
基于光流的快速人体姿态估计①
2019-01-07 02:40周文俊郑新波卿粼波熊文诗吴晓红
计算机系统应用 2018年12期
周文俊,郑新波,卿粼波,熊文诗,吴晓红
1(四川大学 电子信息学院,成都 610065)
2(东莞前沿技术研究院,东莞 523000)
基于视觉的人体姿态估计问题是指根据图像特征估计人体各个部位的位置与关联信息[1].人体姿态估计是图像处理、计算机视觉、模式识别、机器学习、人工智能等多个学科的交叉研究课题,在视频监控、视频检索、人机交互、虚拟现实、医疗看护等领域,具有深远的理论研究意义和很强的实用价值[2,3].
目前的人体姿态估计算法主要分为两类:一类是基于深度图像,另一类是基于可见光图像.基于深度图像的算法,主要利用如Kinect[4]等深度传感器获取代表着人体外貌和几何信息的颜色和深度(RGBD)数据,进而分析人体的姿态.但深度传感器等硬件设备的配置及数量有限,导致其无法分析如监控视频,网上的海量视频等数据.而基于可见光图像的算法,只需要获取图片中人体的表观特征,如人体姿态各部分的HOG特征[5]、人体轮廓特征[6]及视频中上下文(Context)关系[7].但以上特征都需要手动提取,且不具有鲁棒性.直到近几年,深度学习被广泛运用到图像处理领域,促进了人体姿态检测进一步的发展.其中,Cao等[8]从图像底层出发,对人体姿态关节点进行回归分析,同时运用并行网络提取人体关节点间的亲和力场,确定多人姿态关节点之间的联系.Pfister等[9]利用光流信息将前后帧的人体姿态热力图扭曲到当前帧,然后赋予不同时刻热力图不同的权值,综合得到当前帧人体姿态.He等[10]首先采用神经网络提取人体候选区域,然后在候选区域上用两个并行的网络分别进行目标检测和人体姿态关节点检测.Charles等[11]利用已有的人体姿态估计模型初始化视频帧,然后在相邻帧中进行空间匹配,时间传播及人体姿态关节点的自我评估,不断地重复上述过程得到准确的人体姿态关节点.上述基于深度学习的方法能够很好的解决基于单帧图像的人体姿态估计问题.然而,对于大量现有的视频数据,大多数视频分析任务是通过直接将识别网络应用到视频的所有帧,这一方法将消耗大量的计算资源,且未考虑到视频帧之间的时间相关性.
综上所述,基于深度学习的人体姿态检测算法虽然已经在单帧图像上取得了较好的效果,但它们往往依赖于强大的计算机硬件平台,一般需要多个GPU进行加速.而在计算资源受限的移动终端上对视频数据运用上述基于深度学习的人体姿态检测算法时,终端的计算能力往往无法达到需求,所以如何降低或转移人体姿态估计算法的计算复杂度[12],是该领域的一个重要研究方向.另外,由于人和相机具有运动连续性的特点,相邻帧之间的人体姿态也将表现出运动的连续性[13],即时间相关性,因此本文提出了一种基于光流的快速人体姿态估计算法,该算法利用视频帧之间的时间相关性实现人体姿态估计的加速.在一个视频帧组内,首先根据人体姿态估计算法对关键帧进行人体姿态检测.而对于其他的非关键帧,计算它与前向关键帧之间的光流场信息(时间相关性),然后根据光流场将关键帧的检测结果传播到非关键帧上,避免了在每一帧上运行人体姿态估计算法.当光流场计算复杂度低于人体姿态估计算法时,本文框架可以有效提高人体姿态检测算法的检测速度.
1 基于光流的快速人体姿态估计
1.1 视频帧姿态相关性分析
视频相邻帧之间存在极强的时空相关性[14],这种相关性是由运动的连续性决定的,因此视频相邻帧中运动目标及人体姿态信息具有更强的时空相关性.如图1所示为视频帧间相关性及人体姿态相关性效果图,第一行Frame为原始视频帧,第二行Pose为原始视频帧对应的真实姿态信息,第三行Flow为第i帧(i=2,…,5)图像与第一帧图像之间的真实光流场,第四行Dsp为第i帧(i=2,…,5)图像中人体关键点与第一帧图像中人体关键点之间的运动矢量场.
如图1中Dsp反映了视频序列中Framei(i=2,…,5)与Frame1对应关键点之间的运动矢量,而视频帧间的运动矢量为视频帧之间对应相似块的运动信息,同时通过运动矢量可将第一帧图像的人体姿态信息传播到后续视频帧中.Flow为视频序列中Framei(i=2,…,5)与Frame1之间的光流信息,而光流就是在图像灰度模式下,图像间的亚像素级运动矢量,被广泛用于估计两个连续帧之间的像素点的运动[15].因此可以通过视频帧间的光流信息及Frame1中的人体姿态信息预测Framei(i=2,…,5)中的人体姿态信息.另外,由图1中Frame可知,Frame1到Frame5相邻帧之间人体姿态变化较为平缓.而随着时间的推移,当前帧Framei(i=2,…,5)与Frame1的人体姿态信息变化越来越大,相关性也越来越低.
1.2 基于光流的快速人体姿态估计框架
如上所述,视频帧间人体姿态信息存在极强的时间相关性,而充分利用视频帧间的相关性及运动信息可将已检测的人体姿态信息传播到随后相关性较高的相邻帧中,从而避免对每帧图像进行复杂的人体姿态检测.因此本文提出了基于光流的快速人体姿态估计算法,首先将视频帧分割成多个视频帧组确定视频关键帧(每个视频帧组的第一帧为该视频帧组的关键帧,其余视频帧为非关键帧).然后采用Cao等[8]的人体姿态估计算法确定关键帧人体姿态信息,该算法可有效地检测图片中的人体姿态信息;最后利用轻量级光流算法Flownet2-c[16]计算关键帧与非关键帧之间的光流信息,将关键帧的检测结果传播到非关键帧(如图2).
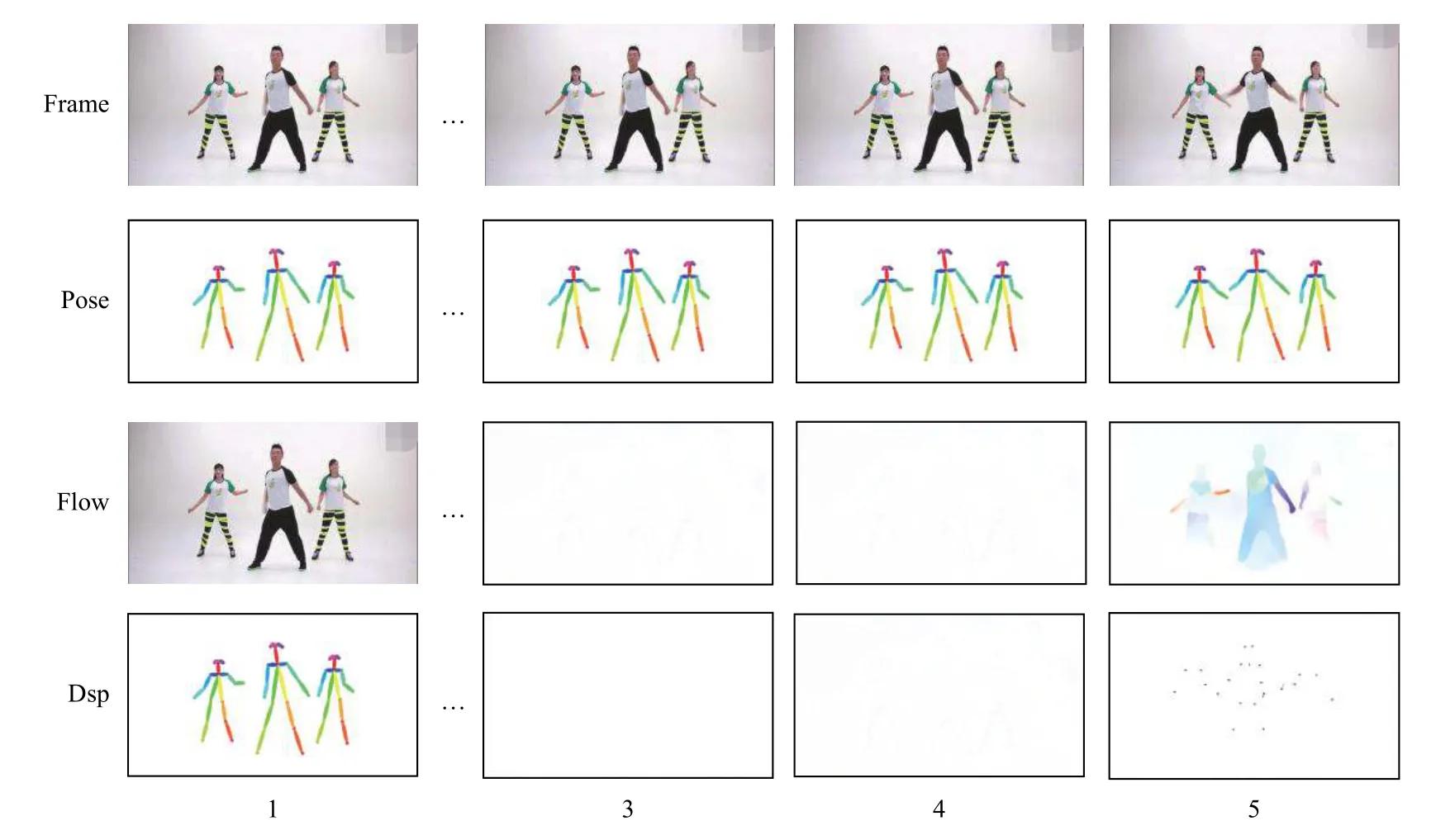
图1 视频帧间相关性及人体姿态相关性效果图
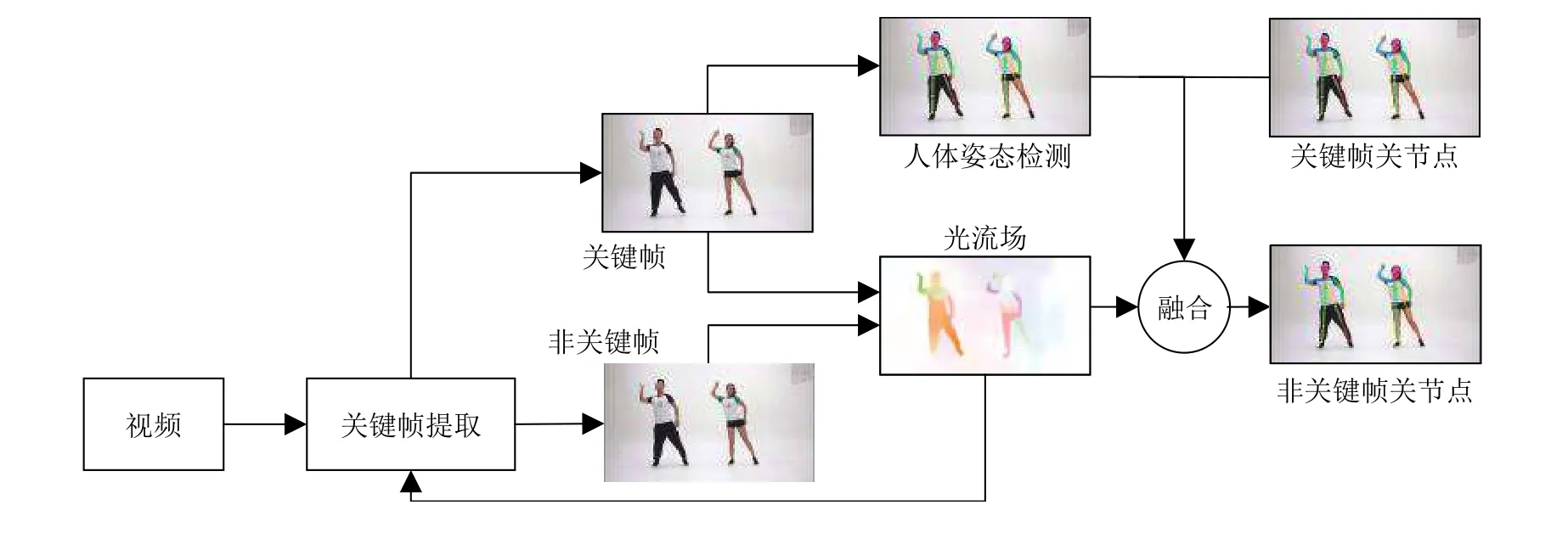
图2 基于光流的快速人体姿态估计
具体定义如下:

其中,Flowi为第i帧图像与对应关键帧FrameI之间的光流信息,PoseI为关键帧的真实人体姿态信息,Posei’为将关键帧的真实人体姿态信息通过第i帧图像与关键帧之间的光流场融合后的人体姿态信息.
基于上述算法原理,本文算法中关键帧的选取,以及关键帧人体姿态信息与光流信息的融合效果直接影响非关键帧的人体姿态估计精度.而由1.1节分析可知视频帧间相关性随着时间推移而降低.因此,视频中关键帧的位置应该根据视频中帧间相对运动程度的不同而重新设置,以适应视频序列帧间相关性的改变.针对上述问题本文提出一种自适应关键帧检测算法.同时也对融合过程中光流计算算法对图像中噪声过于敏感的问题进行优化.
1.2.1 自适应关键帧检测算法
本文算法主要利用光流信息将关键帧的姿态信息传播到非关键帧,当同一视频帧组内关键帧与非关键帧中同一关节点之间有较大的位移时,光流信息就无法准确的描述关节点的运动,从而导致非关键帧人体姿态预测失败.因此本文提出一种自适应关键帧检测算法,其中为了不引入多余的计算量,通过已有的光流场,判断两视频帧之间是否出现剧烈位移运动,从而划分关键帧与非关键帧,达到自适应关键帧检测的目的,具体算法如下:
步骤1.第i帧与前向关键帧PK之间的光流信息fi(x,y).计算局部光流信息模的累加和Local_sum(f)和局部光流信息的最大值Local_max(x,y),具体定义如下:
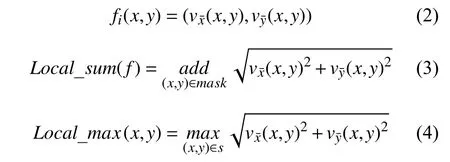
其中,(x,y)为像素坐标,vx¯(x,y)为光流场在x方向上的分量,vy¯(x,y)为光流场在y方向上的分量,mask为图像中每个人的矩形掩模框并集(如图3所示,恰好覆盖所有人的关节点),s为关键帧所有关节点处像素点的集合.

图3 矩形掩模区域
步骤2.确定判决阈值:
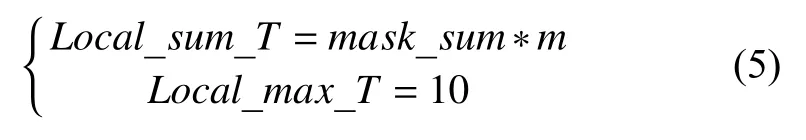
其中,Local_sum_T为局部光流信息模的累加和的阈值,Local_max_T为局部光流信息最大值的阈值.若固定Local_sum_T则无法适应视频中由人距离相机的远近不同,而引起的光流信息不同的问题.因此本文自适应关键帧检测算法会在每一帧自适应阈值.计算关键帧中每个人的矩形掩模框并集的总面积mask_sum,将mask_sum*m(m为掩模系数)作为Local_sum(f)的阈值.而对于局部光流信息的最大值,我们通过大量实验发现,当两帧图像关节点处光流信息的模大于10个像素时,光流场无法准确的预测关节点的位移;当模小于等于10个像素时,光流场可以有效的预测关节点的位移.所以Local_max_T的取值为10.
步骤3.将局部累加和Local_sum(f)与Local_sum_T比较,局部光流信息最大值Local_max(x,y)与Local_max_T比较,以避免局部剧烈运动.
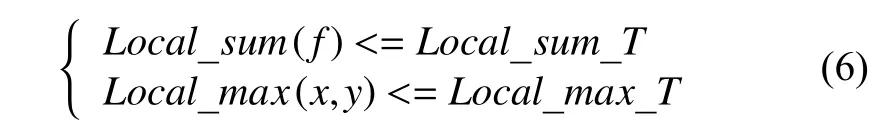
式(6)成立时第i帧为非关键帧,否则结束该视频帧组,第i帧为下一视频帧组的关键帧.
1.2.2 关键点局部融合优化
通过人体姿态估计阶段对关键帧进行人体姿态估计,得到关键帧的人体关节点.然后利用密集光流来预测关节点应如何在时间上流动到下一帧[13].
本文使用的Flownet2-c算法可求得关键帧与非关键帧之间的光流信息.但视频中阴影或噪点在运动物体周围尤其明显,如图4所示,图4(c)为图4(a)和图4(b)利用Flownet2-c算法计算的光流信息.由图可知,运动物体周围的光流信息分布十分不均匀.因此若在融合关键帧姿态信息和光流信息时,只使用关键帧关节处的光流信息作为非关键帧关节点的运动信息,则会因光流信息计算不准确导致关节点信息预测失败.针对这个问题本文利用邻域特性,根据邻域像素点光流信息决定该关节点的运动矢量.采用关节点处5x5邻域的光流信息代替关节点的运动信息,以提高融合预测的准确率.
Flownet2-c算法效果
具体使用式(7)计算得到非关键帧的关节点.
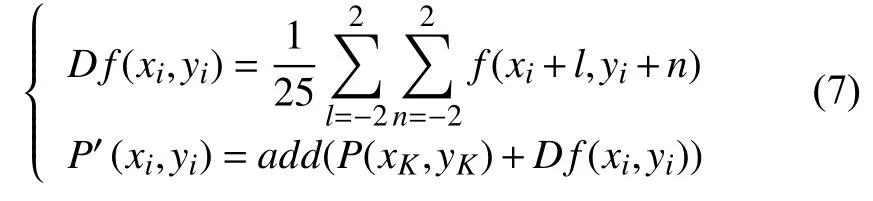
其中,Df(xi,yi)为关键帧关节点处5×5邻域的光流信息的均值,P(xk,yk)为关键帧关节点坐标,P’(xi,yi)为非关键帧关节点坐标.
2 实验结果及分析
2.1 实验设置
本文主要利用Caffe[17]框架搭建基于光流的快速人体姿态估计算法框架与Cao等[8](Caffe)的算法对比(在 Intel i5,8 G 内存,单张 GTX 1070 的机器上测试).

图4 Flownet2-c 算法效果
实验对两个公开数据集进行测试,分别为:(1)OutdoorPose 数据集,该数据集由 Ramakrishna 等[18]提出,共包含 6 段视频序列,约 1000 帧已标注人体各部件真实值的图像.(2)HumanEvaI数据集,该数据集由 Sigal等[19]提出,本文采用 S1_Jog_1_(C1),S1_Walking_1_(C1),S2_Jog_1_(C1)中各 150 帧进行验证.以上两个数据集中包含丰富的人体自遮挡.对于1.2.1中掩模系数取0.4,该系数越大姿态估计速度越快,准确度相对越低;反之,姿态估计速度越慢,准确度相对越高.
本文采用每秒处理的帧数(帧率:fps)评估算法检测速度,利用PCP 评价标准[20]来评估算法对于人体各部件的估计准确度.相关定义如下:
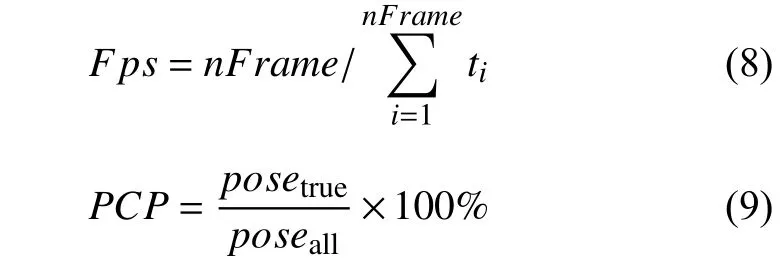
其中,Fps为每秒处理的帧数 (帧率),nFrame为测试视频的帧数,ti为第i帧的检测用时,其中包括利用Flownet2-c 计算两张图片 (分辨率:640×380)之间的光流信息 15 ms.poseture为检测正确的关节点数量,poseall为测试视频中所有的关节点数量.PCP评价标准规定当估计的所有部件端点到其对应真实值端点的距离小于部件长度的一半时,则认为该部件被正确定位.其中,PCP值越大表示对人体各部件的估计准确度越高.
2.2 结果分析
表1为本文算法与Cao等[8]的算法在不同场景下检测帧率及准确度的比较表.从表1可以看出本文基于光流的快速人体姿态估计算法与Cao等[8]的算法在检测准确度差异不大的情况下,有效的提升检测速度.其中在OutdoorPose数据集上,本文算法较Cao等[8]的算法在检测准确度上提升1.3%,检测帧率提升87.5%;在HumanEvaI数据集上,本文算法较Cao等[8]的算法在检测准确度下降1%的情况下,检测帧率提升91.8%.
如图5所示为Cao等[8]的算法与本文算法在上述两个数据集上复杂环境 (包含静态复杂背景、肢体遮挡等)下的部分姿态估计效果图,其中第一列图5(a)、图5(b)、图5(c)为 Cao 等[8]的算法的部分检测结果,第二列图5(d)、图5(e)、图5(f)为本文算法的部分检测结果.

图5 部分姿态估计效果图
如图6所示为上述两数据集的部分图片及本文算法的检测效果图.由图5的测试图片可知,Cao 等[8]的算法在复杂环境下可能会检测失败,而本文算法中非关键帧的姿态信息由关键帧姿态信息及两帧之间的光流信息预测得到,由图5可知在复杂环境下本文算法较原算法在一定程度上可增加人体姿态检测的检测性能.上述结果说明作者提出的加速算法较原算法在平均检测准确度略有提升的情况下,能够利用视频帧间的时间相关性,有效的提升处理速度,降低计算复杂度.

图6 数据集部分效果图
3 结论与展望
为了降低深度学习领域人体姿态估计算法的计算复杂度,本文提出了一种基于光流的快速人体姿态估计算法.该算法将视频分为关键帧和非关键帧分别处理,利用光流场将关键帧人体姿态信息传播到非关键帧,将高计算复杂度的人体姿态估计算法的计算复杂度转移到低计算复杂度的光流信息的计算过程中,同时提出自适应关键帧检测算法及融合算法,确定关键帧位置,防止光流预测不准确等问题.实验表明当光流算法的计算复杂度低于对关键帧的人体姿态估计算法时,本文方法可以在检测效果与原算法差异不大的情况下,有效地降低人体姿态估计的计算复杂度,提升检测速度.在今后的工作中应该进一步考虑如何高效的选取关键帧,进一步对算法进行加速.

表1 人体姿态估计帧率及估计准确度比较
猜你喜欢
学习月刊(2022年6期)2022-12-18
沈阳航空航天大学学报(2022年3期)2022-11-08
导航定位学报(2022年5期)2022-10-13
导航定位与授时(2022年4期)2022-08-05
现代计算机(2022年4期)2022-04-24
小型微型计算机系统(2021年12期)2021-12-08
铁道机车车辆(2021年2期)2021-05-21
沈阳航空航天大学学报(2020年6期)2021-01-27
导航定位与授时(2020年4期)2020-07-29
扬州大学学报(自然科学版)(2019年2期)2019-08-12
