
基于声学特征的母语非汉语者声调研究
2019-01-11 00:31古力努尔艾尔肯艾斯卡尔艾木都拉
声学技术 2018年6期
古力努尔·艾尔肯,艾斯卡尔·艾木都拉
基于声学特征的母语非汉语者声调研究
古力努尔·艾尔肯,艾斯卡尔·艾木都拉
(新疆大学信息科学与工程学院,新疆乌鲁木齐 830046)
从提高满足少数民族普通话高自然度语音合成与高精度语音识别的实际应用需求出发,首次从实验语音学的角度对初级、中级和高级阶段的50名维吾尔族汉语学习者与10名母语为汉语普通话的说话人声调的一阶差分与时长以及相似度进行对比,并对其声调的一阶差分模式、声调时长等韵律参数进行了实验分析,得出维吾尔族学生对汉语声调的偏误情况以及与中国少数民族汉语水平等级考试(Master of Human Kinetics, MHK)成绩的关系。通过实验结果可以发现,三组维吾尔族人学习普通话的声调都有困难。两种语言的音系,语调和重音等特性影响了第二语言中的声调特性。归纳了维吾尔族学习者声调的基本声学特征,总结出了一些重要的规则和结论;为解决给汉语语音处理带来的困难,尤其是少数民族汉语的语音合成和语音识别方面的声调问题,提供了重要的参考依据。
一阶差分;声调偏误;对比分析;维吾尔族学习者;时长
0 引言
汉语普通话是汉藏语系的一个分支,目前是我国最主要的通用语言[1],有非常多的学者在从事这方面的研究,也取得了很多非常有价值的研究成果[2]。例如,从汉语的特点这一角度进行深入研究,还有一些学者通过实验研究母语非汉语的外国人学习汉语的情况[3-5]。但是在众多研究角度中,针对我国国内少数民族学习汉语情况的研究比较少,从声调角度入手开展定量研究的成果更是非常少见。这不仅不利于对少数民族展开有针对性的教学,还不利于少数民族在学习汉语过程中对语音的处理,特别是语音合成和语音识别两个方面。
同时汉语作为声调语言的一种,音调能够区分出汉语的语音结构,掌握声调是学习汉语过程中一个很重要的部分[6-7]。维吾尔语属于阿尔泰语系,是没有声调的语言。维吾尔族人在学习汉语的时候,声调的学习对他们来说是一种全新的语言因素,所以接受起来有一定的困难,在短时间内很难区分清晰。此外,维吾尔族人使用的维吾尔语与汉语的差别还有,作为表音文字,维吾尔族人看到文字就能很准确地读出来,但是汉语不同,作为表意文字,从字面上无法判断发音,更无法得知声调。所以,维吾尔族人单纯重视练习汉语的发音,没有将音调放在重要的位置。这就导致了很多维吾尔族人在中国少数民族汉语水平等级考试(Master of Human Kinetics, MHK)中能够取得很高的成绩,但是口语方面由于不能很好地掌握音调,在汉族人听来,还是有些“洋腔洋调”[8]。对于母语为非声调语言的维吾尔族学生来说,掌握汉语声调对他们来说是有困难的。这与平日的教学以及语言环境都有关系,以至于维吾尔族学生的汉语口语并不标准,主要的原因是汉语的语调掌握的不扎实。汉语的语调确实比较复杂,想要学好汉语,必须要正确掌握语调以及其发音的方法。
鉴于此,本文将运用实验语音学的方法,从汉语作为第二语言的声调习得实验出发,进一步了解新疆维吾尔自治区的学生学习普通话以及其掌握声调的现实情况,通过定量实验的研究方法,对维吾尔族大学生在学习普通话的过程中语调掌握的状况进行研究,也为少数民族普通话学习中自然度语音合成与高精度语音识别技术的发展提供一定的参考。
1 实验设计
1.1 被试情况
本实验中总共有60名被试,其中有50名维吾尔族人(25男,25女),他们都是新疆大学学生,年龄在20~26岁之间,他们的母语是维吾尔语,汉语普通话是他们的第二语言。另外10名是汉族人,来自北京,他们的普通话比较标准,平均年龄是23岁。
需要研究的是维吾尔族人的普通话声调的偏误及产出,也就是研究处在不同的普通话学习阶段的维吾尔族人的普通话声调的特点。因此根据这50名维吾尔族人的普通话熟练程度将其分成三组,作为处在不同的学习阶段的维吾尔族被试。维吾尔族人的普通话熟练程度(分数)是根据中国少数民族汉语水平等级考试(MHK)口语测试平台得到的。
维吾尔族50个人中,普通话熟练分数范围是45~90分,他们的分数发布类似一个正态分布,其平均分是69分,标准差是11。因此我们在分组的时候,选取了在平均分的上下二分之一的标准差作为分界点,将50人分成男、女各3组。最后的分组情况是:低水平组(Uyghur Chinese Beginner Learners, UCB)被试的分数:45<低水平组(Beginner)<= 60;中水平组(Uyghur Chinese Intermediate Learners, UCI)被试的分数:60<中水平组(Intermediate)<=75;高水平组(Uyghur Chinese Advanced Learners, UCA)被试的分数:75<高水平组(Advanced) <=90。详细的分组情况见表1所示。

表1 被试分组的详细情况
1.2 语音采集情况
实验中使用的语音是在专门的录音室中采集的,使用设备有笔记本、外置声卡、麦克风和相互连接的数据线。使用外置声卡能够调节声量大小、降低噪声、监控爆破音情况等。软件采用Matlab编写录音程序。被试的阅读材料是汉语单音节词,每个被试需要录500个单音节词。语音采集频率是16 kHz。录制的汉语单音节词列表尽可能地覆盖了基本汉语声调。例如,“a、ka、bu”的阴平(T1)声调;“de、mo、di”的阳平(T2)声调;“a、ru、e”的上声(T3)声调;“a、ke、bu”的去声(T4)声调等。除去轻声后每个声调的个数为:低水平组(男女各6人),T1:249,T2:319,T3:221,T4:239;中水平组(男女各10人),T1:149,T2:191,T3:134,T4:144;高水平组(男女各9人),T1:226,T2:291,T3:198,T4:216;标准组(参照组,男女各5人),T1:340,T2:353,T3:362,T4:375。
1.3 语音数据处理
采集完被试的语音后,将采集的维吾尔族人和汉族人的普通话语音进行自动标注,本研究中采用的自动切分系统可以将语音切分到音素级,并且限制在20 ms的误差范围内,该自动切分系统的准确性是93.92%[9]。自动标注以后,我们对50个人的音频再次进行手动人工校对,准确率达到97.22%。根据已标注的单音节语音,以被测试者的发音基频为依据,选出每个被试调域的最大值和最小值,其中3%~5%的位置为最小值,95%~97%的位置为最大值,之后将被试的声调进行转换,最终变成五度制。10位汉语母语者和不同水平(高水平、中水平和低水平)的50位维吾尔学习者的4类声调转换成5度值和各声调时长以及音强,然后,与汉语普通话母语者和维吾尔学习者的声调一阶差分、声调时长分布模式以及相似度进行比较。
2 声调的一阶差分分析
通过一阶差分,能够得出汉语声调在日常习得过程中的特征,还能够将汉语方言声调的特征区分出来[10]。同时一阶差分得出来的值可以将F0(基频)曲线的变化直接呈现。此外,每个人的音域都有所差异,这是因为受到先天因素和后天语调习得因素的影响。所以,我们要将音域的差别消除,主要的方法就是将F0值进行转化,变成一阶差分值[11]。因此,通过维吾尔族学习者声调的一阶差分,进一步可以找出他们产生偏误的原因。
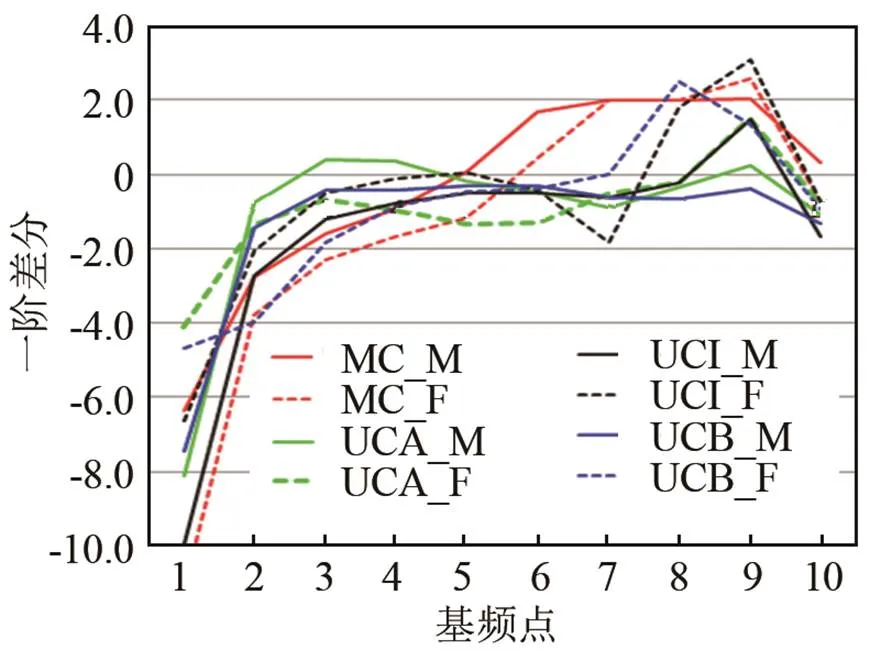
图1 MC&UCA&UCI&UCB阴平声调(T1)曲线的一阶差分
(Note: In this figure and all the following figures and tables of this paper, MC represents native Mandarin speakers, UCA represents high-level Uygur learners, UCI represents middle-level Uygur learners, UCB represents low level Uygur learners; M means male, F means female, T1 is yin-ping tone, T2 is yang-ping tone, T3 is rising tone and T4 is falling tone)

图2 MC&UCA&UCI&UCB阳平声调(T2)曲线的一阶差分
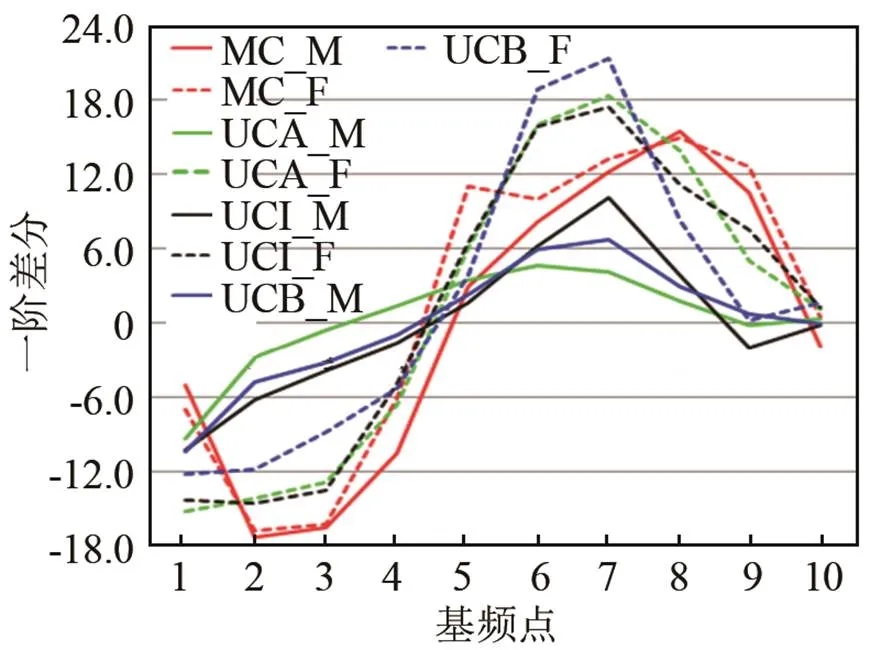
图3 MC&UCA&UCI&UCB上声声调(T3)曲线的一阶差分
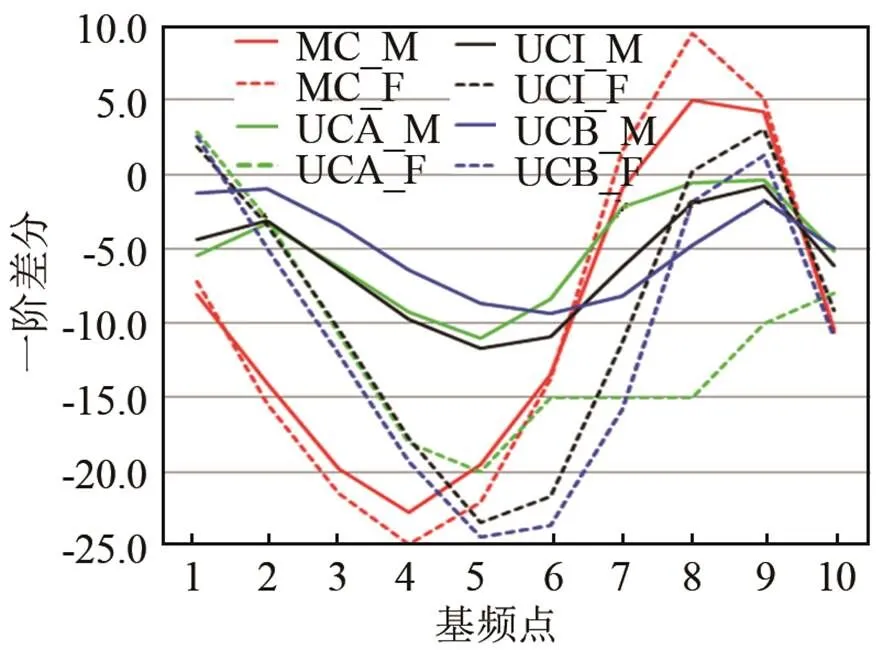
图4 MC&UCA&UCI&UCB去声声调(T4)曲线的一阶差分
图1~4是汉语普通话母语者与各个水平阶段的维吾尔族学习者按照不同声调的一阶差分图(图中M表示男性,F表示女性;MC代表汉语普通话母语者,UC代表维吾尔族普通话学习者,UCA代表高水平组维吾尔族学习者,UCI代表中水平组维吾尔族学习者,UCB低水平组维吾尔族学习者;T1-阴平,T2-阳平,T3-上声,T4-去声)。通过图1~4,可以比较汉族人和维吾尔族普通话学习者的声调调形的不同,主要关注在拐点。图1是T1的一阶差分图,从图1中可以看出,汉语母语者和维吾尔族人的T1在调形上没有很大的差别。
图2是T2的一阶差分图,从图2中可以看出维吾尔族女性学习者(UCB_F, UCI_F, UCA_F)调型类似于标准普通话者(MC_F, MC_M)的调形,但是MC的最高峰在尾部,整体图形呈现出抛物线状,而UCF和UCM并不是这样,他们的最高峰都出现在中部,这说明维吾尔族学习者在原声调曲线上的斜率要大于MC,UC的T2从中部出现急剧的下降趋势。原声调的拐点是轴对应于轴0点的位置。从图2中可以看出,UC的基频平均值比MC的平均值要大(UC大约是4,MC大约是2),可见维吾尔族学习汉语的拐点要相对靠后。从值也可以看出差异:维吾尔族学习者,当=4时=0;而汉语母语者,当=2时=0。这说明学习音节过程中,拐点的位置不同,维吾尔族人的拐点位置在轴的40%位置处,而汉族人在20%处就已经出现了拐点。
图3是T3的一阶差分图。从图3中可以看出,UC_F曲线在=4的时候都能够与=0相对应,这表示维吾尔女性在学习汉语时的拐点出现位置与汉语母语者出现的拐点位置相同。而男性(UC_M)的曲线对应=0位置的轴的值约为3,与汉语普通话母语者有所不同。此外,从轴的最高值可以看出,维吾尔族人为22,而汉语母语者为14,比汉语普通话母语者大将近一半。
图4是T4的一阶差分图。对于女性发音人而言,维吾尔族学习者的调型与汉语普通话母语者很接近,而男性发音人有很大的差异,并且从斜率上看,维吾尔男性被试的斜率要高于汉语母语者,从原声调曲线图中可以看出,维吾尔族的男性汉语学习者的T4下降非常快。
为了将一阶差分在解释声调走向趋势上做出更清晰的解释,我们将对不同水平的维吾尔族学习者男女(UCA, UCI, UCB)和汉语普通话母语者(MC)的一阶差分图(图5~13,图中英文字母含义与图1~4相同)分别进行详细的分析。
图5、6分别是男性和女性汉语普通话母语者声调曲线的一阶差分图。由图5可知,MC_M的T2一阶差分曲线中,对应=0位置的值约是3,T3的是4.2,T2和T3的一阶差分曲线的调形差异性很大。T1一阶差分对应的=0时值为4,T4为5.4。由图6可知,MC_F的T1和T4也有差别。T1的一阶差分=0时的值为6,T3为4.6,T4为7。此外,MC_M与MC_F在本文研究的四类声调都有差异,这种差异主要是体现在一阶差分曲线上。

图5 汉语普通话母语者声调曲线的一阶差分(M)
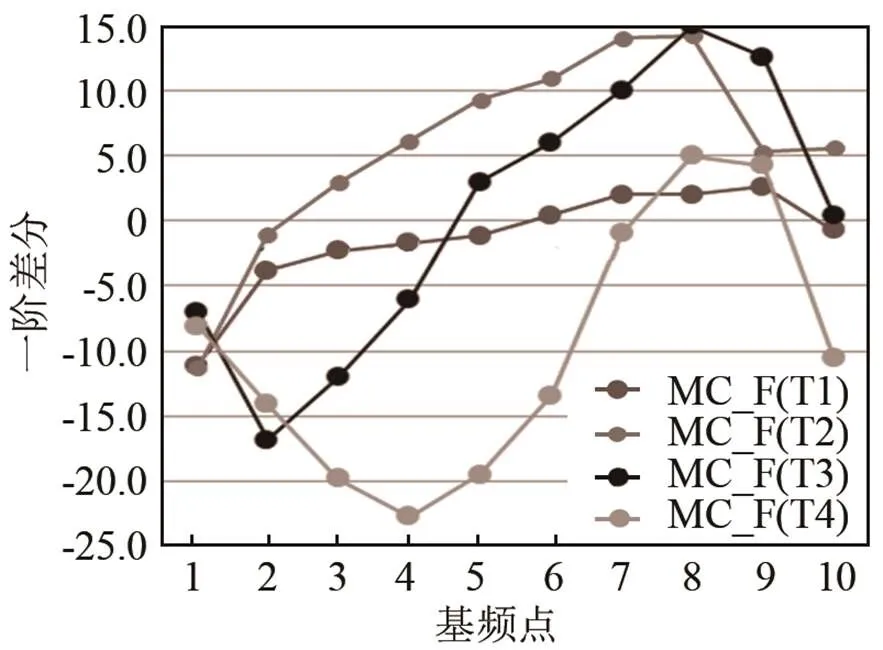
图6 汉语普通话母语者声调曲线的一阶差分(F)
图7、8分别是男性和女性高水平组维吾尔族学习者声调曲线的一阶差分图。从图7~8可以发现,T1和T2的调型很相似,对应=0位置的值都是4,与MC不同。T3一阶差分的对应=0位置的值分别是3(UCA_M)和4.2(UCA_F),与MC_F的调型和拐点很接近。T4的位置也与MC有很大的差异,说明T1&T2&T4的拐点有偏误。
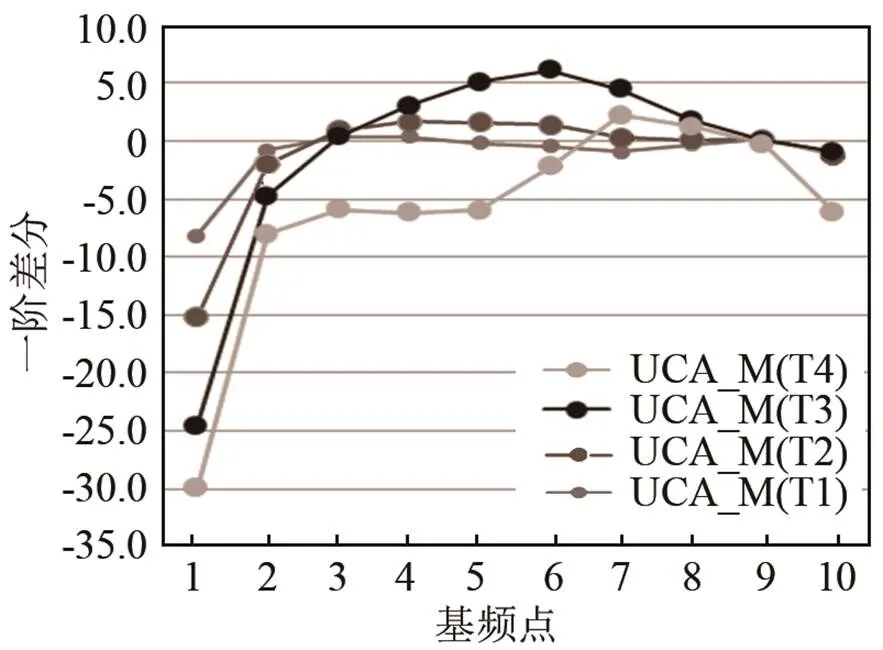
图7 维吾尔族学习者声调曲线的一阶差分(UCA_M)

图8 维吾尔族学习者声调曲线的一阶差分(UCA_F)
图9、10分别为男性和女性中水平组维吾尔族学习者声调曲线的一阶差分图。从UCI的一阶差分图可显示,UCI的T1和T2的调型很相似,UCI_M的T1、T2的拐点和MC_M的相同,一阶差分对应=0位置的值都是3,表示没有偏误。而T3、T4的拐点和调型有很大的差异,UCI_M习得有困难,有偏误。UCI_F的T3的一阶差分中,=0时,的对应值大约为4.2。T3的最大值约为28,比MC的最高值要大,这主要体现出UCI_F在T3的末尾处的斜率要更好,因此T3曲线在末尾处具有更高的上升可能。
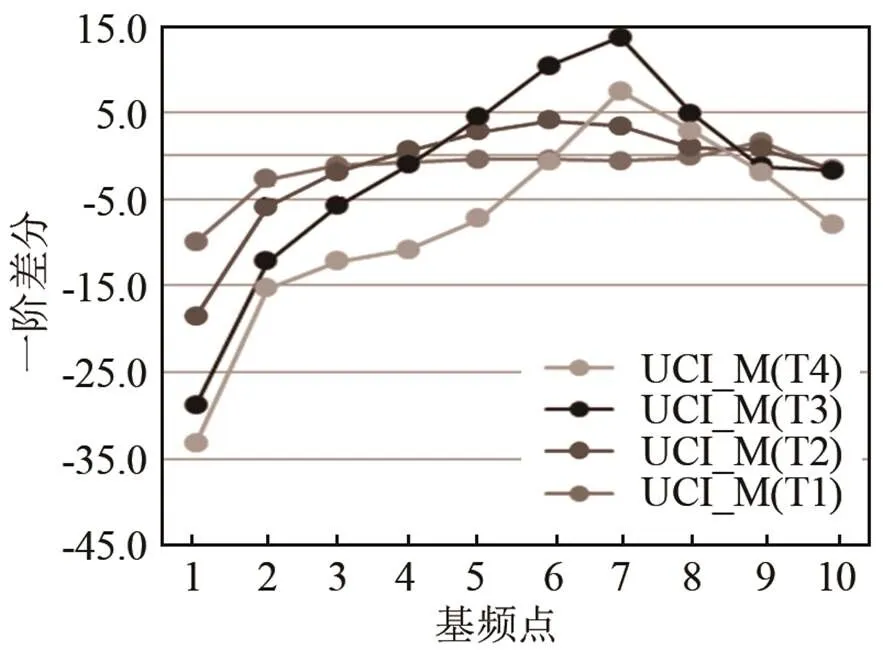
图9 维吾尔族学习者声调曲线的一阶差分(UCI_M)
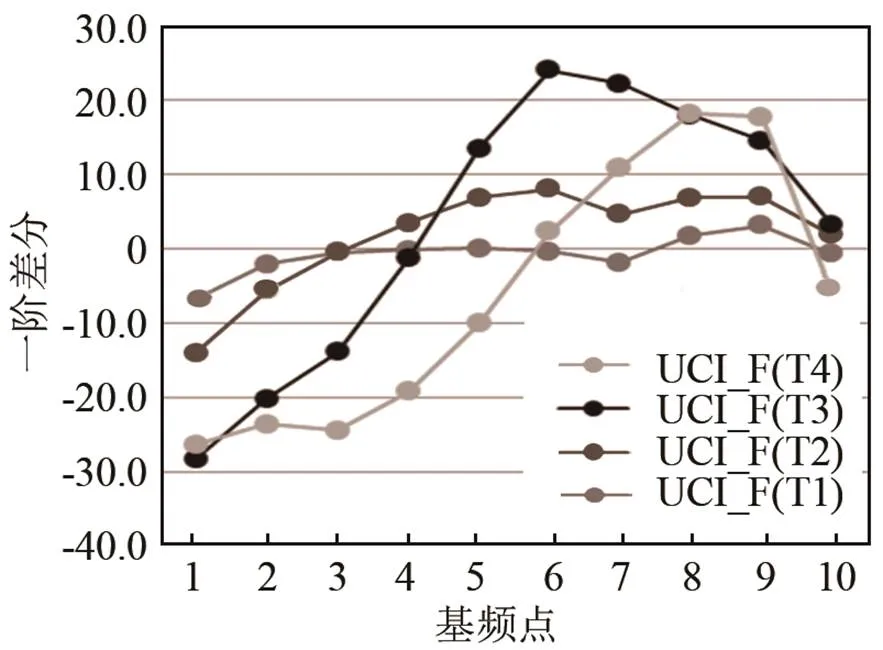
图10 维吾尔族学习者声调曲线的一阶差分(UCI_F)
图11、12分别是男性和女性低水平组维吾尔族学习者声调曲线的一阶差分图,从图中可以看出,T1和T2在调形上具有相似性,=0时对应的值为3,与MC_M的相同;而UCB_F的一阶差分的对应=0位置的值是4,MC_F的值约是2.6。
UCB_M的T3一阶差分对应=0位置的值约是6,T4一阶差分对应=0位置的值约是4,分别比MC_M(约1.8,1.5)大,说明UCB_M的T3、T4末尾的斜率比较小。
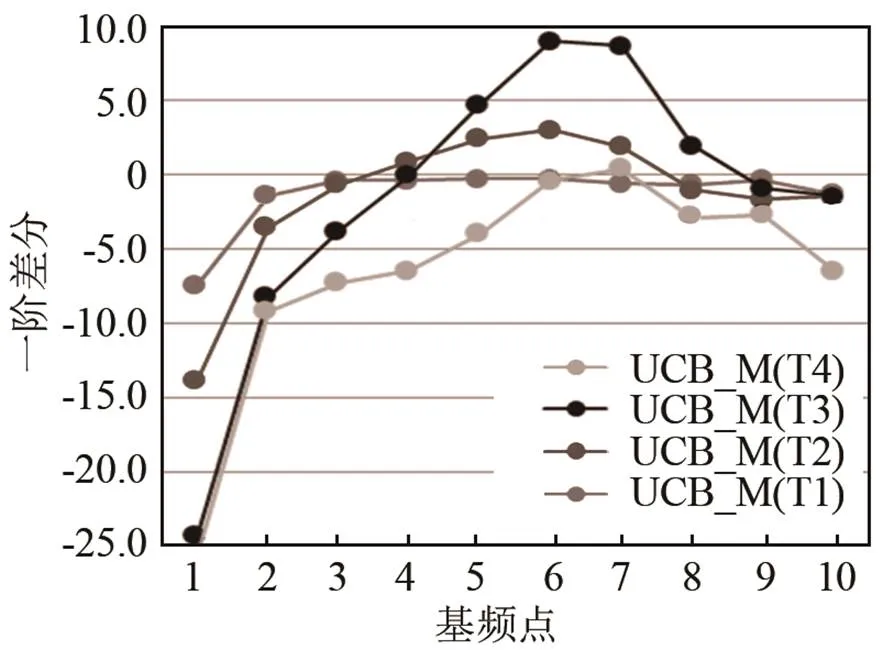
图11 维吾尔族学习者声调曲线的一阶差分(UCB_M)
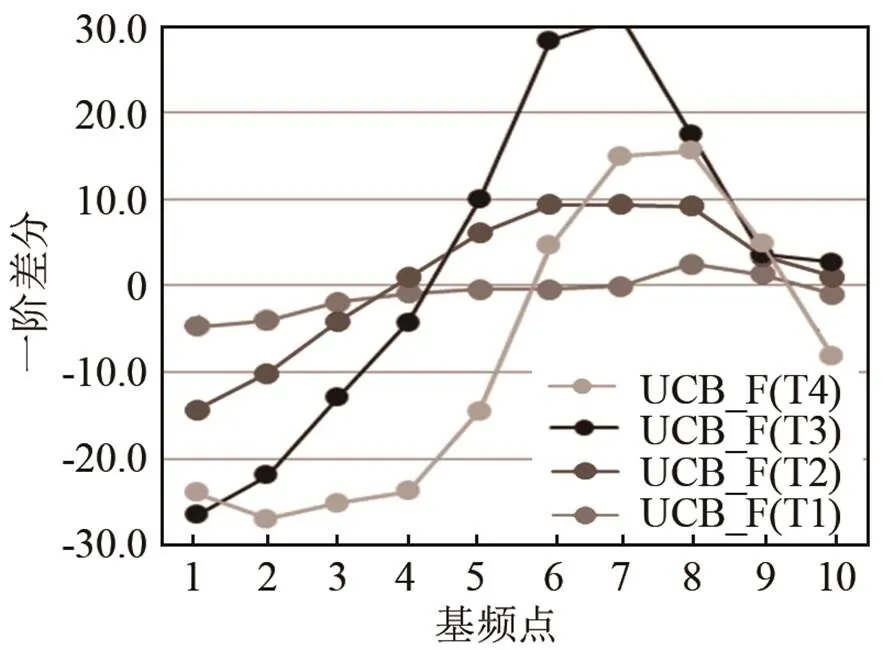
图12 维吾尔族学习者声调曲线的一阶差分(UCB_F)
不过,UCB_F的最大的值相比MC_F的值约大1倍,表示T3末尾的斜率比较大,曲线末尾的上升趋势更大,说明UCB_F的T3有偏误。UCB_F的T4调型和末尾的值跟MC_F很相似。
由以上的各类声调的一阶差分图可推测出,三组维吾尔族人学习普通话的声调都有困难。两种语言的音系、语调和重音等特性影响了第二语言中声调特性。这种声调系统的差异导致了维吾尔族人学习普通话的声调出现困难。
3 声调时长和音强声学分析
3.1 声调时长分布模式
时长就是时间长短的意思:如MC念的“妈”“麻”“马”“骂”里的时长分别为:90、75、111、68 ms;将它分为最长、次长、次短和最短四个等级。声调是一个持续的音段,每个声调都有一定的时长。不同发音人的绝对时长值差别很大,有时甚至同一个人的不同单词的时长之间也存在着很大的差异。
因此,对绝对时长进行了归一化处理。归一化的目的,就是使不同发音人之间的时长更具有可比性。我们采用朱晓农[12]的“跨声调均值”的方法进行时长归一化,该方法是以所有声调时长的平均值作为基准,设为单位“1”,再用各声调的时长除以平均时长,便得到了各声调的相对时长值。规整公式为
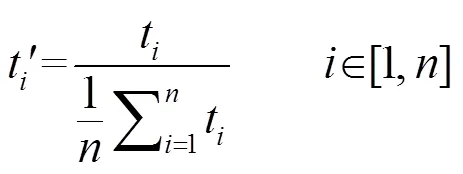
表2和图13分别是UC和MC归一化处理后的(男,女)单字声调相对时长表和比较图。(M代表男性,F代表女性)。
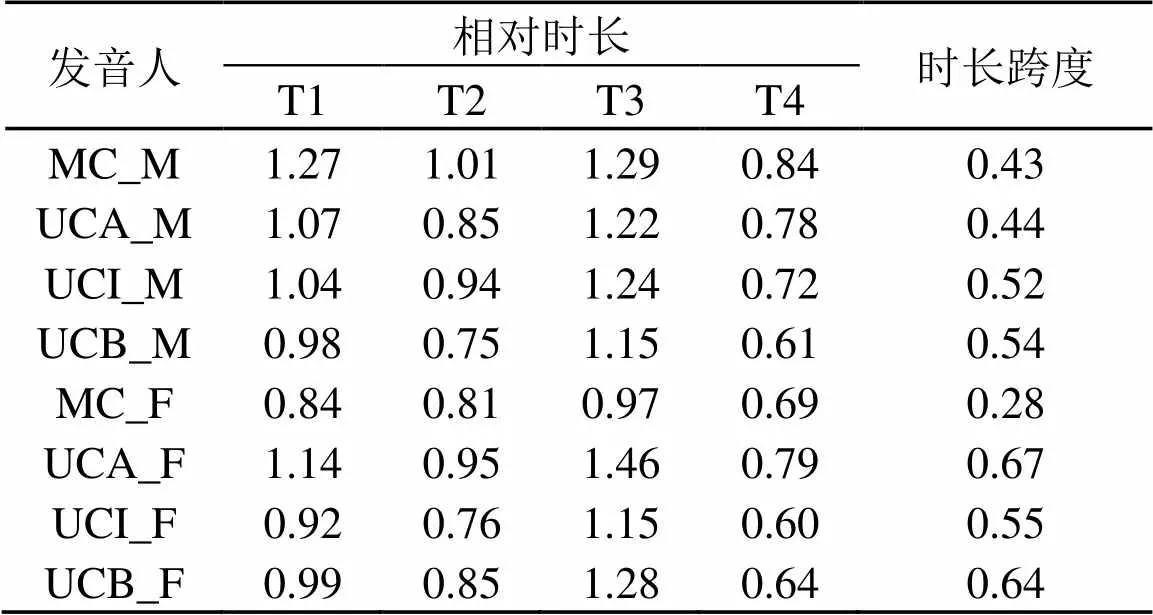
表2 普通话母语者和维吾尔族学习者单音节词声调相对时长
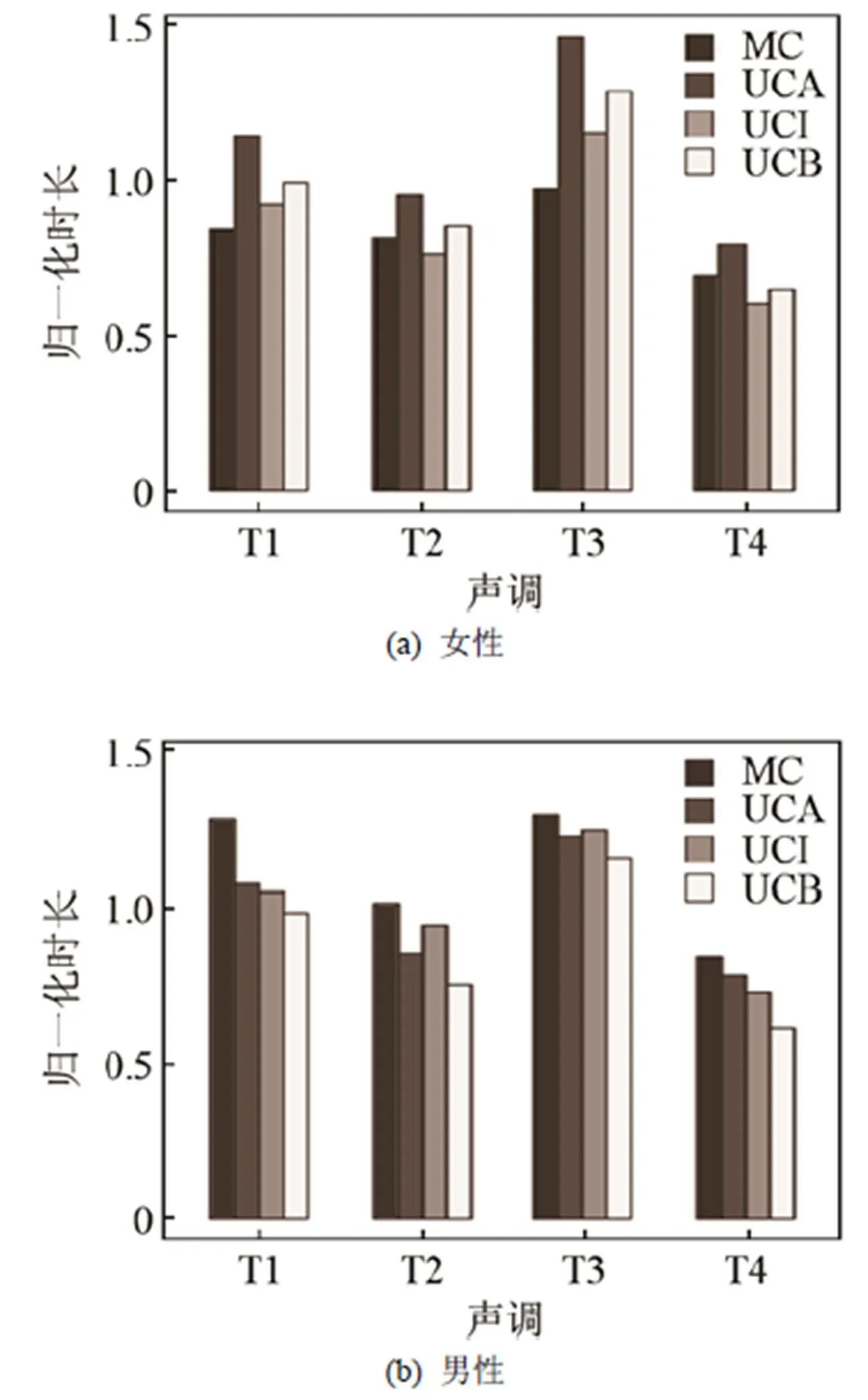
图13 普通话母语者和维吾尔族学习者单音节词声调相对时长分布图(M,F)
对不同性别的UC和MC声调时长的归一化结果表明,(1) 普通话母语者或者不同水平的维吾尔族学习者(男性和女性)在去声(T4)的归一值很接近,差别主要表现在上声、阴平、阳平上。(2) 对于男性发音人来说,在阴平上不同水平的维吾尔族学习者的相对时长很接近,男性普通话母语者(MC_M)在四声时长的跨度为0.43,而不同水平的维吾尔族学习者在四声的跨度值分别为:UCA_M:0.44,UCI_M:0.52,UCB_M:0.54,说明阴平和上声的时长优势在普通话母语者中比较明显。(3) 对于女性发音人来讲,中水平和低水平的维吾尔族学习者(UCI_F、UCB_F)的阳平时长(T2)和UCB_F在阳平的相对时长值接近于普通话母语者。在四组发音人中,高水平维吾尔族学习者的时长跨度最大,为0.67,中低水平维吾尔族学习者的时长跨度相对较小,分别为:中级:0.55,低级:0.64;而普通话母语者的时长跨度最小,为0.28。因此,在女性发音人中,高水平维吾尔族学习者的时长优势更明显。(4) MC和UC都具有相同的时长分布模式T3>T1>T2>T4,但是,表2清楚地显示,在四声中维吾尔族学习者(UC)时长跨度值都大普通话母语者,并且差异比较大,相似性较小。
3.2 声调时长相似度分析
我们需要进一步对MC与UC的声调时长的差异性、以及不同级别的维吾尔族人之间的差异性进行分析,在这个过程中我们引入时长模式相似度。式(2)的e指数提供了客观的数据来表现维吾尔族学习者和汉语母语者声调时长模式的相似度。
e指数距离公式[13]:

表3是以MC(5男,5女)的时长分布为参照,计算出的时长分布相似度。我们可以看到,无论是高水平、中水平或者低水平的女性UC,与MC之间的相似度很高,分别是0.97, 0.98, 0.98。同时,UC(UCA,UCB)女性发音人与MC男性发音人的时长分布模式相似度比起UC(UCA,UCB)男性和MC男性发音人的相似度均要高(0.83>0.71,0.86>0.75)。对UC而言,并不是MHK考试成绩分数越高,时长分布模式与汉语母语者越接近,二者之间的对应关系是模糊的,并不清晰。
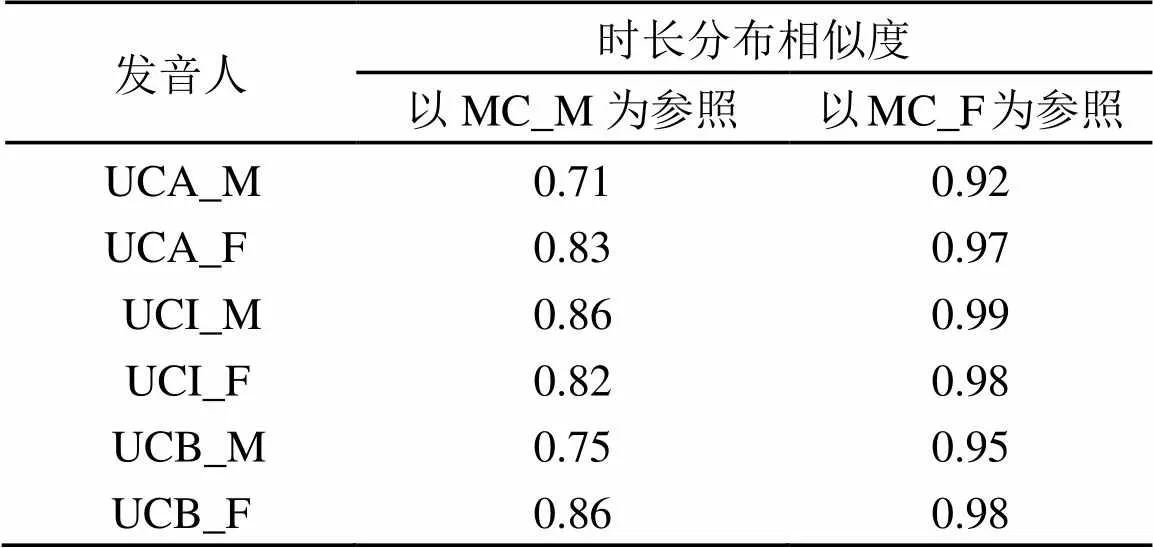
表3 汉语普通话母语者与维吾尔族学习者时长分布模式相似度
3.3 声调的音强特征分析
对60位发音人的样本进行测量统计后,我们得到了MC和UC单字调音强格局(如图14所示)。这里做声调音强(能量)实验是为了探讨音强曲线的形状在四声中有什么不同,以及观察能量在音调中的作用。汉语声调的音强曲线形状为前强、中强、后强、平台、双峰五种类型[14]。

图14 普通话母语者和维吾尔族学习者声调音强分布模式
从整体上看,无论是男性还是女性发音人,MC和UC各类音调音强曲线有明显差异。MC起点音强都是65 dB以上,终点为55 dB以上,都高于UC。
具体来看,MC和UC的音强曲线在各类声调上的表现不同。在阴平调(T1)中,男性MC的音强曲线为平台型,起点为69 dB,中间较平,末尾呈下降趋势,终点为64 dB。男性高、中、低水平UC学习者的音强曲线差异不大,整体上低于男性MC,为前强型。女性MC的音强曲线为前强型,起点较高,末尾处下降趋势较为明显。女性UC的音强曲线为平台型,首尾较低,中间较平。
在阳平调(T2)中,男性MC和女性MC的音强曲线存在差异。前者的音强曲线为后强型,第1~4个点较低,第5~8个点逐渐上升,最高点达到71 dB。后者为平台型,起点略低,中间较平,末尾处下降较明显,最低达到58 dB。男性和女性UC都为平台型,其中男性不同水平学习者的内部差异较小,三条曲线集中在50 dB左右。女性学习者的平均音强高于男性学习者,并且存在一定的内部差异,其中高级水平学习者的音强曲线最高,中级水平学习者的音强曲线最低。在上声调(T3)中,所有发音人的音强曲线都为双峰型,第一个峰值出现在第2点,第二个峰值出现在第9点。MC的音强最大值为69 dB,最小值为63 dB。在去声调(T4)中,MC和男性UC的音强曲线为前强型,第2~5个点处的音强较高,第5点后音强下降明显,其中男性UC的最低点达到36 dB,女性MC的最低点为56 dB。女性UC的音强曲线为平台型,第7~10个点下降明显,最低点达到42 dB。
经分析可见,MC和UC的音强曲线主要体现为高低上的差异,曲线的形状比较一致。男性发音人和女性发音人的音强差异在各个声调上的表现不同。男性MC和女性MC的差异主要体现在T2(后强型 VS 平台型)和T3(拱度小 VS 拱度大)上。男性UC和女性UC的差异主要体现在T1(前强型 VS 平台型)和T4(前强型 VS 平台型)上。高、中、低水平UC的音强曲线较为一致,差异较小。
4 结论
本研究主要分析了10位MC和50位UC(根据MHK考试成绩分成低水平、中等水平、高水平三类)在声调学习数据中的一阶差分模式,对UC的声调偏误进行了声学和实验对比分析。根据各类声调的一阶差分图可推测出不同水平的三组维吾尔族人学习普通话的声调都有困难,对声调有偏误。
两种语言的音系、语调和重音等特性影响了第二语言中声调特性。这种声调系统的差异导致了维吾尔族人学习普通话的声调出现困难。与此同时,维吾尔语是无声调、有重音的语言,而重音不起区别语义的作用。维吾尔语语流中通常会把韵律词放置于重音之前,而韵律词所含音节的音高绝大部分是中平调或是平调,同时随后的重音则运用中升调,而句子快结束时又采用降调。所以,维吾尔族学习者在运用平调、降调和升调时都可以在维吾尔语中找到能够对照的调型。在声调时长上MC和UC有差异,从10位MC的声调时长特征可以看出,这10位被试的声调时长模式具有高度的一致性,均为T3>T1>T2>T4。
从实验结果来看,UC呈现出类似的特征,但是,UC在四声的跨度值远大于MC。而且MC和UC在能量上也有明显的差异。参考MHK考试成绩将其汉语水平分为低水平、中等水平和高水平,但是这样分类并不能体现与声调时长模式之间的相关性。总体说来,MHK考试成绩与单字调发音是有相关性的,一般来说MHK成绩高,单字调发音要更好,但是这种关系并不是绝对成立的。因此,将MHK成绩作为维吾尔族人汉语水平的唯一标准并不科学,还需要开发其他的评定标准,特别是与口语相关的标准。
[1] 朱晓农. 语音学[M]. 北京: 北京商务印书馆, 2010: 190-195.
ZHU Xiaonong. Phonetics [M]. Beijing: The Commercial Press, 2010: 190-195.
[2] ZHAO Lu, FENG Hui, WANG Huixia, et al. Acoustic Features of Mandarin Monophthongs by Tibetan Speakers[C]//Banchs R E, Minghui Dong, Yanfeng Lu, Bali Ranaivo-Malançon. Proceedings of the International Conference on Asian Language Processing 2014 (IALP 2014). Kuching: IEEE, 2014a: 147-150.
[3] 陈晨, 李秋杨, 王仲黎. 泰国学生汉语元音习得中迁移现象的声学实验研究[J]. 民族教育研究, 2009, 20(1): 108-115.
CHEN Chen, LI Qiuyang, WANG Zhongli. An acoustic experiment on transfer of Thai students in their acquisition of Chinese vowels [J]. Journal of Research on Education for Ethnic Minorities, 2009, 20(1): 108-115.
[4] 温雪莹. 日本学生汉语元音习得的实验研究[J]. 语言教学与研究,2008, (4): 62-69.
WEN Xueying. An experimental study of Japanese students' acquisition of Chinese vowels[J].Language Teaching and Linguistic Studies, 2008, (4): 62-69.
[5] 廖涌舜. 零起点泰国汉语学习者元音习得偏误分析及其教学对策[D]. 上海: 上海外国语大学, 2012.
LIAO Yongshun. Error analysis and teaching strategies of vowel acquisition in Thailand Chinese learners of zero distance[D]. Shanghai: Shanghai International Studies University, 2012.
[6] 林焘, 王理嘉. 语音学教程[M]. 北京: 北京大学出版社, 2013, 5-12.
LIN Tao, WANG Lijia. A course in phonetics[M]. Beijing: Beijing University press, 2013, 5-12.
[7] 牟宏宇, 原猛, 冯海泓. 双耳分听汉语普通话声调研究[J]. 声学技术, 2014, 33(1): 42-45.
MOU Hongyu, YUAN Meng, FENG Haihong. Research on dichotic listening of Mandarin tone[J]. Technical Acoustics, 2014, 33(1): 42-45.
[8] 李晓飞. 中级阶段维吾尔族留学生汉语普通话单字调声调习得偏误分析[D]. 新乡: 河南师范大学, 2015: 1-5.
LI Xiaofei. Middle school Uyghur Students, Mandarin Chinese, tone, tone, tone, acquisition, error analysis[D]. Xinxiang: Henan Normal University, 2015: 1-5.
[9] YUAN J, Ryant N, Liberman M. Automatic phonetic segmentation using boundary models[C]//INTERSPEECH. 2013: 2306- 2310.
[10] 金健. 汉语方言典型个案的实验[D]. 广州: 中山大学, 2009.
JIN Jian. An experiment on typical cases of Chinese dialects[D]. Guangzhou: Zhongshan University, 2009.
[11] Bruno Gauthier, Rushen Shi, Yi Xu. Learning phonetic categories by tracking movements[R]. Beijing, Speech Research Report. 2008.
[12] 朱晓农. 上海声调实验录[M]. 上海: 上海教育出版社, 2005.
ZHU Xiaonong. Shanghai tone experimental proceedings[M]. Shanghai: Shanghai Education Press, 2005.
[13] DANG J. Comparison of emotion perception among difference cultures[C]//presented at the APSIPA, sapporo, Japan, 2009.
[14] 鲍怀翘, 林茂山. 实验语音学概要[M]. 增订版. 北京: 北京大学出版社, 2014, 175-177.
BAO Huaiqiao, LIN Maoshan. Overview of Experimental Phonetic[M]. Revised Edition. Beijing: Peking University Press, 2014, 175-177.
Tone investigation of non-native Chinese speakers based on acoustic features
Gulnur Arkin, Askar Hamdulla
(Institute of Information Science and Engineering, Xinjiang University, Urumqi 830046, Xinjiang, China)
Starting from the practical application requirements of ethnic minorities to improve the capabilities in the mandarin speech synthesis with high naturalness and the high precision mandarin speech recognition, this paper makes a comparison of the first order difference, the time length and similarity of tones between 50 Uyghur students in the junior, intermediate and advanced stages and 10 native mandarin speakers from the perspective of experimental phonetics. The experimental results of the first order difference model, the tone duration and other prosodic parameters are analyzed, and the relationship between Uyghur students' Chinese tone errors and MHK scores is obtained. It can be found that the three groups have difficulty in learning Mandarin tones, and the characteristics of phonological, intonation and stress of the two kinds of languages affect the tone characteristics in the second language. The tonality feature and tone duration of Uyghur learners and some important rules and conclusions are summarized. The present research can help strengthen phonetic teaching among ethnic minorities and provide more effective empirical data for speech synthesis and speech recognition of the Chinese spoken by ethnic minorities.
first order difference; tone errors; contrastive analysis; Uyghur learners; duration
H107
A
1000-3630(2018)-06-0571-08
10.16300/j.cnki.1000-3630.2018.06.011
2017-06-22;
2017-08-15
国家973项目 (2013CB329301);国家自然科学基金项目(61063023)资助项目。
古力努尔·艾尔肯(1988-), 女, 新疆伽师人, 博士研究生, 研究方向为语音信号处理。
艾斯卡尔·艾木都拉,E-mail: askarhamdulla@sina.com
猜你喜欢
草原歌声(2020年3期)2021-01-18
小天使·一年级语数英综合(2020年9期)2020-12-16
小天使·一年级语数英综合(2020年9期)2020-12-16
韶关学院学报(2020年8期)2020-11-12
小学生学习指导(低年级)(2019年9期)2019-09-25
作文周刊·小学一年级版(2019年28期)2019-09-07
草原歌声(2017年3期)2017-04-23
西安交通大学学报(医学版)(2015年2期)2015-02-28
湖北大学学报(哲学社会科学版)(2014年1期)2014-03-20
中国火炬(2011年9期)2011-07-24
