
基于Spark的协同过滤算法并行化研究
2019-01-21 00:56陆俊尧李玲娟
计算机技术与发展 2019年1期
陆俊尧,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
推荐系统的目的是为用户进行精准高效的信息推送,在现有的推荐技术中,基于协同过滤的推荐技术是最为成功的。“协同过滤”[1]一词最早是由GlodBerg等在90年代中期开发推荐系统Tapestry[2]时提出的,并且在后来得到了广泛的研究和应用。协同过滤推荐算法主要分为基于用户间相似度的(User-Based)[3-5]协同过滤推荐算法和基于项目间相似度的(Item-Based)[6-9]协同过滤推荐算法。前者基于用户之间的相似度,为目标用户推荐其相近用户感兴趣的项目;后者计算项目之间的相似度,从而为目标用户提供与其感兴趣项目相似度较高的项目。
由于与日益增加的用户数量相比,项目的数量是相对稳定的。所以,基于项目间相似度的协同过滤算法可以有效地减少计算量,提高推荐的时效性。但是面对爆炸式增长的数据量,协同过滤算法的计算效率仍面临着挑战。
作为新一代大数据计算平台,Spark具有基于内存计算的特性,同时也支持对加载到内存中数据的反复查询,非常适合大数据场景下的数据计算,已成为当今最为火热的大数据计算框架之一[10]。
为了提高协同过滤乃至推荐系统的效率,研究了Item-Based协同过滤算法在Spark平台上的并行化方案,并通过实验对该方案的准确性以及时效性进行了验证。
1 Item-Based协同过滤算法原理分析
在基于协同过滤的推荐系统中,最关键的部分就是用户-项目评分矩阵A(m,n),它由数量为m的用户集合U={u1,u2,…,um}对数量为n的项目集合I={i1,i2,…,in}的评分构成,用户u对项目i的评分用Rui表示,推荐则基于评分矩阵按照评分高低进行。而基于协同过滤的推荐算法的任务就是完善和精确这个评分矩阵。
Item-Based协同过滤算法完善用户-项目评分矩阵的过程大致如下:首先计算项目间的相似度,得到相似度矩阵Simn×n;然后在完善用户对未浏览项i的评分时,根据相似度矩阵Simn×n选取K个与i相似度最高的项目来组成最近邻居集KNNi;再基于最近邻居集KNNi利用评分公式进行计算,得到预测评分。
(1)项目间相似度的计算方法。
定义1:对∀i∈I,定义项目-评分矩阵Am×n中对应于i的列为项目i的评分向量,记为Ui。
定义2:对∀u∈U,定义项目-评分矩阵Am×n中第u行对应于用户u的评分向量,记为Iu。
Item-Based协同过滤算法中项目间相似度的计算主要涉及到用户对项目的评分向量,计算方法有标准的余弦相似度、修正的余弦相似度、相关相似度等。其中修正的余弦相似度计算方法如式1所示。
该方法是通过将用户对于项目的评分减去用户评分均值来表现用户对具体项目的评分与大众评分的差异性。
cosadjusted(i,j)=
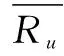
基于相似度计算公式进行项目间相似度计算,生成项目相似度矩阵Simn×n。该矩阵由项目集合I={i1,i2,…,in}两两间的相似度Sim(i,j)组成。
(2)评分计算方法。
预测用户对于未评分或者未浏览项目i的评分的方法包括加权相似度预测方法和Park采用的预测方法等,其中Park采用的预测方法的计算公式如下:
(2)
基于最近邻居集KNNi,利用评分公式得到目标用户对于项目i的评分,进而完善用户-项目评分矩阵,最后为用户推荐评分较高的项目。
2 Spark大数据计算平台
Spark是新一代大数据计算平台的代表,由UC Berkeley的AMPLab实验室提出。相较于传统大数据计算平台Hadoop[11],Spark基于内存进行数据计算,原生语言采用了更为精炼简洁的Scala,不仅可以进行数据的离线计算也可以进行实时计算,不仅可以利用自带的资源调度框架运行(Standalone),还可以利用Hadoop的资源调度框架Yarn、Mesos运行,具有速度快、易用、适用范围广、可扩展等特点。
Spark的核心机制包括弹性分布式数据集RDD和分布式运行架构等。RDD是Spark中最为基本的数据抽象,代表一个由可分区、不可变、内部元素可并行化计算的集合。首先,RDD由分区组成,分区是存取数据、进行计算的基本单位,其数量可由用户按需求自定义。在进行计算时,Spark会根据分区中数据的物理位置进行计算的迁移,从而减少网络中数据的传输,提升运算速度,分区的存在同时还提升了计算过程中的并发度。其次,在Spark中,程序计算过程的本质就是不同RDD之间的转换,计算过程中的中间值与最终结果均被保存于一系列的RDD之中。每个RDD都可以通过持久化操作被存储于内存或者磁盘上,而且RDD间类似于有向无环图(DAG)的转换依赖关系也会被保存起来。当计算过程中发生错误导致RDD中数据丢失时,若该RDD进行过持久化操作,则可以直接进行调用恢复;否则,根据RDD中的依赖关系,从前往后重新进行计算,这在很大程度上提高了Spark的容错性。
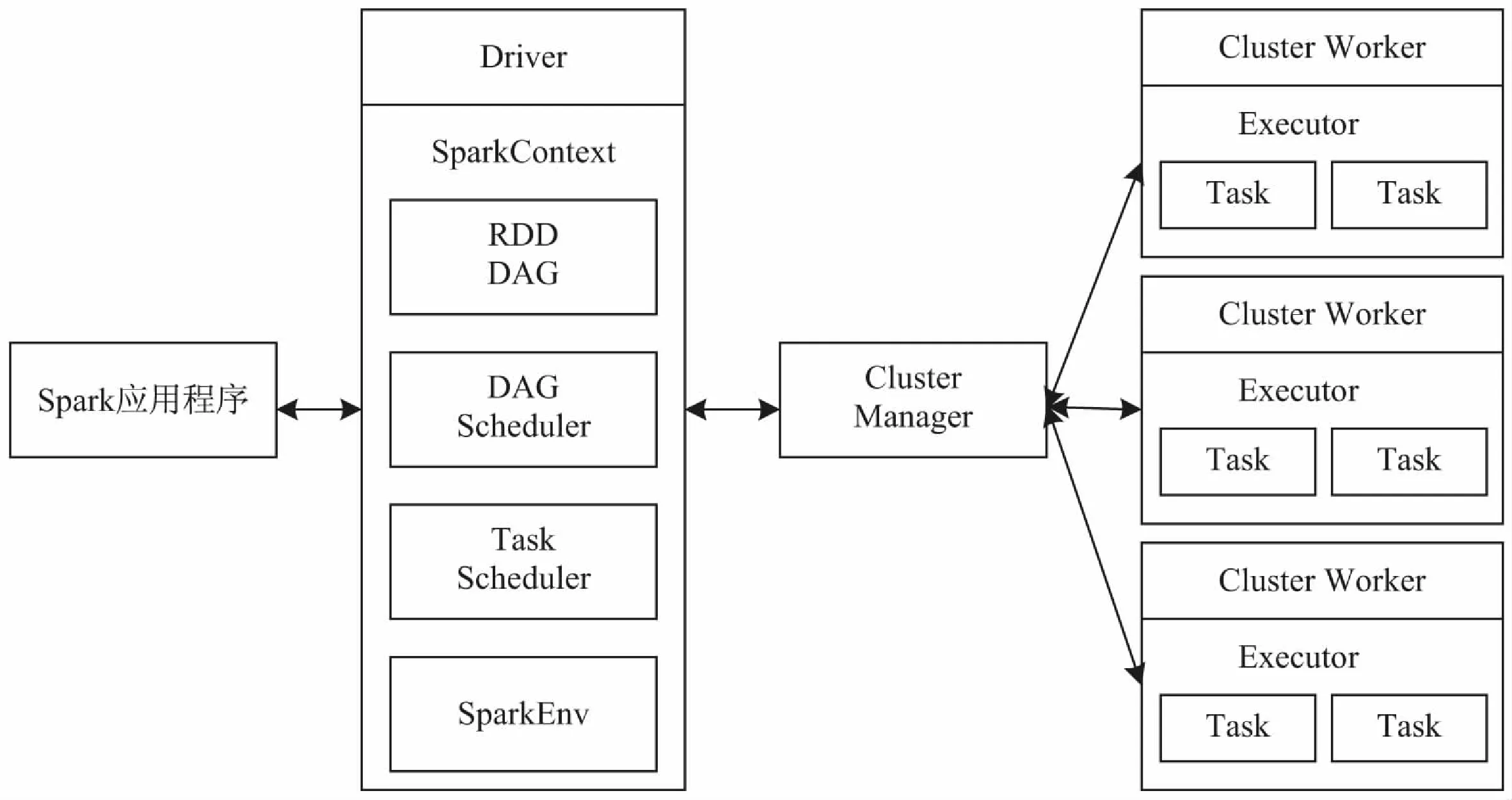
图1 Spark的分布式运行架构
Spark先进的分布式运行架构如图1所示。当用户向Spark集群提交一个计算任务时,驱动程序(Driver)会向资源管理器(Cluster Manager)申请资源。当资源分配完成后,Spark便开始在工作节点(Worker)启动多个任务执行器(Executor),然后等待Driver将规划完成的计算任务集合(即RDD间转换的步骤,类似于一个有向无环图DAG)发送到Worker上。最终计算完成后,Worker将结果发回到Driver。
3 基于Spark的协同过滤算法的并行化方案设计
由于Item-Based协同过滤算法在计算过程中需要对数据进行反复的迭代计算,而Spark的RDD机制正好可以契合这个需求,因此,文中基于RDD转换设计了基于Spark的Item-Based协同过滤算法的并行化方案,同时利用Spark中RDD缓存的特性来对一些计算消耗量极大的中间结果进行存储,采用Spark的广播变量的机制减少计算过程中的网络数据传输[12]。方案的具体过程如下:
(1)Spark的配置与数据源的读取。
Spark的驱动器程序会读取相关的配置文件生成SparkConf对象,然后基于该对象进一步生成SparkContext对象去连接Spark集群。而Spark的计算流程就是通过读取外部数据源或者Spark内存中的数据将其转换为源RDD,然后利用RDD的算子操作进行不同RDD间的转换,最终得到结果RDD。在计算过程中,一个RDD分区就会生成一个计算任务。如果RDD分区数量与Spark集群为程序分配的计算资源不匹配,会导致Spark的并行化计算效率降低。因此,需要对源RDD的分区数量进行合理调整。
(2)多节点并行化执行Item-Based协同的过滤算法。
基于上文的分析,Item-Based协同过滤算法的执行过程被分为两大部分:项目间相似度计算以及评分计算。具体过程如下所述,其中Step1~Step5为项目间相似度计算过程,Step6~Step7为评分计算过程。
Step1:Item-Based协同过滤算法需要涉及到用户对项目评分的历史记录,需要其中的用户编号userId、项目编号itemId、用户对项目的评分rate三个字段。因此,先对原始数据进行预处理生成包含这三个字段的源文件。然后读取源文件,进行字段切分,转换成格式为(userId,itemId,rate)的元组组成的RDDsource。
Step2:采用修正的余弦相似度进行项目间相似度的计算,会涉及到每个用户的评分均值。因此,获取RDDsource中的useId和rate字段,用reduceByKey操作将具有相同userId的元组聚合到一起以后,用avgRateCalculate()这个自定义的平均分计算方法计算用户评分均值并存入RDDavgRate。RDDavgRate由格式为(userId,avgRate)的元组组成。作为分布式计算框架,Spark默认会为多个并行操作中所用到的同一个变量分别进行发送,这会导致计算过程中网络上存在大量的数据传输,影响计算效率。针对该问题,文中采用Spark的广播变量机制来提高计算效率,将有关数据封装成广播变量的数据分发到各个计算节点进行保存且只发送一次,后续计算节点需要用到该数据时直接从本地获取,不依赖网络传输。由于RDDavgRate中的数据在后续计算过程中会被反复查询,因此先用collect操作把RDDavgRate中的数据从各Worker节点汇总到Driver中,用toMap操作转化为Map集合MapavgRate,再将其作为广播变量广播到各Worker节点。
Step3:获取RDDsource中的userId、itemId、rate字段,将itemId与rate用“-”符号连接成“项目-评分”字段。再利用reduceByKey操作将具有相同userId的元组聚合到一起,构成存储用户历史评分信息的RDDhistRate。RDD由格式为(userId,itemId1-rate1,itemId2-rate2,…,itemIdN-rateN)的元组构成,N为编号为userId的用户评论过的项目数量。由于后续的评分计算过程中同样还涉及到对用户历史评分的查询,因此利用toMap操作转化为MaphistRate后,再将其封装为广播变量,分发到各个Worker节点。
Step4:基于RDDhistRate,对于每个userId,将其对应的由“itemId-rate”字段组成的集合进行两两间类似笛卡尔积的合并。先将格式为(userId,itemId1-rate1,itemId2-rate2,…,itemIdN-rateN)的元组利用map操作变成由格式为(itemIdi-itemIdj,ratei-ratej),i,j∈[1,N]的元组组成的List集合。接着利用flatMap操作将List集合中元素取出,再用reduceByKey操作进行聚合,最终得到被用户同时评论过的两个项目的评分汇总,存放于RDDrateSum之中。RDDrateSum由格式为(itemIdiitemIdj,ratei-ratej),i,j∈[1,N]的元组组成。
Step5:以RDDrateSum和MapavgRate为参数,利用自定义的函数similarityCalculate()进行评分计算,最终得到包含所有项目之间相似度的结果RDDsimilarity。该RDD由格式为(itemIdiitemIdj,Sim(i,j)),i,j∈[1,N]的元组组成,其中M为项目的总数量。由于相似度的计算消耗大量资源,故采取Spark中RDD的缓存机制将RDDsimilarity缓存起来,避免后续计算中因数据丢失而产生的重复计算。由于后续计算过程中也要对RDDsimilarity中的数据反复查询,因此也将RDDsimilarity封装成广播变量发送到每一个Worker节点。
Step6:对目标项目i进行预测评分的计算。基于RDDsimilarity,利用filter操作,将RDDsimilarity中key值包含项目i的元组过滤出来,然后将其转化为List集合,对List集合按照相似度值进行从大到小的排序,最后获取排序后的List的前K个值,组成项目i的最近邻居集合KNNi,KNNi也是一个List集合。
Step7:以KNNi以及MaphistRate为输入参数,利用自定义函数rateCalculate()进行预测评分的计算。该函数使用Park采用的预测方法作为计算公式进行评分计算,最终获得用户u对未评分的项目i的预测评分Rui。
以上过程中涉及到的RDD转换流程如图2所示。
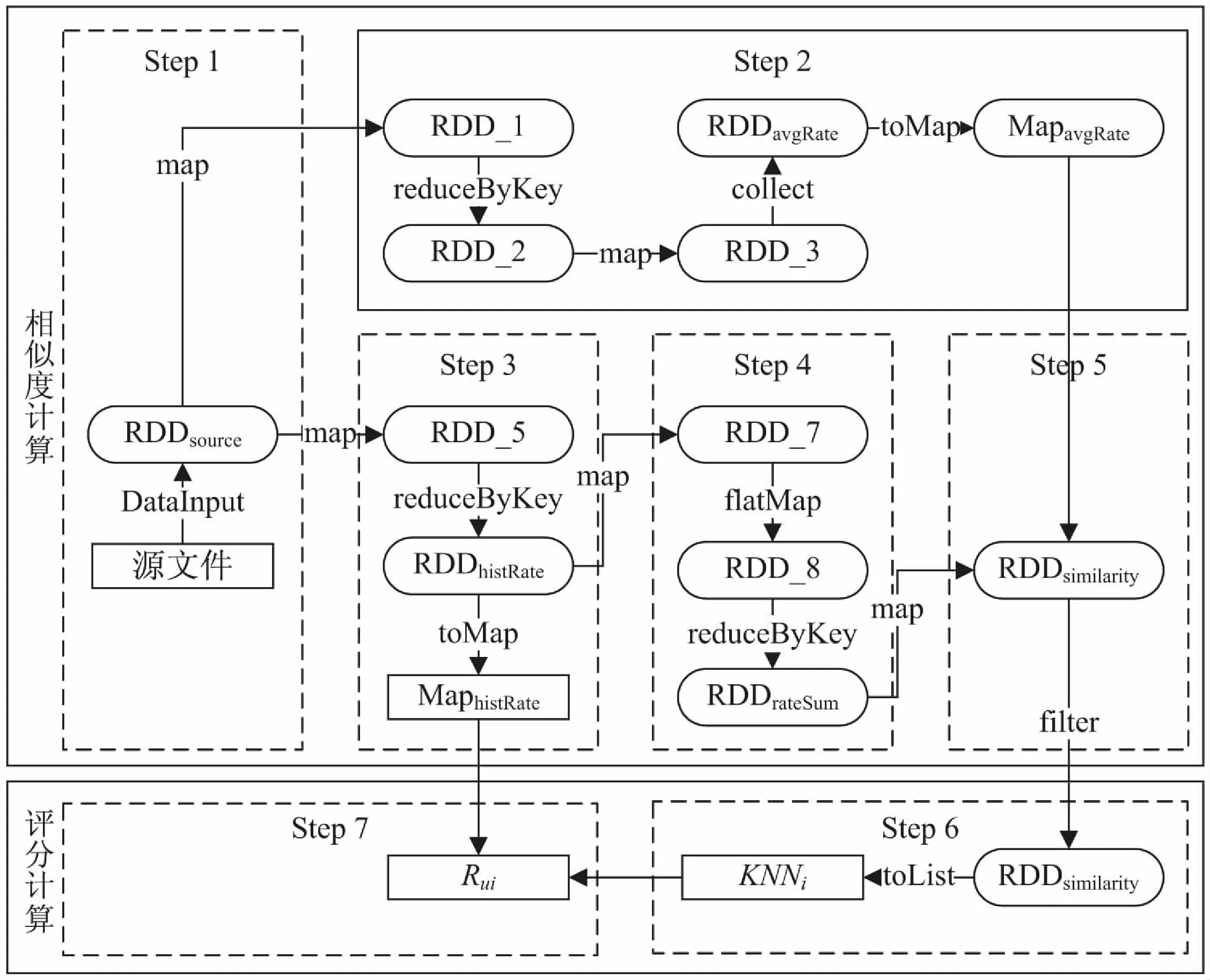
图2 RDD的转换流程
4 实验与结果分析
为了测试和验证基于Spark的Item-Based协同过滤算法的准确性与时间效率,采用MovieLens数据集对基于Spark的并行Item-Based协同过滤算法进行性能测试。首先利用不同比例的测试集和训练集对该算法的准确性进行测试。然后,分别在单机和Spark集群上运行相同规模的数据集,进行算法时效性的对比实验。用Scala语言进行算法实现。
(1)实验环境和数据。
实验配置的Spark环境包含了三个节点,一台驱动节点Master,两台执行节点Worker。每个节点的CPU版本信息为Intel CORE i5-4210H,每个CPU都拥有两个处理单元,硬盘的读写速度为600.00 MB/s,Master节点配有6 G内存,其余Worker节点为4 G。Spark版本为1.6.1;Spark运行的操作系统为CentOS 6.5;Java版本为JDK1.7.0_13;Scala版本为2.10.4。
实验使用了GroupLens Research提供的MovieLens数据集[13],该数据集提供了三种大小不同的数据集,分别为100 k,1 M和10 M。实验采用了大小为100 k的数据集,其中包含943位用户对1 682部电影共计10万条评分记录。记录中包含user id、item id、rating、timestamp四个字段,分别表示用户编号、电影编号、电影评分、评分时间戳。
(2)评分预测准确性测试。
衡量推荐系统推荐准确度[14]的最重要指标就是其评分预测准确性,通常采用均方根误差(RMSE)和平均绝对误差(MAE)来计算,两者可反映出真实值和预测值之差,两者的值越小,说明评分预测的准确性就越高。
实验采用不同比例的训练集和测试集,利用MAE值进行准确度计算。结果如表1所示。

表1 不同的训练集和测试集比例下的MAE值
可以看出,运行在Spark集群上的Item-Based协同过滤算法的MAE值较小,而且MAE值随着训练集比例的提高而降低,即历史数据越丰富则推荐准确度也越高,这体现出了大数据计算框架的重要性,因为它可以处理更多的历史数据,从而带来更高的精确度。
(3)算法执行时间测试。
分别在单机和Spark集群上针对算法运行时间做了测试实验。训练集和测试集比例为9∶1,数据集样本数量逐渐递增。实验结果如图3所示。
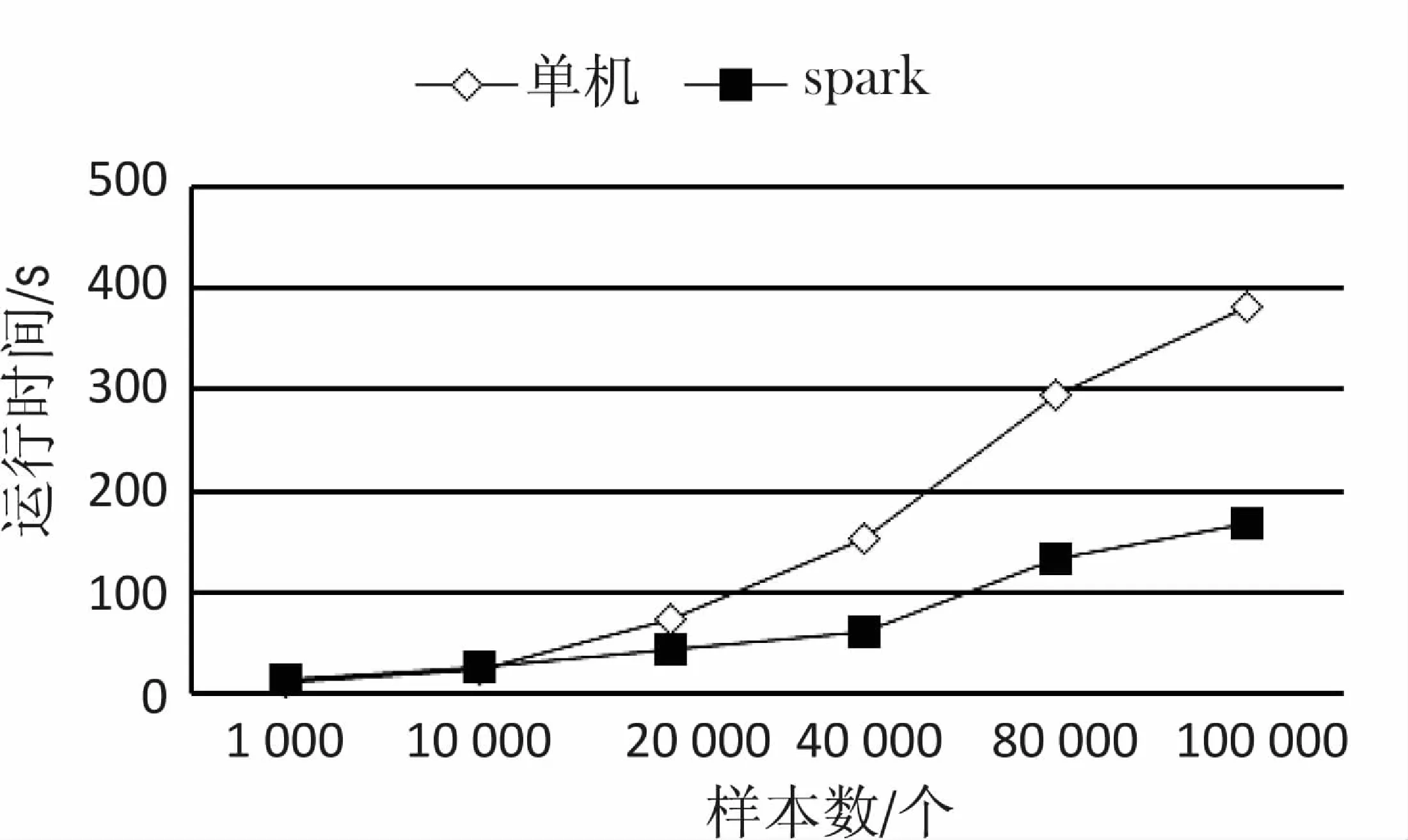
图3 基于单机和Spark集群的运行时间
由实验结果可知,在数据量较小时,由于Spark的启动需要消耗大量资源以及时间,因而无法体现并行化算法在时间效率方面的优势,但随着数据量的增加,其时间效率明显提升。
5 结束语
设计了一种Item-Based协同过滤算法在Spark集群中的并行化方案,并通过基于MovieLens数据集的实验结果证明,在应对大规模数据处理时,基于Spark的并行化Item-Based协同过滤算法,不仅可以保证评分的准确性,而且算法执行速度更快,可以提高推荐系统的时效性。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
计算机应用与软件(2021年10期)2021-10-15
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
汽车观察(2019年2期)2019-03-15
读与写·教育教学版(2017年10期)2017-11-10
民生周刊(2017年19期)2017-10-25
南都周刊(2015年4期)2015-09-10
