
基于概率神经网络的手写苗文识别研究
2019-01-04 08:09曾水玲
大理大学学报 2018年12期
丁 李,曾水玲
(1.吉首大学物理与机电工程学院,湖南吉首 416000;2.吉首大学信息科学与工程学院,湖南吉首 416000)
湘西苗族创造了 3种苗文〔1〕,“板塘苗文”“老寨苗文”和“古丈苗文”〔2〕。方块苗文是一种借源文字,与汉字的结构和造字法上基本一致,造字法主要有形声和会意,双音符的不多,象形成分极少,大量地借用汉字标音。方块苗文用来记录和创作苗歌,苗歌主要是表达苗族人们在生产、生活、农耕、风俗传统等各方面的情怀,留存下来的苗歌手稿有十几万字,为我们研究苗族的民族历史、民族风俗和民族文学提供了宝贵的文字资料。
在信息化时代,专家需要将这些珍贵的苗文手写文字的纸质载体录入进计算机进行保存和传播,对于文字的识别方法,前人已经探索出针对各种文字的识别体系〔3-7〕,而苗文方面,也有学者为苗文便于在计算机中生成和显示,提出了方块苗文动态构造方法〔8〕。随着数字化社会的发展,传统的手写纸质载体需要转型以适应现代化需要。为更高效地进行苗文的录入和传播,开发关于苗文的光学字符识别(optical character recognition,OCR)成为可供选择的方向。所以,开发针对于苗文的识别系统是十分迫切和重要的工作,传统的投影识别法虽然能达到识别苗文的目的,但输入的识别特征矩阵巨大,虽然训练效果不错,但预测结果时,存在有过拟合的问题,使得系统的识别潜力没有完全开发出来,本文工作一方面验证PNN神经网络对于方块苗文图像识别工作的可用性,另一方面就是为了通过简化特征矩阵的办法来挖掘识别系统神经网络的潜在能力。
1 文字图像预处理
手写苗文文字样本经过扫描仪进入计算机后,因纸张的厚度、光洁度和取样设备质量的不稳定都会造成录入后的数字图像文字畸变,形成粘连、笔画中断和图像噪点等干扰,所以在进行文字识别之前,务必要对带有噪声的文字图像进行处理。图像预处理方法有许多经验成果〔9-10〕,其大体步骤包括文字图像大小归一化、灰度化、二值化、规范化等等。
1.1 文字图像灰度化通过外设采集的图像通常为彩色图像,彩色图像会夹杂一些干扰信息,灰度化处理的主要目的就是滤除这些信息。定义在RGB空间的彩色图像,图像内每一个像素点的颜色由Red、Green、Blue 3个分量共同决定。灰度化其实质是将原本由三维描述的像素点,映射为一维描述的像素点。灰度化方法有分量法、最大值法、平均值法、加权平均法。加权平均法的权值是根据人体生理学角度(人眼对绿色最敏感,对蓝色最不敏感)所提出的,具有最理想的灰度化效果,公式权值如下:
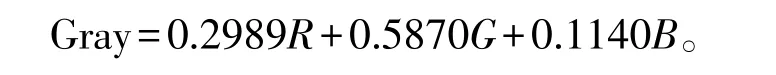
本文采用加权平均法来处理原始图像,处理结果见图1。

图1 灰度化后的图像
1.2 文字图像二值化经过灰度处理的彩色图像还须经过二值化处理将文字与背景进一步分离开。所谓二值化,就是将彩色值图像信号转化成只有黑(0)和白(1)的二值图像信号。二值化效果的好坏,会直接影响灰度文本图像的识别率。二值化处理的具体经验有很多〔11-12〕,方法大致可以分为局部阈值二值化和整体阈值二值化。本文参考基于k中心点聚类的图像二值化方法〔13〕,采用局部阈值二值化,将方块苗文图像分割为互不相交的若干个w×w的小窗口,在每个窗口中求得所辖像素的灰度平均值,经添加惩罚项后作为初步阈值进行二值化处理,继而对各小方块进行二值化变换,各个阈值的计算公式如下:
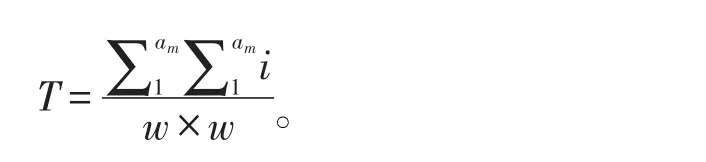
若块内的灰度值大于阈值T,则把该点的值置为1,否则将该点的值置为0,将图像二值化能更进一步减少图像中的信息量,减少无关信息的干扰。将灰度图像二值化后结果见图2。

图2 二值化处理后的结果
1.3 规范化规范化主要分为位置规范化、大小规范化和笔画细化处理,位置规范化和大小规范化在纸质文字转化为数字图像时,就已规范化,每个单体文字图像像素为长宽各130像素。对于细化方面,细化是指对于一个给定的模式图像,抽取其“中心骨架”的过程,细化算法可分为非迭代算法和迭代算法,而迭代算法又分为串行算法和并行算法,本文的细化处理是在不破坏原有结构配置和给定笔画连接位置关系的基础上,采取迭代扫描并删减边界像素点来完成。笔画细化方法中经典的有基于标记的并行细化算法〔14〕,改进的有自动矢量化算法〔15〕。细化后的文字消减了很多手写字体的个性化特征,为特征提取创造了有利条件。
在计算机图像处理过程中,用黑底白字来处理矩阵更加方便,所以先将二值化后的图像取反,取反后结果见图3,之后再利用细化算法将其细化,具体方法:使用一个包含9个像素的3×3模板,9个像素点只取值0或1,因此模板有29=512种形式,给予每个模板一个编号0~511,编号等于模板中的像素加权和,像素权重见图4。

图3 取反效果图
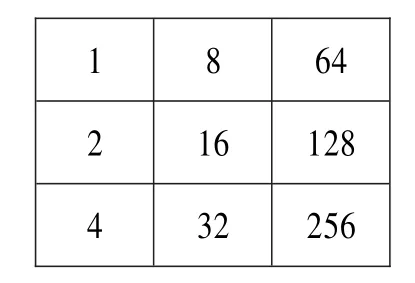
图4 像素权重
把模板分成8个方向,轮流使用8个方向的模板,消去最外层像素点,不断循环,直到剩下“骨架”为止。细化后结果见图5。
图5 笔画细化效果图
2 文字特征的提取
特征提取即对某一模式的组测量值进行变换,以突出该模式具有的代表性特征的一种方法。常见的文字特征类型分为统计类特征和结构类特征,统计类特征有像素点个数、灰度值统计类别等,而结构特征是如边缘、角、区域、脊等代表性特征。
本文着重研究统计类特征中的像素特征,单个文字样本的二值化矩阵通过规范化处理后,长和宽都为130像素,通过统计投影在行列的白点(1)数值个数能够在一定程度上代表文字的特征属性。
2.1 经典投影法经典的特征提取投影法是将文字图像左下角置于直角坐标系原点,统计图像中各种特性的像素点分别在X、Y轴上的投影数量,再以两坐标轴上的特征点数量来组成特征矩阵,此矩阵的维数至少等于图像X、Y轴上像素之和,本文中经典投影法的维数应是X轴上130像素加Y轴上130像素再加上一个标志种类的特征,一共261维特征向量。具体步骤如下:
1)对方块苗文图像的X轴和Y轴平均划分成n=130份。
2)统计x=1的直线与方块苗文二维表达式f(x)的交点个数rx1,统计x=2直线与f(x)的交点个数rx2,依次循环,直到统计到rx130停止。
3)依照步骤2)统计ry1到ry130。
4)构建特征矩阵:T130=[I,rx1,rx2,…,rx130,ry1,ry2,…,ry130],其中I为类别标识,定义为文字的类别。
2.2 改进后的投影法相对于文字的特征提取来说,图像没有其他图像那么复杂,像素点中的信息相对更加简化,采用经典投影法不但浪费计算机资源,甚至可能取得相反的效果即因系统过拟合导致识别率更低。针对方块苗文的像素特点,本文将传统的投影法特征提取加上一个对像素的组别划分,不仅能简化特征维数,更能减少资源的浪费。
在归一化后的方块苗文图像上,像素为130×130的图像,为了能够无余量完全划分,本文采用最大公约数的划分方式,即根据130长宽的像素点,将其横纵轴的130像素点平均分成65组(2像素点为一组)、26组(5像素点为一组)、13组(10像素点为一组)和2组(65像素点为一组)4种划分方式。见图6。分组后统计每个组内的白点(1)个数,即可组成特征向量。具体步骤如下:
前3步与上述步骤相同,不再赘述。
4)设2个像素点为一组,计算Rx1=rx1+rx2,Rx2=rx3+rx4,…,Rx65=rx129+rx130,以及Ry1=ry1+ry2,Ry2=ry3+ry4,…,Ry65=ry129+ry130。
5)构建特征矩阵T65=[I,Rx1,Rx2,…,Rx65,Ry1,Ry2,…,Ry65],其中I为类别标识,定义为文字的类别。
5像素点一组则以此类推,只须计算Rx1=rx1+rx2+rx3+rx4+rx5,Ry1=ry1+ry2+ry3+ry4+ry5以及统计T26=[I,Rx1,Rx2,…,Rx26,Ry1,Ry2,…,Ry26]即可。
根据上述步骤,最终得到T130,T65,T26,T13,T2共5种特征矩阵。

图6 各种像素组的分类
3 实验及结果分析
为了验证普通投影识别法的可用性和改进后的投影法具有更加优秀的识别性能,下面利用上述所抽取的各种特征矩阵,结合PNN神经网络,进行对比分析实验。
3.1 PNN神经网络方块苗文识别系统的建立概率神经网络(probabilistic neural networks,PNN)是一种基于Bayes分类规则与Parzen窗的概率密度函数估计方法发展而来的并行算法。这是一种训练快速、结构简洁的人工神经网络。
PNN神经网络是一种基于径向基函数网络发展而来的一种前馈型神经网络,它的理论依据是贝叶斯决策理论,其作为径向基网络的一种,比较适合模式分类。PNN的层次模型见图7。
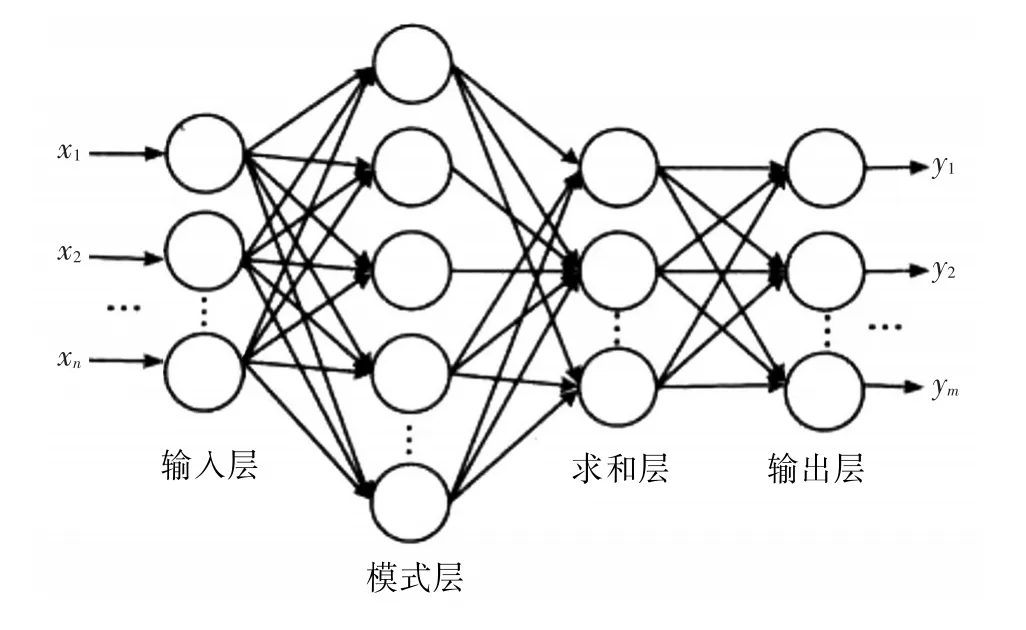
图7 概率神经网络基本结构
3.2 PNN神经网络与特征向量的结合PNN神经网络共分4层,即输入层、模式层、求和层和输出层。
输入层接收来自训练样本的特征,本文的特征向量是由预处理后样本图像的横纵坐标上投影的白点(1)的数目组成,根据像素分组的不同,特征向量维数也不同,比如2像素组,将第一行与第二行中总的白点(1)个数统计在一起,作为一个特征值,由于文字图像为130×130像素图,即对于行来说就有65个特征项,将纵向特征项也加入进来,就有130个特征项,最后还须加入一列表类别的标志量,则2像素组的特征向量即为131维向量,其他向量组以此类推。将特征向量传递给网络,其神经元的数量和样本矢量数量相同。
模式层计算输入特征向量与训练中各个模式的匹配关系,模式层神经元个数等于各个类别训练样本数之和,该层每个模式单元的输出为
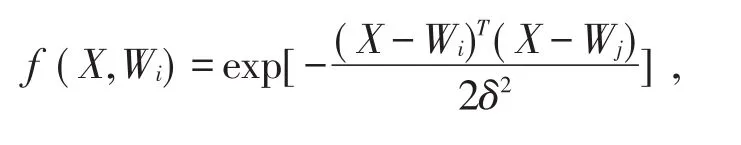
式中Wi为输入层到模式层连接的权值,δ为平滑因子。
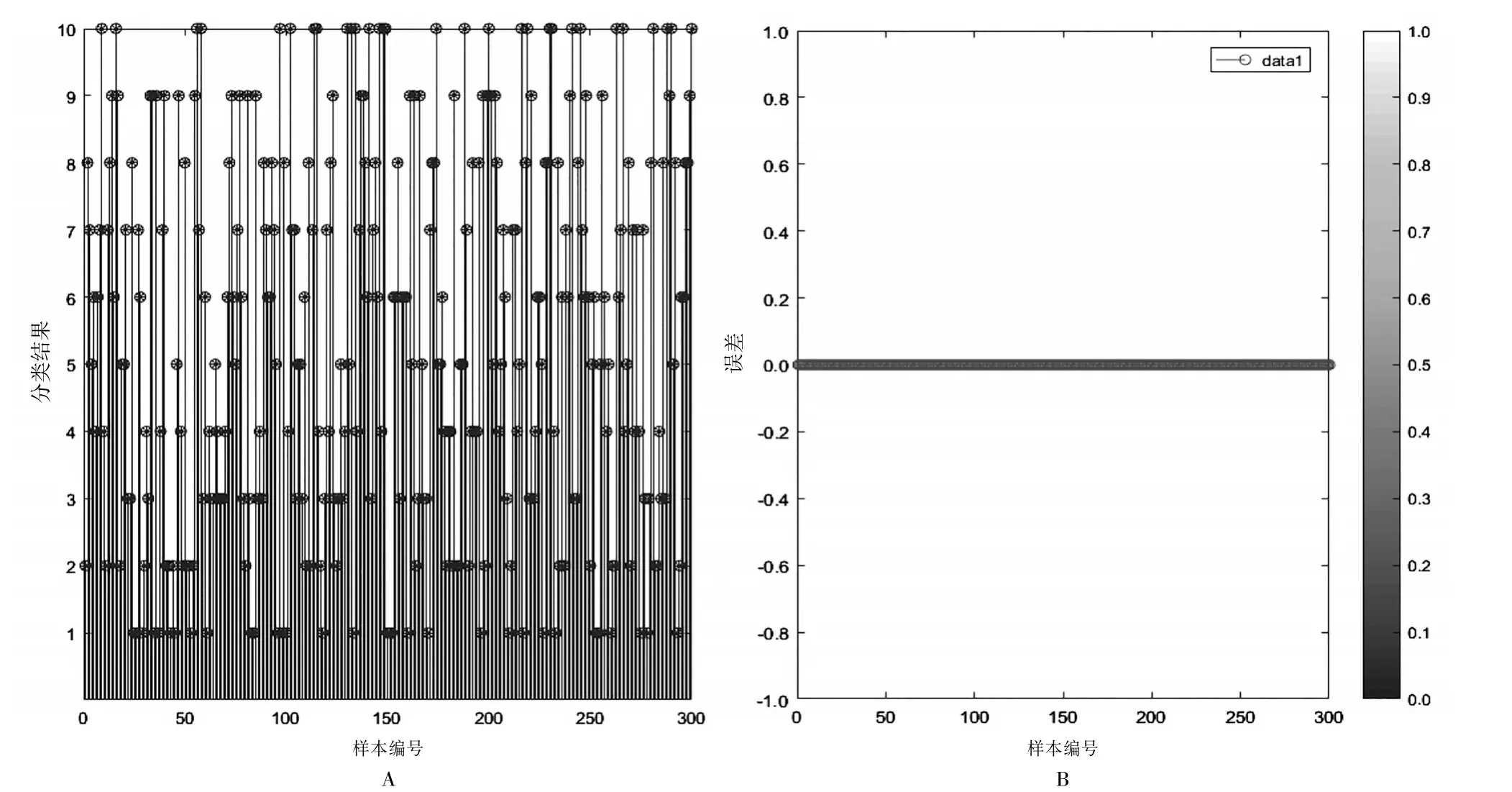
图8 PNN网络训练结果及误差图
第三层是求和层,是将属于某类的概率累计,从而得到文字类别的估计概率密度函数。求和层单元的输出与各类基于内核的概率密度的估计成比例,通过输出层的归一化处理,即能得到各类的概率估计。
输出层神经元是一种竞争神经元,每一个神经元对应一个文字的类别,输出层神经元个数等于参与分类的文字类别总数,它接收从求和层输出的各类概率密度函数,概率密度函数最大的那个神经元输出为1,即所对应的那一类即为待识别的文字模式类别,其他输出神经元值全为0。
3.3 网络的训练预测以及结果分析选取样本库中400个手写苗文字体共10种文字,其中300个作为训练样本,100个作为测试样本。在MATLAB中通过 net=newpnn(p_train,t_train,spread)函数进行概率神经网络的创建,其中p_train和t_train为抽取出的特征矩阵,多次测试后spread数值选取1.5能够很好地保证PNN网络神经元的一部分对输入向量所覆盖的区间产生响应,接着利用y=sim(net,p_train)函数进行已知数据的网络训练,利用y2=sim(net,p_test)进行未知数据的预测,net是构建的PNN神经网络,p_train和p_test分别是训练特征矩阵和预测的未知特征矩阵,网络的训练结果和预测结果见图8~9。
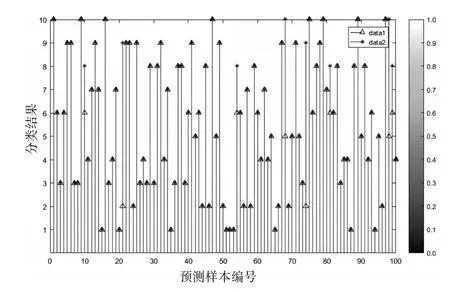
图9 PNN网络预测结果
从图8可知PNN网络的训练效果很好,训练预测值和实际值基本完全吻合,误差图上的训练误差更是为0,这得益于spread值的正确选择,过大或过小都会导致训练出现误差。
从图9可知,横坐标为样本编号,纵坐标为文字种类编号,在100个预测样本中,错误个数为8个。
经过多次测试运行,统计出平均识别率,得到在不同像素分类情况下PNN的识别率。见表1。除此之外,在以上结论的前提下(10像素组拥有最佳的识别效果)与PNN神经网络相似的BP神经网络以及LVQ神经网络也使用相同的特征矩阵进行了识别工作,与其进行了横向对比。为了对比的公平,BP神经网络和LVQ神经网络将采用相同的10像素组特征矩阵进行训练和分类。

表1 经典组与各个像素分组的识别率(%)
对于BP神经网络而言,10像素组的特征矩阵与PNN相同,是一个27维的特征向量,所以BP神经网络输入端设置为27个输入神经元,输出端和PNN神经网络一样设置为10个神经元(10个文字种类)至于隐含层,根据经验公式取10较为稳定,学习率取0.1,在和PNN相同的400个文字样本库中选择300个进行网络训练,剩下100个作为测试样本,根据以上主要参数进行BP神经网络的构建、训练和识别。
对于LVQ神经网络而言,同样是在400个样本中选择300个进行网络训练,100个作为测试样本,输入依然是27维特征向量,输出为10个种类的文字,迭代次数设置1 000,学习率设置0.01,训练目标最小误差设置0.06,根据以上主要参数进行LVQ神经网络的构建、训练和识别。
最终的对比见图10。
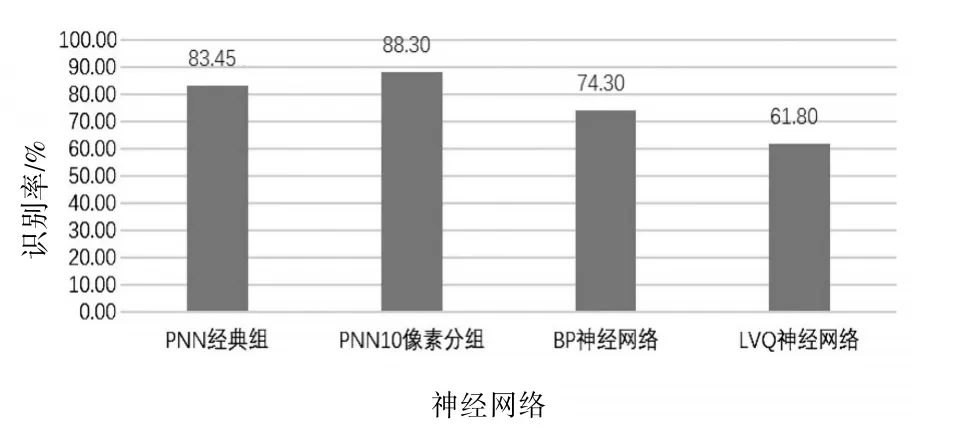
图10 改进前后的PNN神经网络以及其他神经网络的识别率对比
从表1中的结果来看,经典组有83.45%的识别率,说明PNN神经网络的预测功能用于方块苗文的识别是可行的。从其他分组的结果来看,130×130的样本图像大小下,实验了130像素的所有公约数分组,网格从密集到稀疏,识别率逐渐升高,10像素组达到最优,之后识别率又下降到最低,从表中看出表现最好的10像素组的识别率比经典组的识别率高4.85%,具有很可观的提升幅度,说明此种像素分类优化方案是可行的。图10中与其他两种神经网络的横向对比来看,PNN神经网络本身的识别效果是优于BP神经网络和LVQ神经网络的,通过此种优化方案,挖掘出PNN神经网络更多的识别分类潜力。
4 结论与展望
对于湘西方块苗文的计算机识别分类,本文基于OCR技术、图像提取处理技术、PNN神经网络以及MATLAB软件,针对提取的特征矩阵维数过大导致的限制了分类器的识别率问题,提出一套能提升分类器工作效果的解决方案——进行像素的分组,并探究了在不同像素组分类的情况下,PNN神经网络的训练结果和识别率的提升幅度,得到了最适合的像素组分类方式即10像素组分类方式,最大化平衡计算机资源与系统工作效率之间的关系。在接下来的工作中,我们一方面会继续苗文正确率提升的研究,并解决识别率高低起伏较大的缺点,探索更加具有代表性的文字特征提取方案;另一方面也会在优化计算机系统的识别工作效率上进一步探索,改进分类算法来提高文字的识别效率。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
高技术通讯(2021年3期)2021-06-09
现代电子技术(2021年1期)2021-01-17
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
上海大学学报(自然科学版)(2018年5期)2018-11-02
中国交通信息化(2018年3期)2018-06-13
电脑知识与技术(2018年35期)2018-02-27
自动化学报(2017年5期)2017-05-14
自动化学报(2017年11期)2017-04-04
