
一种新的AdaBoost人脸检测方法
2019-03-19 04:40:28杨晓龙董莺艳
重庆理工大学学报(自然科学) 2019年2期
闫 河,王 鹏, 杨晓龙,董莺艳,罗 成,李 焕
(1.重庆理工大学 计算机科学与工程学院, 重庆 400054;2.重庆理工大学 两江人工智能学院, 重庆 401147)
1 人脸特征提取方法
1.1 Haar-like特征提取
因多个全等矩形组成的Haar-like特征具有计算复杂度低的优点,Papageorgiou[11]将该方法运用到人脸检测中,之后Viola[10]对这种特征作了扩展。Haar-like 4种特征如图1所示。
Haar-like计算方法根据人脸器官不同区域存在着一定的差别的情况,用白色像素区域的特征减去黑色像素区域的特征来描述人脸的灰度分布。
Haar-like特征的4种基本模式可以较好地描述人的正脸,但这里存在一个严重的问题:当人脸形态发生变化时,或人脸倾斜、遮挡、发生表情变化时,这4种基本特征就无法有效地对人脸进行表达。通过对以上问题的分析,LIENHART等[13]在4种基本特征的基础上进行了一系列的扩展,并提出了扩展方法,即通过对旋转45°的特征进行分析的快速计算方法。通过扩展后的特征分析可以有效解决人脸姿态变化所引起的各种问题,如图2所示,扩展后的特征模型可分为3类。
如图2所示,Haar-like特征共有14种,故Haar-like特征的总数非常庞大,因此在运用此算法的同时也会存在训练时间较长等问题。为了解决此问题,需要选取最能描述人脸特征的模型,同时去除掉多余的特征描述模型,且在训练过程中,要自动分辨具有更好辨别性能的特征,从而缩短整个过程的训练时间。基于上述分析,本研究提出了一种新Haar-like特征,可有效降低训练时间,并通过实验验证了其有效性。
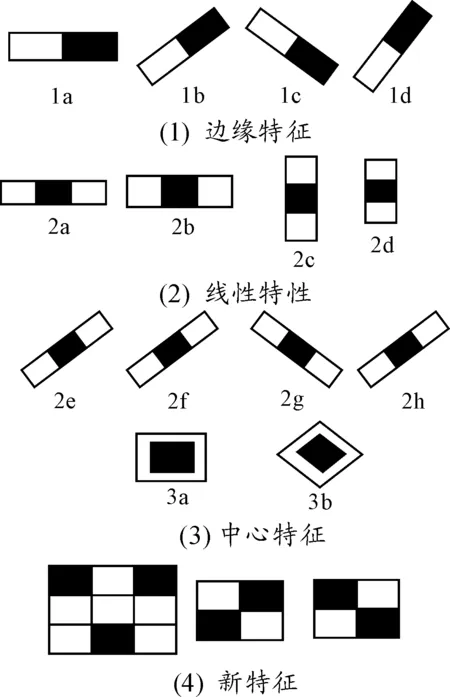
图2 新的Haar-like特征
1.2 积分运算
通过上述分析可知:在一幅图像中,Haar-like特征的总量非常巨大,这必然会增加计算的复杂度。为了提高计算的速度和检测的准确率,同时降低特征的计算复杂性,Viola等[10]提出了一种基于积分图的计算特征的方法。如图3所示,积分值I(x,y)就是点(x,y)对应的黑色区域的像素之和。
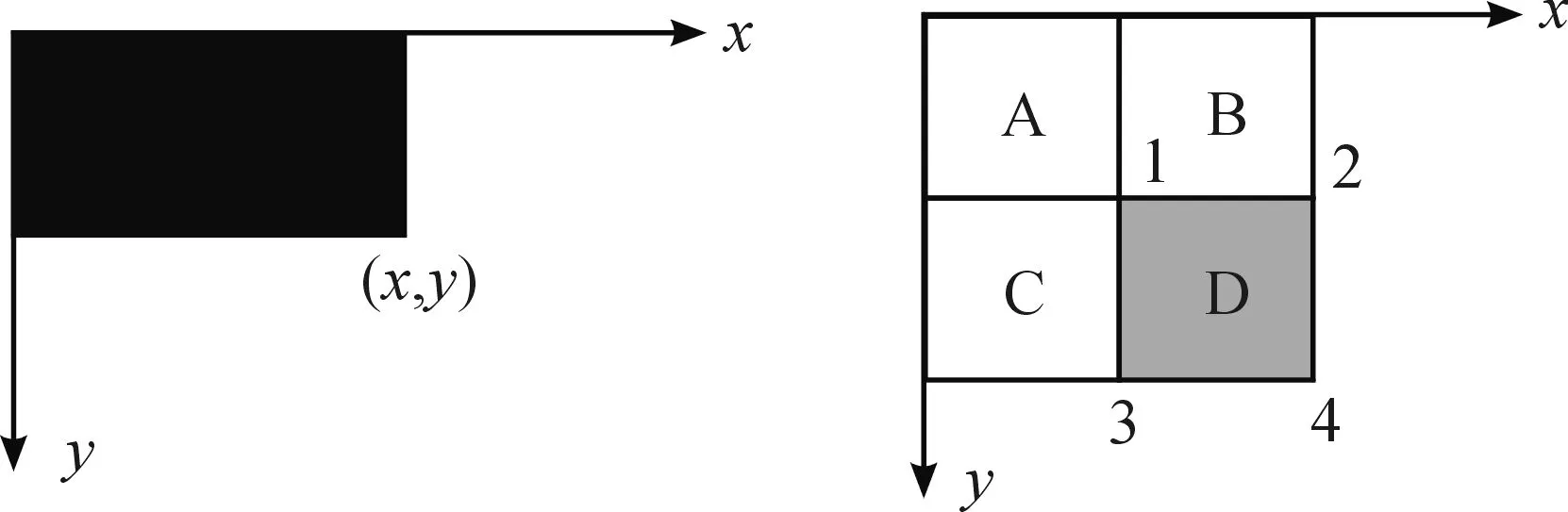
图3 特征积分示意图 图4 积分图值描述
在求一幅图像在任意区域的像素和时,通过积分运算的方法,只需要知道该区域每个端点的积分值,并通过对这些积分值的运算,就可得到各端点的积分图的值。此方法[13]在很大程度上降低了计算的复杂度,节约了计算的时间。
首先,以微电网购电成本与联络线功率波动为主要优化目标,得到最佳的优化结果。分别记作xC和xP,并计算每种优化方式对应的购电成本f1和波动系数f2;然后,引入两个虚拟参与者,将其策略分别设为f1和f2及xC和xP,形成二人零和博弈模型。其支付矩阵如表2所示。
下面讨论具体的算法:对于是正常角度的模型。如图3所示,点(x,y)左上方所有的像素值之和为该积分图I(x,y),有
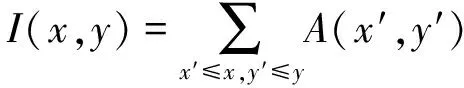
(1)
式中A(x′,y′)表示点(x′,y′)在图像中的灰度表示。
如图4所示,点1、2、3、4的积分图分别用I1、I2、I3、I4来表示,通过计算可得D区域的像素总和为:
Sum(D)=(I4+I1)-(I2+I3)
(2)
同样的方法,计算得到图4中A区域和B区域的像素和分别为:
Sum(A)=(I4+I1)-(I2+I3)
(3)
Sum(B)=(I6+I3)-(I4+I5)
(4)
则该类型的Haar-like特征值为:
Sum(A)-Sum(B)=(I4-I3)-(I2-I1)+
(I4-I3)-(I6-I5)
(5)
通过以上的计算分析,对于正常角度的特征模型,只需要知道相应端点的积分图,并通过简单的积分加减运算,就可得到相应的结果。对有旋转的特征模型,LIENHART等[13]通过对积分图的重新计算和定义,发现点(x,y)的积分图I′(x,y)为点向正上方拉伸且角度为45°的矩形区域内所有像素的灰度总和。
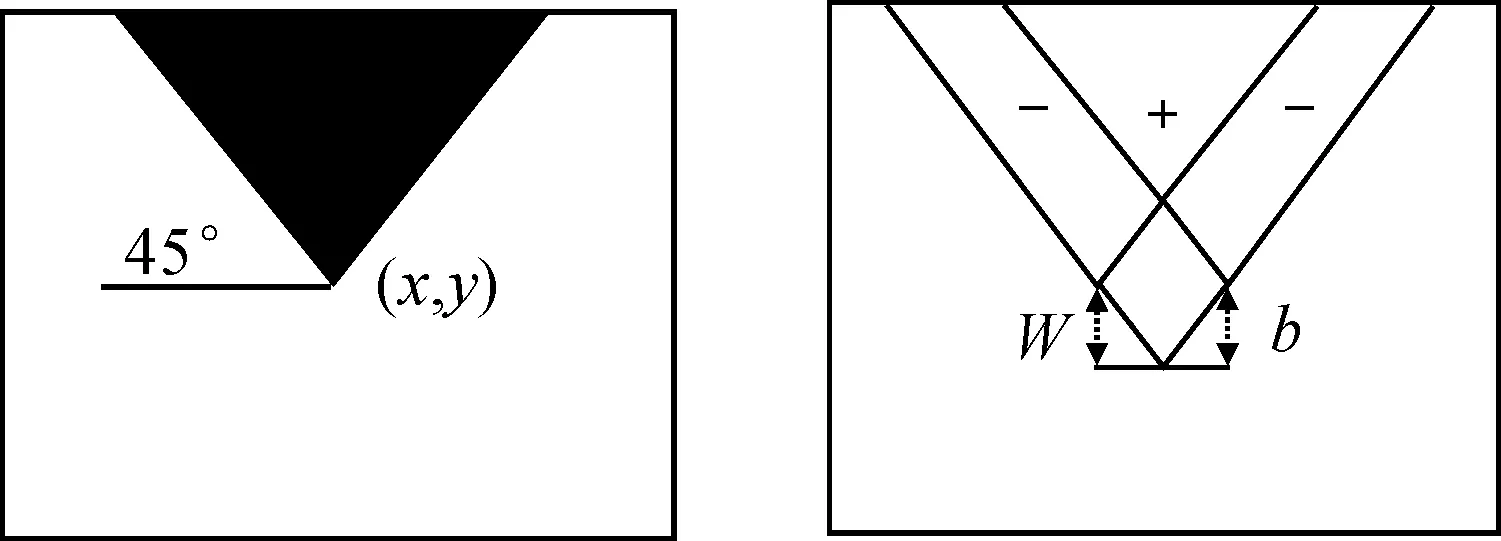
图5 带旋转角特征值计算示意图
I′(x,y)计算公式如式(6)所示。
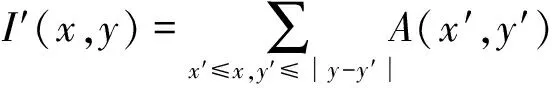
(6)
其中A(x′,y′)代表点(x′,y′)对应的灰度值,为I′(x,y)的值,一般通过递归的计算方法得到积分图的表达式:
I′(x,y)=I′(x-1,y-1)+I′(x+1,y-1)-
I′(x,y-2)+A(x,y)+A(x,y-1)
I′(-1,y)=I′(x,-1)=I′(x,-2)=
I′(-2,y)=0
(7)
通过这种方法,可以快速求出所在矩形区域的像素和。图5的像素和为
Sum(I)=I′(x+w,y+w)+I′(x-h,y+h)-
I′(x,y)-I′(x+w-h,y+w+h)
(8)
通过以上分析可知:新的Haar-like特征只需进行相应的加减运算即可得到,极大地提升了特征的提取速度。
2 算法概述
2.1 弱分类器
AdaBoost算法从众多的特征中选取符合人脸Haar-like的特征,利用这些特征构造弱分类器,并通过迭代的方法从众多弱分类器中选取分类效果较好的值进行组合,并通过加权分配不同的权重,形成最后的强分类器。
弱分类器hj为:
(9)
其中:pj表示不等式的方向;x表示检测子窗口;j为样本中的第j个特征;这里共有±1两种不同的情况。第j个矩形所对应的特征值为gj(x),弱分类的阈值为θj。当hj=1时,样本x为人脸;当hj=0时,样本x为非人脸。
2.2 级联分类器
大量Haar-like特征的弱分类器通过AdaBoost算法训练成强分类器。采取Cascade的策略,运用此强分类器用于最后的人脸检测,可改善检测速度慢等实际情况。这种策略采用的是逐层验证方式,每一层都会排除大量的非人脸样本,同时随着层数的增加,对应的各种强分类器的数量也在增加,每个强分类器中包含的弱分类器也在增加,结构会变得越来越复杂。在整个层级中,需要对阈值合理调整才能准确识别出人脸和非人脸样本。此方法并不会因为弱分类器的不断增加而降低检测速度。
3 实验结果分析
通过上述分析,文献[14]提出了基于Haar-like特征的人脸检测,可以满足实时检测要求。本文提出了基于改进的新Haar-like特征的人脸检测方法。为了验证所提出的人脸检测方法的有效性,采用实验对基于肤色模型的人脸检测结果进行对比(图8~10)。
肤色模型[15-16]的人脸检测首先是检测肤色的区域(如图6所示),然后筛选出人脸的区域(如图7所示)。通过测量,检测的时间为2.43 s。图10为本文的人脸检测方法检测结果,通过测量,检测的时间为1.41 s。通过对比发现:本文算法的检测时间明显低于基于肤色模型的检测时间,充分证明了本文所提算法在人脸检测时效性上的优势。

图6 测试图片

图7 肤色区域

图8 人脸肤色区域

图9 肤色模型的人脸检测结果

图10 本文算法的人脸检测结果
为了进一步验证本文算法的有效性,选取更为经典的Lena图像。此图像暴露了大量的与人脸肤色相近的皮肤和背景颜色,使用肤色模型会造成较大的误差,如图12所示。图13为本文算法人脸检测结果。通过对比发现:本文算法的检测准确率明显高于基于肤色模型的人脸检测率。

图11 Lena图像

图13 本文算法人脸检测结果
为了进一步验证本文算法的有效性,测试数据选取CMU人脸数据集的部分图像,共200张图像,并带有300张人脸。200张图像中包含150张单人脸图像和50多张人脸图像,数据集包含了不同光照和不同肤色等复杂场景的人脸图片。采用本文算法得出检测率,检测结果如表1所示。
通过表1可知:在人脸检测准确率和平均检测时长两方面进行比较,本文算法均优于肤色检测模型和常规AdaBoost人脸检测算法,并进一步证明了本文算法的有效性和鲁棒性。

表1 检测结果
4 结束语
本文对Haar-like特征进行扩展,给出了此特征检测方法的计算过程和分析过程,同时通过弱分类器训练级联强分类器,用于最后的人脸检测。通过在人脸库上的验证实验,证明了本文算法具有检测速度快、检测准确率高的特点。但也有待改进之处:一是本文所用的级联分类器虽然构造简单,但会损失一定的精度和准确率;二是对于多角度人脸,如倾斜角超过45°的人脸目前还无法有效地准确检测。因而,下一步的主要工作将针对多角度的人脸检测做进一步的方法改进。本研究有着广泛的应用领域,能为我国的智能化建设提供技术支持。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
疯狂英语·新悦读(2020年4期)2020-06-18 05:35:28
好孩子画报(2020年3期)2020-05-14 13:42:44
动漫星空(2018年9期)2018-10-26 01:17:14
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
电测与仪表(2014年15期)2014-04-04 12:05:20
