
基于相似路径的位置隐私保护方法①
2019-01-07 02:40孙小婷
计算机系统应用 2018年12期
解 瑾,孙小婷
(中国石油大学(华东)计算机与通信工程学院,青岛 266580)
近年来,随着科技的不断发展,基于位置的服务(Location Based Service,LBS)作为移动互联网应用得到越来越广泛的传播,为人们生活提供了便利.但是由于LBS服务器是通过获取用户位置向用户发布相应的查询信息结果,这就导致了用户在享受位置服务的同时,也更容易遭受个人位置隐私信息泄露的风险.
现阶段位置隐私保护大致分为两部分:基于快照LBS的位置隐私保护和基于连续LBS的位置隐私保护.快照LBS是指用户向位置服务提供商发出单次LBS请求,获取相应查询结果.连续LBS[1]是指用户按照一定频率将自己的位置信息周期性的发送给LBS服务器,LBS服务器通过用户周期性的位置信息和搜索内容,实时将最新的结果返回给用户.然而,在连续查询过程中某些可以关联推断出的背景因素结合特定场景可能会给用户带来隐私威胁.如图1,用户A在连续发送三次LBS请求时,分别处于三个不同匿名集{A,B,C,D}{A,E,F,G}{A,H,I,J},攻击者以根据用户的轨迹关联重构用户A的过程轨迹.针对此类问题,文献[2]首次提出了KAA匿名算法,保证匿名用户在n次查询之后还保持在初始匿名集中.这也就要求在构建连续查询匿名集时,需要尽可能的将用户附近运动趋势相同的匿名用户加入到匿名集中,以避免推断攻击.
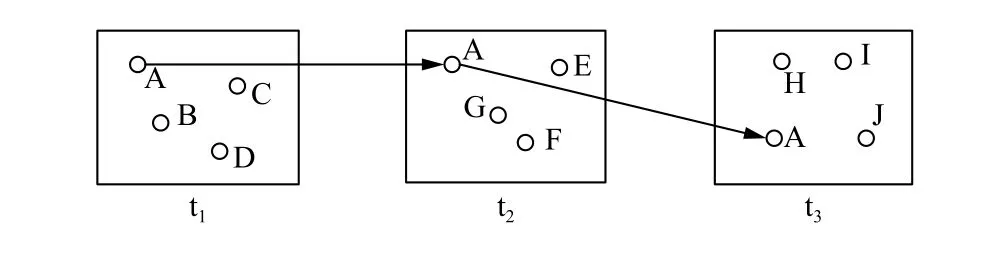
图1 连续 LBS 请求轨迹过程
目前,现有连续LBS请求中随机生成的虚假位置大多忽略攻击者已知的地理背景信息[3]和真实用户的运动模式.即使用户采用了一定的匿名方法保护位置隐私,攻击者还是可以通过相应背景知识攻击用户位置隐私.针对现有连续LBS请求形成虚假轨迹可信性过低造成的位置隐私泄露问题,提出了一种更加真实的相似路径形成算法,主要工作如下:
(1)利用网格单元对历史用户请求密度进行划分,通过每次采样时刻时真实用户周围的历史用户请求密度计算相对请求概率,使匿名组的熵达到最大,从而切断请求与位置间的联系.
(2)通过真实用户运动轨迹的方向、速度对相似轨迹集合建立约束,关注用户移动位置间的时空相关性,使其更加贴近真实用户运动轨迹以达到位置隐私保护目的.
本文第1节讲述相关工作,第2节讲述本文研究的预备知识,第3节讲述LPBSP位置隐私保护方法,第4节分析方法的安全性,第5节讲述本文实验结果及分析,最后第6节总结.
1 相关工作
1.1 抑制法
基于轨迹数据抑制法的隐私保护技术是指在真实用户轨迹中抑制某些用户的敏感信息,使攻击者无法将其与用户相关联,从而达到隐私保护的目的.Gruteser等[4]将地图上的地理区域划分成敏感区域和非敏感区域,通过延迟或抑制敏感区域中真实用户的位置更新信息来保护位置隐私.文献[5]通过MASKIT系统通过过滤保护用户位置隐私的上下文信息流进行隐私检查,从而限制攻击者获得用户的敏感位置信息.在匿名过程中只考虑状态的抑制,隐藏会导致隐私泄露的应用程序.然而,单纯的抑制法通过抑制敏感位置或访问频次高的数据进行位置隐私保护,实现简单但是信息丢失率较大.
1.2 历史数据泛化法
历史数据泛化法会引入可信的第三方,将轨迹信息中的采样点泛化成对应的匿名区域,以达到隐私保护的目的.泛化技术可分为空间泛化技技术和时间泛化技术[6].空间泛化是指在空间区域范围内降低真实用户的位置精度,从而增加位置区域上的不确定性.Wang等[7]为确保用户在每次提交LBS请求时构造的匿名区中包含的匿名用户是相同的,提出了一种基于贪心算法的匿名区构造方法,但这样会使匿名区面积随着查询次数的增加而增加,造成严重的通信和计算开销.Pan X 等[8]提出了一种 ICliqueCloak 的隐身算法,在连续状态中,采用位置k-匿名性和隐身粒度作为隐私度量,划分区域候选集合,当用户发送请求时,可以快速识别并生成相应隐藏区域.2013 年 Latha K[9]在 IClique Cloak的基础上考虑与用户位置相关的处理延迟和匿名化成本,提出KRUPTO算法,增加匿名区域覆盖形成最大团.
时间泛化是指在增加时间范围内用户精确位置的不确定性.Hwang RH[10]提出r-匿名机制用来模糊用户真实轨迹,将k-匿名与s-路段合并,引入时间混淆技术打破用户进行LBS请求提出的时间序列,运用模糊过程的随机性提供轨迹隐私保护.Palanisamy[11]在路网结构中使用mix-zone模型,使k个用户在混合区等待时间相等,并打乱用户进出混合区的关联顺序,以确保隐私保证.历史数据泛化法对实时性要求很高.
1.3 假数据法
假数据法多指利用k-匿名技术[12,13]向真实用户运动轨迹中添加假数据,通过生成k–1条假轨迹,将其一起发送给LBS服务器,以达到匿名效果.假数据的添加可充分考虑现实环境约束,由用户定义虚假数据产生方式,从而提出更加适用于用户的特定需求位置隐私保护算法.其中,Kido[12]等针对用户在地理环境的分布情况利用普遍性,拥挤度和分布均匀性三方面设计MN和MLN算法,首次提出添加假位置达到隐私保护的目的.Gao等[14]提出了用于参与式感知的轨迹隐私保护框架,从图论的角度出发,提出考虑时间因素的理论混合区模型.Dong等[15]考虑用户个性化隐私需求,通过短期位置暴露概率、长期轨迹暴露概率、轨迹偏移距离、轨迹局部相似度和服务请求概率等五个参数让用户进行自定义生成虚假轨迹,但此方法没有考虑攻击者背景信息.Ye AY等[16]通过可信的第三方将伪查询插入真实查询中,防止从用户标识到查询内容的反向映射.值得注意的是,在添加假轨迹时要保证添加的假的干扰数据不能对真实轨迹产生严重后果.
本文提出的相似轨迹LPBSP方法可以更好地符合真实用户轨迹模式,使相似轨迹在地图上分布更加合理,在一定程度上避免了推理攻击和最大移动边界攻击.
2 预备知识
2.1 系统结构
本文提出的基于相似路径的位置隐私保护方法(LPBSP)系统采用中心式服务器结构,包括移动终端、可信第三方匿名服务器(TTP,Trusted Third Party)以及LBS服务器三部分组成,系统架构如图2所示.其优点在于具有用户全局信息,隐私保护程度高、移动终端和TTP间的通信和计算开销较少.
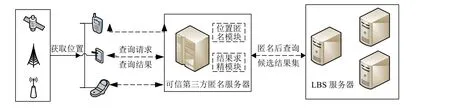
图2 中心服务器系统结构
移动终端中的GPS模块获取移动用户的自身位置坐标,将查询请求发送给TTP;经过TTP中的位置匿名模块做匿名处理生成相似轨迹,并将查询请求发送给LBS服务器;LBS服务器根据查询后选结果将候选集发送给TTP,通过TTP的结果求精模块过滤精确结果并把结果返回给用户.
2.2 相关定义
本文采用基时空网格划分方法,将城市地理区域预划分为网格区域,每个网格都有自己的唯一标识gidgid.
定义1(保护的用户属性).P={ID,li,vi,ti,POI},ID为用户请求LBS服务的唯一标识符,li为用户所在的位置信息,vi为用户历史速度向量集合,ti为采样时间信息,POI为用户所请求的兴趣点.
定义2(k-匿名组).G{u}={k,m},k表示用户需要的匿名轨迹数量,k值隐私保护效果越好.m表示当前匿名组内的用户数量.
定义3(整体轨迹方向偏移度).表示采样时刻ti真实轨迹和相似轨迹的偏移情况.假设用户真实轨迹为,ti表示采样时刻,表示用户在时刻所处位置.假设真实用户在ti时 刻的位置为li=(xi,yi),则相对上一位置轨迹偏移向量为.相似的,相似轨迹在ti时刻的轨迹偏移向量为.则在ti时刻,真实轨迹Tr和相似轨迹FTj的余弦相似度可表示为:
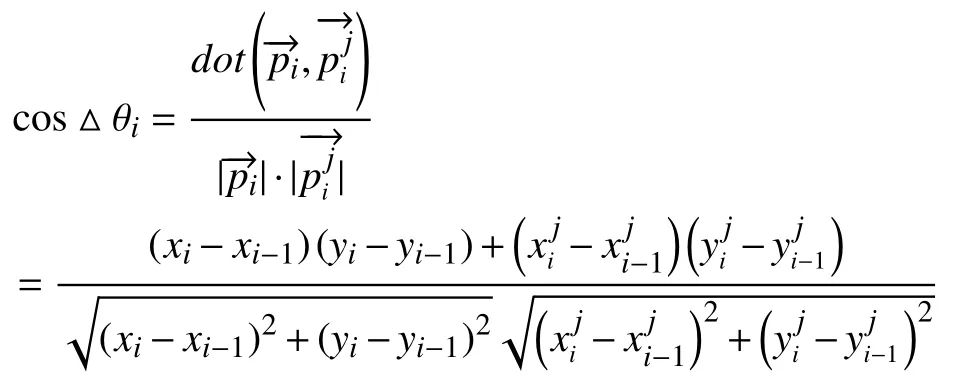
所以

在整个采样阶段相似轨迹FTj相对真实轨迹Tr的偏移角度序列为P={△ θ1,△ θ2,···,△ θn}.那么,真实轨迹Ti和相似轨迹FTj的轨迹方向偏移度d·sim为:

显而易见,d·sim∈[0,1],越趋近于 0,设置的相似轨迹整体相对真实轨迹偏移度越小,整体走向越相似,从而更难被区分.
定义4(局部速度相似度).受真实环境影响,用户移动速度不是一成不变的.假设真实用户移动速度序列为V={v1,v2,···,vn}在ti时刻的速度为vi,数值大小为|vi|,则相应的相似轨迹FTj在ti时刻的速度数值大小为.那么,在ti时刻轨迹间的速度相似性v·sim为:

可知v·sim∈(0,1],越趋近于1,相似轨迹在第i个采样时刻的速度相似度越高,在速度上越接近真实轨迹.
定义5(匿名区域ASRi).根据ti时刻形成的k- 匿名组内真实用户ui和k-1个虚假用户坐标组成的最小矩形区域.
3 LPBSP 位置隐私保护方法
3.1 初始位置生成阶段
在连续请求状态下,轨迹方向偏移角度d·sim,生成的虚假轨迹在极端情况下可能会出现在某个采样时刻集中在一起的情况,从而造成轨迹间距过小匿名效果不佳,如图3(a).为保证生成的虚假轨迹在连续状态下更加分散的匿名效果,需要在初始位置生成阶段进行一定的处理.通过设置每个用户之间的距离限定,扩大初始匿名区用户之间的间距,使初始匿名位置点更加分散,如图3(b).
3.2 候选位置筛选阶段
若在某个采样点时刻匿名区域内用户数量发生了很大的变化,则很有可能是真假用户的位置数据进行了某种变化,从而增加真实用户位置泄露风险.因此,为避免虚假位置点急剧变化情况,在生成候选位置点时需要对其进行筛选处理.本文采用历史位置点和生成虚假位置点相结合的方式,以用户密度为基础,使真实轨迹和相似轨迹在采样时刻更加均匀,提高匿名效果.具体过程如下:

图3 初始位置生成状态
1)TTP记录每个网格内用户请求密度,并预先设置密度阈值 σ.对用户请求密度低于 σ的区域剔除,因为这些区域往往代表真实环境中不可到达区域(如湖泊,森林等).
2)在进行候选位置筛选阶段前,需要根据预设参数计算相似轨迹生成区域.假设在ti时刻真实用户在li=(xi,yi)的速度为vi,根据TTP预先设置的d·sim和v·sim确定生成区域范围.以真实用户所在网格的请求密度为标准,请求密度大的区域代表历史用户在该区域中进行频繁的LBS请求,则在该区域中发生请求的概率相对较大.在ti时刻根据用户所在位置li=(xi,yi)判断此网格的历史请求密度为真实用户所在网格内用户请求数量,Sc:网格面积),当TTP提交的k-匿名组内成员的密度相等时,不易攻击者发现.因此用户需要获得生成区域范围内所有网格用户请求密度,然后进行排序.在排序列表中,选择与真实用户所在区域请求密度相似的网格,并在此基础上随机确定数量为k个历史用户作为候选对象集Ci,每个历史用户代表一个实际位置点.将这些用户的请求密度进行归一化,可得到在ti时刻候选对象集Ci相对请求概率:
真实用户相对请求概率:

虚假用户相对请求概率:


为使每次采样时刻匿名组用户所在区域中请求密度更加均匀,我们需要一个衡量标准,在理想情况下当真假用户所在区域密度完全相等时,熵的值最大有:

当H的值越趋近于Hc时,历史用户请求分布越均匀,攻击者越无法将真实用户从匿名用户中分离出来,此时得到的Hi的匿名组用户最佳:

确定此时候选对象集Ci的匿名区域范围ASRi.
CLS算法如下:

算法 1.CLS 算法输入:每个单元格内历史用户请求密度,时刻用户位置坐标ti tili=(xi,yi)输出:时刻 ,候选对象集 ,匿名区域HmaxCiASRi初始化 ;1.将区域中各个单元格中的用户请求密度进行排序;2.剔除不可到达区域;m=0,H=0 3.从排序列表中选取与真实用户请求区域密度相似的 个候选点;j≤k-1 3k4.while //随机从中选取 个候选点ti2k5.当 时刻虚假用户位置数量小于k–1时;ti6.计算 时刻的 ,和 ;Hi qiqj iHi←-■■■■qil og2qi+k-1∑og2qji qjil■■■■j=1 7.进行 更新;8.end while Hmax 9.选取 ;ti10.确定 时刻熵最大的最佳候选对象集 ;Ci Ci11.确定候选对象集 的匿名区域 ;ASRi ASRi12.输出 .
3.3 相似轨迹生成阶段
LPBSP方法中相似轨迹是TTP根据真实用户的当前位置和前一次匿名区域内所有的匿名用户为基础,通过预先设置的参数对生成的虚假轨迹进行一定约束,使设置的相似轨迹更加贴近真实用户轨迹状态.在采样时刻,用户发起连续LBS请求,真实用户u在ti时刻以位置li=(xi,yi)发起匿名请求,则在[ti-1,ti]时间段内用户u的轨迹距离为s=vi△t,偏移向量为.虚假用户uj在ti-1时刻的位置为TTP根据预先设置的轨迹方向偏移度d·sim对要生成的相似轨迹进行最大偏移设置,确定最大偏移角△θi,用户ui在ti时刻的行驶速度 |vi|;根据局部速度相似度v·sim确定相似轨迹与真实轨迹的相似速度.在候选位置生成区域ASRi内选择合适位置作为t时刻的虚拟位置点,TTP获取此时虚拟点坐标连接作为虚假用户在[ti-1,ti]时间段相对真实用户ui的相似轨迹.
DVS算法如下:

算法 2.DVS 算法输入: ,,T={FT1,FT2,··,FTj,··,FTk-1,Tr}P={ID,li,vi,ti,POI}d·simv·sim输出:相似路径集合 设置中间集合U=null ui1.if is fresh //出现用户请求 ;ui ui2.将 压入集合U中;Ci3.从 中挑选 并计算每一个 加入后 面积;ASRi uijuijASRi4.If < ω // ω 为预设值uij5.将uji加入集合 中;6.end if 7.end if d·sim U8.if (satisfy (,)&& (,)//对集合U中的每个虚假用户 进行 && 期望范围检查9.else uiuj iv·simuiuj i uj id·simv·sim10.将不符合的 从集合 中删除;|U|uj iU12.if 11.计算U内用户数量 ;|U|≥k13.从中随机选取 个;14.end if 15.end if ti k16.确定 时刻真实用户 的用户轨迹 和虚假用户 的相似轨迹.uiTruj i FTj
重复步骤2到16直到ui停止进行LBS请求.
4 安全性分析
针对轨迹隐私保护的攻击者可以根据发起连续LBS请求的时间序列归纳用户大致行动方向,根据相应已知条件发起推理攻击、最大移动边界攻击等攻击模式.这是由于真实连续LBS的请求位置序列有一定的上下文联系,攻击者可以分析真假轨迹的差异性推断出真实用户.
证明:在ti时刻,真实用户ui被识别的概率pi{ui∈,此时,根据公式 (3)可得真实用户相对请求概率qi,可知qi与ui所在区域请求密度di有关,有;相似的,ti时刻虚假用户被识别的概率.若,可保证,此时Hi=Hc.
针对最大移动边界攻击,本文以真实用户运动方向和速度为基础,由用户自定义参数范围,充分考虑真实情况虚假位置的不可到达性,通过速度和方向偏移相似程度限制抵抗最大移动边界攻击.
5 实验结果及分析
本文在 Windows sever 2008 服务器下采用 Java 语言开展 LPBSP 实验,实验采取 Thomas Brinkhoff路网生成器生成Oldenburg城市路网中的用户及兴趣点的实验数据,并与文献[12]做对比实验,验证本文LPBSP方法在匿名成功率、执行时间、熵三个维度上具有一定的贡献.LPBSP试验参数如表1所示.

表1 LPBSP 实验默认参数
在匿名成功率方面,如图4所示文献[12]基于虚假路径的设置,只要有匿名需求便可构建虚假用户进行协作匿名,没有考虑到虚假用户的真实性,假如真实用户在海边,构建的虚假用户很可能会在海里,从而导致匿名效果的损失,而本文LPBSP方法是基于用户查询的历史数据来构建协作匿名,在真实用户发起查询时,周围的历史数据可能会存在不足而导致匿名组构建失败,因而在匿名成功率方面略低于文献[12],但是本文方法仍然具有较高的匿名成功率.
在方法执行时间方面,本文LPBSP方法由于需要获得生成区域范围内所有网格用户请求密度,然后进行排序,时间复杂度为nlogn.如图5所示,文献[12]由于不考虑其他因素,仅以构建虚假路径为核心,因而执行效率高,执行时间较短.本文方法由于在构建协作用户的虚假路径时综合考虑了协作用户真实性,协作路径相似性等诸多因素,因而在执行时间方面略长与文献[12],但是总体来看执行时间仍旧保持在较快的速度,毫秒的差距不影响用户体验.

图4 匿名成功率
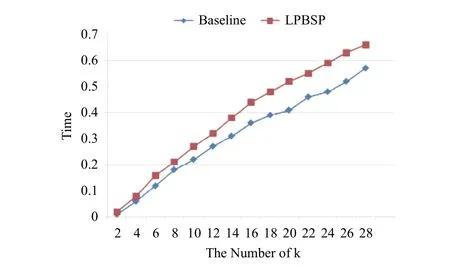
图5 执行时间
在探究位置隐私保护度方面,如图6所示,本文采用熵的形式与文献[12]进行对比实验,通过实验结果图所示,可以发现,熵随着k值的增大而逐渐增大,本文LPBSP方法相较于文献[12]中具有一定优势,原因在于本文考虑了真实用户的历史位置数据进行匿名,并对用户的轨迹及移动速度进行了相似度的设置,相较于文献[12]单纯的构建虚假路径更具有真实性,使得匿名虚假轨迹与真实轨迹具有较高的相似性,因而具有较好的隐私保护度.当然相对于理想状态熵的最优值log2k还是有一定差距,仍需要进行继续的优化.

图6 熵
6 结论与展望
本文针对连续查询位置隐私保护问题中可能存在的因协作用户交叠而暴露真实查询用户的问题,提出了基于相似路径的位置隐私保护方法(LPBSP),首先采用用户历史数据构建初始协作匿名组,然后利用用户历史位置数据、速度及轨迹相似度等对协作路径加以约束,使得协作路径更具有真实性,加以迷惑攻击者,最后通过实验验证本文方法虽然在匿名成功率、执行时间上略逊色于文献[12],但是在位置隐私保护度方面有了较好的应用,在研究位置隐私方面有一定价值.
猜你喜欢
现代电子技术(2022年11期)2022-06-14
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
小学阅读指南·高年级版(2014年2期)2014-05-27
