Poselet限制为一个,但检测模板可以在图像空间中移动,其他节点各自调整Poselet类别以及位置,使得目标函数取得最大值.式(1)匹配的目标函数为:
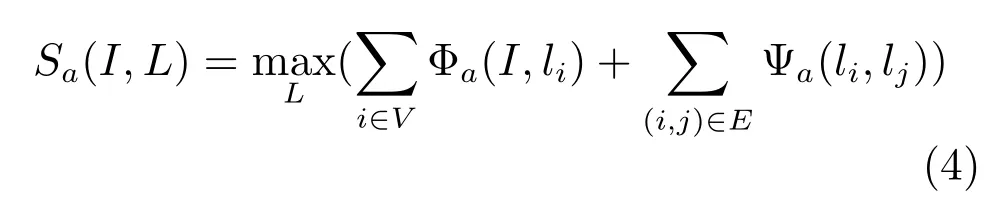
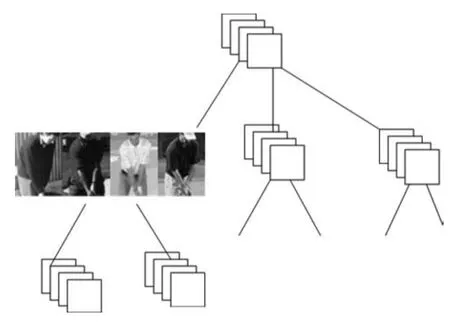
图4 在上下文环境中检测PoseletFig.4 Detecting Poselet in context
利用上下文模型检测节点v的Poseletτ时,该节点的Poselet类别限制为τ,目标函数为:

等式右边的第一项是τ在坐标pv=(xv,yv)的检测得分,第二项是除v节点外的其他节点在各自li处的检测得分,第三项是τ与节点v的父节点parent(v)之间的对偶潜在函数,如果τ是根节点,这一项为0.第四项是v及其所有孩子节点之间的对偶潜在函数之和,如果v是叶子节点,这一项为0.最后一项是层次部件树中与v节点无关的对偶潜在函数之和.
在动作图像中检测节点v的Poseletτ时,目标函数(5)衡量τ及其他部件节点的Poselet与上下文模型的匹配程度.匹配是一个置信度传播的过程,这一过程可以通过Pictorial结构[13]的距离转换算法高效地实现.置信度传播从HPT的叶节点开始,到根节点结束.用Sa(I,li)表示节点i收到每个孩子传来的置信度后的得分,则有:
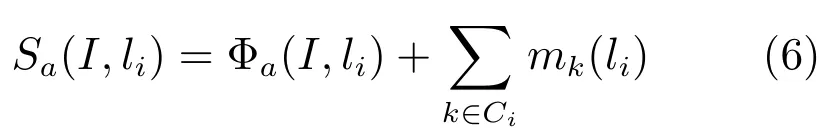
其中,Ci={c1,c2,···}是i的孩子节点集合,当i为叶节点时,mk(li)为0.Φa(I,li)是三维矩阵,保存部件i的一组Poselet在图像二维空间中的检测结果.当Poseletτ位于i节点时,只保留τ的二维矩阵,其他Poselet的检测结果均设置为0.节点i向它的父节点j传播的置信度为:
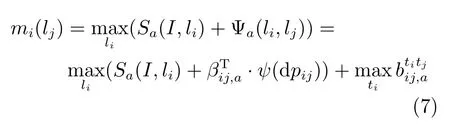
2.3 上下文模型的训练
式(6)匹配以后可以返回每个节点的坐标和Poselet类别,因此模型训练是一个结构支持向量机的训练问题.首先使用初始模型根据式(6)在训练图像上匹配,获得返回结果形成的特征向量,据此训练模型参数.本文训练过程使用随机坐标下降法[30],下面介绍模型参数的训练过程.
本文使用上下文模型的目的不是这个返回结果,而是抑制检测错误.在没有Poseletτ的图像中式(6)得分应该低,而在有τ的图像中,如果返回的Poselet类别和坐标与实际值吻合,得分应该高.
给定N个训练图像,Ii表示第i个图像,Li是图像中第i个部件的坐标和Poselet类别的标注,Poselet类别是训练实例聚类以后分配的聚类编号,坐标是该部件内所有关键点的中心坐标,Ai∈{a1,a2,···,am}= Λ 是图像的动作类别,对动作a训练上下文模型θa=(αa,βa,ba)的目标函数是:

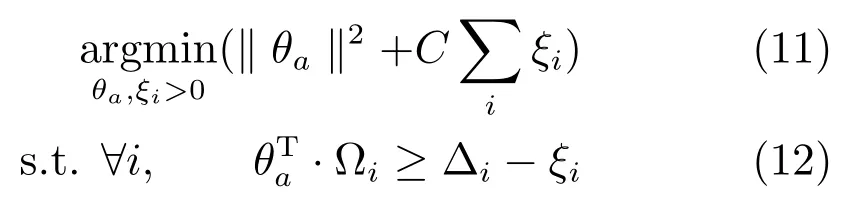
约束(12)中,对于负实例,∆i=1.训练过程中,为了确保目标函数是开口向下的凸函数,当变形代价参数βa中的二次变形权重为负时,将其调整为0.01.
3 提取深度特征
Alex的CNN网络[21]由五层卷积网络和三层全连通网络组成.第一层卷积网络的输入是经过预处理的三维图像,最后一层全连通网络的输出是对应1000种物体类别的向量,据此判定输入图像的类别,中间每层网络的输出是下一层网络的输入.这一架构的底层从图像提取诸如方向、梯度、颜色、频率等底层特征,经过连续多次的卷积计算,形成丰富的中间层特征,以及更加抽象且有判别能力的高层特征[31].
CNN是一个庞大的多层结构,Alex的8层CNN网络有6千万个参数和65万个神经元.从CNN提取深度特征,首先需要百万数量级的图像数据集训练CNN网络.否则,训练过程中产生过度拟合,而在测试数据上则无法得到理想的结果.本文的难题是训练数据集只有数千个训练图像,无法提供足够的训练数据,对此有两种解决方法.
第一种方法是预训练和精细调节.先在有足够训练实例的数据集上训练预备模型,然后以预备模型的参数初始化CNN网络,在新的数据集上以更小的速度训练最终模型.Alex网络出现以来,很多训练实例数量受限的研究选择此方法先在ILSVRC 2012数据集训练预备模型,然后在各自的数据集上精细调节模型参数[32].第二种方法是利用CNN网络良好的领域适应性,不做精细调节,直接把第一种方法中的预备模型作为一个黑盒的特征提取器,对新数据集中的图像提取深度特征.使用这种方法,Donahue等[31]在ILSVRC 2012数据集训练CNN模型,用来对鸟类数据集以及场景数据集提取深度特征.
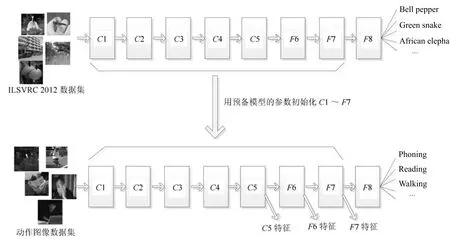
图5 提取深度特征Fig.5 Extract deep features
本文以第一种方法提取深度特征.预训练使用Alex的8层网络结构,在ILSVRC 2012训练集上训练预备模型,参见图5上部,其中C表示卷积层,F表示全连通层.用预备模型C1∼F7层的参数初始化新模型的C1∼F7层以后重新开始精细训练,新模型F8层的初始参数随机生成,输出类别数量设置为数据集动作类别的数量5.精细调节训练的初始速度设置为0.0001,即训练预备模型初始速度的十分之一.
4 实验
下面分别介绍本文使用的数据集,姿态特征单独使用时的动作识别性能,CNN网络的动作识别性能,以及姿态特征与深度特征混合使用后的性能.
4.1 数据集
在动作识别中,PASCAL VOC 2012动作数据集被广泛用来检验识别算法,并且与其他算法做性能比较.但这个数据集很多图像中的人体只有部分可见.例如很多阅读或者玩电脑的图像只有上半身,打电话和摄影的很多图像只有头部和胳膊的一部分.本文的姿态特征从肢体各部件中依次提取,要求肢体的所有部分出现在图像中,因此不使用这个数据集.
实验使用一个静止图像数据集和一个视频截图数据集,本文在静止图像数据集的训练集上训练模型,然后用同一模型分别评价在静止图像数据集以及视频截图数据集上的性能.
静止图像数据集是Ikizler-Cinbis等[11]从互联网收集的静止图像.Cinbis等以动作名称为关键字用Google以及Yahoo搜索引擎检索图像,然后通过迭代执行检测人体和去除无关图像的无监督方式对搜索得到的数据集进行清洗.数据集共有2458个图像,分别属于5个动作,舞蹈、打高尔夫球、跑步、坐和行走,部分图像参见图6.这些图像在拍摄角度,人体外形以及人体姿态上有非常大的差别.同行算法[17−18]对该数据集中的关键点做过标注,但是没有公开标注结果.本文首先对其中每个人体标注17个关键点,包括左右眼睛、左右耳朵、鼻子、左右手关节、左右肘关节、左右肩关节、左右臀关节、左右膝关节、左右脚关节,参见图7.根据标注结果从原始图像中截取128×64大小的人体图像,把其中1/3的图像作为训练集,1/3作为检验集,剩下1/3作为测试集.
另一个数据集是Niebles等收集的低分辨率视频数据集YouTube[33].Ikizler-Cinbis等[11]用人体检测模板先对这个数据集的帧图像做人体检测,然后对检测到的正确结果用矩形框做了标注,并标注了动作类别.与文献[11,17]一样,本文从标注的矩形框中截取人体窗口,作为视频截图数据集.该数据集的动作名称和数量与前一个数据集一致.由于人体窗口是按照检测结果截取的,存在人体不在图像中心位置,人体尺度大小不一的问题,图8显示了其中的部分图像.

图6 静止图像数据集中的部分图像Fig.6 Some images in static image data set

图7 标注了关键点的图像Fig.7 Some images with annotated key points
4.2 姿态特征的动作识别性能
上下文模型训练好以后,对于给定的图像,就可以根据(5)计算每个Poselet在层次部件树环境中的检测得分,然后组合成人体的姿态特征.层次部件树有10个节点,每个节点由12个Poselet表示,共5个动作,姿态特征的维度为10×12×5=600.本文在静止图像数据集的训练集上训练线性SVM,然后分别在静止图像数据集和视频截图数据集上评价动作识别性能.
由于没有公开静止图像数据集的标注,本文实验以及同行算法[17−18]各自标注关键点,训练集和测试集的划分也不一致.这种情况下,仅仅比较动作识别精度是不够的.由于同行算法[11,17−18]都把对整体图像HOG特征的多类别SVM作为基准算法,本实验沿用这一基准,下列性能比较中把相对于基准算法的性能提升作为一个重要的性能评价指标.
表1显示了静止图像数据集上本文的姿态特征与同行算法的动作识别精度比较,其中平均性能是5个动作识别精度的平均值.表1中CNN黑盒是利用文献[31]训练的CNN网络作为特征提取器,从动作图像中提取深度特征,然后使用线性SVM 分类的结果.Poselets[7]是本文的姿态特征在没有应用上下文模型的分类性能.从中可以看到,利用上下文模型后,本文的姿态特征性能提高了5.07%.与其他平面特征相比,本文的姿态特征具有最好的平均精度,且识别精度比基准算法提高了9.99%,这两个指标非常接近CNN黑盒[31]提取的深度特征.
表2是视频截图数据集上的动作识别性能.这个数据集是根据人体检测结果标注的,图像中人体尺度大小差别很大,而且很多图像中人体没有居中.同行算法multiLR_NMF[11]采用抖动技术使得人体大小适中且居中布置,降低了识别难度,动作识别性能及基准算法的识别性能有很大提高.从表2可以看到,本文的姿态特征在没有对截图图像做预处理的情况下,取得了与同行算法[11]非常接近的平均识别精度,与基准算法比较提高了14.16%,而算法[11]只比基准算法提高了4.26%.在该数据集上,本文姿态特征的性能与CNN黑盒[31]特征几乎持平.
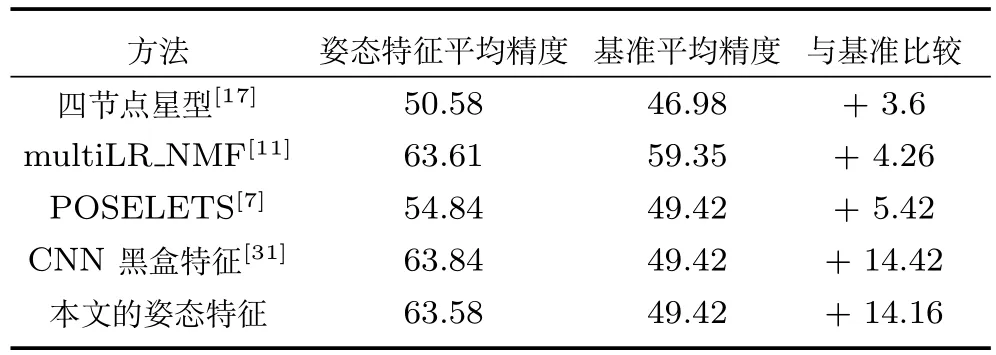
表2 视频截图数据集上的动作识别精度(%)Table 2 Precision on image form video data set(%)
4.3 CNN的动作识别性能
本文通过预训练和精细调节方法训练CNN网络,先在ILSVRC 2012训练集上训练预备模型,然后在静止图像数据集上精细调节模型参数.为了展示使用预备模型的效果,本文对使用预训练模型前后在静止图像数据集上做了对比实验.前者对C1∼F8层均使用随机的初始数据,在静止图像数据集的训练集上训练CNN网络.图9比较了使用预备模型前后CNN训练中出错率的变化过程.从图中可以看到,没有使用预备模型的情况下,训练结束时的出错率为37%,经过预训练和精细调节出错率降低到28%,下降了9%.可见,通过精细调节,很大程度上缓解了过度拟合问题.
4.4 姿态特征与深度特征混合后的性能
CNN的第一层卷积网络检测图像中的频率、方向、颜色等底层特征,有判别能力的特征在高层[21].本文从卷积网络的最后一层C5开始,依次提取图像的C5、F6、F7层输出分别组成深度特征向量,参见图5下部,通过实验验证深度特征与本文提出的姿态特征在动作识别中的互补作用.
图5中,C5是Alex网络的最后一个卷积层,对C4层输出的卷积运算结果执行Relu非线性运算后,再经过max合并,C5层的输出是一个6×6×256=9216矩阵.F6层通过6×6×256×4096卷积模板对C5输出执行全连通卷积运算,然后执行Relu变换,输出是一个4096维向量.F7层经过4096×4096全连通卷积,输出特征仍然是4096维向量.
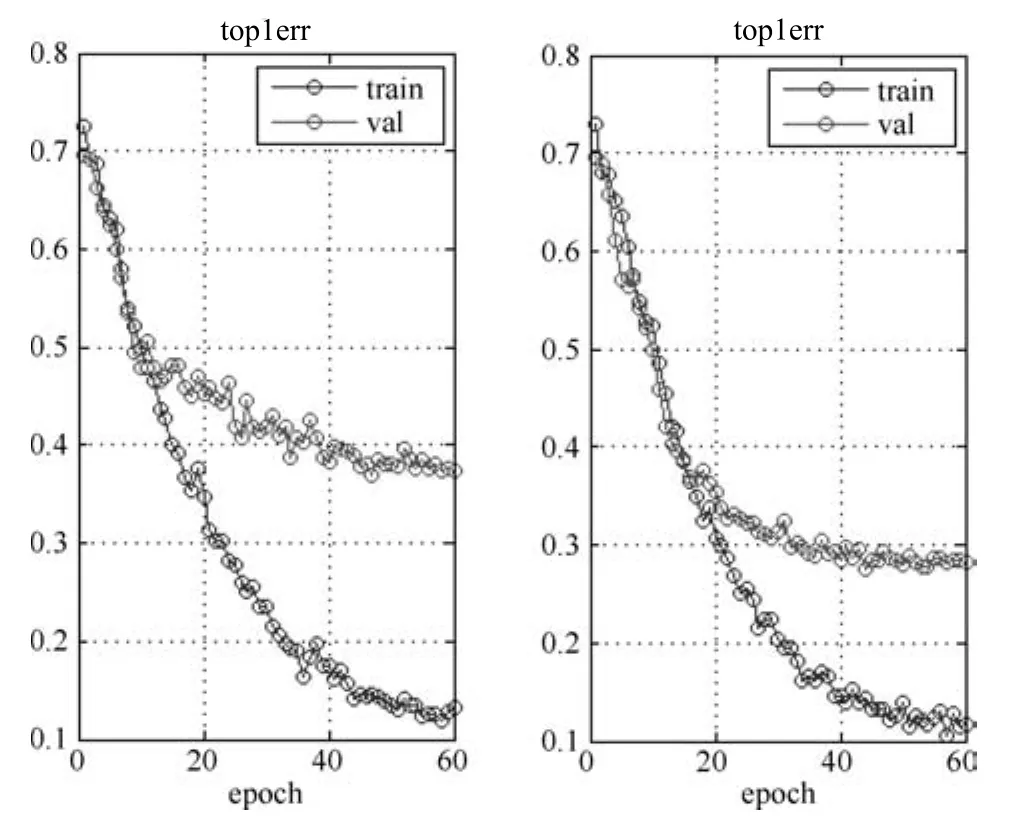
图9 使用预备模型前后CNN训练过程top1错误率比较Fig.9 Comparison of top1 error between whether using pre trained model
表3是静止图像数据集上本文提出的姿态特征,CNN,以及姿态特征与不同深度特征混合后的性能比较.其中CNN是通过预训练和精细调节的CNN深度网络分类的结果,姿态特征和深度特征的混合是把两者连接后使用线性SVM 的分类结果.从表中可以看出,CNN以71.7%精度高于姿态特征的识别精度.每种姿态特征与不同深度特征混合以后,性能均超过CNN以及姿态特征单独使用时的性能,且三种深度特征有不同的表现.姿态特征与F6和C5混合后的性能比较接近,高出与F7混合后的性能1.4个百分点.

表3 静止图像数据集姿态特征、CNN及混合后性能比较(%)Table 3 Precision comparison on static image data set(%)
表4是视频截图数据集上本文提出的姿态特征、CNN、以及姿态特征与不同深度特征混合后的性能比较.从表4可以看到与表3类似的结果,即姿态特征与深度特征的混合使用远远大于两者单独使用的性能.
从表3和表4可以看出,对不同的动作类别,姿态特征和CNN深度特征各有优势.对于跑步动作,两个数据集上姿态特征的性能均高于CNN深度特征,因为跑步中的人体姿态明显不同于其他四个动作,尤其是胳膊和腿的姿态.打高尔夫球也有独特的人体姿态,视频截图数据集上的结果显示姿态特征明显优于深度特征.而舞蹈动作中的很多姿态与行走以及坐相似,这三种动作的姿态容易混淆.表3和表4中显示,对这三种动作,从整体图像提取的深度特征性能高于姿态特征.
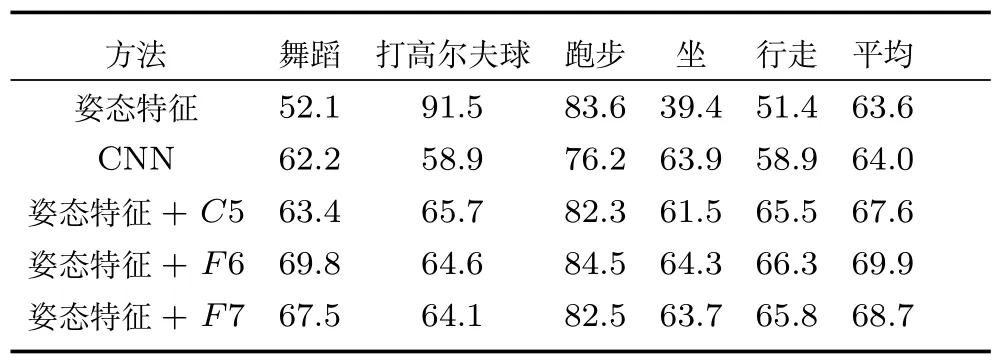
表4 视频截图数据集姿态特征、CNN及混合后精度比较(%)Table 4 Precision comparision on video data set(%)
为了进一步认识姿态特征和深度特征在动作识别中的互补作用,图10显示了部分姿态特征识别正确而深度特征识别错误的图像,图11显示了部分深度特征识别正确而姿态特征识别错误的图像,两图左侧是静止图像数据集中的图像,右侧是视频截图数据集中的图像.图10中的每个图像都有典型的动作姿态,但往往包含了干扰动作识别的背景,甚至有些是无背景的卡通图像,可见,这类图像中深度特征不如姿态特征.图11中的图像有些没有明显的动作姿态,有些尺度过大或过小,但图像中包含该动作的背景或物体,例如凳子、球场等等,这类图像中,深度特征的识别能力超过姿态特征.

图10 姿态特征识别正确而深度特征识别错误的图像Fig.10 Some images recognized accurately by pose feature but falsely by deep feature

图11 深度特征识别正确而姿态特征识别错误的图像Fig.11 Some images recognized accurately by deep feature but falsely by pose feature
5 结论
静止图像中的动作可以通过图像局部中的姿态线索识别,也可以对整体图像训练CNN网络识别.姿态特征描述人体的姿态语义信息,深度网络中的高层特征是经过深度学习得到的抽象特征,本文通过实验验证了两者在动作识别中的互补关系.为了在训练实例数量有限的数据集上提取深度特征,通过预训练和精细调节的方法训练深度网络,然后提取C5、F6、F7三层的输出作为深度特征.实验结果表明,这三层特征与姿态特征混合使用,性能均得到很大提升,且远远超过了单独使用CNN的性能.两个数据集上的实验结果表明,F6层深度特征与姿态特征混合使用性能最好,且最稳定.
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
学生天地(2020年3期)2020-08-25 09:04:16
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
制造技术与机床(2018年9期)2018-09-19 06:48:16
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
海外华文教育(2017年6期)2017-08-07 03:11:00
水电站机电技术(2016年1期)2016-02-28 14:21:50
