
基于迁移学习的分层注意力网络情感分析算法
2018-12-14 05:30曲昭伟王晓茹
计算机应用 2018年11期
曲昭伟,王 源,王晓茹
(1.北京邮电大学 网络技术研究院,北京 100876; 2. 北京邮电大学 计算机学院,北京 100876)(*通信作者电子邮箱wyuan@bupt.edu.cn)
随着互联网技术的发展和社交网络的普及,越来越多的用户选择在社交网站上发表自己的观点,产生了大量的评论信息,这些评论信息表达了用户的情感色彩和情感倾向性,因此,通过对评论文本进行情感分析可以判断评论文本中的情感取向,应用于市场分析以及相关产品推荐上。
1 相关工作
文本情感分析又称为观点挖掘,利用自然语言处理、文本分析等方法对带有情感色彩的文本进行分析、处理、推理和归纳[1]。
情感分析方法主要有基于情感词典匹配的方法以及基于机器学习的方法。随着深度学习逐渐成为自然语言处理领域研究热点,利用深度学习的方法解决情感分析问题的技术飞速发展[2]。在自然语言处理领域,例如循环神经网络(Recurrent Neural Network, RNN)等深度神经网络在处理情感分析问题时具有明显优势。长短期记忆网络(Long Short-Term Memory, LSTM)可以捕捉到评论语句中的长期依赖关系,从整体上理解文本的情感语义,与卷积神经网络(Convolutional Neural Network, CNN)相比,RNN更适合处理序列信息。Li等[3]研究了树结构的LSTM网络;Cho等[4]提出了门循环单元(Gated Recurrent Unit, GRU),与LSTM网络相比,具有更少的参数;Ravanelli等[5]将一种加权循环单元应用于语音识别领域,实验结果证明该结构具有较好的语音识别效果。
近年来,迁移学习逐渐成为数据挖掘领域的研究重点,即将从源领域学习到的模型或思想应用于目标领域。在计算机视觉领域,在大规模图像分类数据集(ImageNet)上训练的深度卷积神经网络[6]可以用作其他模型中的组成部分,并在一系列任务上得到出色的结果。Zhuang等[7]提出一种基于双编码层自编码器的监督表示的迁移学习方法;Tan等[8]探究了以一种称为远程域迁移学习的新型迁移学习问题,在目标域与源域完全不同的情况下实现迁移学习;Long等[9]提出了深度适配网络的深度迁移学习方法;吴斌等[10]针对古代诗歌等短文本的情感分析问题提出一种基于特征扩展的迁移学习模型。
在文本情感分析问题中,利用Word2Vec[11]和GloVe[12]等模型进行无监督训练得到的词向量迁移到自然语言处理任务中能够提高模型的性能,但是这类无监督训练得到的词向量无法准确代表上下文关系[13],该问题也限制了分类模型的准确率。针对以上问题,本文提出一种基于迁移学习的分层注意力神经网络(Transfer Learning based Hierarchical Attention Neural Network, TLHANN)的情感分析方法,利用机器翻译模型编码器生成的词的分布式表示与GloVe模型训练的词向量相结合作为情感分析算法的输入,准确表示文本语境关系,并采用最小门单元(Minimal Gate Unit, MGU)[14]简化算法结构,经过大量实验证明了本文算法的分类准确率比传统算法有较大提升。
2 基于迁移学习的文本情感分析算法
2.1 训练LSTM编码器
由于机器翻译任务的数据集远大于其他自然语言处理任务,本文提出的情感分析算法的第一部分是利用英语-德语翻译任务训练一个LSTM编码器。这一步骤的目的是为了得到可以应用于文本情感分析的辅助的隐藏向量,从而提高情感分析算法的性能。这些输出的隐藏向量与GloVe训练的词向量相结合,作为情感分析部分的输入。

(1)
(2)
(3)

(4)
根据全局注意力模型[14],可变长度的对齐向量χt可以表示为:
(5)
(6)
其中ct定义为源隐藏状态的加权平均。最后输出单词的分布表示为:
(7)
经过上述机器翻译任务的训练之后,本文得到了一个双向LSTM编码器,利用这个编码器得到新句子的隐藏向量,将它与传统的GloVe向量相结合,如图1所示。
对于输入序列w,后续情感分析模型的输入x如式(8)所示:
(8)

图1 将利用机器翻译任务训练的编码器迁移到情感分类任务中
2.2 情感分析任务
基于Yang等[16]提出的模型,本文采用的情感分析算法具有分层结构,分为单词层和句子层。在每一层,使用一种简化的循环神经网络结构单元——最小门单元(MGU)。MGU只有一个门单元——遗忘门,将输入(重置)门合并入了遗忘(更新)门,结构图如图2所示。在t时刻,MGU计算当前的状态为:
(9)
遗忘门控制上一时刻记忆的遗忘程度以及附加多少新信息,MGU的遗忘门的表示为:
ft=σ(Wf+Ufht-1+bf)
(10)

(11)


图2 最小门单元结构
本文采用的是一种分层的情感分析算法,结构如图3所示。在单词层,将翻译任务训练得到的隐藏向量与GloVe向量相结合作为模型的输入,并采用MGU网络来模拟句子的语义表示。

(12)
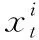
(13)

(14)

(15)
然后得到句子表示:
(16)

图3 TLHANN算法结构
得到了句子层的表示si之后,利用相同方式获得文档层的表示:
hi=MGU(si);i∈[1,m]
(17)
同样,不同的句子对判别文档的情感极性所起到的作用也有差异,因此,在句子层也采用注意力机制,并引入句子层的上下文向量vs,如式(18)~ (20)所示:
vi=tanh(Wshi+bs)
(18)
(19)
(20)
d是最终得到的文档表示,而上下文向量vs被随机初始化并通过训练过程学习得到。
上文得到的d总结了文档中句子的所有信息,因此可以将它作为文档情感分类的特征。使用一个多层感知器可以得到:
(21)
然后使用softmax层得到不同情感等级的概率分布:
(22)
其中:pc是情感等级是c的概率,C是情感等级数。
本文使用黄金情感分布和模型预测的情感分析的交叉熵误差作为损失函数:
(23)

(24)

3 实验与分析
3.1 数据集及实验设置
在进行机器翻译任务时使用了两个数据集,分别为WMT2016的Multi30k数据集和IWSLT2016年的机器翻译任务数据集,其中Multi30k的训练集由30 000个描述图像的句子对组成,IWSLT2106的机器翻译数据集训练集由209 772个句子对组成。在训练LSTM编码器时,使用the CommonCrawl-840B GloVe 模型生成英语词向量,得到300维的词向量,这里的LSTM网络的隐藏层隐藏单元数设置为300。训练时采用随机梯度下降算法,学习率以1开始,当验证复杂度首次提高时,每个周期将学习率减半,Dropout均为0.2。在Multi30k数据集上训练的机器翻译模型在测试集上的BLEU(BiLingual Evaluation Understudy)分数为37.6,在IWSLT2106版本的机器翻译数据集上训练得到的模型在测试集上的BLEU分数为24.7。
对于情感分析任务,使用4个数据集:IMDB、IMDB2、Yelp2013和Yelp2014。数据集的详细信息见表1,将数据集按8 ∶1 ∶1的比例分为training、development、testing集。
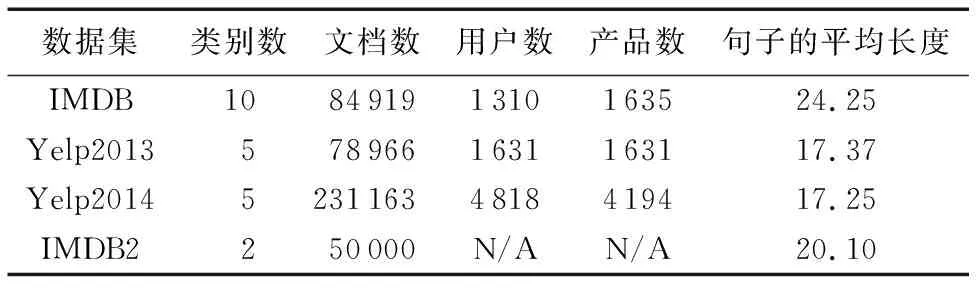
表1 实验数据集的统计信息
本文使用两个常用的模型评价指标:准确率(Accuracy)和均方根误差(Root Mean Square Error, RMSE),其中准确率用来评价情感分析算法的表现,RMSE用来衡量预测的情感级别和真实值的偏差。Accuracy和RMSE的公式如下:
Accuracy=T/N
(25)
(26)
其中:GRi是真实的情感等级,PRi是预测的情感等级,G是GRi与PRi相等的文档数,N是总文档数。本文设置情感分析算法中MGU隐藏单元数为300,注意力机制中的单词、句子上下文向量为300维。使用development集来调超参数并且使用Adadelta在训练中更新参数。
3.2 实验结果及分析
本节分别将本文提出的基于迁移学习的分层注意力神经网络的情感分析方法与未引入迁移学习的方法包括SSWE (Sentiment-Specific Word Embeddings)+ SVM(Support Vector Machine)[17]、LSTM+ UPA(User Product Attention)[18]、LSTM+CBA(Cognition Based Attention)[19]进行对比。其中SSWE+SVM利用特殊的情感词嵌入,采用SVM分类器进行情感分析;LSTM+UPA方法利用LSTM网络结合注意力机制进行情感分析;LSTM+CBA方法利用基于视觉追踪数据的注意力机制的LSTM网络进行分析。实验结果如表2和表3,其中表2为以上四种方法的分类准确率, 文所提算法的分类准确率与LSTM+CBA算法和SVM算法相比分别平均提升了8.7%及23.4%,表3为四种方法的均方根误差值。从实验结果可以看出,对于同样的情感分析数据集,本文方法具有更高的分类准确率和更小的误差。

表2 四种方法的分类准确率对比

表3 四种方法的分类均方根误差对比
另外,比较了在迁移学习部分中,用于训练LSTM编码器的机器翻译数据量对后续情感分析任务的影响,实验结果如表4所示。实验结果表明,翻译数据集越大,将得到的LSTM编码器迁移到情感分析任务时,对于算法性能的提升越大;也就是说,用于训练LSTM编码器的机器翻译数据集越大,将该编码器迁移到情感分析任务中时,生成的分布式表示能够更好地体现句子上下文关系,对于文本情感极性的预测更有帮助。

表4 与随机初始化词向量相比本文算法的准确率提升效果 %
为了说明注意力机制的作用,在4个数据集上比较了本文的基于迁移学习的分层注意力神经网络(Transfer Learning based Hierarchical Attention Neural Network, TLHANN)与不引入注意力机制——基于迁移学习的分层神经网络(Transfer Learning based Hierarchical Neural Network, TLHNN)的性能,实验结果如表5所示。从表5中可以看出,在情感分析算法中引入注意力机制能提升算法的性能,在IMDB、Yelp2013、Yelp2014和IMDB2数据集上的分类准确率分别提升了4.0%、2.0%、2.3%以及10.6%。

表5 注意力机制对于分类模型的影响(分类准确率)
4 结语
本文针对情感分析问题提出了一个基于迁移学习的分层注意力神经网络(TLHANN)算法。首先利用机器翻译任务训练一个LSTM编码器,将其迁移到情感分析任务中用来生成分布式表示作为神经网络的输入,并采用简化的循环神经网络结构,减少了模型参数数量。经过大量实验验证了该算法在不同的数据集上的出色表现。研究其他自然语言处理任务对于情感分析问题的可迁移性并提高分类准确率将成为下一步工作的重点。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
新高考·高一数学(2022年3期)2022-04-28
锻压装备与制造技术(2021年5期)2021-11-13
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
科学技术创新(2021年5期)2021-03-17
健康体检与管理(2021年10期)2021-01-03
——编码器
演艺科技(2020年7期)2020-08-13
