
基于双层分类模型的人体动作识别方法
2018-12-22 07:40赵雪章席运江黄雄波
计算机工程与设计 2018年12期
赵雪章,席运江,黄雄波
(1.佛山职业技术学院 电子信息系,广东 佛山 528137; 2.华南理工大学 工商管理学院,广东 广州 510000)
0 引 言
在过去的几年中,学者们尝试克服静态图像的限制性,以获得可靠的动作识别结果[1,2]。目前用以识别图像中人体动作的方法主要有以下几种[3]:基于特征模型的方法、基于实例学习的方法以及基于图像-结构的方法。为了提高动作识别的性能,一些方法融入了额外的信息,例如目标交互和上下文信息。还有一些组合算法,如文献[4]提出的结合特征袋(bag-of-features,BoF)和支持向量机(support vector machine,SVM)分类器的方法;文献[5]提出的结合姿态激活向量(posture activation vector,PAV)和SVM分类器的方法。然而,这些方法对于静态图像的识别率仍然较低。这是因为测试图像中许多图像的人体范围为上半身,而上半身经常呈现非特定动作且容易与其它动作相似。文献[6]提出的Fusion+BoF方法使用了颜色和形状描述符,所以在动作分类中获得了较优性能,但其需要大量的处理时间。
为此,提出一种基于姿态库和AdaBoost双层分类模型的人体动作识别方法,该方法的主要创新点如下:
(1)构建一种两层AdaBoost分类模型,利用第一层分类器找到目标边框的合适位置,以此训练由特征向量和空间信息组成的姿态库,并通过第二层分类器模型来识别动作。
(2)构造了空间姿态激活向量(spatial PAV,SPAV),该向量利用姿态库的空间位置为分类模型提供了与人体动作相关的可判别信息。
1 提出方法的框架
本文方法主要分为4个部分,即创建姿态库、训练姿态库、构建空间姿态激活向量(SPAV)和动作识别。其基本流程如图1所示,各步骤分别描述如下。
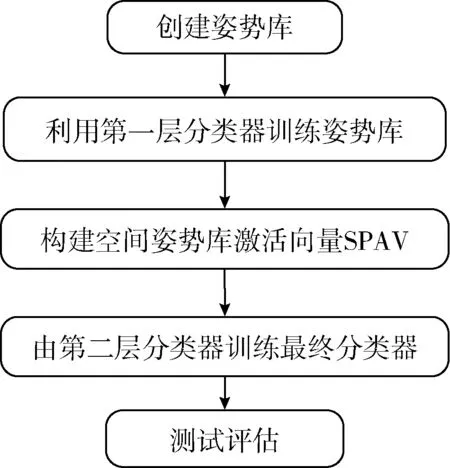
图1 提出方法的流程
首先,基于Hausdorff距离来估计图像块之间的空间关系,以此构建特定动作的初始姿态库。
然后,构建一种双层AdaBoost分类模型,基于动作姿态库来训练第一层分类器,并获得最终姿态库。这里采用与文献[5]相似的方法创建姿态库。利用第一层分类器找到图像中人像边框的合适位置,以此训练由特征向量和空间信息组成的姿态库。
接着,根据第一层分类器生成姿态激活向量(PAV),为了考虑姿态库的空间位置,构造了空间PAV(SPAV)。
最后,将SPAV作为第二层分类器的输入,对动作进行最终判别。其中对于每张图像,将动作类的SPAV进行聚合,构成一个级联SPAV(CSPAV),并利用这些CSPAV来训练第二层分类模型。
在测试阶段,应用已训练的第一层分类器从输入图像中估计CSPAV,然后将CSPAV应用到第二层分类器上。当计算完所有c-动作类的分数之后,将具有最大分数的类作为最终判决。
2 姿态库的构建
本文通过将图像分解为一组部位来构造姿态库,每个姿态库为从给定视角处捕获人体动作突出的部分。姿态库中的每个实例来自人图像的给定位置、方向和范围处的一个对应矩形区域。
为了替代传统的欧氏距离,本文采用了一种Hausdorff距离[7]来估计图像块之间的空间关系。Hausdorff距离实现简单且对目标空间位置的变化不敏感[8]。构造姿态库的算法步骤如下所示:
(1)利用包括2D关键点和动作标签的训练图像生成三维的n个随机种子窗口。
(2)对于i=1到n执行。
1)选取随机种子窗口,并利用Hausdorff距离估计配置空间中从种子区域S到目标随机区域R的直接距离dS(R)
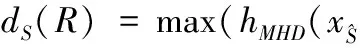
(1)

2)利用直接距离找到k=50个最近的实例,并标记集群标签为i。
(3)结束。
(4)对于第i个集群,估计其为每类的熵
Ei(ω)=-P(ωi)×logP(ωi)
(2)
式中:P(ωi)为集群i为ω类的条件概率。
(5)选择含有最低熵值Ei的m集群。接着,移除每个集群中不包括在该类的所有实例,最后将剩下的集群称为姿态库。
(6)每个姿态库储存了所有用于测试的实例的中心位置。
在该算法中,设置随机种子窗口的数量为600。对于实时应用,为了减少处理时间,可将所需选择的m个集群(姿态库)的数量从300减至30。


(3)
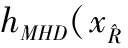
(4)

(5)
(6)
设定k(x)为Epanechnikov核函数,该函数为各向同性内核,其分配更大的权值到实例中心点处的关键点,表示如下
(7)

图2 所提取的姿态库的实例
3 提出的双层AdaBoost分类器
在选择了一个动作姿态库后,从每个姿态库中提取视觉特征,同时利用特征向量和模式分类器研究外观模型。
尽管梯度方向直方图(histogram of oriented gradients,HOG)特征是人体检测和动作识别中最常用的特征[9],但缺点是需要高的计算量。目前,局部二值模式(local binary pattern,LBP)特征[10]和一些改进版本已在人体和目标检测中采用。其中,中心-对称LBP(CS-LBP)特征的计算量较低,但其丢失了方向信息[11]。所以,本文采用了新的、更低维度的CS-LBP特征,即方向CS-LBP(OCS-LBP)。
OCS-LBP中,通过求和属于k的所有梯度幅值,获取每个方向k的OCS-LBP特征。利用最小-最大归一化方法对k的最终集合,即OCS-LBP特征进行归一化。为了设计对部分遮挡和扭曲鲁棒的特征描述符,将姿态库细分为16×16像素。也就是说,64×64的姿态库可以分为4×4个子块,64×96的姿态库可以分为4×6个子块,64×128的姿态库可以分为4×8个子块,128×64的姿态库可以分为8×4个子块。然后对于每个子块,分别计算每个OCS-LBP特征,并利用积分直方图保存局部变化,以降低计算时间。最后,级联局部OCS-LBP描述符,从而产生含有128个维度(16×8)、192个维度(24×8)和两个256个维度(32×8,32×8)的OCS-LBP描述符。
对于利用外观模型的动作检测,这里应用了一种双层分类模型,该模型比单个分类器具有更好的分类性能和对噪音的抑制能力。第一层分类器为基于姿态库训练的二进制分类器。第二层分类器为一个多级分类器,将第一层分类器的输出作为输入。这里的两级分类器都采用AdaBoost分类器。
3.1 训练第一层AdaBoost分类器
随机森林分类器能够很好地解决高维度问题,例如人体检测、目标跟踪、烟雾探测和目标检测等。与随机森林方法基本类似,当采用基于单个分类器对样本进行分类的效果不理想时,通常希望能够通过整合多个分类器来提高最终的分类性能,并称这种不太理想的单个分类器为“弱分类器”[12]。与随机森林方法不同,AdaBoost方法并不是简单地对多个分类器的输出进行决策投票,而是通过一个迭代过程对分类器的输人和输出进行加权处理[13]。在不同应用中可以采用不同类型的弱分类器,并在每一次迭代过程中,根据分类器的情况对各个样本进行加权,而不仅仅是简单的重采样。
对于姿态库的第一层分类,其AdaBoost分类器训练过程描述如下:
(1)首先,假设已经给定N个训练样本x1,…,xN,用fmx∈-1,1m=1,…,M表示M个弱分类器对于样本x的输出,通过AdaBoost算法构造这M个分类器并进行决策。
(2)然后,再进行初始化训练样本x1,…,xN的权重ωi=1/N,i=1,…,N。
(3)对m=1→M,重复以下过程:
1)首先是利用ωi加权后的训练样本来进行构造分类器fmx∈-1,1 ,(注意构造分类器的具体算法可以不同,例如采用线性分类器和决策树等)。
2)计算样本采用ωi加权后的分类错误率em,并令cm=log1-em/em。


所谓利用加权后的训练样本构造分类器,是指对分类器算法目标函数中各个样本对应的项进行加权,因此需要根据具体采用的分类器类型具体分析。例如,对于最小平方误差判别,加权后的均方误差(mean squared error,MSE)准则函数为
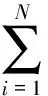
(8)
而对于决策树或一些其它方法,则可以根据每个样本的权值调整重采样概率,按照这个概率对样本进行重采样,用重采样得到的样本集构造新的弱分类器。
根据以上算法流程,利用第一层分类器学习完姿态库后,再利用第一层分类器生成姿态激活向量(PAV)。
3.2 生成姿态激活向量
利用第一层分类器学习完姿态检测器之后,在测试图像的人体范围上检测动作,从而生成PAV。如果人体范围内利用SVM分类器,以扫描窗口方式检测一个动作,则PAV的第i项会通过投票方式决定。然而,所构建的典型PAV的主要缺点是其没有考虑动作的空间位置,且需要大量的计算时间进行动作检测[14,15]。例如,打电话动作中的大部分实例是从人体的右上方提取的,如果动作检测器仅仅比较没有位置信息的视觉外观,则会在没有空间信息的一些区域中检测到多个动作。
为了考虑动作的空间位置和减少总计算时间,不从所有人体区域提取重叠的测试实例,取而代之的是,仅仅从动作实例的中心位置提取测试实例。提取踢足球实例的一个例子如图3所示,由于踢足球主要是腿部动作,为此提取的实例为人体的中下区域。

图3 从动作中心位置提取实例
扫描窗口是从给定的候选位置处提取的,检测每个窗口,并将其作为初始位置附近的第i个动作类。然后对每个检测的动作进行投票,决定作为空间PAV(SPAV)的第i个项。SPAV的最后第i个项为所有动作类型i的检测分数总和。对于一种动作类型,本文使用动作的5种不同尺寸。对于一种尺寸动作,本文训练30个动作。然后将动作的5种尺寸连接到一个维数为150(5×30)的SPAV描述符。
3.3 训练第二层AdaBoost分类器
第二层分类器将第一层分类器产生的SPAV作为输入,并产生最终的多级动作分类器。

从所有数据动作图像中提取完CSPAV(CSC)集合之后,和第一层分类器的方法一样,利用CSPAV训练所有9个类别的第二层分类器。
在学习了第一和第二层分类器之后,将含有人体区域的输入窗口应用到第一层分类器和CSPAV。同时,将第一层分类器的聚合输出应用到第二层分类器。在计算完所有c-动作类别的分类分数之后,利用最大分数操作来给出最终类别,即
μ(c)=Max[score(1), …,score(C)]
(9)
如果动作类别c的最高分数μ(c)超过了阈值T,则将该输入窗口动作类别判定为c,表示为

(10)
4 实验及分析
4.1 实验设置
在PASCAL2010和KTH动作数据姿态库上进行实验。PASCAL2010数据姿态库包含9种不同人体动作,例如打电话、演奏乐器、读书、骑自行车、骑马、跑步、拍照、用电脑和走路。KTH数据集由6种自然动作组成,包括走路、慢跑、快跑、拳击、挥手和拍手,每个动作由25个人完成。图4给出了PASCAL2010数据姿态库中每个动作的样本图像。

图4 PASCAL2010数据集中的9种动作实例
为了进行测试,从PASCAL2010数据姿态库中选用454张9类动作图像,每类大约包含50张图像。对于KTH动作数据姿态库,本文采用968张6类动作图像,且每个动作类别至少有108张图像。
利用C++语言编译实现提出的人体动作识别系统。在测试中,首先对检测图像进行裁剪,使人体周围留有足够背景区域。然后缩放人体范围,以致臀部和肩膀之间的距离为200个像素。接着,在人体范围内利用扫描方法和双层分类器进行动作检测,从而获得不同位置和尺寸的动作。
4.2 训练实例数量的选择
对于训练分类器,每种动作的训练实例图像数量直接影响训练精度和时间消耗。实例图像数量的增加可以改善识别性能,但同时也增加了运行时间。
为了确定最佳训练图像数量,进行了相关实验。在PASCAL2010数据集上,通过改变动作实例数量进行实验,用来选择最优数量,结果见表1。其中,采用平均精度(average accuracy,AP)作为度量来定量评估动作识别性能,采用每幅图像的平均识别时间来评估方法的计算复杂度。可以看出,当用于动作识别的每类动作实例数量为30时,提出方法具有良好的识别性能,且其处理时间相对较短。在KTH数据集上执行相同实验,结果与PASCAL2010数据集相近。为此,来后续实验中,每类动作选取30张图像作为训练图像,其它作为测试图像。

表1 不同训练实例图像数量下的识别性能
4.3 性能验证
首先,在KTH和PASCAL2010数据集上执行本文方法,统计各类动作的识别结果。两个数据集上,各类动作的识别混淆矩阵如图5和图6所示。
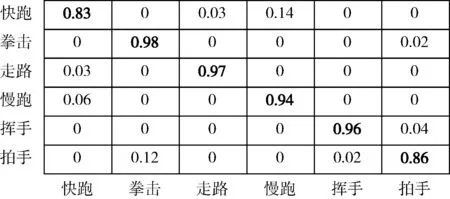
图5 在KTH数据集上分类的混淆矩阵
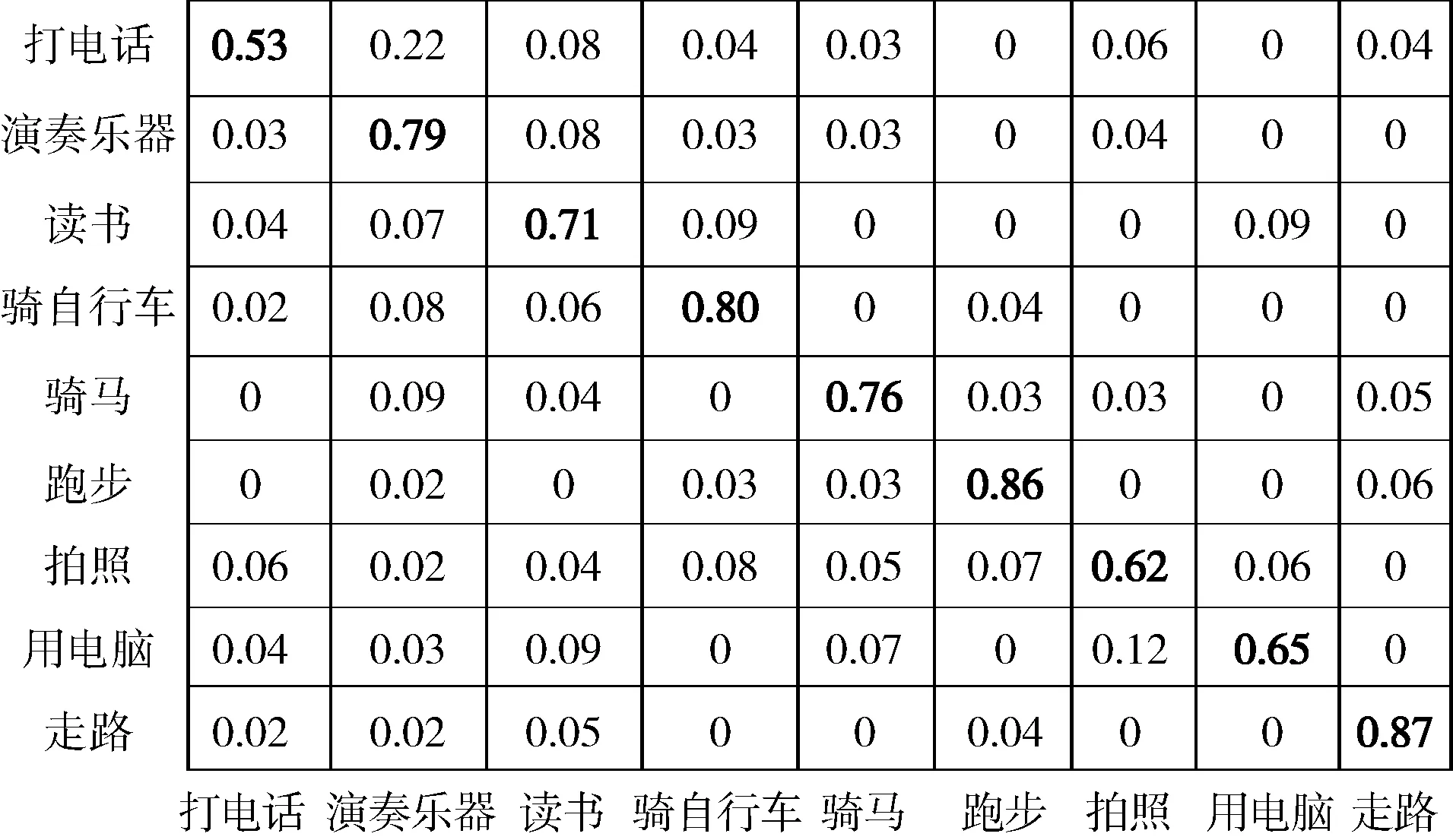
图6 在PASCAL2010数据集上分类的混淆矩阵
可以看出,对于KTH数据集,本文方法的整体识别率较高。只在快跑和慢跑、拍手和拳击之间有较高的错误分类。这是因为KTH数据集的动作较为简单,且背景不复杂,所以获得了较高的识别率。
对于PASCAL2010数据集,由于其动作和背景复杂,其整体识别率不如KTH数据集。其中,本文方法对演奏乐器、骑自行车、跑步和走路的识别率较高,而对打电话、拍照和用电脑的识别率较低。这是因为这些动作的相似度较高,例如很多打电话图像被分类到演奏乐器类别上。
4.4 性能比较
为了进一步评估提出算法的性能,将其与几种相关方法进行比较,分别为文献[4]提出的结合BoF和SVM的方法(BoF+SVM);文献[5]提出的PAV+SVM方法;文献[6]提出的基于BoF和SVM,且融合了颜色和形状描述符的方法(Fusion+BoF)。在KTH和PASCAL2010数据集上的实验结果分别见表2和表3。

表2 KTH数据集上识别准确率/%
这些结果证实,PAV+SVM比BoF+SVM方法的识别率高,这表明PAV的有效性。但由于基础PAV没有考虑动作的空间位置,所以比本文方法差。这就表明了PAV的空间位置和双层分类器对辨别人体动作非常有效。另外,Fusion+BoF方法与本文方法的性能相近,这是因为其使用颜色和形状描述符,增加了输入特征,所以获得了较好的性能。但其计算量较大,需要消耗大量的时间。
我们还可以观察到,所有测试方法对于一些人体的特定动作类,例如演奏乐器和读书等,具有较高的识别性能。而对于另一些类,例如打电话和拍照,具有较低的分类性能。这是因为测试图像中的许多人体范围包含上半身,而上半身经常会拥有非特定动作和与其它动作相似的动作。
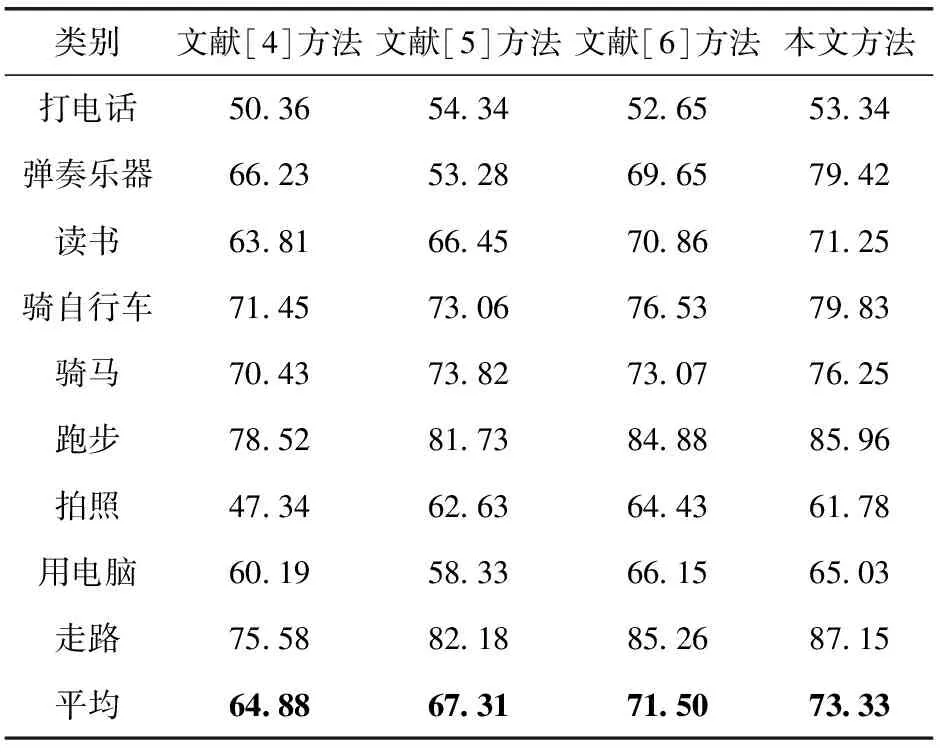
表3 PASCAL数据集上识别准确率/%
对各种方法在PASCAL2010数据集上识别每个图像所需的时间进行统计,结果见表4。可以看出,本文方法的平均速度为1.34 s,比PAV+SVM的平均速度快了约0.8 s。这就说明了结合空间位置的PAV比基础PAV在时间效率方法有明显提高。这是因为其不从所有人体区域提取测试实例,仅仅从动作实例的中心位置提取测试实例。另外,Fusion+BoF的处理时间最长,这是因为其使用了颜色和形状描述符,在提取特征和分类过程中需要更多的计算量。

表4 各种方法的平均识别时间/s
5 结束语
基于姿态库和AdaBoost双层分类模型提出了一种人体动作识别算法。为了考虑姿态库的空间位置,基于第一层分类器来训练姿态库,获得图像的SPAV。级联每张图像的SPAV,将其作为第二层分类器的输入。将提出的方法应用到两个动作图像数据集上,都获得了良好的识别性能。
在今后研究中,将考虑融入上下文、背景等一些附加特征描述符到识别系统中,以此提高本文算法对一些相似动作的识别性能。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
航天返回与遥感(2014年5期)2014-07-31
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中原工学院学报(2014年4期)2014-04-01
新课程学习·中(2013年3期)2013-06-14
