
基于分解的改进自适应多目标粒子群优化算法
2019-01-03 08:05高兴宝
复杂系统与复杂性科学 2018年2期
庞 锐,高兴宝
(陕西师范大学数学与信息科学学院,西安 710119)
0 引言
在许多实际问题中,往往需要同时优化多个相互冲突的目标函数,即多目标优化问题(Multi-objective Optimization Problems,MOPs)。在MOPs中,一个目标的优化往往以另一些目标的劣化为代价,所以其解集必为一组相互折衷的Pareto最优解。由于MOPs的复杂性,往往难以使用传统优化算法求解。不同于传统方法,进化算法(Evolutionary Algorithm,EA)是受自然界物种进化的启发而形成的一种随机优化算法,它采用基于种群的遗传进化产生后代个体,并通过优胜劣汰的自然选择进化种群。因此它具有更高的寻优效率、鲁棒性强、便于操作且为求解复杂优化及多目标优化问题提供了新途径。
上世纪末以来,许多学者通过模拟不同物种的行为提出了多种EA,如粒子群算法(Particle Swarm Optimization,PSO)[1]、蚁群算法(Ant Colony Optimization,ACO)[2]、人工蜂群算法(Artificial Bee Colony,ABC)[3]、差分进化算法(Differential Evolution,DE)[4]、免疫算法(Immune Algorithms,IA)[5]和萤火虫算法(Firefly Algorithms,FA)[6]等。这些算法为解决复杂优化问题提供了新思路并被广泛用于求解调度问题、组合优化和存货控制等实际问题[7]。特别地,作为一种模拟鸟群觅食行为的自然模型,PSO由于操作简单、收敛速度快,已被广泛应用于求解单目标优化问题,且对MOPs也有显著优势[8-18],因此基于PSO的多目标EA已成为优化领域的一个研究热点[19]。
近年来,研究者们相继提出了各种多目标粒子群优化算法(Multi-objective Particle Swarm Optimization,MPSO)。特别地,文献[8]引入Pareto支配概念确定PSO中粒子的个体最优和全局最优位置,首次提出了多目标粒子群优化算法(MOPSO)。基于MOPSO,文献[9]设计了一种新的变异算子。该算子在迭代初期让所有的粒子均参与变异,而随着迭代逐渐减小参与变异的粒子数,有效地增强了PSO的探索能力。为避免“群爆炸”,文献[10]提出了一种基于速度约束的多目标粒子群算法(SMPSO)。在进化过程中,该算法对所有粒子的速度加以限制,以防止粒子由于速度过快而集中涌向搜索边界。文献[11]将PSO与NSGA-Ⅱ[20]相结合,提出了非劣排序多目标粒子群优化算法(NSPSO)。基于非支配关系,文献[12]提出了一种求解MOPs的多目标综合学习粒子群算法(MOCLPSO)。由于种群中个体的适应度依赖于Pareto支配关系,上述算法可加快收敛速度,但仍需要设计相应的多样性保留机制来维持解集的多样性和分布性,且收敛性和解的分布均匀性之间的平衡仍有待加强。
MOEA/D是典型的分解算法,它将MOPs分解成若干个标量优化子问题进行求解[21]。受该思想的启发,文献[13]用PSO代替MOEA/D中的交叉算子,并对粒子的个体最优和全局最优位置进行更新,提出了一种基于分解的MOPSO/D算法。文献[14]引入一种重新初始化策略来维持种群的多样性,且从当前种群中选择粒子的个体最优和全局最优位置以节约存储资源,提出了dMOPSO算法。文献[15]提出一种基于目标空间分解的MPSO/D算法。该算法基于一组均匀分布的方向向量将目标空间分解成若干个子区域,且在每一子区域中仅保留一个最优解以保证所获解分布的均匀性。然而在每次迭代中,由于每一子区域仅保留一个解,因此这种分解方法容易造成部分优质解性能的丧失,难以处理复杂MOPs,且利用拥挤距离作为个体适应度的评价指标,计算复杂、收敛速度慢。上述基于分解的MPSO,虽然对部分MOPs有效,且比基于Pareto支配的MPSO,降低了计算复杂性,但在处理具有不连续、退化或多峰的复杂Pareto前沿面问题时,很难找到可均匀覆盖整个Pareto前沿面的解集。
此外,文献[16]用分解方法简化MOPs,并用非支配关系保证算法的收敛性,提出了D2MOPSO。文献[17]设计了一种基于两个局部最优解的多目标粒子群算法(2LB-MOPSO)。该算法从外部文档的非支配精英解中选取粒子的个体最优和全局最优位置,提高了搜索效率。结合PSO与DE,文献[18]提出了一种自适应的混合进化算法(HMOEA-AMP)。该算法用PSO更新进化种群,DE更新外部文档,但其计算复杂性高且收敛速度有待提升。
由以上分析,基于分解的更新策略更有利于维持种群多样性和解的分布均匀性,而基于Pareto支配的策略可以加快种群的收敛速度,提高算法的搜索效率。因此本文结合分解策略和Pareto支配策略,提出一种基于分解的改进自适应多目标粒子群优化算法(An Improved Self-adaptive Multi-objective Particle Swarm Optimization based on Decomposition,ISMPSO/D)。首先,在分解方法确保进化种群多样性的前提下,设计了新的适应度评价方法以自适应地调整每个父代个体的适应度值,让适应度值更高的个体尽可能多地产生后代,并将在竞争中获胜的优质后代解添加到父代候选解集中,增强了算法的寻优质量,提高了算法的收敛性;其次,在更新粒子时,从当前粒子的邻居或邻居外随机选择个体最优和全局最优位置,并对后代解进行变异,增强了种群多样性,避免了算法陷入局部最优;最后,引入外部文档作为候选的输出种群,并采用拥挤距离维持其多样性,从而充分结合了分解方法和Pareto支配的优势,增强了算法处理复杂问题的能力。通过12个多目标测试函数的仿真实验,并与5种多目标优化算法的比较,说明了所提ISMPSO/D算法的有效性。
1 有关算法简介
1.1 多目标优化问题
本文研究多目标优化问题(1):
minF(x)=[f1(x),f2(x),…,fM(x)]T
s.t.x∈X
(1)
其中,x=(x1,x2,…,xn)T是n维决策向量,X⊆Rn是决策空间,F是M维目标向量,fi(x)为n元实值函数。
下面给出多目标优化中的几个重要定义[22]。
定义1Pareto支配。设u,v是多目标优化问题(1)的两个可行解,若∀i∈{1,2,…,M},fi(u)≤fi(v)∧∃j∈{1,2,…,M}使fj(u) 定义2Pareto最优解。u为Pareto最优解(或非支配解)当且仅当∃v∈X:vu。 定义3Pareto最优解集。称X中所有Pareto最优解构成的集合为Pareto最优解集,记为PS,即PS={u|∃v∈X:vu}。 定义4Pareto前沿面。称PS中所有Pareto最优解的目标函数值所构成的曲线(或曲面)为Pareto前沿面,记为PF,即PF={F(u)=[f1(u),f2(u),…,fM(u)]T|u∈PS}。 PSO是Kennedy等提出的一种简单有效的微粒群智能优化算法[1]。在PSO中,每个粒子代表搜索空间中的一个可能解,种群即为问题潜在解的集合。设种群中第i个粒子的速度向量为vi=(vi,1,vi,2,…,vi,n),位置向量xi=(xi,1,xi,2,…,xi,n)(i=1,2,…,N,N为种群中的粒子个数),则其速度和位置按方式(2)-(3)进行更新: (2) (3) 不同于其它EA算法,PSO的形式简洁、操作方便、收敛速度快并且不需要过多的参数调整,因此更适合求解MOPs。但其快速的收敛会使种群多样性变差,容易导致算法陷入局部最优和出现早熟收敛。 为提高粒子群算法的搜索效率及克服分解方法处理复杂多目标问题的缺陷,本文提出一种改进的ISMPSO/D算法。首先,在进化种群中采用基于目标空间分解的更新策略,在每个子区域中保留一个最优解来维持解集的分布均匀性和多样性。同时,为更好地评价个体性能,用个体产生后代解的优劣设计了一种新的适应度评价方法,且后代解产生后,在新老解之间执行竞争操作,根据竞争结果自适应地调整其父代个体的适应度值,并把在竞争中获胜的优质后代解添加到父代候选解集中,提高了算法的搜索效率。其次,在粒子更新时,从当前粒子的邻居或邻居外随机选择个体最优和全局最优位置,增强种群多样性,且对产生的新解进行变异,避免算法陷入局部最优。最后,引入外部文档A作为候选输出解集,并基于Pareto支配和拥挤距离更新和维护A,且在迭代完成后,采用基于逆世代距离(Inverted Generational Distance,IGD)[23]的种群输出策略,输出具有最优IGD值的POP(t)或A作为最优解集。 为尽可能保证初始群体的随机性和多样性,本文将采用如下分解方法产生初始群体POP(0)。首先,随机产生N个个体x1,x2,…,xN组成POP和一组均匀分布的方向向量λ1,λ2,…,λN,并利用MOEA/D[21]的方法,确定每个向量的T个邻居(T为整数)。其次,基于这组方向向量,将目标空间分解成N个子区域,且使每个子区域中仅保留与对应方向向量最为接近的非支配个体。记分类之后所有子区域中个体的集合为POP(0),具体操作如下。 算法1初始群体的产生 1)随机产生POP={x1,x2,…,xN}和一组均匀分布的方向向量λ1,λ2,…,λN; 2)为每个方向向量找到离它欧式距离最近的T个向量,并把这T个向量作为该向量的邻居; 3)计算POP中个体xi的目标值F(xi),(i=1,2,…,N)确定参考点Z=(Z1,Z2,…,ZM),其中 Zj=min{fj(x)|x∈POP},j=1,2,…,M (4) 4)对每一个体xi(i=1,2,…,N)计算F(xi)-Z与λk(k=1,2,…,N)之间的夹角Δ(F(xi)-Z,λk),并按式(5)将POP分解为sub1,sub2,…,subN: (5) 即为xi找到与F(xi)-Z夹角最小的方向向量; 5)当subi=Ø时,随机产生一个体放入subi中;当subi中有多个个体时,根据Pareto支配关系找到其中的非支配解;若有多个非支配解,则保留与λi夹角最小的个体,并删除其它个体,即 (6) 2.2.1 适应度评价与个体竞争 在EA中,个体适应度值是反映个体性能优劣的重要指标。在进化过程中将根据适应度值的大小对种群中的个体进行优胜劣汰,适应度值大的优质个体将有机会繁衍更多的后代,而适应度值小的个体将会逐渐被淘汰。适应度评价方法对个体的影响类似于自然界中“物竞天择,适者生存”的自然准则,因此设计合理的适应度评价方法对EA性能有至关重要的影响。尽管已有的适应度评价方法,如目标函数值的大小和个体对目标函数的影响程度[7]、非支配排序[20]、Tchebycheff方法[21]和拥挤度距离[15]等,能将个体的适应度值与目标函数值相联系实现择优操作,但在迭代过程中无法自适应地调整个体的适应度值并且由于过多的函数评估,易浪费计算资源。 本文设计了一种新的自适应适应度评价方法。在进化过程中,该方法根据产生后代解的优劣自适应地调整父代个体的适应度值,淘汰在竞争中失败的个体,而将获胜的后代解添加到父代候选解集中。所提方法在父代个体适应度值和子代解的质量之间建立了自适应的动态联系,操作简单;不仅加快了后代解信息的利用率,而且提高了粒子的学习能力和算法的收敛,有效节省了计算资源。 通常,在EA中适应度值大的优质个体会比一般个体更容易产生好的后代解。为提高后代解的质量,自然期望这些优质个体尽可能多地被选择为父代个体参与进化,从而产生更高质量的后代。事实上,若个体在进化中产生了好的后代解,则可认为它在下一次进化中仍具有产生好的后代解的潜力。因此,本文将每一个体所产生后代解的优劣作为反映该个体适应度的指标,即个体产生的优质后代数目越多,它的适应度值就会越高,被选择为父代个体的概率就越大。 在进化前,对POP(0)中每一个体的适应度值进行初始化。为使非支配个体更多参与进化,将非支配个体的初始适应度值设为1,受支配个体的初始适应度值设为0,即个体xi的初始适应度值 (7) 在第t次迭代中,执行以下操作。 6)执行上述操作N次使每一代产生N个后代解。 图1 子区域中的个体竞争Fig.1 The individual competition in the sub-region 本文ISMPSO/D每产生一个后代解,就对其进行分区,并与该区域原来的解进行竞争,且获胜的优质后代可尽快参与到种群进化,从而使种群中非支配个体数不断增多且越来越靠近对应方向向量,但文献[15]是先产生N个后代解,然后再进行分区。此外,由于增加了优胜劣汰的竞争操作,因此ISMPSO/D在保证多样性前提下有效提升了收敛速度。 2.2.2 粒子的更新 由PSO更新式(2)-(3)知,在pbest和gbest的引导下,种群可以快速朝真实PF方向逼近。但PSO的快速收敛容易使种群多样性变差,不利于搜索。由于不同粒子具有不同的特征,且这些特征有助于搜索,所以在更新粒子时,首先产生一个随机数,若该随机数小于J,则从当前粒子的邻居中随机选择pbest和gbest以增强算法的局部开发能力;否则从邻居外随机选择pbest和gbest以增强算法的全局探索能力,避免陷入局部最优。 在标准PSO中,增加邻域修正策略可以提高后代解的质量、提升算法的收敛速度和增强PSO的局部搜索能力[15]。因此本文仍采用如下更新方式[15]: (8) (9) 其中,uj和lj分别为决策向量第j维分量的上下界, (10) 在更新过程中,由于pbest和gbest均从当前粒子的邻居或邻居外随机挑选,避免了某一粒子信息被多次利用,从而既降低了后代解集中于某个区域的可能性,又平衡了种群的局部开发和全局探索能力;接着对后代解实施变异操作,进一步增强了种群的多样性。因此两种策略的结合,不仅提高了搜索群体的多样性,而且有效增强了PSO的搜索能力,避免算法陷入局部最优。此外,参数J的选择对平衡算法的全局探索与局部开发有重要影响,根据3.1节中的实验分析,本文中取J=0.9。 综上所述,完整的种群进化过程如下。 算法2种群的进化 1)输入POP(t)和Fiti(i=1,2,…,N),令后代解集E=Ø,操作次数k=1; 6)若达到最大操作次数N,则输出POP(t),Fiti和E;否则令k=k+1,返回2)继续上述循环。 用EA求解MOPs时,由于部分问题的PF分布较为复杂(如DTLZ5~7),所以为使最终所获解集具有更好的分布性和收敛性,应在PF分布密集区域保留更多解,而在稀疏区域保留较少解。尽管ISMPSO/D算法在更新种群时,采用一组均匀分布的权向量将目标空间分解成若干个子区域,且在每个子区域中仅保留一个最优解,但均匀分布的权向量并不能保证最终获得PF的均匀性,且每个子区域中仅保留一个最优解,会造成密集区域优质解的严重丧失。因此基于目标空间分解的更新策略并不适合求解所有优化问题,尤其对具有不连续、退化或多峰PF的复杂问题。为克服这一不足,本文引入外部文档A储存进化过程中产生的历史精英解,以获得一组候选的高质量解集。但随着进化,文档A中精英解数目就会急剧增加,故对它进行如下操作:1)采用Pareto支配关系保证收敛性,即每一次迭代后,将后代解集E与A合并,找出其中的非支配解;2)采用拥挤距离方法确保多样性,即当非支解数目超过预先设定的规模H时,计算它们在目标空间中的拥挤度距离,删去具有较小拥挤距离的多余解。迭代完成后,将外部文档和进化种群都作为候选的输出种群,充分结合了分解方法、Pareto支配和拥挤距离的优势,增强了算法处理复杂问题的能力。 由以上分析,ISMPSO/D在迭代过程中会产生进化种群POP(t)和外部文档A两组解集。对POP(t),采用了基于目标空间分解的更新策略,而对A,采用了Pareto支配和拥挤距离的更新策略。由于不同优化问题的最优更新策略不同,因此本文采用基于IGD的种群输出策略。对每个测试问题,迭代完成后,分别计算两组解集的IGD值并进行比较,输出具有较小IGD值的解集。 由2.1-2.4小节,ISMPSO/D算法的详细步骤如下。 算法3ISMPSO/D算法 1)初始化: (1)设置进化种群规模为N,外部文档规模为H,最大函数评估次数为FES_max;初始权值为ω,加速度常数为c1和c2,常数为J,方向向量邻居规模为T; (2)根据算法1产生初始种群POP(0)并随机产生一组速度向量V={v1,v2,…,vN}; (3)根据式(7)初始化Fiti(i=1,2,…,N),令外部文档A=Ø,迭代次数t=0; 2)更新ω并执行算法2; 3)将E中的解与A中的解合并,更新A; 4)若满足终止条件,则计算进化种群POP(t)和外部文档A的IGD指标,输出具有较小IGD值的解集;否则,令t=t+1返回步2)继续循环。 为验证ISMPSO/D算法的有效性,本文选取ZDT[24]和DTLZ[25]测试集中的12个多目标基准函数进行数值实验,并与5种多目标优化算法进行比较,12个测试函数为双目标优化问题ZDT1~4和ZDT6和三目标优化问题DTLZ1~7;5种多目标算法为两种典型的多目标进化算法NSGA-Ⅱ[20]和MOEA/D[21]以及3种具有代表性的多目标粒子群优化算法SMPSO[10]、dMPSO[14]和MPSO/D[15]。本文所有实验均使用Matlab R2014a在Math-PC机(Inter(R) Core(TM)2 Quad CPU)上进行。 ISMPSO/D算法的参数设置如下:邻居规模T=10,最大函数评估次数FES_max=100 000,分布指标ηm+1=20,初始权值ω=0.9,权值采用MPSO/D中的更新方式;加速度常数c1=2和c2=2;J=0.9(具体说明见下文);对三目标问题,种群规模N=105,外部文档规模H=105,而对于双目标问题,种群规模N=100,外部文档规模H=100;ISMPSO/D的方向向量产生方式与MOEA/D的方向向量产生方式相同。 IGD值可以反映真实PF与近似PF之间的距离。IGD值越小,说明算法所获解集与真实PF之间的距离越小,其收敛性和多样性更好。为衡量各算法收敛性和解集多样性,本文将IGD值作为各算法的性能评价指标。 为探索不同J值对算法性能的影响,当J取0,0.3,0.6,0.9时,表1给出了部分测试函数IGD的平均值和标准差(括号内数据为标准差),并用粗体标出了在每个测试问题上的最好IGD值。从表1可以看出,当J=0.9时,除ZDT3和DTLZ3的标准差稍差外,各测试问题的IGD值都是最好的;对ZDT1和DTLZ3,不同J值对算法性能影响不大;对ZDT3问题,J取0.3和0.9的IGD值优于J取0和0.6时的IGD值;但对ZDT4、DTLZ5和DTLZ7,J值越大,IGD结果越小;因此在下面所有实验中取J=0.9。 表1 6种测试函数在不同J值下的IGD结果Tab.1 The IGD results of 6 test functions with different J values 本小节将ISMPSO/D算法与其它5种算法进行实验,为确保算法评价的公平客观及具有统计意义,在显著水平为0.05时,根据文献[26]所提方法对各比较算法和本文算法做t-检验。 为实验的公平性,对双目标ZDT问题,所有算法的种群规模设置为100,每个测试问题的最大函数评估次数为100 000;而对三目标DTLZ问题,所有算法的种群规模设置为105,每个测试问题的最大函数评估次数为100 000。对比算法的其它参数与其原文献的设置相同。每种算法均独立重复运行30次。 对双目标ZDT3和三目标DTLZ5~7问题,ISMPSO/D算法在外部文档A上的IGD值较小,故将外部文档A作为最终的输出种群;而对其余8个问题,进化种群POP(t)的IGD值较小,因此输出进化种群POP(t)。其原因在于外部文档中采用了拥挤距离和Pareto支配的更新策略,而进化种群是基于目标空间的分解维持多样性的。ZDT3的PF是不连续的凸形曲线,DTLZ5和DTLZ6的PF非均匀且退化,DTLZ7的PF不连续且分簇。实际上,对应不同优化问题的最佳更新策略并不相同,基于分解的方法在求解具有规整PF的三目标问题(如DTLZ1~4)时更具优势,而基于Pareto支配和拥挤距离的方法更适合求解具有退化且不连续PF的问题(如ZDT3及DTLZ5~7)。本文算法充分结合了分解方法、Pareto支配和拥挤距离的优势,因此更具竞争力。 表1列出了ISMPSO/D和其它5种对比算法在12个测试问题上IGD的平均值(Mean)和标准差(Std)。每个测试问题的最佳IGD值用黑色加粗表示,“+”、“≈”、“-”分别表示本文算法的IGD值在t-检验中分别优于、相似于、劣于各对比算法在同一测试问题上的显著性区分结果,表1的最后统计了ISMPSO/D分别优于、相似于、劣于各对比算法的问题个数。 从表2可以看出,本文ISMPSO/D算法在2个双目标和3个三目标问题上取得最好IGD值(其中在ZDT1和DTLZ1上输出外部文档,在其余问题上输出进化种群),MPSO/D获得4个最优值,MOEA/D在ZDT4和ZDT6上获得最优值,SMPSO在DTLZ5上取得最优值,而dMPSO在12个测试问题上都未获得最优IGD值。 与MPSO/D相比,ISMPSO/D获得最优值的个数多于MPSO/D,且在三目标DTLZ1和DTLZ3上,二者所获IGD均值相同,但在DTLZ5~7以及除ZDT2之外的其它双目标问题上,ISMPSO/D比MPSO/D获得的IGD值要小。对PF分布较为规整的双目标ZDT1、ZDT4和ZDT6,ISMPSO/D由于采用了自适应适应度评价方法以及后代个体的实时竞争策略,因此更具优势;而对PF分布较为复杂的DTLZ5~7,外部文档的引入使得本文充分结合了分解方法、Pareto支配和拥挤距离的优势,从而取得了较好IGD结果。 表2 6种算法在12个测试函数上的IGD结果Tab.2 The IGD values of six algorithms on twelve test functions 与MOEA/D相比,ISMPSO/D在三目标DTLZ1~7上以及双目标ZDT1~3问题上都取得最优IGD值。与SMPSO、NSGA-Ⅱ以及dMPSO相比,所提算法除了在DTLZ5上的性能稍逊于SMPSO和NSGA-Ⅱ外,在其它问题上均有显著优势。综上,ISMPSO/D在总体上获得最好的多样性和收敛性。 为直观观察各比较算法在测试问题上所获得的近似PF,图2给出了4种算法在7个较难测试问题上迭代1 000次的近似PF图像。由图2可以看出,对7个较难测试的函数,ISMPSO/D算法均能获得分布均匀且完整的PF;对双目标ZDT1和ZDT6问题,各算法都表现出良好的收敛性和均匀性,但基于分解的ISMPSO/D、MPSO/D和MOEA/D算法所获PF要比NSGA-Ⅱ均匀;对ZDT3问题,MPSO/D陷入局部最优未能找到分布完整的PF,MOEA/D和NSGA-Ⅱ虽然能找到完整的PF,但所获解集的分布性明显差于ISMPSO/D;对三目标的4个测试问题,ISMPSO/D获得的PF更为完整;对DTLZ1和DTLZ3,ISMPSO/D和MPSO/D的分布性明显优于NSGA-Ⅱ和MOEA/D,且后两种算法仅能找到部分PF且分布不佳,而在搜索边界上MPSO/D的分布性稍逊于本文算法;对PF非均匀且退化的DTLZ6问题,本文算法所获PF不仅收敛而且分布均匀,MOEA/D和NSGA-Ⅱ收敛性不好,MPSO/D所获PF的收敛性和分布性均最差;对DTLZ7,ISMPSO/D和NSGA-Ⅱ能收敛到4个簇上,而MOEA/D的多样性严重缺失,MPSO/D不收敛。因此,本文算法不仅可以搜索到7个测试问题的完整PF,而且收敛性和所获PF的分布性最佳。 图2 4种算法在7个较难测试问题上的近似PF Fig.2 Approximate PF of four algorithms on seven difficult test functions 综上所述,ISMPSO/D的综合性能明显优于其它算法。其原因在于:1)提出的新适应度评价方法将父代解的适应度值与子代解的优劣相联系,且一旦产生后代解就立即参与竞争,并根据竞争结果对进化种群和父代适应度值进行更新,使得优质后代解的信息被快速利用,提升了进化种群的整体质量,加速了算法收敛。在相同迭代次数下,对PF分布规整的问题(如ZDT1、DTLZ1和DTLZ3),其IGD比较结果和PF图像都说明了上述改进的有效性;2)外部文档的引入以及pbest和gbest的随机选择,避免了种群多样性的过早丧失,改进了分解方法处理具有复杂PF问题(如DTLZ6和DTLZ7)的不足。 为提高粒子群算法的搜索效率及克服分解方法处理复杂多目标问题的不足,通过考虑适应度评价和种群更新对算法收敛性及解的分布均匀性的重要影响,本文基于目标空间的分解提出一种求解MOPs的改进ISMPSO/D算法。首先,设计了一种自适应适应度评价方法,并根据竞争结果对父代适应度值和进化种群进行更新,加快了算法的收敛速度;其次,在更新粒子时,从当前粒子的邻居或邻居外随机选择个体最优和全局最优位置,增强了粒子的多样性,且对产生的后代解立即进行变异,避免了算法陷入局部最优;最后,引入外部文档作为候选的输出种群,并采用拥挤距离维持多样性,克服了分解方法不利于求解复杂问题的缺陷。通过对12个基准函数的数值实验,并与5种多目标算法的比较,表明了所提算法不仅改进了分解方法无法找到复杂PF的缺陷,而且能更好地维持算法收敛性和解集多样性的平衡。 尽管ISMPSO/D算法在多目标测试问题上的综合性能有所提升,但对超多目标优化问题如何改进,其性能有待进一步研究。1.2 标准的粒子群算法

2 提出的算法
2.1 初始群体的产生
2.2 种群的进化
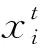





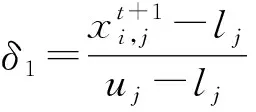

2.3 外部文档的维护
2.4 种群的输出
2.5 算法流程
3 仿真实验
3.1 J值的选取

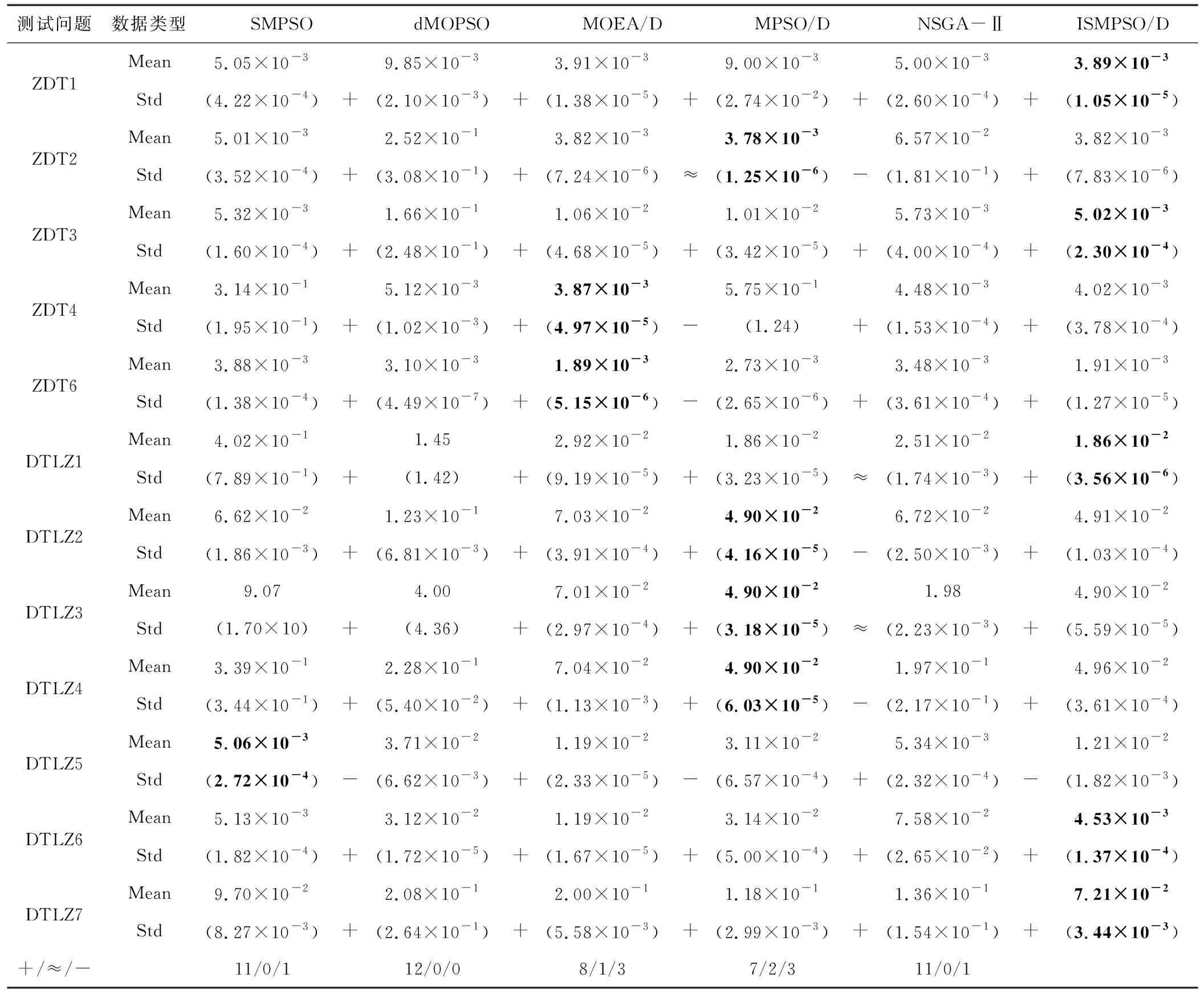
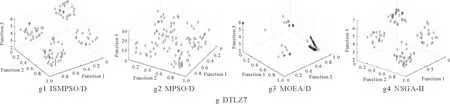
3.2 比较与分析


4 结论
猜你喜欢
计算机仿真(2022年8期)2022-09-28
今日农业(2022年15期)2022-09-20
意林(2021年9期)2021-05-28
时代英语·高一(2019年1期)2019-03-13
红土地(2018年7期)2018-09-26
郑州大学学报(工学版)(2018年2期)2018-04-13
自动化学报(2017年2期)2017-04-04
Coco薇(2016年8期)2016-10-09
中国塑料(2016年11期)2016-04-16
当代畜禽养殖业(2014年10期)2014-02-27
