
基于LVQ聚类算法的雷达目标特征分析
2019-01-03 02:20程玉堃丁志辉王静娇
雷达与对抗 2018年4期
程玉堃,丁志辉,王静娇
(中国船舶重工集团公司第七二四研究所,南京 211153)
0 引 言
舰载雷达在扫描作业过程中接收到的回波信号中总是混杂着噪声、杂波和各类干扰,例如气象杂波、海洋杂波、地物回波、有源或无源干扰以及其他多种偶然扰动。干扰引起的噪声和杂波会形成具有随机特性的虚假点迹[1]。雷达数据处理部分的检测、凝聚等过程无法区分真实目标点迹数据和虚假目标点迹数据。这不仅产生了冗余数据,增大了传输的数据量,也不利于目标航迹的跟踪,更会干扰雷达操作人员的判断和操作。尽管雷达的信号处理系统已经通过采用诸如动目标处理、恒虚警率检测、杂波图等处理方法去尽可能地减少虚假点迹,但对于信号处理后的数据处理环节输出的真、假目标点迹混合数据中残留的虚假点迹,目前已有的判别和剔除方法仍然存在一些缺陷。
1 综 述
对于雷达回波中真、假目标点迹的判别,目前常用的一种方法是基于先验已知的真、假点迹的训练样本,在样本空间中寻找一个划分真、假目标的超平面。该超平面应当对训练样本局部扰动的“容忍性”最好,即其鲁棒性要好,对于新的未知样本的泛化能力要强[2]。具体原理是,由于真、假目标点迹特征信息的分布特性不同,通过提取真、假性先验已知的目标点迹的归一化幅度、距离向展宽、方位向展宽、仰角向展宽、回波点数等特征信息,得到每项特征信息的均值和方差值等统计特性。将这些特征信息两两组合形成支持向量,从而生成分隔真、假目标点迹的超平面,得到目标真、假性判别的似然区间。针对每一组需要判别真假的目标,计算其在所有特征信息组合下的似然概率并加权求和,得到每个目标点迹的真、假性综合评估值,然后根据该评估值判别目标的真假性,进而实现剔除。
该方法最大的缺陷在于需要有一组先验已知的真、假目标点迹训练样本,即真、假目标点迹的多个特征信息的统计特性(均值和方差)已知。然而现实中,数据处理输出的目标点迹是真、假未知的,因此需要通过某种方法在目标点迹真、假性未知或部分已知的条件下,通过某种准则,尽可能地对点迹进行初步的真、假性分类,以此为基础才能应用前述的假目标剔除方法。作为聚类算法的一种,学习向量量化(LVQ)算法适用于解决此类问题,根据训练样本是否有监督信息,LVQ算法可以应用于有监督和无监督两种场景。
2 LVQ算法
2.1 算法介绍
对于训练样本的标记信息未知的情况,无监督学习算法通过自主学习来揭示数据内在的性质和规律,为进一步的数据分析提供支撑。聚类算法就是这样一类算法。它将样本划分为若干互不相交的子集,称为样本簇。聚类的目的是尽量使结果样本簇的“簇内相似度”尽可能高,“簇间相似度”尽可能低[3]。聚类算法大体分为原型聚类、密度聚类、层次聚类3种类别。LVQ算法是一种原型聚类算法。与一般聚类算法的不同之处在于它假设数据样本带有类别标记,学习过程中会利用这些监督信息来辅助聚类。下面介绍LVQ的算法原理。
2.2 算法原理
2.2.1 LVQ算法的准备工作

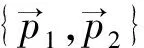
Ri={‖x-pi‖2≤‖x-pi′‖2,i′≠i}
(1)
2.2.2 LVQ算法的实现步骤
(1) 监督信息初始化
由于用于训练的样本数据是在真实回波条件下针对特定目标(飞机、船只)采集的,其距离、方位、仰角等信息基本已知,因此可将样本中这部分已知目标的真、假标签设为真,其他目标的标签全部预设为假。
(2) 原型向量初始化
(3) 原型向量迭代优化
p′=pi*+α·(xj-pi*)
(2)
p′=pi*-α·(xj-pi*)
(3)
(4) 输出原型向量
3 仿真验证
本文使用天线采集的14圈回波的CFAR处理后数据,数据方位范围200°~300°,仰角范围0°~15°,距离范围0~300 km。通过分析得到一批飞机目标和一批船只目标在天线采集的第2圈时的距离、方位、仰角位置和第14圈的距离、方位位置如图1~图6所示。
从图1中可以看出,飞机目标距离单元范围为1 900~1 930,方位范围280°~288°,距离向展宽为8个距离单元,方位展宽为3°左右。从图3中可以看出,飞机目标的仰角向展宽为2°左右。从图2中可以看出,船只目标位于距离单元范围为4 460~4 490,方位范围275°~285°,距离向展宽为10个距离单元,方位展宽为5°左右。从图6中可以看出,船只目标的仰角向展宽为3.5°左右。在进行目标特征分析之前,首先通过设定特定的检测门限,使用点迹凝聚方法从采集数据中提取得到一组真、假目标点迹混合数据(共23 476个),将这组数据作为本次训练的样本。分析图1和图2可知,飞机目标和船只目标在数据采集期间的位置范围较为固定,且目标附近没有明显杂波。因此,首先对所有目标中满足这两组目标所在范围的所有目标设定标签为真,其他所有目标的标签为假。使用凝聚算法提取的目标特征信息如表1所示。

表1 凝聚算法提取的目标特征信息

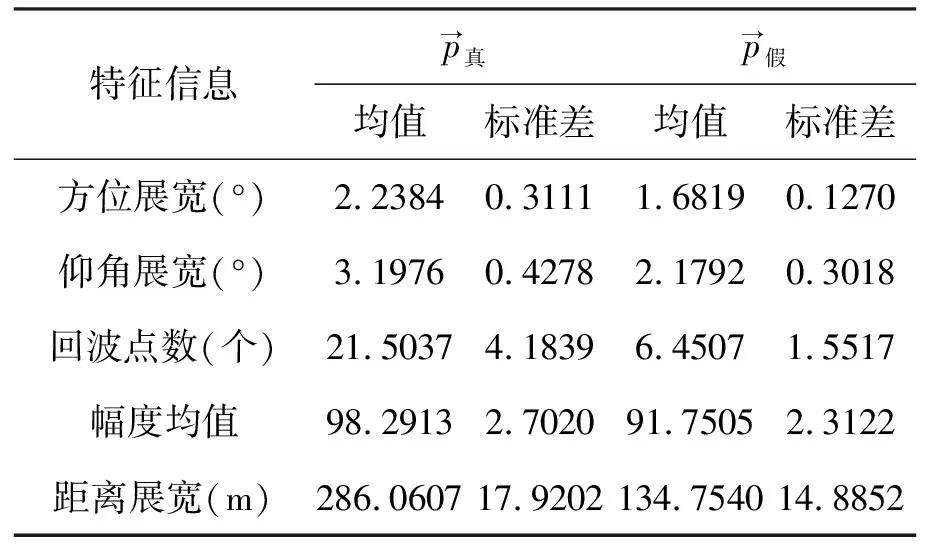
表2 LVQ算法得到的真、假目标特征统计特性
统计结果显示,使用LVQ算法聚类得到的典型的真目标比典型的假目标在方位展宽、距离展宽、仰角展宽、回波点数、信号幅值这些特征方面的均值和方差都要更大一些。这与实际情况相符。使用上述统计数据作为后续支持向量算法中真、假目标点迹特征信息的统计值,进而根据真、假性综合评估值进行点迹剔除。仿真的目标剔除范围为0~150 km,第2圈的剔除前、后效果对比如图7~8所示。
分别对比图7和图8可知,近处雷达回波虚假点迹明显减少的同时远处的孤立真目标得到保留,点迹剔除取得了较好的效果。这说明基于LVQ算法对目标粗样本的初步聚类所得到的真、假目标点迹特征信息的统计值为后续的风险系数计算提供了很好的数据支撑,较好地实现了预期的效果。
4 结束语
针对目前常用的虚假点迹剔除算法在实际应用过程中所面对的缺乏先验训练样本数据支撑的问题,本文讨论了如何通过使用LVQ算法对真、假目标点迹混杂的粗糙样本进行初步聚类以得到真、假目标点迹特征信息的统计特性,为后续的虚假点迹剔除算法提供数据支撑。下一步将围绕真、假目标统计特性分析、算法效果优化以及硬件平台验证和改进等展开更多工作。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
幼儿园(2021年12期)2021-11-06
计算机应用与软件(2021年7期)2021-07-16
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
初中生世界·九年级(2020年2期)2020-04-10
科技视界(2016年15期)2016-06-30
互联网天地(2016年1期)2016-05-04
小学生时代·大嘴英语(2015年7期)2015-11-23
为了孩子(孕0~3岁)(2009年6期)2009-07-15
红领巾·成长(2009年8期)2009-01-12
