
一个面向影音视频的宽带通信节带化系统
2019-02-19 01:28,,,,,,
郑州大学学报(理学版) 2019年1期
, , , , , ,
(云南大学 信息学院 云南 昆明 650504)
0 引言
随着互联网产业的飞速发展,语音、图片、视频等各种多媒体类型的文件应用越来越广泛,其中数字视频通信成为人们关注的焦点,在多媒体通信应用中占据重要位置.为了解决其存储和传输占用的宽带资源,国际电信联盟及国际标准化组织制定了H.261、H.263、H.264、H.265、MPEG-1、MPEG-2、MPEG-4、MPEG-7等系列标准用于视频压缩编码.2002年6月,音视频编码标准(AVS)工作组宣布成立,AVS是我国具备自主知识产权的第2代信源编码标准.在这些编码标准中,特别是面向低码率、高质量的标准在实时应用中具有重要意义.视频编码是用尽量少的比特数来最大限度地表述视频内容,从而节约移动通信宽带资源.2012年全球移动数据流量为5 EB.预计到2019年,全球视频流量占据的比重将从2014年的64%上升到80%[1],视频业务的比重在不断提高.庞大的网络数据量对网络带宽提出了巨大的考验.尽管移动通信系统不断通过技术演进与革新来增加带宽,但仍无法从根本上解决带宽不足的问题.
从节省移动通信带宽资源上讲,众多研究者从压缩编码技术上提高编码性能,从而减少视频传输的数据量.文献[2]采用四叉树单元结构、残差四叉树变换结构、像素自适应差值以及自适应熵编码等多项先进编码技术来提高视频数据压缩量.文献[3-4]分别利用自适应滤波与码率控制技术等实现编码效率的最大化.文献[5]综述了基于压缩感知的编码方法,提出感兴趣区域编码.这些技术从视频数据的编码角度减少了信息冗余,节省了带宽资源,但计算量较大.鉴于人眼对视频的视觉冗余,文献 [6-7]提出了可察觉失真编码和非对称立体视频编码算法来提升视频传输的网络适应性和编码效率. 文献 [8-9]把视频编码和视觉冗余相结合,有效提升了网络适应性和编码效率.在面对移动通信压力时,只从编码压缩上减少数据冗余是不够的,需要结合更多的技术来节省带宽资源.本文对影音视频提出了一种节带化处理系统,在传输过程中建立模型库,减少图像传输冗余,节约了移动带宽资源.
1 视频节带化处理系统
视频编码是以图像质量为代价,减少连续帧间和帧内的冗余.一部视频包括很多场景,每个场景又包括不断切换的镜头内容,这样影音视频在时间先后上难免会有重复信息.图1为《生活大爆炸》第1季第7集中几个不同时刻的帧图,每张图的两个方框区域内表示了在时间先后上出现的内容冗余,消除这种间隔帧间的冗余信息,将节约更多的移动宽带通信资源.

图1 视频间隔帧间的内容冗余Fig.1 Content redundancy between video interval frames
从图1可以看出,影音视频间隔帧间存在着一定的冗余信息.为了减少这部分冗余信息,提出了结合存储的影音视频节带化系统,如图2所示.影音视频在传输之前,对其做一个预处理,视频是连续的图像序列,包括多个场景,各个场景又分成不同的镜头,先对视频做镜头检测,把镜头切换的那一帧找出来,然后分析镜头切换帧间的冗余;采用特征匹配方法,匹配越多的帧相似性越大,把先前出现过的帧内容建立模型库,后续出现的帧如果可匹配上模型库里的模型,则匹配上的那部分区域就不用传输.系统模型库主要是根据背景区域建立的.模型库建立后,视频就被分成了匹配区域和未匹配区域,后续传输中收发两端同时更新这个库,传输时传输未匹配区域和匹配区域的标签信息,即未匹配区域的图像编码信息和匹配区域的语义编码信息,这些语义信息包括模型编号以及区域外接点位置等描述匹配区域的信息.在收端根据标签信息找到模型库里的匹配模型,与解码图像拼接成帧图,最终构成可观看的视频.

图2 影音视频节带化系统Fig.2 Content-slimming system for audio video
2 影音视频节带化关键技术
2.1 自适应镜头检测
影音视频可能由几十个场景构成,而每一个场景中又包括很多的镜头切换,镜头检测的目的是为了把影音视频的镜头切换帧找出来.利用自适应阈值法[10]进行镜头检测,把视频序列按每21帧分成一个小组,相邻小组间首尾帧相同,每10个组构成一个单元,阈值处理过程如图3所示.
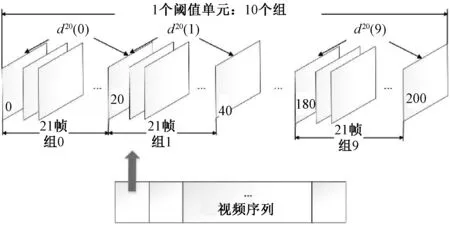
图3 阈值处理过程Fig.3 Threshold processing
如果有镜头转换,则在小组内通过相同的自适应阈值两次二分,将镜头转换范围缩小在5帧内,通过式(1)判定出镜头切换帧.
≥3,
(1)
式中:tm是帧间最大距离值;ts是帧间第二大距离值;C是一个为了保证分母非零的很小的常量.对于切换镜头的检测,该方法效果很好,对于渐变镜头的计算会加入更多的判定条件,计算会更复杂些.图4是镜头检测得到的几个镜头起始帧.

图4 镜头检测得到的镜头起始帧Fig.4 Shot starting frames obtained by lens detection
2.2 特征匹配
特征匹配一方面是为了根据镜头起始帧建立出模型,另一方面是实现模型库与后续图像的匹配,完成图像拆分及重构.图像匹配技术通过对两幅图像的特征、结构、关系、纹理、灰度等对应关系和相似性、一致性进行分析,寻找出相同对象目标.张焕龙等[11]针对传统群智能方法在图像匹配应用中参数较多且调节复杂的问题,将布谷鸟搜索(CS)机制引入到图像匹配过程.1999年Lowe提出了尺度不变特征转换(scale invariant feature transform,SIFT),并于2004年得到完善[12]. SIFT对图像平移、旋转、尺度变换等变形也能很好地检测到特征点[13],同时采用了不同尺度空间,受噪声影响小,又因为基于特征点的匹配实现速度较快,因此在图像匹配识别领域应用广泛.图5是两帧图像的SIFT特征点匹配情况.
2.3 随机采样一致性算法
图5中存在一条斜向右上的错误匹配对,为了剔除这种特征点对,利用随机采样一致性(RANSAC)算法[14]来去除这种错误匹配对.RANSAC算法具有较强的稳定性,可以用一个估计模型来表示这些适合的点,去掉样本群中错误的样本,得到有效样本点, 已被广泛地应用于特征检测、样本以及极限估计中[15].由于图6是运用RANSAC算法去除错误匹配对后得到的更精确的匹配情况,故匹配的点对数减少了.

图5 SIFT特征点匹配Fig.5 SIFT feature point matching

图6 加入RANSAC算法后的SIFT特征点匹配Fig.6 SIFT feature point matching after adding RANSAC algorithm

图7 模型库示例Fig.7 Examples of model library
特征点匹配数目越多,范围越宽,说明图像越相似,相应冗余信息也越多.特征匹配上的帧图像,把先出现的帧所在镜头起始帧与该镜头内最后一帧作差,即用帧差法提取背景,然后把背景分割成与原视频同宽的背景区域,构成模型库.图7为两个模型库示意图.
2.4 点集三角剖分
图像可匹配区域的拆分过程如图8所示.图8(a)是建立的模型与后续帧的SIFT匹配,特征点匹配只能说明图像间有相似区域,但是对这个区域的大小进行确定还是个难点.为了准确表示匹配区域,利用点集三角剖分法[16]来对特征点构成封闭区域,那么封闭区域肯定是可以匹配上的,即图像进行分割时的区域是相应模型的一个子集.三角剖分后形成的区域内图像信息就是不需要传输的,可以根据模型库进行恢复.特征点三角剖分过程如图8(b)所示.图8(c)中的黑色区域是拆分掉的区域,不需要传输,直接可以根据模型进行恢复.

图8 图像可匹配区域的拆分过程Fig.8 Split process of image matching region
3 实验结果分析
在Windows 7平台上,搭建了Matlab实验仿真,对两段视频实验素材进行了节带化系统处理,表1列举了两段视频的实验素材信息.视频1、视频2都是《The Big Bang Theory》里截取的片段,是本文节带化仿真的原始影音视频.

表1 实验素材信息Tab.1 Information of experimental material
3.1 视频恢复效果
影音视频节带化系统仿真中,对视频受关注的前景信息没有进行处理,而只是对具有相似性的背景区域进行了处理,忽略了边缘较少的细节信息,视频恢复效果可接受.图9为原视频与恢复视频同一时刻的截图,其中线框区域内的图像是不传输的区域.对比视频可以看出,恢复的效果还是很好的,但是在细节地方还是会有拼接上的差别,对图9(c)、(d)截取的时刻来说,右下角字母CBS以及HDTV处有明显的色差.所以在收端从模型库里选择模型恢复图像,还需考虑更多关于颜色方面的细节.
3.2 YUV平均值
为了从颜色上来判断恢复视频和原视频是否有很大差异,在颜色空间YUV里比较了两个视频节带化处理前后的YUV平均值.选择YUV空间是因为它是电视系统中一种常用的颜色编码方法.图10为原视频与恢复视频YUV平均值对比曲线图.从图10可以看出,视频1和视频2节带化处理前后的YUV平均值在每帧基本保持不变,说明从模型恢复的区域没有改变整体的颜色,不会在视觉上产生较大的颜色差异.

图9 原视频与恢复视频同一时刻的截图Fig.9 Screenshots at the same time of the original video and the recovery video
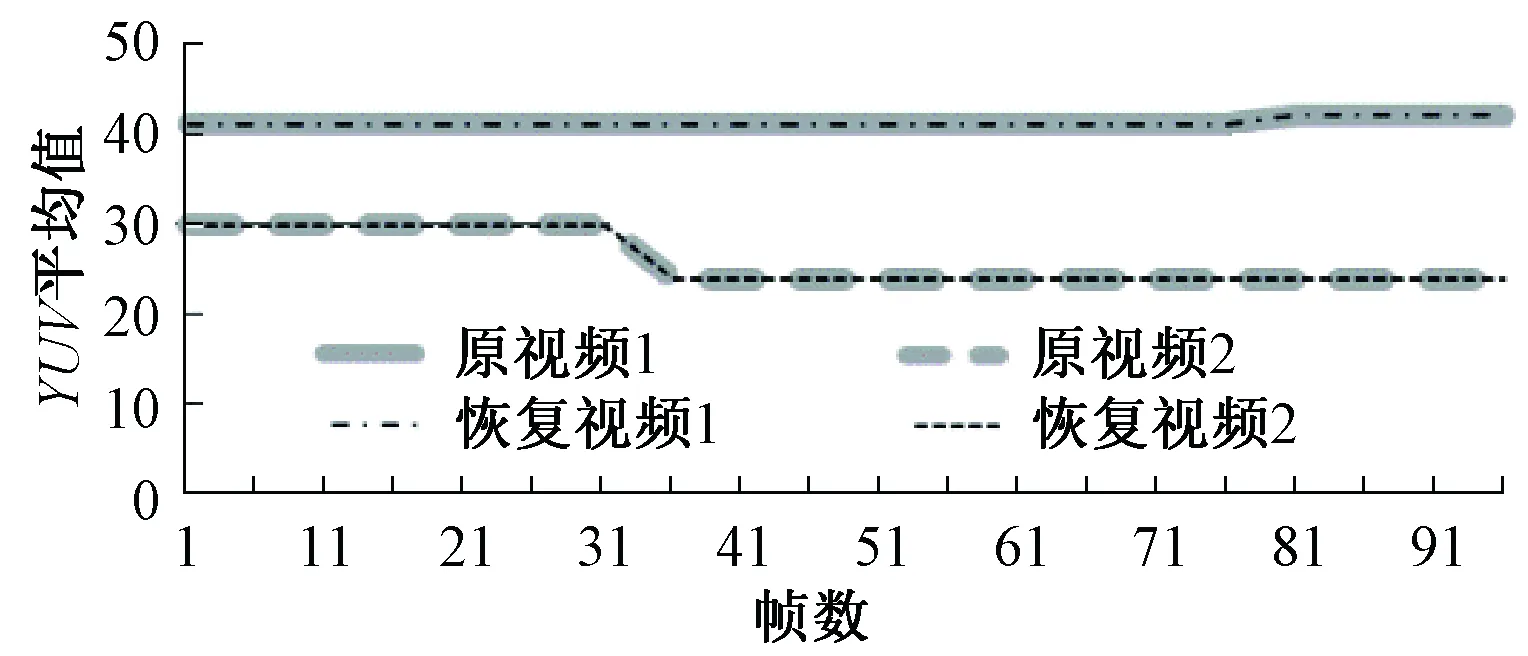
图10 原视频与恢复视频YUV平均值比较Fig.10 Comparison of the YUV average value of the original video and the recovery video
3.3 视频峰值信噪比
为了从图像本质上对视频进行客观评价,对视频1和视频2计算了平均峰值信噪比(PSNR).图11显示了视频1和视频2的原视频与恢复视频的平均峰值信噪比,图中的平均峰值信噪比是每帧图像的YUV三个维度上的均值.由图11可以看出,原视频在图像上已经存在一定压缩,峰值信噪比是以视频解压后为参考进行计算的.对视频1而言,原视频的平均峰值信噪比在40 dB附近波动,在32帧左右波动较大;恢复视频在38 dB附近波动较小,整体上更平稳.对视频2而言,原视频的平均峰值信噪比在45 dB附近波动,整体有一个略微下滑的趋势,恢复视频保持这种趋势,但整体上更平稳.峰值信噪比可以从一方面说明图像质量的损失情况,其值越大说明图像压缩损失越小,图像越清晰,即恢复出的视频效果较好.
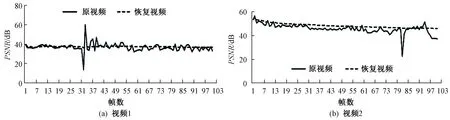
图11 视频1和视频2的原视频与恢复视频的平均峰值信噪比Fig.11 Average PSNR of the original video and the recovery video of video 1 and video 2
3.4 节约量
移动宽带通信中对影音视频节带化处理后,视频的恢复效果在颜色和信噪比上都与原视频相差很小.节带化系统一方面是为了保证视频质量,另一方面也是为了节省带宽资源.本文对原始视频和节带化处理后的视频进行比较,得到视频的节约量.表2列举了视频1、视频2的节带化实验结果,视频原始数据量用M表示,节带化后传输的数据量用N表示,节约率β可以表示为
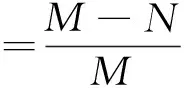
(2)
从表2可以看出,就影音视频而言,节带化处理后传输的视频信息量减少.对于镜头切换间隔帧重复的视频,节带化系统对这种影音视频能达到10%左右的节约量,这个节约量还只是在图像帧基于匹配上的子区域进行的拆分与重构,当然传输的数据还需要增加一些对匹配模型的说明,而这部分信息很小,所以采用视频节带化系统处理可以实现带宽资源的节约.
视频2的节约率比视频1低,一方面是因为视频本身间隔时间内重复信息变少了,单位时间内能实现建模匹配的模型减少;另一方面,匹配过程中,点匹配对一些帧没有达到好的效果,故模型库里模型匹配识别出来的区域变小了,即能拆分的区域小,所以节约率有所下降.对视频而言,虽然本文的建模还不能达到理想模型库全集,匹配的准确性也还不够高,但是从整体上看,这种存储加计算的节带化处理系统可以节省视频传输资源,达到期望的目的.
为了更直观地表示影音视频建模存储节带化系统的节约量,以视频帧的方式把每一帧图像的节约量直观表示出来,把视频分成帧,对节带化处理前后每一帧的大小进行比较,可以得到每一帧的节约量.图12列举了视频1中20帧节带化处理前后对比图.图中所示第1帧是参考帧,之后的19帧是视频在时间上有一定间隔的帧,参考模型的建立是根据第1帧图像确定的,所以第1帧是全信息传输.有了模型之后,后续能与模型匹配的帧只需要传输未匹配信息和关于选定模型的信息,选定模型的信息可用数据量很小的标签表示.忽略掉模型的标签信息,得到影音视频节带化处理前后视频帧的节约量.

表2 节带化实验结果 Tab.2 Experimental results of content-slimming
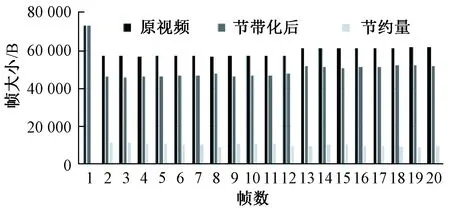
图12 视频1中20帧节带化处理前后比较Fig.12 Comparison of before and after content-slimming processing of 20 frames in video 1
4 结束语
在互联网迅猛发展和普及的今天,视频节带化研究将是一个热点问题,视频业务有强大的市场动力.本文从视频内容上提出一种影音视频节带化处理系统,在传输过程中建立模型库,减少图像传输冗余,节约移动带宽资源.从节带化系统仿真角度搭建了基于影音业务的节带化系统并仿真,从视频恢复效果和节约量来分析仿真结果,指出了这种视频节带化处理的优点.对于影音视频,本文提出的这种计算加存储的影音视频节带化系统,能减少视频传输量,节约移动通信带宽资源.在将来的工作中,对于高效建模、区域分割以及视频图像的重构都需要进一步的研究,以达到影音视频节带化系统的高效性和准确性.
猜你喜欢
中原商报·科教研究(2021年4期)2021-03-03
作文评点报·低幼版(2019年42期)2019-12-30
小学生作文(低年级适用)(2018年10期)2018-10-27
小天使·二年级语数英综合(2018年5期)2018-06-29
Coco薇(2017年6期)2017-06-24
中国科技纵横(2017年1期)2017-03-10
Coco薇(2015年3期)2015-12-24
Coco薇(2015年7期)2015-08-13
会计之友(2014年28期)2014-10-13
计算机辅助工程(2014年2期)2014-07-21
