
条件区间分位数超高维特征筛选研究
2019-02-19 01:38,,
郑州大学学报(理学版) 2019年1期
, ,
(南京信息工程大学 数学与统计学院 江苏 南京 210044)
0 引言
随着科学技术的飞速发展,人类在知识探索发现、社会发展、个人生活等方面越来越多地面临超高维数据的分析问题,例如:对人体基因序列的解码,海量待投资目标中的最优投资组合确定,以及医疗核磁共振检查数据的分析等.在超高维数据中,协变量Z=(Z1,…,Zpn)T的维数pn随着样本量n呈指数级增长,但只有少量的协变量同响应变量之间是相互关联的,模型呈现稀疏性特征.现有的基于惩罚似然的变量选择方法,如Lasso[1]、SCAD[2]、Adaptive Lasso[3]等方法不能很好地解决问题.为了解决超高维数据的降维问题,近年来很多学者提出了多种便捷的超高维变量筛选方法,先将pn维降到较小维数dn,然后再利用传统的变量选择方法进行建模.文献[4] 基于超高维线性回归模型提出了基于边际相关系数的SIS方法.文献[5]将确定性独立筛选方法(sure independence screening, SIS)和迭代的确定性独立筛选方法(iterative sure independence screening,ISIS)推广到了广义线性模型.文献[6]提出了基于协变量和响应变量条件分布边际相关的稳健超高维筛选指标.文献[7]基于距离相关系数提出了无模型假设下的特征筛选方法.文献[8]在无模型假设下提出了基于条件分位数的超高维特征筛选方法.文献[9]结合局部领域嵌入算法与l2,1范数提出一种无监督特征选择方法.

1 筛选和排序过程
为了给出超高维筛选指标,定义与响应变量Y相关的重要变量集合记为A,那么
A={k:F(yZ)依赖Zk,k=1,…,pn,∃y∈Ψy},
Ψy为Y的取值区域.仿照文献[8],可定义基于τ∈Δ⊂(0,1)下的重要变量集合Aτ={k:Qτ(YZ)依赖Zk,k=1,…,pn}.
注意到如果Y与Zk独立,Qτ(YZk)=Qτ(Y),τ∈Δ,k=1,…,pn,那么
E[τ-I{Y 定义dk,τ(t)=E([τ-I{Y 则Qτ(YZk)=Qτ(Y)时,ωk=0;反之ωk>0,k=1,…,pn.由此可见,ωk越大,则越代表Zk是与Y不独立的重要变量. 为了给出重要变量集合的估计,定义dk,τ(t)的经验估计为 本研究发现,种植体植入后即刻及12周,直径为5.0 mm种植体的ISQ值显著高于直径为3.5、4.3 mm的种植体(P<0.05);说明种植体直径对植入后的稳定性存在显著影响。可能是受限于病例数和研究方法,本研究中种植体长度对稳定性的影响并不显著。Romanos等[12]认为,在HU值较大的区域宽径种植体可以获得更好的稳定性。 Shiffler等[17]研究发现,长度对种植体稳定性存在显著影响,同时认为下颌区种植体的稳定性普遍高于上颌区。本研究中,术前颌骨HU值下颌显著高于上颌,种植体植入后即刻及12周下颌区的ISQ值也显著高于上颌(P<0.05),与Shiffler等的研究结果相一致。 条件3 在Qτ(Y)附近,F(y)二次可微,Y的密度函数f(y)对正数c01、c02一致地满足0 定理1在条件3下,若nτ>nα/2,则存在正数c1和c2,使得 ωk≥cn-α)≤O(pnnτexp (-c1n1-2α)+pnnτexp (-c2n3-2α)), (1) 且在条件1和条件2下 (2) 其中:sn=Aτ是集合Aτ中元素的个数. 注: 由于变量维数pn随样本量呈指数级增长,若pn=O(exp (nγ)),则当0<γ<1-2α,nα/2 (3) 注意到 (4) 根据文献[8]定理1的证明可以得到 ≥cn-α)≤3exp (-c1n1-2α)+3exp (-c2n3-2α). (5) 则由式(3)~(5)可得 ωk≥cn-α)≤3nτexp (-c3n1-2α)+3nτexp (-c4n3-2α). 那么容易得到 ωk≥cn-α)≤O(pnnτexp (-c3n1-2α)+pnnτexp (-c4n3-2α)). 下面证明定理1的第二部分结论. 本文通过蒙特卡罗方法来验证所提出筛选方法的有限样本性质,为了说明所提出方法IQ-SIS的优劣,将与Q-SIS (文献[8])、SIRS (文献[6])和DC-SIS (文献[7])进行比较,考虑样本量n为100或200,协变量维数pn=2 000,并重复200次试验,筛选出的变量个数dn=[n/log (n)].为方便比较,沿用文献[8]相同的模拟例子和评价指标,其中指标p0为真实模型大小;Median为200次重复试验中包含所有重要预测变量的最小模型大小的中位数;IQR为200次重复试验中包含所有重要预测变量的最小模型大小的四分位差;PAll为200次重复试验中在给定筛选变量个数后,筛选出包含所有重要预测变量次数的百分比. 例1考虑如下模型 Y=Z1+0.8Z2+0.6Z3+0.4Z4+0.2Z5+σ(Z)ε, 其中Z=(Z1,…,Zpn)T服从多元正态分布,均值向量为0,协方差矩阵Σ=0.8|i-j|,(i,j=1,…,pn),σ(Z)=exp (Z20+Z21+Z22),且ε服从标准正态分布或标准柯西分布,考虑分位数点τ取值为0.5或0.75.可见,在分位数为0.5时,真实模型的重要变量个数为5;分位数为0.75时,真实模型的重要变量个数为8.为了给出更稳健的筛选结果,根据所提出区间分位数的思想,考虑分位数区间分别为[0.4,0.6]和[0.7,0.8]用于IQ-SIS.模拟结果见表1. 表1 例1模型的变量筛选模拟结果 例2考虑更复杂的非线性模型 σ(Z)ε, 其他模拟条件与例1相同,模拟结果如表2所示. 表2 例2非线性模型的变量筛选模拟结果 从表1和表2的模拟结果可以发现,本文改进的条件区间分位数筛选方法IQ-SIS要优于Q-SIS特征筛选方法,具有更小的模型大小和更高的重要变量覆盖率,并且随着样本量的增加,筛选出包含所有重要预测变量的百分比显著增加,并趋近于1.当考虑异方差情形的时候,在0.75分位数条件下,IQ-SIS也较Q-SIS有更优良的表现.DC-SIS在所有结果中表现最差,SIRS由于考虑的是全局情况下的特征筛选,所以相较于仅仅考虑0.75分位数范围的条件分位数筛选方法具有更好的表现.但如果所研究问题为特定分位数条件下的分位数回归问题,则本文所提出方法则有其局部研究优势.总的来说,本文所改进的区间条件分位数筛选方法较Q-SIS更加稳健可靠. 本文探讨了超高维数据的特征筛选和降维问题,超高维数据建模的首要任务是通过快速便捷的降维方法,将超高维减少为一般高维问题,则传统的高维降维方法就可适用于数据建模.在现有超高维降维方法的基础上,本文推广了无模型假设的基于条件分位数的特征筛选方法,改善基于特定分位数水平而导致的可能由于分位数微小扰动产生的筛选变量的不稳定性.本文提出基于条件区间分位数的特征筛选方法,并说明所提出方法具有无模型假设、计算简便、稳健性高的特点,并从理论上证明了所提出方法满足特征筛选的筛选相合性.此外,本文还通过蒙特卡罗数值模拟验证了所提出方法的有限样本性质,结果表明所提出方法能够改善传统的基于特定条件分位数的特征筛选方法的筛选降维效果.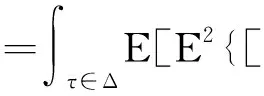


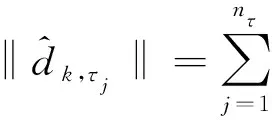
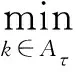


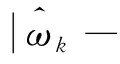

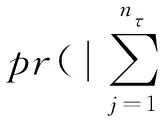
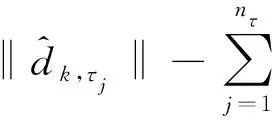


2 数值模拟


3 结论
猜你喜欢
心理学报(2022年10期)2022-10-12福建农林大学学报(自然科学版)(2022年5期)2022-10-08车主之友(2022年4期)2022-08-27中国循证心血管医学杂志(2022年1期)2022-03-15内蒙古统计(2021年4期)2021-12-06海峡姐妹(2019年12期)2020-01-14小学生学习指导(中年级)(2020年3期)2020-01-03学校教育研究(2019年24期)2019-02-07火控雷达技术(2016年1期)2016-02-06
