
基于Python的图博档数字资源推荐算法
2019-03-14 07:19:30陈玉鸣
图书馆研究 2019年1期
陈玉鸣
(南京大学信息管理学院,江苏 南京 210046)
1 引言
快节奏的生活方式让越来越少的人倾向于去图书馆、档案馆、博物馆(以下简称“图博档”)等实体机构查找资料。因此,为了满足人们的需要,数字化的图博档平台开始出现并快速发展起来。仅以图书馆的数字化为例,截至2016年底,国家图书馆的数字资源总量达1 323.35 TB,与2015年相比增加162.37 TB。其中,馆藏特色数字化资源1 059.69 TB,外购数据库101 TB,网络导航和网络资源采集114.73 TB,征集数字资源42 TB,电子报纸呈缴5.93 TB[1]。然而,在信息资源数量大幅增加的同时,很多真正迎合用户需要的信息却被淹没在茫茫的信息海洋中,难以被有需求的用户轻易发现。同时,由于现在图博档数字资源平台的信息量巨大,用户需要花费很多时间搜索所需信息,而人们的时间精力也有限,需要在尽可能短的时间内获取尽可能多的有效信息资源,在这种情况下,图博档平台有必要采用一套推荐系统让用户快速并精确地获取所需信息。
2 研究现状
推荐系统利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西,并将这些结果推荐给用户。推荐系统现被广泛应用于购物网站、旅游网站等。推荐系统的核心是推荐算法,常见的推荐算法包括基于协同过滤的推荐算法、基于内容的推荐算法、基于关联规则的推荐算法等。这些算法有各自的优点,但对于图博档数字资源平台来说,也存在缺陷。国内外专家学者们将这些基础的推荐算法进行改进与融合,完善了其功能。
GIOVANNI SEMERARO等人[2]提出了一种基于内容的推荐算法,它通过基于内容的经典模型中的社交标签来集成用户生成的内容,让用户通过输入数字评分以及用自由标签注释项来表达对物品的偏好。该推荐算法提高了推荐内容的准确性,是个性化博物馆设计的网络服务的核心。
“冷启动”问题是推荐算法常见的难题。为了解决这一问题,Jason Morawski等人[3]在传统的协同过滤推荐算法上进行改进,提出了一种使用模糊向量的协同过滤与内容过滤混合的推荐算法。该算法有效解决了传统协同过滤推荐算法的“冷启动”问题,适合于馆藏相对较少的图书馆,这种方法对稀疏数据集特别有效。
为了更加切合项目,Alvaro Tejeda-Lorente等人[4]提出一种能够考虑项目质量的推荐算法,这个系统使用项目的质量来计量它们的相关性,该算法提出一种策略能在基于内容的推荐算法和协同过滤算法之间切换,该推荐系统采用模糊语言学的方法开发,并在大学数字图书馆中得到了令人满意的测试。
Gabroveanu Mihai[5]提出一种基于分布式学习管理系统关联规则的推荐系统,利用分布式数据挖掘算法分析来自LMS数据库的信息已提取关联规则,然后提取的规则被用作推理规则来提供个性化推荐,可以使推荐更加准确。
国内学者也为推荐算法的研究做出了杰出贡献:张红燕[6]借助数据挖掘技术找到关联规则,分析高校图书馆内读者的借阅行为,并运用基于数据库的知识发现(KDD)方法,构建一个以书目或书目阶层为导向的高校图书馆新书推荐系统,以帮助读者快速找到适合自己的学习资料,增强其对图书馆服务的满意度。徐文青、双林平[7]依照Web2.0的“社会化标注”思想,针对基于内容的推荐算法(CBR)和协同过滤推荐算法(CF)存在的不足,提出了基于读者标签(TAGS)的、融合图书“热门度”因子的个性化图书推荐的两个改进算法。利用统计分析软件R,重点对改进后的CBR算法进行实验分析和验证,结果表明,改进算法的图书个性化推荐效果有明显改善。田磊等人[8]利用改进的K-mean算法对借阅用户的类别与偏好性进行了系统的分析,然后通过构造用户借阅偏好性矩阵与用户相似性度量,采用协同过滤算法实现了图书借阅的个性化推荐。该算法可根据用户的借阅爱好准确地为其推荐图书,整体上具有较高的性能,提高了图书推荐的准确率。
国内外专家学者所研究的这些推荐算法,为本文所介绍的服务于图博档数字资源平台的推荐算法提供了宝贵的参考价值。
3 算法设计
本文所介绍的图博档数字资源推荐算法,总结了以上推荐算法的优点,在此基础上进行改善。通过获取用户的历史浏览记录,在整个数字资源数据库中进行遍历,推荐给用户相关的数字资源。这一方式解决了不能推荐新加入数据库的物品的问题,同时可以推荐出数据库中所包含的用户所感兴趣的全部内容,不至于丧失多样性。如图1所示,首先从图博档数字资源平台中获取需要推荐给用户的数字资源,加以整理,提取关键属性,然后再获取用户的浏览记录,从浏览记录中提取关键词,在提取出来的需要推荐给用户的数字资源中匹配这些关键词,就能把用户所感兴趣的、所需要的信息资源提取出来,屏蔽掉一些无关的信息,推荐给用户,让用户在数字资源平台中浏览信息时难以错过潜在的符合需要的数字资源。
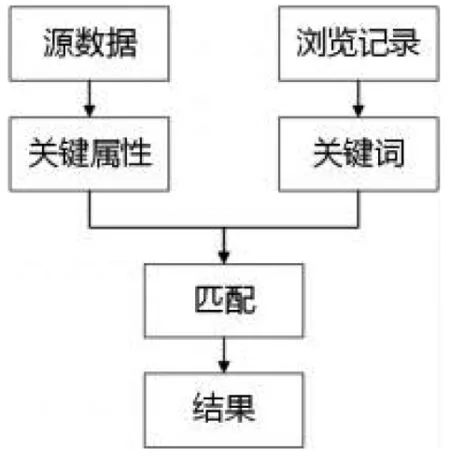
图1 推荐算法流程图
3.1 开发平台
本文所介绍的推荐算法是基于python编程语言在eclipse平台上开发的,python是一种面向对象的解释型计算机程序设计语言,语法简洁清晰,拥有丰富和强大的库,是当今主流的编程语言之一。
3.2 源数据
在图博档数字资源平台浩如烟海的数据资源中,存在着各种类型的数据。如果针对每一种类型的数据都用一种推荐算法,过程烦琐且工作量大。本文介绍的推荐系统可以适用于各种类型的数据推荐服务,简单有效。在实验中,将采用讲座类型的数据进行实验分析。
由于源数据的信息量很大,而很多信息对于所要实现的推荐功能来说是无效信息,因此要对这些信息进行加工,提取出所需要的信息序列,将其重新写入一个文本文档当作新的数据源。对于讲座类型的数据进行推荐,需要知道讲座举办的时间、地点、主讲人、主题等信息。
3.3 关键词获取
关键词获取是该推荐算法的核心功能。在python环境下,笔者采用了jieba中文分词[9]。中文分词指的是将一个汉字序列切分成一个一个单独的词。Jieba分词是一款比较成熟的中文分词工具,具有支持三种分词模式的特点:(1)精确模式。试图将句子最精确地切开,适合文本分析;(2)全模式。把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;(3)搜索引擎模式。在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词。
Jieba分词的基本思路如下:(1)加载词典dict.txt;(2)从内存的词典中构建该句子的DAG(有向无环图);(3)对于词典中未收录的词,使用HMM模型的viterbi算法尝试分词处理;(4)已收录词和未收录词全部分词完毕后,使用dp寻找DAG的最大概率路径;(5)输出分词结果。
3.4 关键词匹配
通过对用户浏览记录的分词分析,得到用户所需求的关键信息,根据这些关键词,就可以在数据库中进行查找,得到与用户所需相符合的讲座信息。
4 结果分析
以Eclipse Java Oxygen为试验平台,搭载python2.7语言,以推荐讲座为样例进行实验。
4.1 获取数据源
连接平台的数据库,从存有讲座信息的表lecture里获得讲座全部信息,择取其中主要属性data,time,topic,speaker,lectureInfo,place,address,形成一组新的讲座信息,以文本文档的格式保存到本地文件lecture.txt里。运行结果如图2所示。

图2 获取的讲座信息图
以相同方式获取用户的浏览记录,这里主要获取用户浏览记录的title参数属性,将结果以文本文档的格式保存到本地文件trace.txt里。
4.2 获取关键词
定义Get_Keywords()函数,用open()函数打开trace.txt文件,调用jieba中文分词插件,获取用户浏览痕迹的关键词,以文本文档的形式保存到本地文件keywords.txt里。因为用户浏览记录是以表的形式存储的,而表存在换行问题,单行的浏览记录与多行的浏览记录可能存在差异,因此在这里笔者将浏览记录分为单行和多行的情况分别进行实验测试。
4.2.1 单行浏览记录的关键词获取
当浏览记录是单行记录时,如图3所示。

图3 单行浏览记录示例图
把需要获取的关键词数目设为3个,运行结果如图4所示。

图4 单行浏览记录关键词获取图
4.2.2 多行浏览记录的关键词获取
当浏览记录是多行记录时,如图5所示。

图5 多行浏览记录示例图
把需要获取的关键词数目设为3个,运行结果如图6所示。用户浏览记录里的关键信息。

图6 多行浏览记录关键词获取图
4.3 关键词匹配
定义Find_match()函数,将这些得到的讲座信息放进文本文档result.txt,系统平台可以将这些内容推荐给用户。同关键词获取所存在的问题一样,对于单个关键词和多个关键词,能否做到每个关键词逐行遍历是该算法的一个难点,笔者将关键词设定为1个和多个分别进行试验来验证该算法的有效性。
4.3.1 单个关键词匹配
当获取的关键词为单个时(如图7所示),预期的结果是能够在lecture.txt文件里筛选出所有包含该关键词的讲座条目。

图7 单个关键词示例图
运行结果如图8所示。

图8 单个关键词匹配实验结果图
4.3.2 多个关键词匹配
当获取的关键词为多个时(如图9所示),预期的结果是能够在lecture.txt文件里筛选出所有包含一个或多个关键词的讲座条目。

图9 多个关键词示例图
运行结果如图10所示。
由上述实验结果可知,无论对于单行浏览记录还是多行浏览记录,该算法都可以成功地获取

图10 多个关键词匹配实验结果图
由此可见,无论是单个关键词还是多个关键词,该推荐算法都可以准确地推荐出所有包含这些关键词的讲座条目。
5 结语
在大数据时代,推荐系统可以很大程度上便利用户的信息检索需求,在未来必将成为图博档数字服务平台里不可缺少的一部分。经实验论证,本文所介绍的基于python的图博档数字资源推荐算法可以成功地实现为用户推荐的功能,该推荐算法的优点是推荐内容全面且具有多样性,适用性强,其基于python开发语言的特性,能应用于各种图博档数字服务平台。除了适用性外,该算法灵活多变,管理者可以在后台更改推荐给用户的信息数量。
本文提出的推荐算法目前的弊端是需要平台本身提供用户浏览痕迹,对于没有保存用户浏览痕迹的平台,该算法的具体应用将作为今后研究的课题。
猜你喜欢
智富时代(2019年6期)2019-07-24 10:33:16
创新作文(5-6年级)(2018年11期)2018-04-23 12:46:50
高中生·天天向上(2016年9期)2016-11-22 09:10:34
南风窗(2016年19期)2016-09-21 16:56:12
山东青年(2016年3期)2016-02-28 14:25:46
少儿美术·书法版(2016年12期)2016-02-06 01:00:52
少儿美术·书法版(2016年5期)2016-02-06 01:00:25
小天使·六年级语数英综合(2014年3期)2014-03-15 00:26:19
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
外语学刊(2011年3期)2011-01-22 03:42:20
