
抵抗Web攻击的异常入侵检测算法
2018-12-20 07:54王禹程
电子设计工程 2018年24期
王禹程
(陕西工业职业技术学院陕西咸阳712000)
伴随着互联网技术的发展和普及,网络通信日益成为人们日常生活中必不可少的部分。数据通信、在线视频、移动支付等均成为了人们生活中重要的习惯。人们在享受互联网带来便利的同时,也面临着巨大的安全隐患。Web攻击严重破坏了互联网通信安全,网络黑客可以随意窃取用户的个人信息、盗取银行卡密码、使网络瘫痪或崩溃,严重侵犯了用户的权益。因此,研究切实有效的可以抵抗Web攻击的计算机安全技术,已成为一个迫切的需求[1-2]。
目前,计算机安全技术研究种类繁多,常用的安全技术主要包括有计算机安全助手、网络防火墙技术、用户数据安全加密技术等。这些传统的安全技术在较大程度上可以有效抵抗常规的Web攻击,保护用户的数据安全。但现有的安全技术也存在着一定的不足,常用的安全技术主要针对用户端数据的加密与保护,是被动式的构建防御。而基于Web攻击的异常入侵是属于动态的入侵行为,入侵时间有攻击类型均具有不确定性。这就需要研究新型入侵检测技术,可以根据对网络数据和用户行为模式的分析,主动的对各种Web攻击入侵做出响应[3-4]。
入侵检测作为网络安全的主要技术,受到了研究者的广泛关注。目前主要的方法包括神经网络[5]、遗传算法[6]、特征提取[7]、聚类分析等[8-10]。其中,基于聚类分析的方法又可分为k-means聚类算法、层次聚类算法、SOM聚类算法和FCM聚类算法4种[11]。虽然异常入侵检测算法种类繁多,但均面临着检测准确度较低和复杂度较高的问题。
1 入侵检测系统设计
1.1 需求分析
设计一个合理有效的入侵检测系统,首先要明确其主要需求。作为一个成功的入侵检测系统要满足三个特点,分别是可视化、易操作和高检测率。首先,通过入侵检测系统,系统管理员可以实时检查系统的状态,查询各项系统指标包括程序、文件等。其次,系统设计应考虑到不同的用户层次,必须操作简单,非专业人员可以轻松的管理和配置,更具有应用价值。最后,系统对于各种类型的网络入侵均可进行良好的检测,且在发现网络入侵之后可以及时响应,自动执行向管理员报警并切断网络等处理。其具体设计需求包括:
1)统计用户行为活动,分析计算机和网络交互数据;
2)鉴别已知的异常入侵类型,并进行有效响应;
3)对可疑的行为模式进行记录和分析;
4)对计算机主要程序和数据文件的完整性进行评估。
1.2 设计原理
如图1所示,本文所设计的入侵检测系统主要可以分为嗅探器、解码器和数据预处理等8个模块。其中,嗅探器和解码器主要功能是实现抓包数据采集与解码分析。数据预处理与异常分析器是将数据格式进行处理,利用检测方法将已知的入侵行为与规则库进行匹配并报警。对于未知网络入侵行为则需要进行聚类分析,从而进行准确的入侵检测。

图1 入侵检测系统原理图
数据抓包收集模块,如图2所示。抓包模块采用Socket编程,通过对底层进行捕包和分析,实现信息提取。并通过自身设定好的规则进行包的过滤,例如不接受规定目的ip所发送的包,限定端口不接受包,系统可预先设置敏感词汇对包进行预过滤处理等。
2 聚类算法基本原理
2.1 聚类算法原理与应用
聚类算法的基本思想就是分类,将具有同一类属性或相似属性的数据对象分配到同一个类别中,尽可能保证不同类别中数据具有较低的相关性。一般聚类依据的准则可以是数据间的距离或者相关性大小等,根据一定的准则将数据划分成若干个相似性较低的类。
目前文献研究中关于聚类算法的研究种类繁多,包括基于各种方法或不同聚类准则的聚类算法。同时,还可能结合优化算法进行聚类分析。其中,比较经典的聚类算法研究包括基于K-means的聚类算法[12-13]以及其改进算法和基于层次方法的聚类算法[14]。另外,聚类算法结合神经网络模型、机器学习等综合聚类方法也开始得到了更多的关注[15]。
聚类算法研究在最近十几年得到了广泛的发展,充分应用于各个领域。各种聚类算法被提出和改进,其在机器学习、数据挖掘等领域被充分的研究。将聚类算法应用于Web攻击类型检测成为一种趋势。利用聚类算法准确的分类识别性能,可以对不同的异常入侵类型进行检测,能取得较好的检测准确率。
目前,一般聚类的研究均是将数据简单分类的思想,每一个数据至多属于一个类别。基于模糊聚类[16]思想的入侵检测算法使用隶属函数确定每一个数据与各个类别数据的相似程度来进行数据分类。众多基于模糊聚类的入侵检测算法已被广泛的研究,例如比较著名的基于FCM模糊聚类的入侵检测算法等。
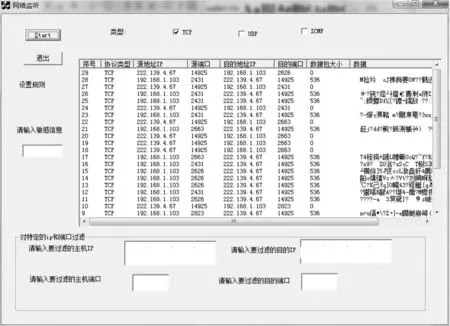
图2 数据抓包模块界面
如表1所示,不同聚类算法的入侵检测正确识别度对比,采用不同聚类0算法的检测精度相差较大。综合考虑到算法复杂度及检测准确度,本文首先对传统k-means聚类算法进行分析。

表1 不同聚类算法检测精度对比
2.2 K-means聚类算法
K-means是划分方法中较为经典的聚类算法之一。K-means具有效率高、聚类准确度高的特点,故被广泛应用于大规模的数据聚类问题。目前,基于K-means聚类的入侵检测算法的改进算法也不断被提出。
K-means聚类算法是一种迭代聚类算法,其主要的算法思想是利用随机生成的k个类或子集的平均值或者中心点作为每个集合的标准,将数据空间分割成k个子空间。然后分别比较剩余数据和这k个中心点的距离,将剩余的数据对象分配给距离最近的类。并根据分配结果更新每个数据集合的平均值,重复上述分配过程直至所有数据均不再变动。K-means聚类算法通常使用均方误差作为目标函数,判断聚类算法迭代过程是否结束:
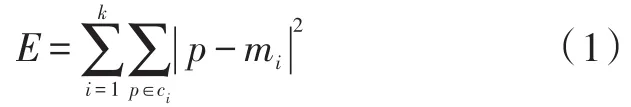
其中,E表示的是多个类数据对象的均方误差的总合。其表征的是子集中元素的紧凑程度,E越小表示子集中元素相似性越大;反之表示子集中元素相似性较差,则表示聚类算法性能较差。mi是子集ci的平均值[12],表示每个子集的中心位置。一般而言,不同子集的中心位置差距越大,表示聚类算法性能越好。通常,数据间距离度量使用欧式距离计算。具体算法步骤如下:
K-means聚类算法
输入:包含n个对象的数据集合;
子集的数目k;
1)初始化子集平均值,将随机选取的k个数据分别作为各个子集的中心;
2)计算目标函数值;
3)根据子集中数据的平均值,更新每个数据所属的类别;
4)根据更新的数据类别,更新子集的平均值;
5)更新目标函数值;
6)判断目标函数值是否变化,若是转到6),否则迭代结束。
输出:k个子集,使平方误差准则最小。
3 基于KNN聚类的入侵检测算法
KNN是通过测量不同特征值之间的距离进行分类。与K-means聚类方法不同,KNN聚类算法的思路是选取一个样本的k个相似数据对象来判断该数据对象的类型。在KNN算法中,选取的相邻对象均是经过正确分类的对象。KNN聚类算法使用临近数据去判断所属类别,k值的选取影响聚类的准确度。
在KNN聚类算法中,是选取距离数据最近的k数据对象来判断该数据的类别。首先需要选择出距离最近的数据点,通常判断距离远近使用欧氏距离或曼哈顿距离,分别如式(2)和(3)所示:

不同于K-means算法,KNN聚类不是根据该数据对象和某一数据的距离判断所属类别。而是根据相邻k个数据中大多数数据所属类别进行判断,因此KNN聚类算法准确性更高。
KNN聚类算法的具体步骤总结如下:
KNN聚类算法:
输入:明确类别的数据训练集;
相邻的数据数目k;
1)计算数据对象与训练集元素之间的距离;
2)选取距离测试数据最近的k个训练数据;
3)判断选取的k个点所在类别,并统计各个类别出现的次数;
4)返回出现次数最高的类别作为测试数据的预测分类。
输出:样本的类别。
K-means在一定程度上可以提供相对较高的入侵检测精度,但其实现复杂度也较高,其时间复杂度为O(n*k*t)。为了抵抗Web攻击,入侵检测算法精度仍需要进一步提高,且时间复杂度需要降低。为了满足实际需求,文中提出基于KNN聚类的入侵检测算法,其时间复杂度仅有O(n),大幅提高了实用性。
4 仿真结果及分析
为了验证算法的有效性,本节将对所提出的基于KNN聚类的入侵检测算法和基于K-means聚类检测算法进行对比。攻击类型分别为参数篡改、SQL注水、路径遍历和缓冲区溢出四种,检测结果如图3和图4所示。
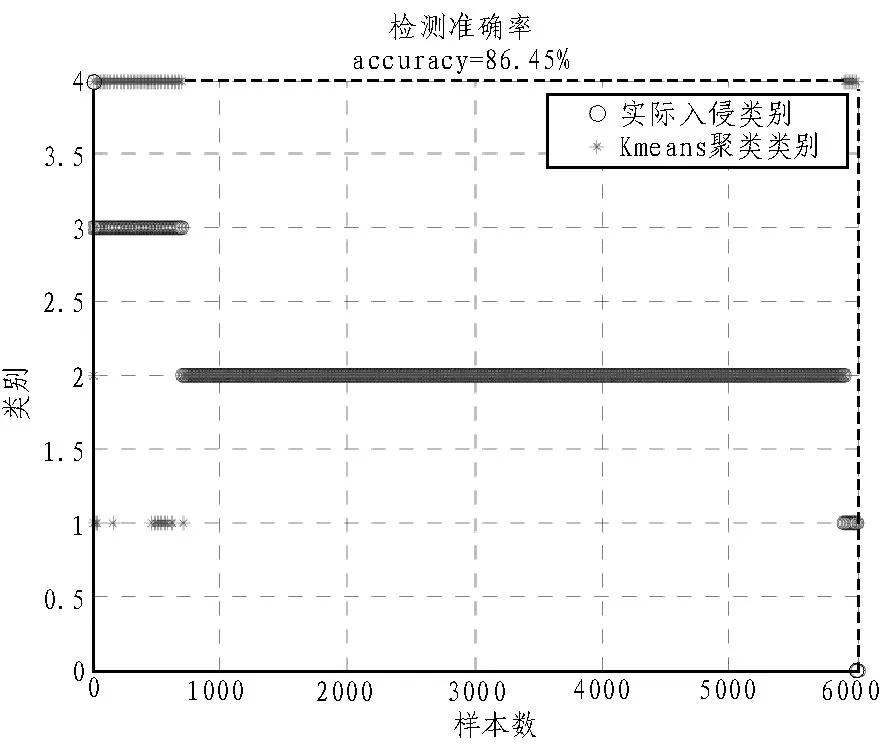
图3 K-means聚类算法入侵检测正确率
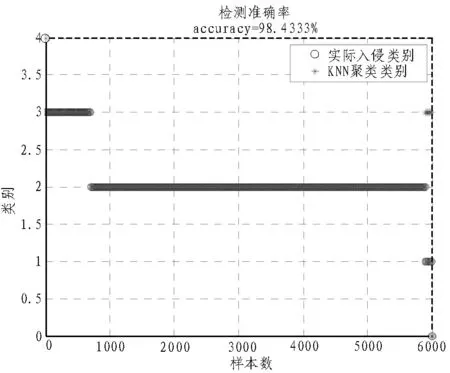
图4 KNN聚类算法入侵检测正确率
由图3和图4可知,基于KNN聚类算法入侵检测算法的检测率高达98.4%。相对于K-means聚类算法要高出12%,且对各种类型的攻击适应性均较好,算法性能优越。
为了更进一步验证所提算法对各种攻击类型的检测性能,表2和图3分别统计了所提算法对不同类型Web攻击的检测率。从表中可看出,对于常见的4种Web攻击类型所提的基于KNN聚类的入侵检测算法检测率可达到87%以上。其对于不同类型的Web攻击,均可以较好的进行检测。
5 结束语
文中针对当前抵抗Web攻击的安全需求,对异常入侵检测算法进行研究。首先,文中设计了异常入侵检测系统,利用数据挖掘原理和数据抓包处理建立数据库,为异常入侵检测提供数据支持。其次,分析研究了聚类算法在入侵检测中的应用。通过对比几种常见聚类算法的入侵检测率,分析了现有基于聚类算法的异常入侵检测算法存在的不足。并在此基础上,提出基于KNN聚类的异常入侵检测算法。相对于传统的基于K-means聚类的入侵检测算法,其时间复杂度更低,更具实时性。仿真结果表明,本文所提的异常入侵检测算法检测正确率相比于传统方法高12%,且对于不同类型的Web攻击检测准确率高达87%以上。具有较好的普适性,可应对不同类型的Web攻击,实现较为精准的异常入侵检测。

表2 不同攻击类型检测率对比
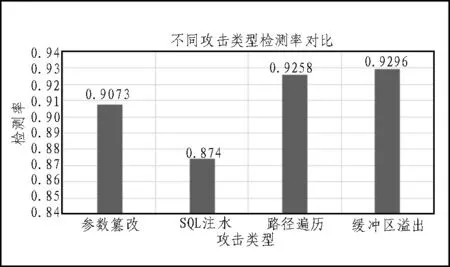
图5 不同攻击类型检测率对比图
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
中国惯性技术学报(2019年6期)2019-03-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
新校长(2016年8期)2016-01-10
都市丽人(2015年4期)2015-03-20
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
商事法论集(2014年1期)2014-06-27
