
基于改进样本熵的金融时间序列复杂性研究
2019-01-21 00:56:42于文静徐凌宇
计算机技术与发展 2019年1期
于文静,余 洁,徐凌宇
(上海大学 计算机工程与科学学院,上海 200444)
0 引 言
股票时间序列是非线性非平稳的时间序列,由于其随机因素多,波动变化剧烈等特点备受人们的关注[1]。研究股票时间序列的复杂性可以更好地帮助人们了解金融市场的运行机制,并防范风险。样本熵(sample entropy,SampEn)[2]是一种很流行的度量时间序列的复杂性方法,由Richman和Moorman于2000年提出,是对近似熵(approximate entropy,ApEn)[3]的一种改进。在过去的几十年里,样本熵被成功应用在降雨时间序列、脑电信号、振动信号[4-6]等方面。
然而,在区分健康信号和患病信号时,以及衡量替代数据和真实数据之间的复杂度大小时,样本熵得到的结果和人们认为的复杂度是截然相反的。Costa[7]认为产生这个问题的原因可能是没有考虑生理信号的多重尺度,因此提出了多尺度熵。比较两条时间序列的复杂度时,需要比较两个序列在各个尺度上的样本熵大小,最后综合给出两条序列的复杂度大小。随后,提出了多种改进的多尺度样本熵[8-11]并广泛应用于各领域。但是,多尺度的过程实际上破坏了原有序列的结构,得到的多个结果在比较复杂度时难免会产生误解。
为了解决样本熵的熵值大小和序列的真实复杂度无关的问题,考虑从样本熵度量时间序列复杂性的原理入手。通过分析发现循环序列的样本熵都是0,也就是说对于规则性序列,样本熵的值是最小的。但是对于不同循环序列的循环结构的构成也就是循环体结构中向量组成的复杂度都是不一样的,样本熵却给这些规则的但循环体结构完全不同的序列以最小的且相同的复杂度。另外,样本熵在计算时间序列中向量的相似性时,没有考虑这些向量在时间序列中的时间属性,所以只要两个向量的模式是相似的,则两个向量就是相似的,没有考虑这两个向量在时间序列中的分布情况。因此,从这两个角度出发,文中在样本熵的基础上提出了二维熵。
1 二维熵方法
二维熵参数用N,m,r表示。其中,N为序列长度,m为维数,即重构向量时向量的长度,r为相似容限。具体算法如下:
设原始时间序列u(i)为由N个点构成的序列,根据预先设定的嵌入维数m将原始时间序列重构成一组m维向量,每个向量代表从第i个点开始连续的m个u的值:

2,…,N-m+1
(1)

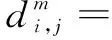
(2)
(3)
(4)
然后计算每个向量和其他向量相似可能性的平均概率的和,并除以序列中m维向量的总数,得到m维向量的自相似的概率,记为Bm(r)。
(5)
将维数m增加1,重复上述步骤,得到Bm+1(r)。
二维熵在计算时间序列的复杂度时不仅考虑新信息的产生率还考虑向量自相似程度,故二维熵的计算模型如下:
(6)
(7)
根据Pincus[12]建议,二维熵与互二维熵在计算时m设为2,r为0.2×SD,SD为时间序列的标准差。
2 二维熵的有效性验证
这一节用Logistic映射对模型进行验证。Logistic映射是一个著名的例子[13-14],在数学上表示为:
xi+1=axi(1-xi)
(8)
其中,xi是0与1之间的一个实数,控制参数a是一个正的参数。
在模拟实验过程中,选取参数a∈[3.5, 4.0],序列的长度设置为1 000,以生成不同的序列。当a=3.5时,产生周期性序列,当a∈[3.6, 4.0]时,序列的复杂度随着a值的增大而增大。
图1是a∈[3.5, 4.0]时产生的不同序列在r从0.1以0.01的步长增大到0.25时的二维熵曲线图。从图中可以看出,二维熵熵值的大小和参数a所代表的序列的复杂度是一致的,同时在r变化时,二维熵能够保持一致性。
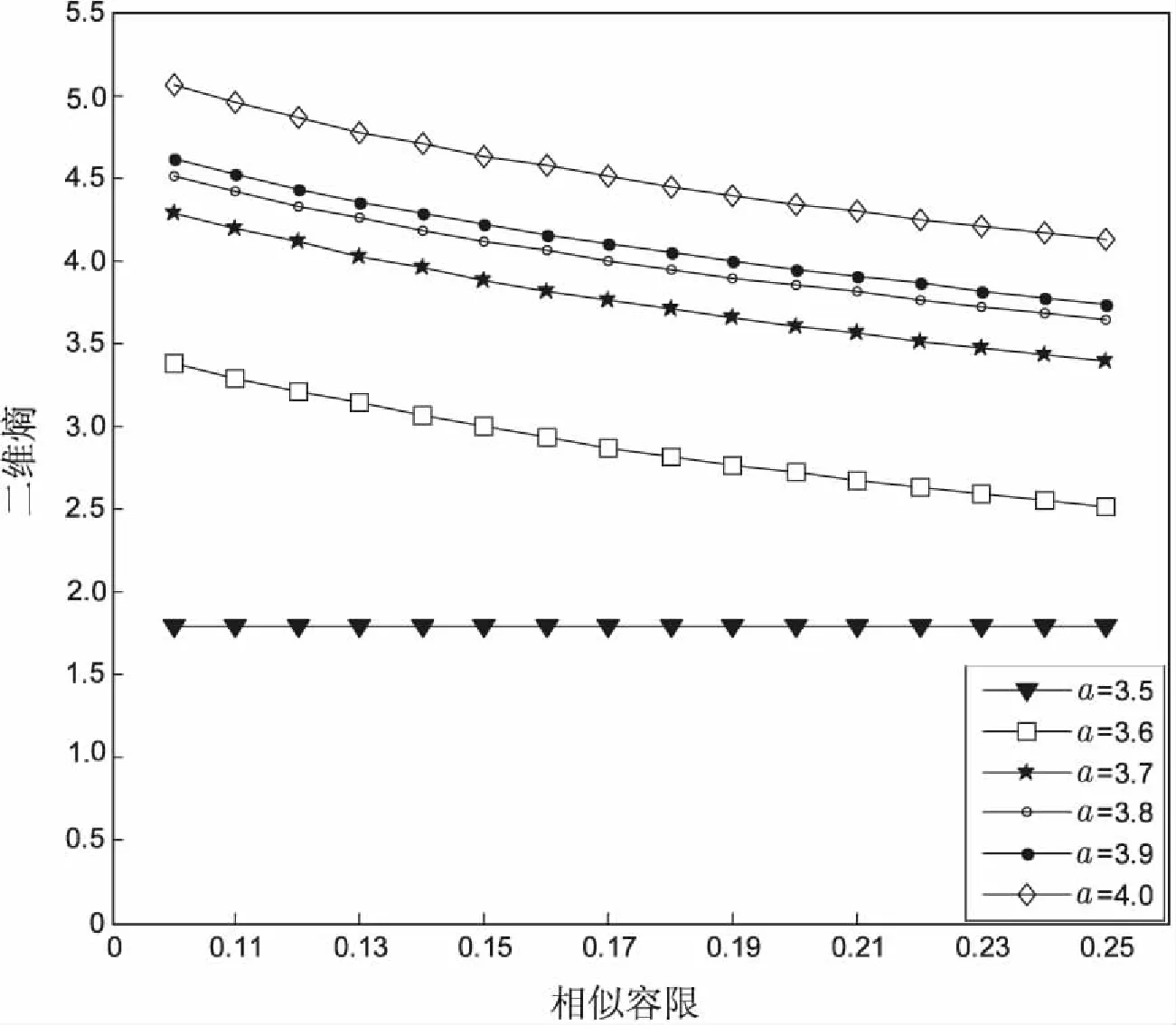
图1 不同复杂度的Logistic序列的熵值曲线
(a)二维熵
(b)样本熵
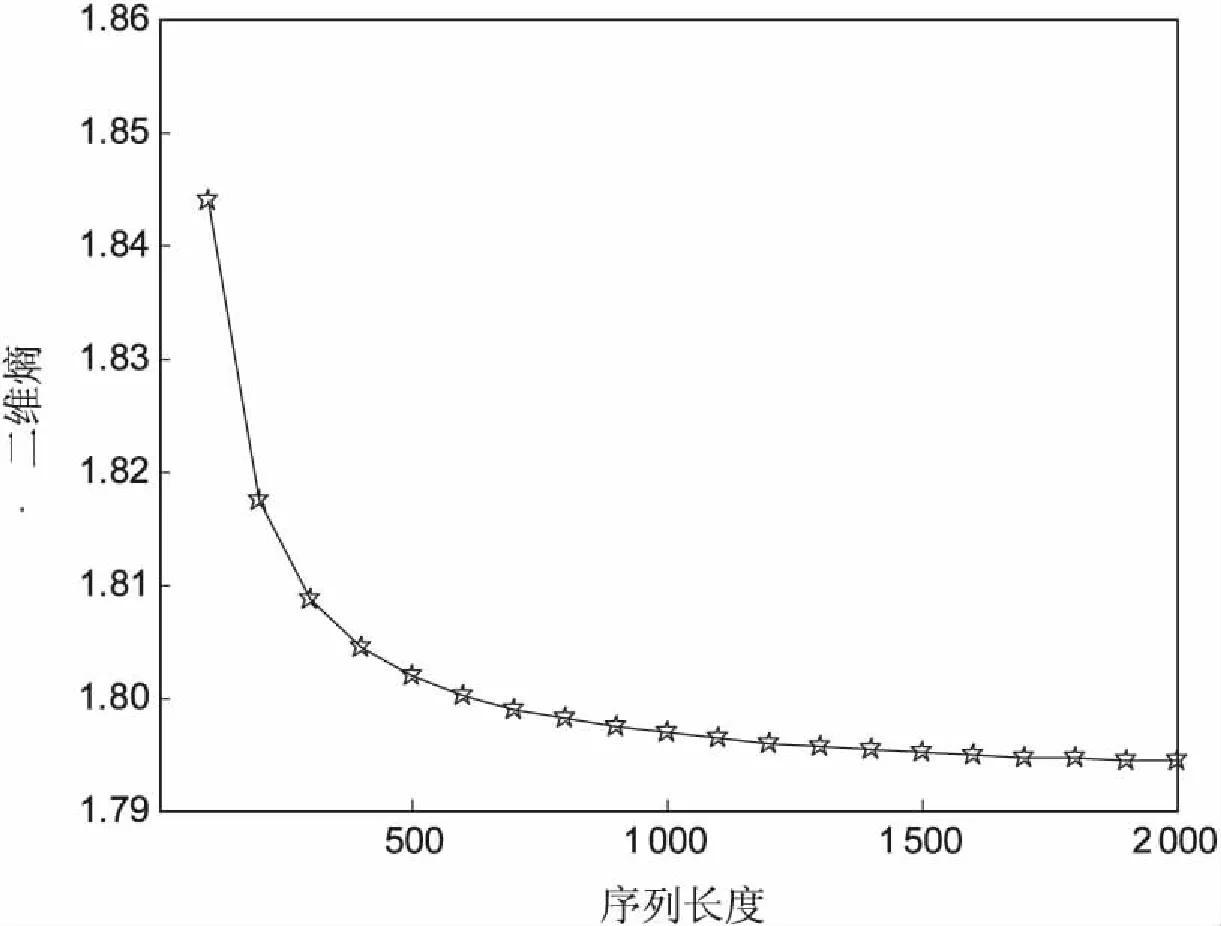
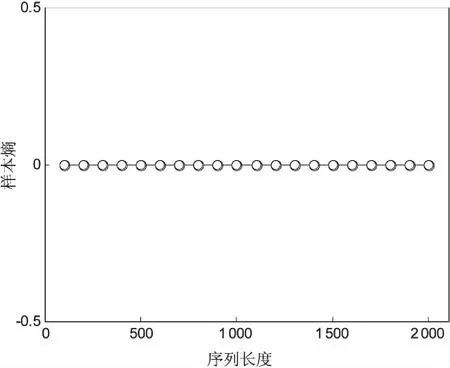
图2是当a=3.5时,产生长度从100以步长100增长到2 000时的Logistic序列的样本熵和二维熵曲线。当a=3.5时,Logistic产生的序列具有周期性。从图2(a)可以看出,随着序列长度的增加,二维熵的值先增加后保持平稳。而图2(b)样本熵的值在不同长度下,熵值都为0。
这是因为样本熵在度量时间序列的复杂度时,对于周期性或规则性序列,样本熵的值就会为0,无法根据不同周期序列的结构的复杂性判断序列的复杂性。而二维熵则会根据不同周期序列的结构复杂性给出不同的二维熵值大小。当a=3.5时产生的不同长度的Logistic序列之间的差异只是长度,循环结构体是一样的。只是当时间长度小时,得到的结果会存在一点误差,当序列的长度足够长时,误差造成的影响就可以忽略不计。
这两个实验证实了二维熵在衡量时间序列复杂度上的有效性,并且它优于样本熵,且得到的结果和真实复杂性是一致的。
3 实证研究
接下来用二维熵以及互二维熵研究股票市场在金融危机前后时间内的复杂性和不同市场之间的异步性。利用美国道琼斯工业平均指数(DJI)、香港恒生指数(HSI)、上证综合指数(SCI)和深圳成分指数(SZCI)[15]从2006年1月1日到2010年12月31日的收盘价时间序列进行实证研究。这些数据来自雅虎财经:https://hk.finance.yahoo.com/。这四条股指在这段时间的收盘价序列如图3所示。可以看出,金融危机发生后一段时间(400~800天),这四条股指的收盘价的价格都大幅下降。
首先研究这4条股指在不同时间段的复杂性大小,每两百天一段,计算这四只股指在不同段的二维熵的大小曲线,如图4所示。第一段0~200可以看成是金融危机前期正常股价波动期;第二段201~400为金融危机前股价上升剧烈期;第三段400~600为金融危机发生期;第四段600~800为市场调节期;第五段800~1 200为市场正常期。
从图4可以看出,美国道琼斯工业平均指数和香港恒生指数两个股指以及上证综合指数和深圳成分指数两个股指之间在不同时间段的复杂度趋势是一致的。同时可以看出,当收盘价价格在一开始波动上升期,也就是在第二段时间内时,这四只股指的二维熵的大小都是相对其他时间来说比较小的。金融危机后第三段时间,这段时期是这四只股指价格波动最大的时期,这四只股指的二维熵的值也是相对比较大的。第四段时期,美股道琼斯工业平均指数和香港恒生指数的二维熵值降到最小值,而中国的上证综合指数和深圳成分指数的二维熵增加到一个相对高的值,因为中国政府对市场具有一定的调控作用,导致复杂度相对来说依然很大。随后市场开始恢复,直到第六段时间,各个股指的二维熵复杂性相对大小恢复到第一段时间段的大小,也就意味着市场趋于正常。
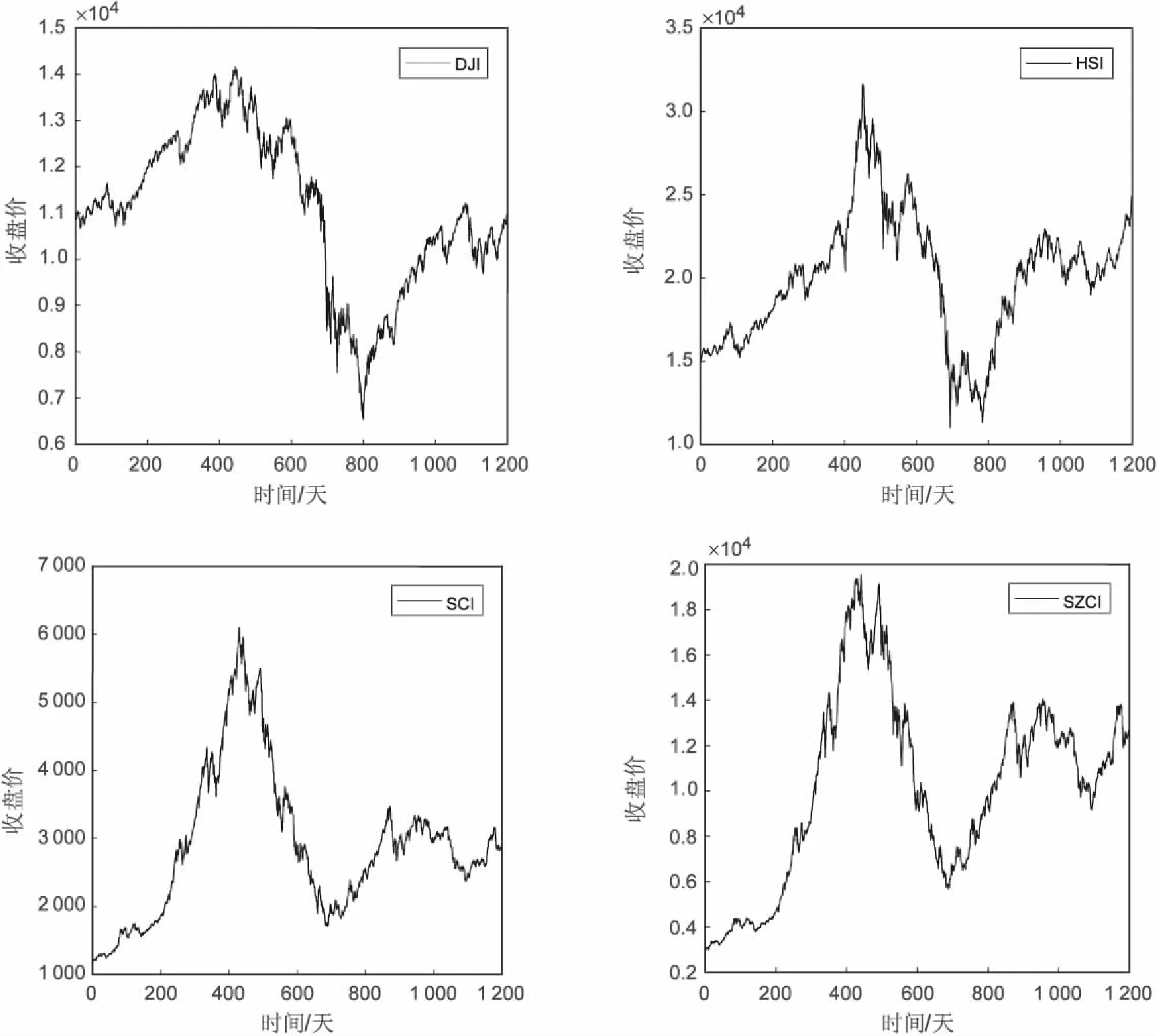
图3 DJI、HIS、SCI和SZCI从2006到2010年的日收盘序列
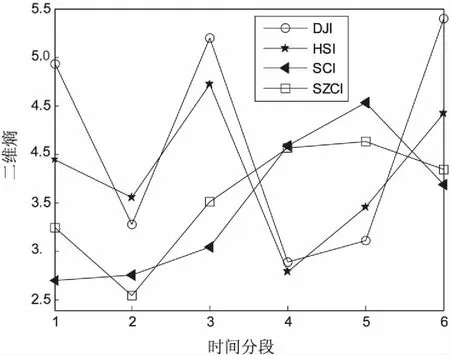
图4 DJI、HIS、SCI、SZCI在不同时间段的二维熵曲线
最后用互二维熵来衡量这四只股指的异步性,如图5所示。可以看出,每只股指和自身的互二维熵值是最小的,也就是说股指本身的价格趋势和自己的异步性是最小的。除此之外DJI和HSI的异步性,HSI和SZCI的异步性以及SCI和SZCI之间的异步性也是相对来说比较小的。总的来说,中国市场的两只股指的异步性相对于其他股指的异步性要小,美股的异步性和港股的异步性要比中国市场的股指的异步性小,这是由于不同的市场环境造就的结果。
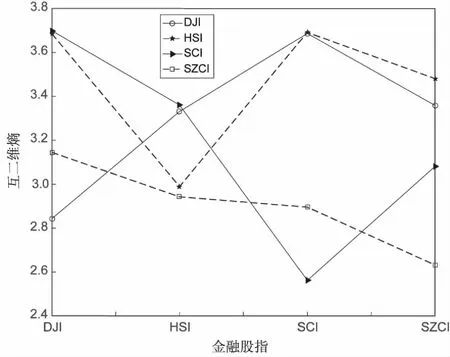
图5 DJI、HIS、SCI、SZCI的互二维熵曲线
4 结束语
在样本熵的基础上提出了一种新的度量时间序列复杂度的方法,二维熵。该方法在度量时间序列复杂度时考虑了序列结构的复杂性,所以对于循环规则序列二维熵能够根据它们循环体结构的复杂性判断序列的复杂性,并在二维熵的基础上提出了互二维熵来度量时间序列的异步性。接着用Logistic映射产生的不同复杂度的序列来证明二维熵的有效性。最后用这两种熵测量的方法来度量DJI、HIS、SCI、SZCI四只股指在金融危机发生前后股指的复杂性以及这几个股指之间的关系。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
中华养生保健(2020年2期)2020-11-16 00:49:16
科学(2020年1期)2020-08-24 08:07:56
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
证券市场红周刊(2018年40期)2018-05-14 19:45:16
证券市场红周刊(2018年41期)2018-05-14 18:45:56
证券市场红周刊(2018年5期)2018-05-14 14:45:46
证券市场红周刊(2018年27期)2018-05-14 08:48:58
中国卫生(2016年9期)2016-11-12 13:27:58
