
基于联合领域自适应卷积神经网络的多工况故障诊断
2019-01-23 09:51韩树发于颖唐堂陈明王亮夏跃利
微型电脑应用 2019年1期
韩树发, 于颖, 唐堂, 陈明, 王亮, 夏跃利
(同济大学 1a. 机械与能源工程学院; 1b. 中德工程学院,上海 201804;2. 云内动力股份有限公司 昆明 201804)
0 引言
如今,基于数据驱动的智能故障诊断算法取得了优异的结果。数据驱动算法从大量历史数据中自主学习故障数据的内在特征,替代传统的手工特征提取。近年来,深度神经网络(DNN)展现出强大的分层特征提取能力。其中卷积神经网络(CNN)是一种特殊的神经网络形式。由于其稀疏连接性,参数共享性及平移不变性,CNN能够提取更为鲁棒的特征,在图像分类领域取得了显著的成果[1]。近两年来,基于CNN的故障诊断方法吸引了大量学者研究[2-5]。这些研究结果显示,相比与其他数据驱动算法,CNN表现出更为优异的效果,具有良好的研究前景。
尽管基于深度学习的故障诊断取得了如此高的理论准确率,目前提出的算法仍存在巨大缺点,难以满足实际应用要求。目前基于深度学习的故障诊断算法都基于一个共同的假设,即训练数据(也称为源数据)与测试数据(也称为目标数据)必须具有相同的概率分布。然而在实际工业应用中设备的工况复杂多变,这一假设很难满足。当训练数据与测试数据分布不同时,深度学习模型的识别准确率往往会显著下降,识别的效果也变得不稳定。这是由于不同工况的故障数据特征分布不同,传统的深度学习算法在训练数据中提取的特征在测试数据中不适用。为此需要引入一种新方法解决源数据与目标数据特征分布差异的问题。
迁移学习(Transfer learning, TL)是一个可以解决跨域问题的机器学习方法。广泛应用与源数据与目标数据来自不同分布的情况。迁移学习从源域中学习知识,并通过这些知识协助目标域的分类问题。微调(Fine-tune)是一个有效的迁移学习方法[6],适用于当源数据与目标数据都有标签的情况。然而,在实际工业的故障诊断中,难以收集到足够的标签目标数据。为了解决目标数据无标签时的分类问题,领域自适应(domain adaptation)技术被大量地研究[7-10]。
相对于传统的数据驱动的故障诊断方法,领域自适应技术在多工况故障诊断方面展现了巨大的潜力。然而,当前该方面的研究仍处于初步阶段。目前应用在故障诊断中的领域自适应算法的共同点是最小化源数据与目标数据在潜在特征空间中特征分布的差异[11-13]。但这些方法只考虑到减小边缘分布的距离。然而文献[14]指出,同时将边缘分布与条件边缘分布相匹配,可以提高模型迁移的鲁棒性。考虑到实际工业应用情况,目标域大多为无标签数据,因此估计目标域的条件边缘分布十分困难。本文在原有的领域自适应的基础上,提出了在无标签目标域内估算条件边缘分布的方法,进而提出了一种同时匹配边缘分布与条件边缘分布的领域自适应方法,即为联合领域自适应算法。将联合领域自适应算法与CNN结合,设计了一种端到端的多工况故障诊断模型,命名为JDACNN(Joint domain adaptation convolutional neural network)。在本文的实验中,与当前的故障诊断深度迁移模型相比,该模型展示出了更强的迁移学习能力。
1 相关研究
(1) CNN特征提取
基本的CNN结构主要由3种类型的分层构成,即卷积层、池化层和全连接层。在卷积层中,卷积核扫描全部输入得到特征图;在池化层中,通过下采样运算来减小输出的大小并保持平移不变性。
目前基于CNN的故障诊断研究主要着眼于提取特征的泛化性[15-17]。文献[15]提出了随机卷积和深度信念网络(SCDBN)的端到端模型,该模型通过随机卷积核从不同类别的轴承数据中提取更为泛化的特征。文献[16]提出了Lifting-Net这一新型CNN架构,在多转速高噪音的工况下对故障数据进行分类。文献[17]提出的CNN模型不依赖目标数据信息,在负载变化的工况下对故障的识别取得较好的效果。
(2) 领域自适应
迁移学习是一种解决在源数据和目标数据来自不同特征分布时分类准确率下降的机器学习方法[18]。 在迁移学习中,领域自适应是一个能够从大量的源域数据学习到知识转移至无标签目标域的有效技术。领域自适应通过减少源域与目标域之间的差异,在目标域无标签的情况下完成了知识的迁移。领域自适应的目的是找到一个源域与目标域共享的特征空间,并在这个特征空间内训练分类器。在故障诊断领域,领域自适应技术被初步地应用。为了解决跨域的特征提取问题,文献[11]将迁移成分分析(TCA)算法应用于故障领域中,旨在减少不同工况下故障信号的特征分布差异。为了学习迁移性的故障数据特征,文献[12]将深度神经网络与领域自适应技术结合,提出了一个新型深度神经网络模型。该模型适用自编码器提取源数据的特征,同时通过减小最大均值差异(MMD)来缩小源域与目标域特征分布的距离。最终,采用支持向量机(SVM)作为分类器来对自适应的特征进行分类。文献[13]提出了一个深度迁移学习模型来提高模型在无标签目标数据上的表现。在该文章中,首先利用源数据预训练一个3层的稀疏自编码器(SAE),然后通过同时最小化源数据的分类损失与MMD对模型进行微调。下面将对领域自适应做出定义:
其中,源域与目标域的定义如式(1)。
(1)
Ds,Dt分别表示源域和目标域。xs,xt分别表示源数据和目标数据。ys表示源数据的标签。ns,nt分别表示源域和目标域的样本数量。
领域自适应技术认为源域和目标域来自不同的边缘分布,即P(xs)≠P(xt)。
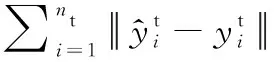
领域自适应的主流方法是通过源域和目标域训练一个特征映射,使得映射后的共享特征子空间中源域和目标域之间的差异最小,从而将目标数据的分类问题转移到源数据上。最大均值差异(MMD)评估源域和目标域分布差异的常用方法[19]。MMD越小说明差异就越小。
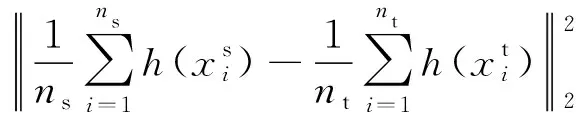
(2)
(3)
其中M表示MMD矩阵,Mij表示MMD矩阵中的元素;H表示转换矩阵,h(·)表示数据特征的一个非线性变换。
2 改进的深度迁移学习方法
在本章,我们提出了一个基于CNN的联合领域自适应模型(JDACNN)。通过最小化源域与目标域之间的边缘分布、条件边缘分布的距离,通过自适应层的映射可以将源域与目标域映射到特征子空间。在这个特征子空间中,源域与目标域的特征分布相同。从而将源域上有标签的分类问题迁移到目标域中,提高模型在目标域中的表现。
与CNN类似,本文提出的JDACNN从源域中通过监督学习的方式提取数据的分层特征。而与CNN不同之处在于,JDACNN将底部神经层参数固定,顶部神经层设置为自适应层。自适应层在源域和目标域上进行训练,通过减少MMD使自适应层上特征的分布差异减少,训练后的自适应层可以将源域与目标域特征映射到共同的特征子空间,从而完成知识的迁移。
(1) CNN结构
模型的结构是基于LeNet-5[20]进行的改进,该模型与LeNet-5不同之处在于:减少了卷积核尺寸以提高计算效率,增加卷积核数量以提高特征抓取能力,增加了一层全连接层,采用dropout技术,使用不同形式的激活函数与损失函数等。该模型包含2个卷积层,2个池化层与3个全连接层。故障信号的输入图尺寸为3232。模型的结构如图1所示。
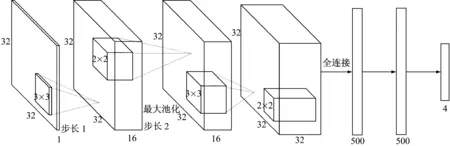
图1 JDACNN结构
第1层,卷积核尺寸为,步长为1,卷积核数量为16;第2层,池化范围为,池化步长为2;第3层卷积核尺寸为,步长为1,卷积核数量为32;第4层池化范围为,步长为2;第5层到第6层为全连接层,节点数量为500。第7层为输出层,节点数为4。
为了防止卷积与池化操作导致的维度损失,零填充(zero-padding)被应用于卷积层与池化层。Drop-out技术与正则被应用在全连接层,以避免模型的过拟合。Drop-out技术[21]以一定概率通过设置神经元参数为0的方式,移除非输出的神经元。因此drop-out等价于训练多个子网络的集合体,是一种计算量小但功能强大的模型正则化技术。在我们的模型中,drop-out的概率被设置为0.5。
线性整流函数(ReLU)函数被选作为本文模型的激活函数,定义如式(4)
ReLU(x)=max(0,x)
(4)
本文中CNN的损失函数被设为交叉熵损失函数与l2正则损失,如式(5)。
(5)
公式5中yi表示独热码(one-hot)标签的第i个元素,ai表示预测的概率,λ代表l2损失的权重,n表示全连接层参数w的数量。
(2) 联合领域自适应技术
为了解决多工况下故障诊断准确率下降的问题,本文提出了改进的领域自适应技术——联合领域自适应技术。为了提高模型的迁移能力,本文提出的联合领域自适应技术,不仅考虑源域和目标域来自不同的边缘分布,同时也考虑到源域和目标域来自不同的条件边缘分布,即:P(xs|ys)≠P(xt|yt)。
尝试在源域和目标域上训练自适应层的参数,通过降低自适应层的MMD来减少特征分布之间的距离,最终通过自适应层将源域与目标域映射到一个共同的特征空间。如图2所示。
1到4层为共享层,共享层从源域中提取泛化的特征。5到6层为全连接层,被设置为自适应层。自适应层的权重将由源数据与目标数据共同训练。本文模型的目的是通过降低MMD,减小自适应层所表示的特征的边缘分布差异与条件边缘分布的差异。
设h(·)为自适应层的特征映射函数。源域与目标域在潜在特征空间下边缘分布的MMD如上述式2所定义。
受到文献[14]的启发, 为了提高模型的迁移能力。本文提出的模型同时考虑边缘分布与条件分布。对于任意类别c,条件边缘分布的MMD估计的是P(hs|y=c)与P(ht|y=c)之间的距离,如式(6)、式(7)。
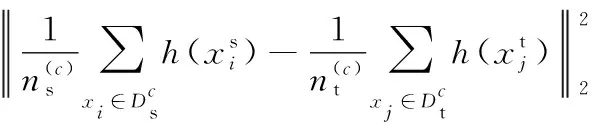
(6)
(7)
为了获得无标签目标数据的条件边缘分布,我们在预训练的网络中预测目标数据,获得伪标签,并通过迭代的方式更新目标数据的伪标签,进而不断提高网络的表现。
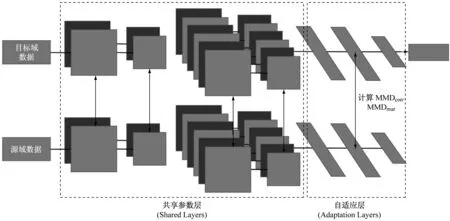
图2 本文模型结构
(3) 最终损失函数
通过最小化边缘分布与条件边缘分布的MMD,经过自适应层的特征映射,源域与目标域的特征分布被匹配起来。从而源域的分类问题被迁移到目标域上。
将公式(2),(5),(6)结合,模型的损失函数定义如式(8)。
L=J+λ1MMDmar+λ2MMDcon
(8)
公式(8)中,λ1,λ2分别控制边缘分布MMD与条件边缘分布MMD的权重。
在训练阶段,只有源域的样本用于最小化分类损失,源域与目标域的样本共同用于最小化MMD。优化算法选为小批量的随机梯度下降法。训练网络的算法如算法1所示。
3 实验与结果分析
为了验证模型的效果,本文采用了西储大学(CWRU)的滚动轴承故障集进行了测试。西储大学故障数据集包含4种工作负载(0HP,1HP,2HP,3HP)。数据标签包括正常(NO),内圈损坏(IF),外圈损坏(OF)与滚子损坏(RF)。该滚动轴承故障集使用加速度传感器采集振动信号,采样频率为12 Hz。本文选择的是加速度传感器安装在电机驱动端采集的数据。

算法1:JDACNN训练输入:源数据,源数据标签,目标数据输出:最优的JDACNN模型1. 用源域数据Xs预训练JDACNN,预训练的损失函数如公式5所示;2. 固定层1到层4的参数;3. 循环: 用最新的JDACNN模型预测目标数据,获得伪标签yt; 将Xs, Xt, ys, yt投入模型中,训练的损失函数为公式(8); 每训练一步,更新参数,直到收敛。
(1) 准备阶段
本文提出的模型是一种端到端的故障诊断模型,采用源数据作为模型的输入。本文中提出了一个将原始信号转换为M×M图片的方法,如图3所示。
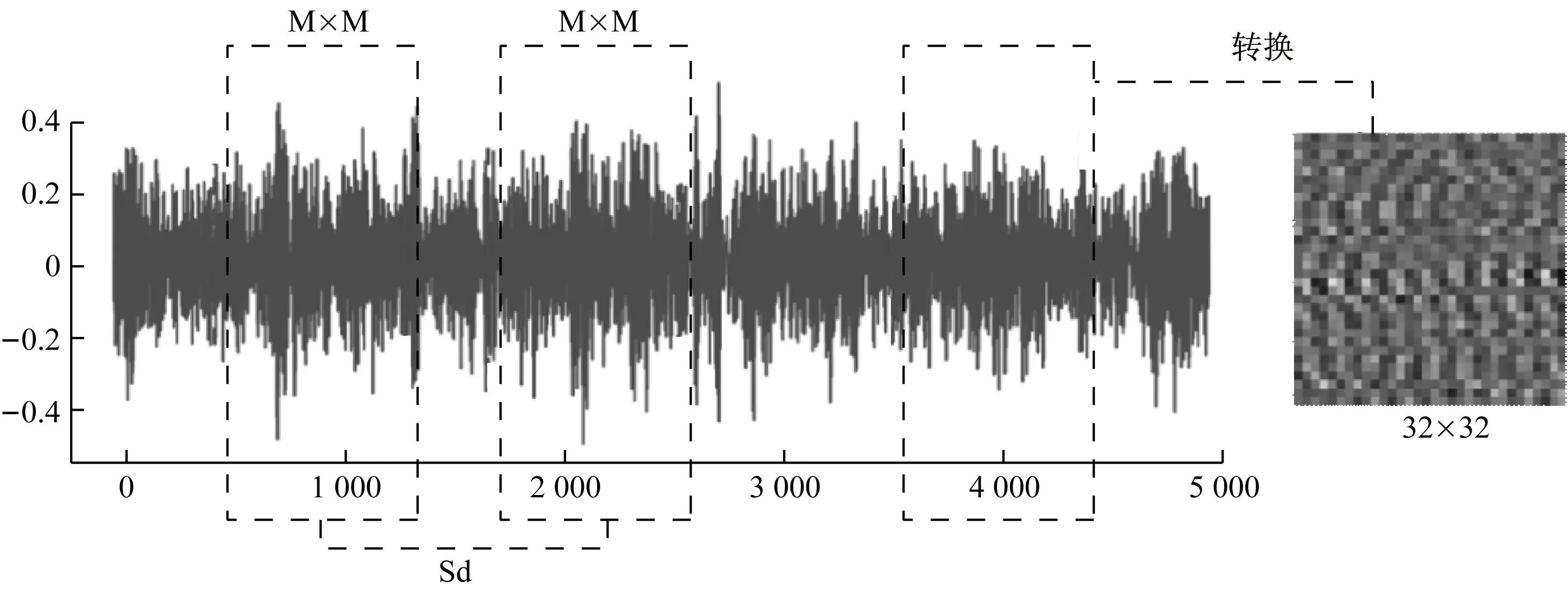
图3 原始信号转换图片
首先沿着原始信号以Sd的步长选择M2个信号节点,如式(9)。
Sd=M-o×M
(9)
公式(9)中,o∈[0,1]为覆盖率。o越大,会产生更多的样本,如式(10)。
P(i,j)=N((i-1)×M+j)
(10)
公式(10)表示了图片像素点与原始数据的对应关系,P(i,j)代表图片中第i行第j列的像素点。N(i)表示所选M2个原始数据节点中的第i个节点。
(2) 参数敏感性
本文中,MMD是对特征分布差异的估计。MMD越大,说明特征分布差异越大,需要设置为自适应层减少特征差异。CNN提取的底层特征为泛化特征,因此表现为MMD很小,无需对MMD很小的网络层进行自适应处理。本文中,依据每层的MMD来选择自适应层,如图4所示。

图4 各层的MMD
图4展示了层4到层6的MMD大小。注意到第5层与第6层的MMD明显大于第4层的MMD。因此层5与层6被设为模型的自适应层。
在网络设计确定后,模型的超参数包括MMD权重λ1,λ2与训练批量大小(Batch size)S。在本段,对不同的超参数的选择进行了测试,以获得模型最佳表现。
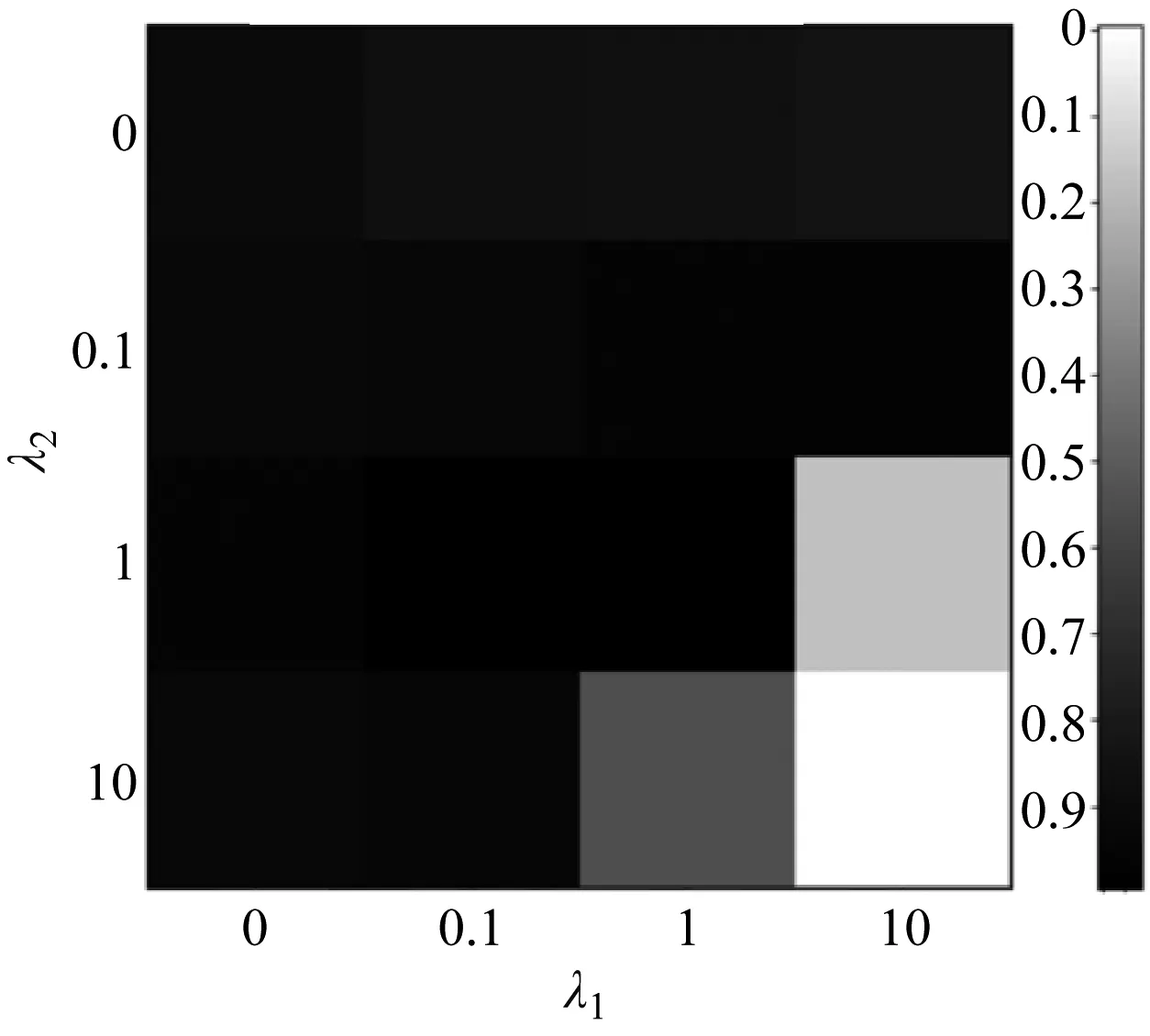
λ1,λ2分别控制了边缘分布MMD与条件边缘分布MMD的权重。权重越大,源域与目标域的特征分布差异越小。但权重过大也会导致分类损失难以收敛,影响分类准确率,如图5所示。
(a) λ1,λ2灰度图
(b) 批量大小
图5(a)展示了λ1,λ2从[0, 0.1, 1, 10]这4个数值取值时模型的表现,图中灰度值代表模型测试的准确率。最终我们选择λ1=1,λ2=1。
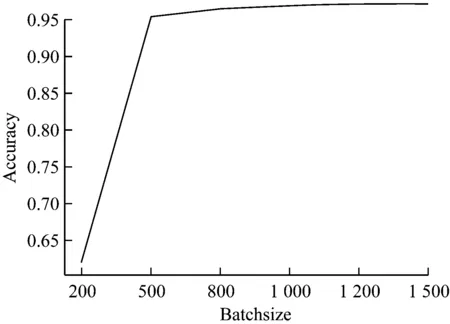
当网络训练时,故障数据的分布在小批量数据中被估计。一个小批量数据需要包含足够多的源域与目标域的样本。批量大小决定了MMD估计的准确程度,因此S需要足够大。然而,过大批量会消耗大额的计算机内存。图5(b)展示了S在[200-1500]取值时模型的表现。最终我们选择S=1 000。
(3) 测试结果
为了展示联合领域自适应深度学习算法的有效性,本文的JDACNN模型与相同结构的CNN做比较,即只在源域数据上训练的CNN模型。JDACNN也与相同结构的传统的深度迁移神经网络做比较,即缺少匹配条件边缘特征分布的领域自适应CNN模型,验证联合领域自适应算法相较于传统的领域自适应算法的优越性。
JDACNN也与其他数据驱动算法比较来证明其良好的研究前景。相比较的算法包括传统的机器学习算法SVM,传统的深度学习算法人工神经网络(ANN)与经典的迁移学习算法TCA[7]、联合分布适配(JDA)。
在实验中,将0HP的数据作为源域数据,1HP到3HP的数据作为目标域数据。这3中情况下的测试分类准确率,如表1所示。
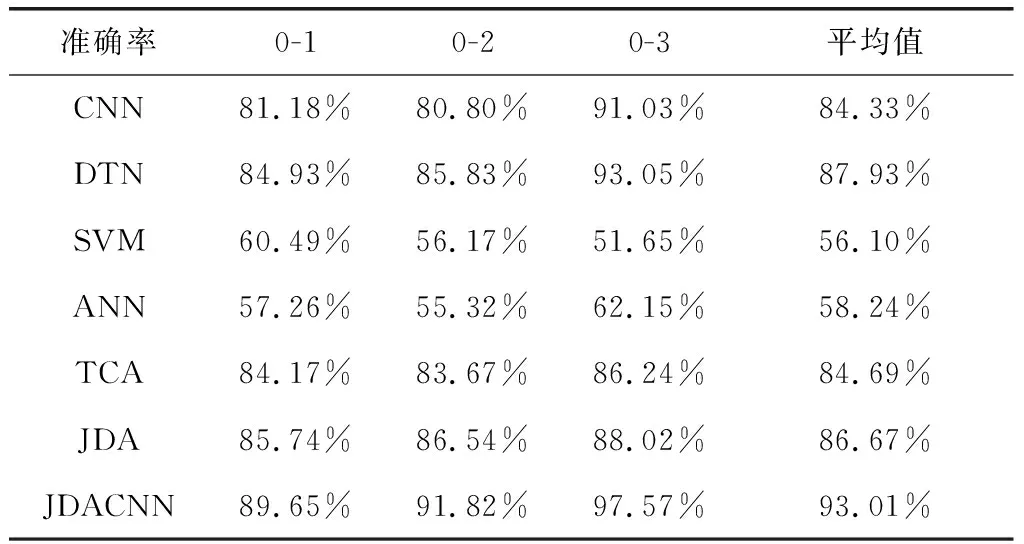
表1 CWRU数据集测试准确率
从检测的结果来看,当3HP数据集是目标域时,JDACNN的识别准确率达到97.57%。JDACNN平均准确率是93.01%。在所有情况下,JDACNN的识别准确率均超过传统的DTN和有着同样结构的CNN。相对于CNN,JDACNN平均提高了8.68%,与传统的DTN相比,JDACNN平均提高了5.08%。这充分证明了JDACNN在领域自适应的有效性。与其他数据驱动算法相比,JDA平均达到了86.67%的准确率,比其他算法要高。然而,仍相对于JDACNN低6.34%,这充分证明了JDACNN在提升迁移能力与特征提取方面的有效性。
4 总结
当训练数据与测试数据来自不同分布时,传统的深度学习算法分类准确率将明显下降。本文提出的JDACNN模型,通过减小数据特征的边缘分布、条件边缘分布的MMD,提高了模型的迁移能力,解决了传统深度学习算法准确率下降的问题。本文的主要贡献如下:
1. 本文提出的模型减少了多工况故障诊断下的准确率损失。模型在西储大学滚动轴承故障数据集中进行测试。结果显示应用提出的联合领域分布算法后,模型的表现有明显的提高。
2. 成功地解决了联合领域分布算法中估计无标签目标数据的条件边缘分布的难题。通过迭代设置伪标签估计条件边缘分布,提高了模型的迁移能力。
3. 为了提高模型的迁移能力,依据MMD选择自适应层,固定共享层参数,保留了模型从源域学习到的底层泛化特征。测试了模型的参数敏感度,以提高模型能力。最终设计了基于CNN的端到端的网络结构。
经过实验测试,联合领域自适应技术表现出更强的迁移能力,展现了在多工况故障诊断方面良好的潜力。本文提出的JDACNN,仍有许多需要改进的地方。
在CNN架构方面,未来的研究方向将致力于提高CNN提取泛化特征的能力。更为泛化的底层特征将有助于联合领域自适应的知识迁移。此外,本文提出的JDACNN,在训练优化时,容易发生收敛失败。这是因为Relu被用作激活函数,,当未正确设置超参数时,一些神经元将被过度激活,导致softmax函数指数值过大,易导致softmax层值的溢出。因此,应进一步研究一种适用的数据预处理方法,以避免神经元过度激活的现象发生。
猜你喜欢
汽车实用技术(2022年16期)2022-08-31
一重技术(2021年5期)2022-01-18
计算机技术与发展(2020年11期)2020-12-04
通信产业报(2016年44期)2017-03-13
青年文学家(2015年29期)2016-05-09
汽车电器(2014年5期)2014-02-28
雕塑(1999年2期)1999-06-28
雕塑(1996年2期)1996-07-13
雕塑(1996年4期)1996-07-12
