
图书馆读者需求与服务匹配模型研究
2018-12-28 10:10:04林淑贞
图书馆研究 2018年6期
林淑贞
(广州图书馆,广东 广州 510623)
1 引言
读者大数据与精准画像技术是当前图书馆学界研究的重点和热点。其中,读者大数据的汇聚、提炼与应用是构建精准读者画像和实现图书馆个性化服务的关键所在,也成为图书馆服务领域关注的焦点[1]。随着阅读路径分析、云计算、深度学习等技术在图书馆领域的应用,已有一批基于读者大数据技术的图书馆读者与服务匹配模型及算法问世,其中较具特色的成果有:Zne-Jung Lee[2]等研究人员设计与实现了一个基于读者大数据的图书馆推荐模型,该模型通过对读者信息进行持续跟踪与融合,刻画出读者的阅读习惯,提高了个性化服务的读者满意度;Daniel Mican[3]等研究人员设计了基于读者社会媒体大数据分析的推荐系统,该系统通过读者关系分析,对读者需求进行了深入发掘,提高了推荐的准确度;Dharna Patel[4]等研究人员将云计算运用于读者大数据挖掘工作中,并据此设计了一款图书推荐系统,取得了较高的读者需求匹配度;Aravind Sesagiri Raamkumar[5]等研究人员对读者大数据与海量论文之间的需求与匹配关系进行了分析,并开发了对应的科学文献服务系统,具有较高的读者满意度;Yifan Hu[6]等研究人员基于大数据技术开发了读者协同过滤推荐系统,极大地提高了读者荐读服务的准确度。Julien Verplanken[7]等研究人员设计了基于大数据技术的读者动态画像模型,并以此为依据开发了精度较高的推荐系统;Raymond J.Mooney[8]等研究人员应用自学习技术,构建了读者阅读成长模型,并将其应用于读者服务系统中,取得了很高的用户满意度。尽管上述成果具备一定的理论价值与实践意义,但从实际应用效果来看,普遍还存在着服务推荐精度不稳定、覆盖度较低、系统资源开销较大等问题。针对这些问题,本研究基于读者大数据融合技术,深入和全面地描绘读者画像,构建了较为完善的图书馆读者需求与服务匹配模型LRSM(Library Reader and Service Matching)。该模型的结构、处理流程以及关键算法如下文所述。
2 模型结构与应用流程

图1 模型结构与应用流程
2.1 模型结构
LRSM的总体特点是结构较为简单(全模型仅4个主要子模块),接口标准,可适用于各类图书馆的推荐服务运行;其结构特点是“紧内聚,松耦合”,复杂的数据结构被封装在各个模块中,用户或第三方软件通过其接口就可以获取相关的推荐服务,使得服务的获取变得极为简单,而避免了过多繁复的配置和二次开发。如图1所示,LRSM模型主要嵌入在图书馆信息服务系统中,为读者提供高匹配度的个性化服务推荐。该模型主要有4个子模块。一是读者画像生成子模块。该模块主要从图书馆管理大数据系统中抽取读者相关信息,通过融合后,形成包含读者特征与需求信息的读者画像信息,并将这些信息存储在读者画像库中。LRSM模型通过该子模块,对读者的持续跟踪,不断丰富和细化这些画像信息,为需求与服务匹配工作提供读者的基础数据。二是服务信息融合子模块,该模块主要从图书馆各职能部门的服务器中获取服务与业务项目的特征信息,以及读者对于这些项目的反馈信息,最终形成图书馆的服务特征空间,为服务项目检索提供基础数据。三是需求与服务匹配子模块,该模块同时接收读者信息与服务信息作为检索依据,从读者画像库与服务资源库中选取匹配度较高的对应项目,推荐给读者。其中的需求与服务的融合匹配算法参见下文第3节。四是推荐接口子模块,该模块可以根据图书馆方或读者的具体要求,接收读者的需求报告,并向需求与服务匹配模块发出推荐申请,最终通过邮件、短信、微信等综合方式,向读者推荐图书馆的各项服务。
2.2 模型流程
LRSM模型对于读者需求与图书馆服务的信息处理与匹配流程如下:
Step1:读者画像生成,即LRSM模型根据读者的注册信息,生成其静态画像属性;根据读者的借阅历史、服务使用记录、留言反馈等信息,生成动态的读者画像属性,并定时或实时地对其进行动态更新;最终,读者大数据将融合生成读者画像信息,存储在读者画像库中。
Step2:服务特征挖掘,即LRSM模型根据图书馆各服务职能部门提供的服务项目说明、读者意见反馈等信息,融合生成或定时更新数据库中的图书馆服务特征信息。
Step3:需求与服务预匹配,即为了提高二者的匹配速度,LRSM模型在系统空闲时,将对两类数据作预匹配,一方面自动提高近期访问频率较高的服务的权重;另一方面对近期访问图书馆的读者进行画像信息更新,对读者的潜在需求进行预测,并预先为其生成一部分高匹配度推荐服务列表。
Step4:需求与服务匹配,即一方面,当有读者进入图书馆管理信息系统时,LRSM模型将调用其读者画像作为检索依据,搜索匹配度较高的服务,形成推荐服务队列;另一方面,当有新服务上线,或旧服务更新时,LRSM模型将根据其服务特征,搜索匹配度较高的读者,形成推荐目标读者队列。
Step5:推荐实施与读者反馈,即LRSM模型根据读者订制或默认模式,将图书馆服务精准的推荐给目标读者,并收集读者的反馈,从而进一步细化和丰富读者画像信息以及服务特征信息。
3 需求与服务的融合匹配算法
本模型采用了基于读者大数据的需求与服务融合匹配算法。该算法的基本思路来自大数据传导模型,该模型为多层信息传导结构,其本质是一种信息能量传导模型的改进。总的来说,需求与服务融合匹配算法的核心(融合匹配度)可以有如下表示:

(1)
在匹配度表达式(1)里,vi、hj是系统中匹配元素(读者需求与图书馆服务)的状态,而ai、bj则分别是它们的融合导向值,wji则是两类元素的匹配权重;该表达式中的具体求值计算方法如下:

(2)
其中,hio(n)=〔h1h2...hM〕T,权值wj(n)=〔w1w2...wM〕T,M是服务的个数。至此,可以通过下列公式求得融合匹配度:

(3)

(4)
为保证匹配度的收敛和最大化,应对(4)进行进一步的处理。首先为精确描述读者的需求,可以建立下列模型:

(5)
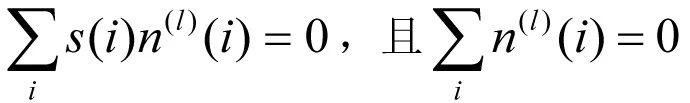

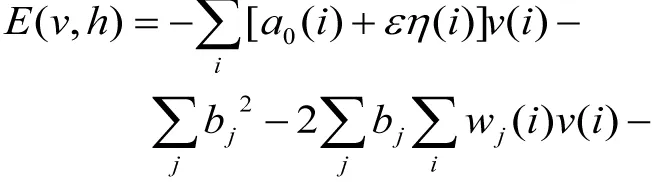
(6)
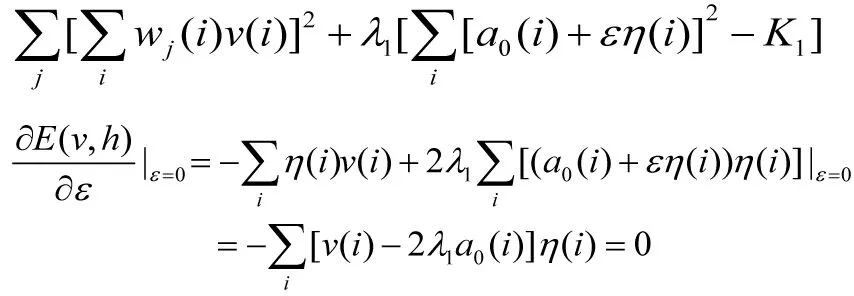
(7)

(8)
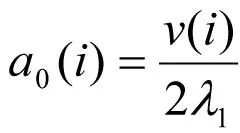
(9)
公式(8)中的v(l)(n)可以视为读者需求的不同表达,在L个需求时,有:
(10)
求其总和,可以表达为:
(11)
进一步有:

(12)
此时可得:
(13)

(14)
有:

(15)


(16)

(17)
在(17)中,k3为设定值。至此,可以求得融合匹配度,当(1)中的匹配度较高时,进行推荐或个性化服务的效果较好。
4 实验与结果分析
LRSM模型在某图书馆信息服务系统中进行了测试,并与当前较为流行的读者辅助服务模型RSSM(Reader Supported Service Model)进行了独立实验与对比。为了保证实验的公平公正,图书馆技术人员在两台服务器中分别部署了LRSM模型与RSSM模型作为后台,而两种模型基于各自的独立标注读者数据集,之后的服务推荐等信息处理任务均交由统一的界面完成。最终,两个实验读者组的数量分别为1 475人(LRSM)和1 461人(RSSM),人数差距符合统计学的差别分析要求;按照上述规范与要求,最终对两种模型的读者需求覆盖度、需求匹配精确度以及系统资源占用率等客观指标进行了为期30天的跟踪对比实验,并按照信息系统开发规范的要求,对两种模型进行了读者满意度方面的主观指标调查。最终的实验结果如图2所示:

图2 两种模型的读者需求覆盖度对比
如图2所示:LRSM模型与RSSM模型在30天的实验过程中,均取得了良好的读者需求覆盖度。该指标指代图书馆个性化服务模型在一定的实验周期之中,为读者提供或者推荐的图书馆服务,在读者使用到的所有图书馆服务中所占的比例。如图2所示,尽管二者均具备良好的读者需求覆盖度,但从总体上看,LRSM模型的读者需求覆盖能力大大超过了RSSM模型。究其原因,主要是由于LRSM模型的读者需求挖掘效能更高,对读者新需求的发现更为灵敏。此外,从图2中也可以看出,LRSM模型的读者需求发现速度较快(曲线上升速度快),并在达到覆盖度稳定区后,长期保持较高的需求覆盖度。

图3 两种模型的需求匹配精确度对比
如图3所示:LRSM模型与RSSM模型在30天的实验过程中,均取得了良好的需求匹配精确度。该指标指代图书馆个性化服务模型在一定的实验周期之中,两种模型提供或推荐给读者,并实际被采纳的服务,占到各自提供的服务数量的总比例。如图3所示,尽管二者均具备良好的读者需求匹配精确度,但从总体上看LRSM模型的需求匹配精确度超过了RSSM模型。究其原因,主要是由于LRSM模型的读者需求挖掘更为深入,对读者需求的刻画更为细致。此外,从图3中也可以看出,LRSM模型的需求精度上升速度较快,并在达到稳定区后,较长时间保持了匹配的高精确度。
实验完成后,将告知两组读者相关情况,并请他们为两个模型进行评价。表1是两种模型的读者主观评价情况(组内平均得分)对比。

表1 两种模型的读者主观评价对比
最后,LRSM模型与RSSM模型在30天的实验过程中,均取得了良好的性价比;二者的CPU占用率均未10%。在内存占用率方面,RSSM模型的峰值内存需求达到了150M,而LRSM的峰值内存需求仅为110M,体现了良好的性价比,参照目前主流的图书馆服务器配置(8G以上),该指标表明LRSM模型具有较高的系统可部署性和可扩容性。
5 结论
LRSM模型在图书馆服务上的应用体现出了其良好的应用价值,具有较高的读者需求覆盖度和需求匹配准确度。该模型的系统资源占用率较低,性价比突出,能够为读者提供个性化程度较高、需求满意度较高的图书馆服务。从目前的应用效果来看,该模型还需在以下几方面进一步扩展:首先,进一步丰富读者画像的内容,从而更全面地采集读者需求信息,深化和扩展图书馆服务的内容;其次,图书馆服务元数据挖潜,为需求-服务匹配提供更为精准和丰富的资源;最后,进一步优化需求-服务匹配算法,研究服务系统空闲期的游走需求采集模型。
猜你喜欢
科学技术创新(2022年30期)2022-10-21 14:01:24
小哥白尼(神奇星球)(2022年3期)2022-06-06 07:39:34
农业与技术(2021年23期)2021-12-14 09:03:32
新世纪智能(高一语文)(2020年9期)2021-01-04 00:42:42
非公有制企业党建(2020年10期)2020-10-27 06:30:14
原子与分子物理学报(2020年5期)2020-03-17 06:59:18
小太阳画报(2018年1期)2018-05-14 17:19:25
少年博览·小学低年级(2016年10期)2016-11-24 06:48:23
小天使·一年级语数英综合(2014年8期)2014-06-26 14:42:04
延河(下半月)(2014年1期)2014-02-28 21:05:10
